1.本发明涉及重组胶原蛋白、制备方法及其应用,尤其涉及重组表达的全长的胶原蛋白α1链、制备方法及其应用,属于胶原蛋白表达技术领域。
背景技术:
[0002]ⅰ、ⅱ型胶原蛋白是人体内中典型的成纤维胶原蛋白,均由3条α肽链构成,每条α肽链均包含由氨基端肽区、特征性(g-x-y)n三联重复序列区、羧基端肽区三部分。
[0003]ⅰ型胶原蛋白由两条α1链和一条α2链构成,是人体内所含的各种胶原蛋白中最丰富的一种,存在于肌肉、皮肤、动脉壁、纤维软骨中。ⅱ型胶原蛋白由三条α1链构成,主要分布在软骨组织、玻璃体、眼角膜中,占成人软骨基质胶原蛋白总量的90%以上,是软骨和骨型形成、骨骼生长和成熟软骨维持等所必需的成份。
[0004]
作为一种重要的天然生物蛋白,胶原蛋白有良好的生物相容性、生物活性和可降解性等独特功能特征,可广泛应用于化工、医药、食品、化妆品等众多领域,尤其适合制备多种生物器械,是最为理想的生物材料来源,具有广阔的应用前景。
[0005]
市场上销售胶原蛋白主要是利用酸、碱、酶解法处理动物组织获得的胶原提取物:加工过程降解严重,使其生物活性丧失;提取的胶原肽长度不等、性质不均、质量不稳定且有疯牛病、口蹄疫等病毒感染的安全隐患;同时动物源与人的胶原蛋白的氨基酸序列差别较大,属于异源性蛋白,会导致免疫排斥和过敏症状。
[0006]
基因工程技术生产重组胶原蛋白则可有效避免这些缺陷。现有重组胶原蛋白的表达方法中,哺乳动物细胞表达系统、昆虫细胞(杆状病毒)表达系统、转基因动植物等表达系统成本高、产量低、周期长,多用于科研阶实验;大规模工业化生产中主要由原核(大肠杆菌)表达系统、毕赤酵母表达系统来表达人胶原蛋白。大肠杆菌中没有蛋白质的翻译后修饰,大规模表达为胞内表达,需裂解菌体,产生的大量杂质宿主蛋白和天然带有的(细胞壁成分)内毒素、肽聚糖,均需经复杂纯化工艺方能去除。但对于毕赤酵母来说,人胶原蛋白毕竟是一种外源蛋白,表达时会占用较多的细胞内资源(其所依赖的甲醇代谢途径最多可表达细胞可溶性蛋白30%的蛋白),细胞内会针对外源性的蛋白质进行相应调节,典型的状况是重组蛋白会出现严重的降解,人ⅰ、ⅱ型胶原蛋白的α1链均为1000个氨基酸以上的长肽链,更易产生降解。
[0007]
成熟的人ⅰ、ⅱ型胶原蛋白的α1链序列均包含氨基端肽、三螺旋区域、羧基端肽三部分,人ⅰ型胶原蛋白α1链(后文中按规范称之为α1(ⅰ))全长1057aa,人ⅱ型胶原蛋白α1链(后文中按规范称之为α1(ⅱ))全长1060aa。以毕赤酵母表达人α1(ⅰ)链的研究、专利较多,表达人α1(ⅱ)链的研究、专利较少。现有毕赤酵母表达全长α1(ⅰ)链、全长α1(ⅱ)链的成果中,大部分研究中均只表达了α1(ⅰ)链的部分序列,而非成熟的全长α1(ⅰ)链序列。有一些公开的成果中虽然表达了全长的α1(ⅰ)链,但均会于表达时产生与目的产物占比基本相同的主降解产物,于sds-page电泳上表现为一条几乎与全长α1链目的条带(目的产物)占比量基本相当的主降解条带(主降解产物)。这样的降解不但降低表达生产的全长α1链的产量,而
