1.本技术涉及大数据存储分析领域,尤其是涉及一种大数据标签存储方法、分析方法及系统。
背景技术:
2.在日常的工作中,需要对人、物、车、案等主体使用带有主体特性的数据标签进行快速搜索和标签数据分析。
3.目前使用关系型数据库存储标签数据也呈现一些现状:目标标签主体的数据量已经达到了亿级,使用关系型数据库存储无法保证插入更新、查询的速度,不能满足标签数据生产中的频繁、快速更新和毫秒级检索的需求。每个主体的数据标签都是不同的,数据标签的列是动态的。使用关系型数据库存储只能穷举所有的列,创建一个字段超级多的表。
4.随着目标业务的扩展,数据标签也一直在增加,因为关系型数据库的列无法动态扩展,只能修改原来的表结构,增加新的标签列,数据库维护成本高;搜索标签时需要获得标签的来源信息和标签出现的次数以供标签溯源,现有的标签数据存储结构已经无法再增加新的列来存储这两个信息了,导致对于标签溯源的需求一直没有实现。由于单条数据中很多标签列都是null值,再加上标签搜索还有前模糊匹配,所以在检索数据的时候关系型数据库的索引会失效,搜索速度会变得非常慢。因为每一个数据标签都是一个单独的列,根据关键字搜索时要遍历几百个标签列,要做到快速的全文搜索是无法实现的。
技术实现要素:
5.有鉴于此,本技术提供种一种大数据标签存储方法、分析方法及系统,用以解决现有数据库存储大数据标签存在速度过慢或效率不高,导致查询业务受阻的技术问题。
6.为了解决上述问题,第一方面,本技术提供一种大数据标签存储方法,所述方法包括:
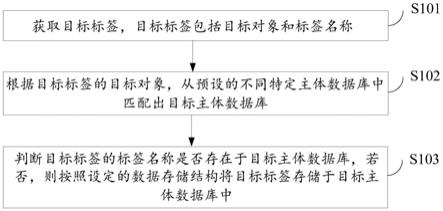
7.获取目标标签,所述目标标签包括目标对象和标签名称;
8.根据所述目标标签的目标对象,从预设的不同特定主体数据库中匹配出目标主体数据库;
9.判断所述目标标签的标签名称是否存在于所述目标主体数据库,若否,则按照设定的数据存储结构将所述目标标签存储于所述目标主体数据库中。
10.可选的,所述目标标签还包括标签来源;则按照设定的数据存储结构将所述目标标签存储于所述目标主体数据库中,包括:
11.利用数组形式存储目标标签的目标对象和标签名称;
12.为目标标签的标签名称设置标签编码;
13.为目标标签的标签编码创建标签字段和来源字段,所述来源字段内嵌于所述标签字段;
14.将目标标签的标签名称和标签编码对应存储于所述标签字段,将目标标签的标签
来源存储于所述来源字段。
15.可选的,所述按照设定的数据存储结构将所述目标标签存储于所述目标主体数据库中,还包括:
16.设置检索模式,包括:当目标标签的标签名称和标签编码被同时检索时,采用分词索引模式;当目标标签的标签名称或标签编码单独被检索时,采用不分词索引模式;
17.将记录目标标签的标签来源的出现次数为1;
18.将目标标签的标签来源的出现次数存储于来源字段。
19.可选的,所述按照设定的数据存储结构将所述目标标签存储于所述目标主体数据库之后,所述方法还包括:
20.若获取到关于目标标签的第一删除指令,所述第一删除指令包括待删除标签来源,则从目标主体数据库中将目标标签对应的待删除标签来源删除;
21.判断删除后所述目标标签是否存在其他标签来源,若是,则保留所述目标标签的标签编码和标签名称;若否,则将所述目标标签的标签编码和标签名称删除;
22.可选的,所述按照设定的数据存储结构将所述目标标签存储于所述目标主体数据库之后,所述方法还包括:
23.若获取到关于目标标签的第二删除指令,所述第二删除指令包括待删除标签编码,则从目标主体数据库中将目标标签对应的待删除标签编码、标签名称和标签来源删除。
24.第二方面,本技术提供一种大数据标签分析方法,包括:
25.执行所述的大数据标签存储方法;
26.获取待查询数据,所述待查询数据包括同一待查询对象对应的多个待查询标签名称和维度参数;
27.确定所述待查询对象对应的待查询主体数据库;
28.根据所述多个待查询标签名称和维度参数,构造数据分析脚本;
29.利用所述数据分析脚本在所述待查询主体数据库中查询,获取数据分析结果。
30.可选的,根据所述待查询对象对应的多个待查询标签名称和维度参数,构造数据分析脚本,包括:
31.根据多个待查询标签名称的命中要求情况,确定多个所述待查询标签名称的查询逻辑关系;
32.根据待查询主体数据库的内外层逻辑顺序,构造数据查询语法;
33.根据所述维度参数,构造聚合语法;
34.根据多个所述待查询标签名称的查询逻辑关系、数据查询语法、聚合语法以及预设的统计算法,构造数据分析脚本。
35.可选的,所述根据多个所述待查询标签名称的命中要求情况,确定所述待查询标签名称的查询逻辑关系,其中,所述查询逻辑关系至少包括and和or逻辑关系。
36.第三方面,本技术提供一种大数据标签存储系统,所述系统包括:
