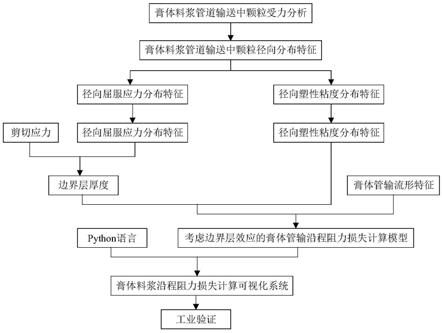
1.本发明涉及山洪灾害防治领域,特别涉及一种基于机器学习的山洪灾害区划方法。
背景技术:
2.山洪是山丘区小流域由于短历时强降雨诱发的急涨急落的地表径流,山洪灾害是世界上最致命的自然灾害之一,其具有突发性强、隐蔽性强、破坏力大、损失严重等特点,常造成居民伤亡、冲毁建筑设施、改变河流形态和破坏自然环境。随着极端气候事件和人类活动的加剧,山洪灾害问题逐渐受到世界各国的广泛关注与高度重视。开展山洪灾害区划可以有效地反映的山洪灾害的空间分异格局,为山洪灾害实施分而治之的防治与预警提供科学依据,有利于山洪防治减灾事业的稳健发展。
3.山洪灾害分区是自然地理区划的研究内容之一,自然区划方法主要包括:成因分区法、评价指标分级分区法、多元统计法以及能够较好识别地理区域的聚类分析法等。聚类算法是自然地理区划研究中应用最普遍的方法,应用领域也很广,如流域水文区划、气候区划、降雨区划等。但近年来关于山洪灾害的研究多以风险评估为主,较少关注山洪灾害的区划研究。
技术实现要素:
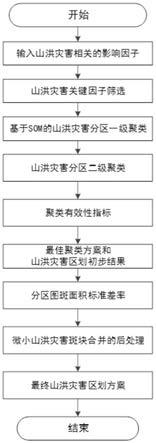
4.发明目的:针对以上问题,本发明目的是提供一种基于机器学习的山洪灾害区划方法,以小流域为基本空间单元进行som两级混合聚类,根据聚类结果和分区图斑面积标准差率获得山洪灾害区划方案。
5.技术方案:本发明的一种基于机器学习的山洪灾害区划方法,包括如下步骤:
6.(1)预处理山洪灾害影响因子,提取各项短时强降雨指标和下垫面数据指标;
7.(2)根据随机森林模型的变量重要性,从短时强降雨指标和下垫面数据指标中筛选山洪灾害的关键因子,将关键因子作为山洪灾害距离的输入变量;
8.(3)根据筛选的关键因子,构建基于自组织映射神经网络模型som进行山洪灾害的一级空间聚类,然后分别利用ward、kmeans、pam、clara、hkmeans聚类方法对som神经元节点分组,进行二级聚类;
9.(4)利用外部指标和内部指标对山洪灾害的二级聚类结果进行综合评价,确定山洪灾害最佳聚类方案,作为山洪灾害的初步区划结果;
10.(5)计算初步区划结果中分区图斑面积标准差率,对微小斑块进行合并后处理,获取最终山洪灾害区划结果。
11.进一步,步骤(3)利用神经网络模型som进行一级空间聚类包括两阶段:
12.(301)第一阶段用权重向量w
ij
计算获胜神经元,使其与输入向量xk的距离d
jk
最小,表达式为:
13.|x
k-wc|=minj{d
jk
}
14.(302)第二阶段为学习阶段,更新获胜神经元及周围神经元的权重向量,表达式为:
15.w
ij
(t 1)=w
ij
(t) η(t)(x
i-w
ij
(t))
16.其中0<η(t)<1为增益函数,随着时间逐渐减小;w
ij
为权重向量,t是迭代步长。
17.进一步,步骤(3)自组织映射神经网络模型som包括两层网络,输入层中的神经元个数为用于山洪灾害区域化的关键因子数目,输出层被组织成二维网格的拓扑结构。
18.进一步,所述外部指标包括区划效果指数rqi;
19.所述内部指标包括戴维森堡丁指数dbi和轮廓系数si;
20.步骤(4)评价标准为:外部指标rqi作为聚类方案判定的主要指标,根据rqi的最小值判定最优的聚类数目与方案;当不同方案rqi最小值相同时,再结合内部指标dbi和si进行评判,当dbi数值较小、si数值较大对应方案为最佳聚类方案。
21.进一步,所述拓扑结构为正方形或六边形结构。
22.进一步,步骤(5)最终山洪灾害区划结果标准为分区图斑面积标注差率趋于稳定。
23.进一步,步骤(5)分区图斑面积标准差率定义为各个图斑面积的标准差除以均值,表达式为:
[0024][0025]
其中σ为标准差,μ为均值。
[0026]
有益效果:本发明与现有技术相比,其显著优点是:
[0027]
1、本发明通过随机森林模型对山洪灾害相关关键因子进行选择,然后利用som进行两级混合聚类,结合多种机器学习方法实现了山洪灾害空间区划;
[0028]
2、通过随机森林模型的特征选择,更好的找到与历史山洪灾害高度相关的关键因子,以较少数目的关键特征变量保留数据信息用于山洪灾害区划;
[0029]
3、基于som两级混合聚类,对输出进行二级聚类后综合多种聚类方法的优势获取更佳的聚类结果;
[0030]
4、提出了聚类结果评价的外部指标rqi,结合内部指标dbi和si确定最佳聚类方案作为初步区划结果;提出了基于分区图斑面积标准差率的聚类微小斑块后处理方法,将细小图斑与具有最长公用边界的邻近图斑合并,为确定分区数目提供数量依据。
附图说明
[0031]
图1为本发明山洪灾害区划方法流程图;
[0032]