且因其与全长α1链的相关性质接近,想获得高纯度的单一全长α1链产品还需要进行两步双亲和纯化方能获得,增加了纯化艺复杂程度,相应的提高了纯化成本。所以保持全长肽链完整、减少降解,同时保持胶原蛋白生物学活性不发生改变是以毕赤酵母生产重组胶原蛋白面临的重要挑战。
技术实现要素:
[0008]
本发明的目的在于,克服现有技术中存在的一些技术问题,提供毕赤酵母重组表达的全长的胶原蛋白α1链、制备方法及其应用。本发明中的重组人ⅰ型胶原蛋白α1链的变体(记为α1(ⅰ)m1)和重组人ⅱ型胶原蛋白α1链的变体(记为α1(ⅱ)m6),相对于天然全长的α1(ⅰ)链与α1(ⅱ)链,在毕赤酵母中表达时均消除了几乎与全长α1链目的条带(目的产物)占比量基本相同的主降解条带(主降解产物),提高了目的产物的产率;与毕赤酵母表达的天然全长的α1(ⅰ)链胶原蛋白与α1(ⅱ)链胶原蛋白及商品化人胶原蛋白有类似的理化特征和相同的生物学活性,均有应用于生物医学材料领域的价值。
[0009]
为实现上述目的,本发明采用了以下技术方案:
[0010]
本发明提供了重组胶原蛋白α1链,所述重组胶原蛋白α1链为α1(ⅰ)m1或α1(ⅱ)m6,所述α1(ⅰ)m1由人ⅰ型胶原蛋白α1链的天然全长氨基酸序列经过氨基酸突变获得,所述α1(ⅱ)m6由人ⅱ型胶原蛋白α1链天然全长氨基酸序列经过氨基酸突变获得。
[0011]
优选的,所述α1(ⅰ)m1的氨基酸突变的位点数为4;所述α1(ⅱ)m6的氨基酸突变位点数为9。
[0012]
优选的,所述人ⅰ型胶原蛋白α1链为seq.no.id.1所示,所述氨基酸突变的位点为第106位的m、109位的r、190位的m、193位的r,具体的,均改变为p;
[0013]
所述人ⅱ型胶原蛋白的α1链为seq.no.id.4所示,所述氨基酸突变的位点为第67位的v、68位的m、72位的m、75位的m、78位的r、108位的m、111位的r、162位的m、165位的r,具体的,均改变为p。
[0014]
进一步的,所述α1(ⅰ)m1的氨基酸序列如seq.no.id.2所示,所述α1(ⅱ)m6的氨基酸序列如seq.no.id.5所示。
[0015]
本发明中,氨基酸序列突变的位点上相应氨基酸变更的种类发生一些变化,即突变的位点相同,但变更的氨基酸种类不同,也会产生与本专利类似的技术效果;改变其中一处或几处进行突变处理,也有可能获得与本专利类似的技术效果。
[0016]
本发明还提供编码所述重组胶原蛋白α1链的核苷酸,所述编码重组胶原蛋白α1链的核苷酸序列包括编码α1(ⅰ)m1或α1(ⅱ)m6的核苷酸序列。
[0017]
进一步的,所述编码α1(ⅰ)m1和核苷酸序列如seq.no.id.3所示,编码α1(ⅱ)m6的核苷酸序列如seq.no.id.6所示。
[0018]
本发明还提供了重组表达载体,含有编码所述重组胶原蛋白α1链的核苷酸。