37.获取数据模块,用于获取目标标签,所述目标标签包括目标对象和标签名称;
38.匹配模块,用于根据所述目标标签的目标对象,从预设的不同特定主体数据库中匹配出目标主体数据库;
39.存储模块,用于判断所述目标标签的标签名称是否存在于所述目标主体数据库,
若否,则按照设定的数据存储结构将所述目标标签存储于所述目标主体数据库中。
40.第四方面,本技术提供一种大数据标签分析系统,所述系统包括:
41.获取数据模块,用于获取待查询数据,所述待查询数据包括同一待查询对象对应的多个待查询标签名称和维度参数;
42.确定数据库模块,用于确定所述待查询对象对应的待查询主体数据库;
43.脚本构造模块,用于根据所述多个待查询标签名称和维度参数,构造数据分析脚本;
44.分析模块,用于利用所述数据分析脚本在所述待查询主体数据库中查询,获取数据分析结果。
45.采用上述实施例的有益效果是:本实施例获取目标标签,根据目标标签的标签对象,可以匹配出目标主体数据库,从而便于将目标标签存储到目标主体数据库中;判断所述目标标签的标签名称是否存在于所述目标主体数据库,若否,则按照设定的存储结构将所述目标标签增添至所述目标主体数据库中,从而将目标标签存储到对应的目标主体数据库中,实现大数据标签的快速分类存储,提高数据存储速度,减少数据拥塞。
附图说明
46.图1为本技术提供的大数据标签存储方法一种实施例的方法流程图;
47.图2为本技术提供的大数据标签存储方法步骤s103一实施例的方法流程图;
48.图3为本技术提供的数据存储结构脚本示意图;
49.图4为本技术提供的大数据标签存储方法步骤s103另一实施例的方法流程图;
50.图5为本技术提供的大数据标签分析方法一种实施例的方法流程图;
51.图6为本技术提供的大数据标签分析方法步骤s503一种实施例的方法流程图;
52.图7为本技术提供的数据分析脚本示意图;
53.图8为本技术提供的数据分析方法流程图;
54.图9为本技术提供的大数据标签存储系统一实施例的原理框图;
55.图10为本技术提供的大数据标签分析系统一实施例的原理框图。
具体实施方式
56.下面结合附图来具体描述本技术的优选实施例,其中,附图构成本技术一部分,并与本技术的实施例一起用于阐释本技术的原理,并非用于限定本技术的范围。
57.在本技术的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
58.在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
59.参照图1为本技术提供的大数据标签存储方法一种实施例的方法流程图,该大数据标签存储方法包括下述步骤:
60.s101、获取目标标签,目标标签包括目标对象和标签名称;
61.s102、根据目标标签的目标对象,从预设的不同特定主体数据库中匹配出目标主
体数据库;
62.s103、判断目标标签的标签名称是否存在于目标主体数据库,若否,则按照设定的数据存储结构将目标标签存储于目标主体数据库中。
63.在本实施例中,特定主体数据库采用elasticsearch数据库创建,不同特定主体数据库的类型有人员信息数据库、车辆信息数据库、案件信息数据库以及物件信息数据库等;目标对象是指被打标签的数据主体,比如人员、车辆、案件等不同的数据主体;标签名称是指针对目标对象打的标签名字,比如针对某个人员,可能被贴有涉案人员、涉警人员和个体工商户等标签名字,在本实施例中,一个目标标签包含被标的目标对象、一条标签名字以及对应的标签来源。本实施例中使用elasticsearch 数据库存储数据,可以解决亿级数据量的存储,使用分片存储方式,可以横向扩展,即使数据量再大存储也毫无压力。一个分片就是一个lucene 的实例,搜索数据时会到每个分片上进行搜索然后汇总结果,提升搜索效率。在写入大批量数据的时候,也可以做到接近实时的搜索速度,读写互不影响。
64.本实施例获取目标标签,根据目标标签的标签对象,可以匹配出目标主体数据库,从而便于将目标标签存储到目标主体数据库中;判断目标标签的标签名称是否存在于目标主体数据库,若否,则按照设定的存储结构将目标标签增添至目标主体数据库中,从而将目标标签存储到对应的目标主体数据库中,实现大数据标签的快速分类存储,提高数据存储速度,减少数据拥塞。
65.在本实施例中,数据存储结构采用表结构、数组、字段、分词和/不分词检索方式创建;参照图2,步骤s103中,按照设定的数据存储结构将目标标签存储于目标主体数据库中,包括:
66.s201、利用数组形式存储目标标签的目标对象和标签名称;
67.s202、为目标标签的标签名称设置标签编码;
68.s203、为目标标签的标签编码创建标签字段和来源字段,来源字段内嵌于标签字段;
69.s204、将目标标签的标签名称和标签编码对应存储于标签字段,将目标标签的标签来源存储于来源字段。