图2为山洪灾害区划方法结果:(a)小流域单元初始聚类结果,(b)小流域初次合并结果,(c)山洪灾害区划方案。
具体实施方式
[0033]
本实施例所述的一种基于机器学习的山洪灾害区划方法,流程图如图1所示,包括如下步骤:
[0034]
(1)预处理山洪灾害影响因子,提取各项短时强降雨指标和下垫面数据指标:
[0035]
由于原始降雨数据存在异常值和数据缺失问题,故使用前需要对原始降雨数据进
行预处理,剔除其中的异常值,利用插值弥补缺失的数据,最终得到各项短时强降雨指标,同时对下垫面数据通过重采样得到相同空间分辨率的下垫面数据指标。构建影响山洪灾害的指标体系,包括短时强降雨因子、下垫面数据指标、小流域属性,将这些数据作为输入山洪灾害密切相关的影响因子。
[0036]
(2)利用随机森林模型的变量重要性,从短时强降雨指标和下垫面数据指标中筛选山洪灾害的关键因子,将关键因子作为山洪灾害距离的输入变量。
[0037]
选取发生历史山洪灾害的小流域作为正样本,训练随机森林模型,利用袋外样本数据测试随机森林模型中每棵树的oob误差,xj随机森林变量重要性定义如下:
[0038][0039]
其中t是随机森林中的树,ntree是树的数量,erroob
t
是利用袋外样本数据测试模型中每棵树的oob误差,为随机打乱袋外样本数据中变量j的值重新测试每棵树的oob误差。
[0040]
通过随机森林模型计算变量重要性排序,选择变量重要性大,且高于变量重要性均值的变量,作为影响山洪灾害的关键因子。
[0041]
(3)根据筛选的关键因子,构建基于自组织映射神经网络模型som进行山洪灾害的一级空间聚类,然后利用ward、kmeans、pam、clara、hkmeans聚类方法对som神经元节点分组,进行二级聚类;
[0042]
利用神经网络模型som进行一级空间聚类包括两阶段:
[0043]
(301)第一阶段用权重向量w
ij
计算获胜神经元,使其与输入向量xk的距离d
jk
最小,表达式为:
[0044]
|x
k-wc|=minj{d
jk
}
[0045]
(302)第二阶段为学习阶段,更新获胜神经元及周围神经元的权重向量,表达式为:
[0046]wij
(t 1)=w
ij
(t) η(t)(x
i-w
ij
(t))
[0047]
其中0<η(t)<1为增益函数,随着时间逐渐减小;w
ij
为权重向量,t是迭代步长。
[0048]
自组织映射神经网络模型som包括两层网络,输入层中的神经元个数为用于山洪灾害区域化的关键因子数目,输出层被组织成二维网格的拓扑结构,拓扑结构为正方形或六边形结构。
[0049]
(4)利用外部指标和内部指标对山洪灾害的二级聚类结果进行综合评价,外部指标rqi作为聚类方案判定的主要指标,根据rqi的最小值判定最优的聚类数目与方案;当不同方案rqi最小值相同时,再结合内部指标dbi和si进行评判,当dbi数值较小、si数值较大对应方案为最佳聚类方案,作为山洪灾害的初步区划结果。
[0050]
外部指标包括区划效果指数rqi,表达式为:
[0051][0052]
其中m为总小流域数;c为类别数;f为关键因子数;cv
ij
为类型i中j的变异系数;ε为常数。
[0053]
内部指标包括戴维森堡丁指数dbi和轮廓系数si;表达式分别如下:
[0054][0055][0056]
其中k是聚类数目,是i簇中每个样本与该簇中心之间的平均距离,是j簇中每个样本与该簇中心之间的平均距离,d
ij
是簇i与簇j的簇中心之间的距离;
[0057][0058]
其中a(i)为样本与同一簇类中的其他样本点的平均距离;b(i)为样本与距离最近簇类中所有样本点的平均距离。
[0059]
(5)计算初步区划结果中分区图斑面积标准差率,运用arcgis的eliminet工具对微小斑块归并到相邻边最长的图斑里,当分区方案中各区域面积相当,分区图斑面积标准差率趋于稳定时,表明各个区域的面积达到相近,即得到分区大小相对均匀的山洪灾害区划方案。通常定义面积小于100km2时为微小图斑。
[0060]
分区图斑面积标准差率定义为各个图斑面积的标准差除以均值,表达式为:
[0061][0062]
其中σ为标准差,μ为均值。
[0063]
利用本发明方法进行山洪灾害区划结果如图2所示:图2(a)为以小流域为基本空间单元,进行基于som两级混合聚类,并通过聚类有效性指标判定得到的最佳聚类方案,即:由rqi确定最佳聚类数为7,再由dbi和si确定的最优初始小流域单元聚类结果,对应聚类方法为sofm和kmeans;图2(b)为相邻小流域属于同一聚类的初次合并后的7类结果;图2(c)根据分区图斑面积标准差率合并后的山洪灾害区划方案。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。