[0019]
本发明还提供由上述重组表达载体构建的工程菌,所述工程菌含有所述重组表达载体或表达所述重组胶原蛋白α1链。
[0020]
所述工程菌的宿主菌优选为毕赤酵母,所述工程菌保藏日期为2021年03月11日,保藏编号为cgmcc no.21891或cgmccno.21892,分类命名为巴斯德毕赤酵母pichia pastoris,保藏单位为中国微生物菌种保藏管理委员会普通微生物中心,地址为北京市朝
阳区北辰西路1号院3号。其中保藏编号为cgmcc no.21891的工程菌表达的是重组α1(ⅰ)m1胶原蛋白α1链,保藏编号为cgmcc cgmccno.21892的工程菌表达的是重组α1(ⅱ)m6胶原蛋白α1链。
[0021]
需要说明的是,本发明的宿主菌不限于毕赤酵母,只要根据本发明的方法,于毕赤酵母或其它种类的酵母菌中均可分泌表达,理论上均可获得与本专利类似的技术效果。
[0022]
本发明还提供所述重组表达载体或所述的工程菌在表达所述重组胶原蛋白α1链中的应用。
[0023]
本发明还提供了所述重组胶原蛋白α1链的制备方法,包括:
[0024]
(1)合成编码重组胶原蛋白α1链的核苷酸序列:
[0025]
将天然胶原蛋白α1链序列将其氨基酸序列位点上相应氨基酸进行改变,ⅰ型胶原蛋白的α1链改变4个氨基酸得到α1(ⅰ)m1,ⅱ型胶原蛋白的α1链改变9个氨基酸得到α1(ⅱ)m6;在序列的氨基端和羧基端添加亲和纯化标签,合成编码α1(ⅰ)m1、α1(ⅱ)m6的dna序列,使其含有双特异性亲和纯化标记,这样便于以两种标签序列为基础进行免疫学抗体检测。
[0026]
经检测表明,α1(ⅰ)m1、α1(ⅱ)m6分别消除了全长α1(ⅰ)链、全长α1(ⅱ)链于毕赤酵母中表达时所产生的一条几乎与全长α1链目的条带(目的产物)占比量基本相同的主降解条带(主降解产物)。
[0027]
α1(ⅰ)m1、α1(ⅱ)m6相对天然原始序列,其突变的氨基酸位于特征性的(g-x-y)n三联重复区域,但均是位于x、y上的氨基酸,并没有改变胶原蛋白(g-x-y)n三联重复的氨基酸序列结构特征;且仍保持与原胶原蛋白类似的理化特征和生物学活性。
[0028]
(2)构建重组表达载体:
[0029]
将合成的dna连接入表达载体ppic9k中,分别构建表达重组α1(ⅰ)m1胶原蛋白的ppic9k-col1a1m1和表达重组α1(ⅱ)m6胶原蛋白的ppic9k-col2a1m6两种重组表达载体。
[0030]
(3)构建重组工程菌株、诱导表达和菌株筛选:
[0031]
以sac i线性化重组表达载体,电转入毕赤酵母感受态细胞,转涂至md平板初筛后,再经过含有不同浓度g418的ypd平板筛选,挑取菌落接入bmgy培养基中,再以bmmy培养基诱导表达;筛选表达量高的工程菌株。
[0032]
所述筛选到的表达量高的工程菌为巴斯德毕赤酵母pichia pastoris,保藏编号分别为cgmcc no.21891、cgmcc no.21892。