70.在一个具体的实施例中,参照图3所示的数据存储结构脚本,同一个目标对象可能会有多个目标标签,所有目标标签都存储于一个tags字段,tags字段是一个数组,每一个数组元素都是一个目标标签,一个目标标签需一个标签字段和一个来源字段即可存储,从而使得在创建字段时配置的索引规则后续也不需要修改,表结构的维护成本极大地降低了。
71.参照图4,步骤s103中按照设定的数据存储结构将目标标签存储于目标主体数据库中,还包括:
72.s401、设置检索模式,包括:当目标标签的标签名称和标签编码被同时检索时,采用分词索引模式;当目标标签的标签名称或标签编码单独被检索时,采用不分词索引模式;
73.s402、将记录目标标签的标签来源的出现次数为1;
74.s403、将目标标签的标签来源的出现次数存储于来源字段。
75.在存储目标标签时,既要存储目标标签的标签编码又要存储标签名称,标签编码作为插入更新的依据字段,采用不分词检索,提供了数据标签的精确搜索和作为数据分析参数的能力。
76.将标签名称和标签编码对应一起存储,并且设置为一般分词,实现目标标签的全文搜索。根据标签名称全文搜索也符合用户的搜索习惯,全文搜索的响应速度有效提升,只需几毫秒。
77.此外,在标签字段内嵌来源字段,使每一条数据中的每一个目标标签都能找到对应的来源。同一个目标标签的来源可能会是多个,因此在存储目标标签时,需要存储两个来源,所以来源信息也使用数组结构存储。同一目标对象的相同标签会出现多次,而次数又根据目标标签的来源会不同,所以次数信息是放在标签来源信息内部。
78.在本实施例中,目标标签在插入目标主体数据库中更新时,使用 elasticsearch提供的painless脚本实现插入更新逻辑,elasticsearch数据库中标签数据插入更新相比于关系型数据库速度更快,几千万标签数据插入更新只需几十分钟就可以完成,在插入更新的过程中也不会影响搜索的性能,数据搜索几乎是实时的。
79.需要说明的是,因为针对目标标签的数据存储结构是一个嵌套的格式,在存储时还需要计算标签出现的次数。如果目标对象还不具有当前输出的标签名称,那么直接更新目标对象增加新的标签信息和对应的来源信息,标签出现次数记为1。如果数据主体已经有了当前输出的标签名称,再判断是否有当前标签名称的来源,如果没有相同的来源信息,则新增来源,标签出现次数记为1;如果数据主体已经有了当前标签名称的来源信息,则对原有来源的标签出现次数上加1。
80.可选的,本实施例的大数据标签存储方法还包括:
81.若获取到关于目标标签的第一删除指令,第一删除指令包括待删除标签来源,则从目标主体数据库中将目标标签对应的待删除标签来源删除;
82.判断删除后目标标签是否存在其他标签来源,若是,则保留目标标签的标签编码和标签名称;若否,则将目标标签的标签编码和标签名称删除;
83.可选的,若获取到关于目标标签的第二删除指令,第二删除指令包括待删除标签编码,则从目标主体数据库中将目标标签对应的待删除标签编码、标签名称和标签来源删除。
84.本实施例中,清除标签数据亦是对标签字段的更新,使用painless 脚本实现标签数据的清除。
85.需要说明的是,对比elasticsearch中的update by query方式清除标签方式的优势在于:update by query方式类似于关系型数据库的“set
…ꢀ
where
…”
语句,对大批量数据更新必定会超时导致更新中止,update byquery查询时获取的是快照信息,当多个标签清除操作并行执行时,就会产生版本冲突导致数据更新失败,查询失败时也会导致数据更新中止。本实时例的标签清除逻辑将查询和更新拆分了开来,先根据标签编码和规则id查询要清除标签的数据主键集合,可以在几百毫秒内完成,在要清除标签的数据的主键集合后再执行清除标签的脚本,可以支持几千万的标签数据快速清除,并且不容易出错导致中途停止,规避了update by query的缺陷。
86.参照图5,本实施例还公开了一种大数据标签分析方法,执行的大数据标签存储方法,该分析方法包括:
87.s501、获取待查询数据,待查询数据包括同一待查询对象对应的多个待查询标签名称和维度参数;
88.s502、确定待查询对象对应的待查询主体数据库;
89.s503、根据多个待查询标签名称和维度参数,构造数据分析脚本;
90.s504、利用数据分析脚本在待查询主体数据库中查询,获取数据分析结果。
91.在本实施例中,基于目标标签的数据存储结构,标签数据分析就变得简单得多。不管传入的数据分析参数的个数是多少,又或者是一些标签名称的组合,只需对标签编码tag_code这一个字段进行查询,数据分析脚本整体结构都不用改变,只需传入不同的参数值即可。