[0033]
(4)高密度发酵培养:
[0034]
将经过蛋白质表达鉴定表达量高的工程菌,采用发酵罐进行高密度发酵培养。
[0035]
(5)蛋白质纯化:
[0036]
使用一次阳离子交换层析对发酵上清液进行纯化,以冷冻干燥的方法获得纯度高的α1(ⅰ)m1、α1(ⅱ)m6胶原蛋白。
[0037]
本发明中将得到的重组胶原蛋白进行蛋白性质表征和体外实验,对获取的毕赤酵母表达的α1(ⅰ)m1、α1(ⅱ)m6进行分析验证,本发明得到的蛋白符合重组胶原蛋白结构特征,具有细胞粘附活性,与商品化的人胶原蛋白基本一致,更重要的是2种变体蛋白与未突变前的胶原蛋白的结构特征、细胞黏附活性是类似的或相同的。
[0038]
本发明还提供一种组合物,所述组合物包含所述重组胶原蛋白α1链或上述方法制备的胶原蛋白α1链。
[0039]
本发明还提供一种制品,所述制品包含所述重组胶原蛋白α1链或上述方法制备的胶原蛋白α1链或上述组合物。所述制品包括但不局限于药物、药物组合物、医疗器材、生物材料、组织工程产品、化妆品或保健品等。
[0040]
进一步的,所述制品包括为细胞提供黏附、支撑、生长迁移空间的材料或作为输送营养物质与新陈代谢产物通道的材料。
[0041]
进一步的,所述制品为胶原蛋白水凝胶。
[0042]
本发明还提供所述重组胶原蛋白α1链、核苷酸、重组表达载体、工程菌、组合物等在制备制成品中的用途,包括但不限于药物、医疗器材、生物材料、组织工程产品、化妆品或保健品中的用途。
[0043]
本发明还提供所述重组胶原蛋白α1链、核苷酸、重组表达载体、工程菌或组合物在制备促进创伤修复或组织再生的产品中的用途;进一步的,所述产品为胶原蛋白水凝胶。
[0044]
本发明的有益效果:
[0045]
(1)本发明中胶原蛋白α1链变体,改变的氨基酸位点于天然原始序列中占比极少(突变的氨基酸占比低于1%,突变前后氨基酸序列同源性均高于99%)、得到完整的重组α1链胶原蛋白的同时并没有改变原始蛋白本身的性质(理化特性、生物学活性)、并且制备成相关产品的时候与天然序列的重组蛋白有相同的性质、生物学活性等。
[0046]
α1(ⅰ)m1与α1(ⅰ)相比、α1(ⅱ)m6与α1(ⅱ)相比,有类似的理化特征和生物学活性,均有应用于生物医学材料领域的价值。本发明通过进行α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)的细胞粘附实验发现,α1(ⅰ)与α1(ⅰ)m1相比、α1(ⅱ)m6与α1(ⅱ)相比,细胞粘附活性无明显差别,且均与商品化的人胶原蛋白基本一致。使用毕赤酵母表达的α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)胶原蛋白制备胶原蛋白水凝胶,对水凝胶的液体力学特征进行检测,α1(ⅰ)与α1(ⅰ)m1相比、α1(ⅱ)m6与α1(ⅱ)相比,其所制备的水凝胶在黏度、弹性模量、溶胀度上均无明显区别。使用扫描电镜扫描冻干后的胶原蛋白水凝胶,均为多孔网状结构,孔径范围集中于100-200μm,有应用于生物医学材料领域的潜力。将四种胶原蛋白水凝胶与nih/3t3细胞于体外共培养,加入钙黄黄绿am后,可检测到黏附、生长于水凝胶中的发绿色荧光的活细胞;加入mtt检测,均可观察到黏附、迁移生长至水凝胶内部的活细胞形成的蓝紫色结晶。
[0047]
(2)本发明通过sds-page电泳、western blot对表达的蛋白质进行鉴定,结果表明,相对于全长的α1(ⅰ)链与α1(ⅱ)链,α1(ⅰ)m1与α1(ⅱ)m6在毕赤酵母中表达时均消除了几乎与全长α1链目的条带(目的产物)占比量基本相同的主降解条带(主降解产物),提高了目的产物的产率。并且,通过采用发酵罐进行高密度发酵实验,发酵产物经sds-page电泳检测发现,α1(ⅰ)m1、α1(ⅱ)m6可于高密度发酵条件下仍能保持目的条带的完整性,主降解条带依然不会产生,而同样高密度发酵条件下发酵生产的重组人α1(ⅰ)、α1(ⅱ)则会产生明显的主降解条带。
[0048]
并且,本发明的重组胶原蛋白只需要使用一次阳离子交换层析对发酵上清液进行纯化,以冷冻干燥的方法获得纯度高的α1(ⅰ)m1、α1(ⅱ)m6胶原蛋白冻干海绵,经sds-page电泳检测,其主要是作为目的产物的单一条带,无主降解条带,获得了纯度高目的产物,降低了纯化的成本。而α1(ⅰ)、α1(ⅱ)同样以一步阳离子交换层析则只能获得目的条带(目的产物,全长α1链)、主降解条带(主降解产物)混合的纯化蛋白,需要两步亲和层析方能获得纯度高的α1(ⅰ)、α1(ⅱ)胶原蛋白。
附图说明
[0049]
图1为α1(ⅰ)m1与α1(ⅰ)氨基酸序列的差异图,图中灰色背景、加粗的氨基酸所示为差异位点。
[0050]
图2为α1(ⅱ)m6与α1(ⅱ)氨基酸序列的差异图,图中灰色背景、加粗的氨基酸所示为差异位点。
[0051]
图3为ppic9k-col1a1m1载体图谱。
[0052]
图4为ppic9k-col2a1m6载体图谱。
[0053]
图5为α1(ⅰ)m1、α1(ⅱ)m6胶原蛋白诱导表达24h的上清的sds-page图。
[0054]
图6为α1(ⅰ)m1、α1(ⅱ)m6胶原蛋白诱导表达24h的上清的wb图,图中,左边为抗6
×
his tag抗体的wb图,右边为抗strep-tag ii抗体的wb图。
[0055]
图7为α1(ⅰ)、α1(ⅱ)胶原蛋白sds-page检测结果中目的条带、主降解条带质谱分析结果。
[0056]
图8为α1(ⅰ)m1、α1(ⅱ)m6胶原蛋白sds-page检测结果中目的条带质谱分析结果。
[0057]
图9为α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)胶原蛋白诱导48h发酵上清的sds-page图。
[0058]
图10为α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)纯化后冻干海绵的sds-page图。