92.在一实施例中,参照图6,步骤s503中根据多个待查询标签名称和维度参数,构造数据分析脚本,包括:
93.s601、根据多个待查询标签名称的命中要求情况,确定多个待查询标签名称的查询逻辑关系;其中,查询逻辑关系至少包括and和or逻辑关系;
94.s602、根据待查询主体数据库的内外层逻辑顺序,构造数据查询语法;
95.s603、根据维度参数,构造聚合语法;
96.s604、根据多个待查询标签名称的查询逻辑关系、数据查询语法、聚合语法以及预设的统计算法,构造数据分析脚本。
97.参照图7所示的数据分析脚本,该脚本对上亿的数据标签进行分析,只需几百毫秒就可得到分析结果,分析速度比使用关系型数据库提升了几百倍。
98.在一个具体的实施例中,数据分析方法如图8所示,本数据分析方法的关键在于动态构造数据分析参数的逻辑关系和分析的维度。例如分析疫情中不同病例类型的人员的职业分布情况,得到一份感染人群的分布图,根据不同人员的感染比例分析出哪些人员是高危感染人员。
99.本示例中作为待查询标签名称有五个:“确诊病例”、“疑似病例”、“阳性检测”、“其它病例”、“密接人员”,这五个标签名称都需要精准命中,所以应该使用tag_code不分词搜索,并且设置逻辑关系为“or”,对查询条件取并集。维度参数为职业标签tag_code,对十几类职业进行分组统计,得到每一类人群中符合查询条件的数量,然后计算出占比。
100.区别于现有技术,本实施例通过优化了数据存储结构,极大地降低的数据表的维护成本,提升了目标标签的写入性能和搜索性能,实现了目标标签的全文搜索和快速的数据分析,弥补了标签来源信息记录的缺失,提供了统一的标签数据分析方法,省去了大量的开发工作,降低了工作成本。并满足了用户对标签名称使用中全文检索,毫秒级响应,数据分析和溯源的需求。
101.应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本技术实施例的实施过程构成任何限定。
102.本实施例还提供一种大数据标签存储系统,该大数据标签存储系统与上述实施例中大数据标签存储方法一一对应。如图9所示,该大数据标签存储系统包括创建模块901、获取数据模块902、匹配模块903、存储模块904。各功能模块详细说明如下:
103.获取数据模块901,用于获取数据模块,用于获取目标标签,目标标签包括目标对象和标签名称;
104.匹配模块902,用于根据目标标签的目标对象,从预设的不同特定主体数据库中匹
配出目标主体数据库;
105.存储模块903,用于判断目标标签的标签名称是否存在于目标主体数据库,若否,则按照设定的数据存储结构将目标标签存储于目标主体数据库中。
106.关于大数据标签存储系统各个模块的具体限定可以参见上文中对于大数据标签存储方法的限定,在此不再赘述。上述大数据标签存储系统中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
107.本实施例还提供一种大数据标签分析系统,该大数据标签分析系统与上述实施例中大数据标签分析方法一一对应。如图10所示,该大数据标签分析系统包括获取数据模块1001、确定数据库模块1002、脚本构造模块1003、分析模块1004。各功能模块详细说明如下:
108.获取数据模块1001,用于获取待查询数据,待查询数据包括同一待查询对象对应的多个待查询标签名称和维度参数;
109.确定数据库模块1002,用于确定待查询对象对应的待查询主体数据库;
110.脚本构造模块1003,用于根据多个待查询标签名称和维度参数,构造数据分析脚本;
111.分析模块1004,用于利用数据分析脚本在待查询主体数据库中查询,获取数据分析结果。
112.关于大数据标签分析系统各个模块的具体限定可以参见上文中对于大数据标签分析方法的限定,在此不再赘述。上述大数据标签分析系统中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
113.本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。
114.本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程 rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram (ddrsdram)、增强型sdram(esdram)、同步链路(synchlink) dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram (rdram)等。
115.以上所述,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。