[0059]
图11为α1(ⅰ)、α1(ⅱ)胶原蛋白傅里叶变换红外光谱(ft-ir)分析图。
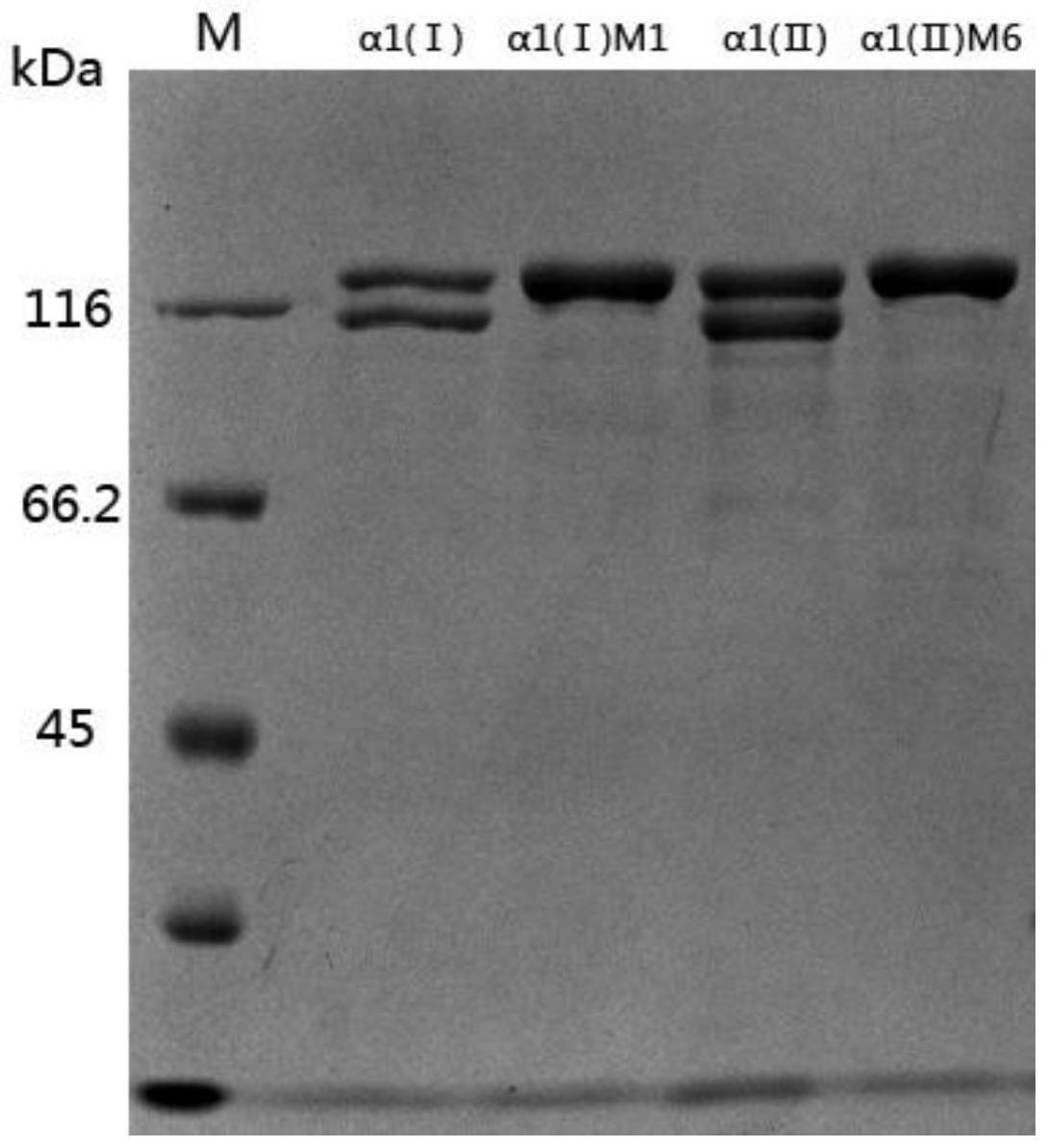
[0060]
图12为α1(ⅰ)m1、α1(ⅱ)m6胶原蛋白傅里叶变换红外光谱(ft-ir)分析图。
[0061]
图13为α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)胶原蛋白细胞黏附活性检测。
[0062]
图14为冻干α1(ⅰ)、α1(ⅰ)m1胶原蛋白水凝胶表面扫描电镜图(上两图α1(ⅰ)胶原蛋白水凝胶,下两图α1(ⅰ)m1胶原蛋白水凝胶)。
[0063]
图15为冻干α1(ⅱ)、α1(ⅱ)m6胶原蛋白水凝胶表面扫描电镜图(上两图α1(ⅱ)胶原蛋白水凝胶,下两图α1(ⅱ)m6胶原蛋白水凝胶)。
[0064]
图16为α1(ⅰ)、α1(ⅰ)m1胶原蛋白水凝胶中nih/3t3细胞黏附生长结果图。
[0065]
图中,上三图从左至右分别为:α1(ⅰ)胶原蛋白水凝胶上黏附生长的nih/3t3细胞(明场显微镜拍摄)、α1(ⅰ)胶原蛋白水凝胶上黏附生长的nih/3t3细胞(钙黄绿素am染色,明亮部分为发绿色荧光的细胞,荧光显微镜拍摄)、α1(ⅰ)胶原蛋白水凝胶中生长的nih/3t3细胞形成的蓝紫色结晶(mtt染色,黑色部分为结晶,明场显微镜拍摄);
[0066]
下三图从左至右分别为:α1(ⅰ)m1胶原蛋白水凝胶上黏附生长的nih/3t3细胞(明场显微镜拍摄)、α1(ⅰ)m1胶原蛋白水凝胶上黏附生长的nih/3t3细胞(钙黄绿素am染色,明亮部分为发绿色荧光的细胞,荧光显微镜拍摄)、α1(ⅰ)m1胶原蛋白水凝胶中生长的nih/3t3细胞形成的蓝紫色结晶(mtt染色,黑色部分为结晶,明场显微镜拍摄)。
[0067]
图17为α1(ⅱ)、α1(ⅱ)m6胶原蛋白水凝胶中nih/3t3细胞黏附生长结果图。
[0068]
图中,上三图从左至右分别为:α1(ⅱ)胶原蛋白水凝胶上黏附生长的nih/3t3细胞(明场显微镜拍摄)、α1(ⅱ)胶原蛋白水凝胶上黏附生长的nih/3t3细胞(钙黄绿素am染色,明亮部分为发绿色荧光的细胞,荧光显微镜拍摄)、α1(ⅱ)胶原蛋白水凝胶中生长的nih/3t3细胞形成的蓝紫色结晶(mtt染色,黑色部分为结晶,明场显微镜拍摄);
[0069]
下三图从左至右分别为:α1(ⅱ)m6胶原蛋白水凝胶上黏附生长的nih/3t3细胞(明场显微镜拍摄)、α1(ⅱ)m6胶原蛋白水凝胶上黏附生长的nih/3t3细胞(钙黄绿素am染色,明
亮部分为发绿色荧光的细胞,荧光显微镜拍摄)、α1(ⅱ)m6胶原蛋白水凝胶中生长的nih/3t3细胞形成的蓝紫色结晶(mtt染色,黑色部分为结晶,明场显微镜拍摄)。
具体实施方式
[0070]
为了使本领域技术人员更好的理解本发明的技术方案,下面对本发明的较佳实施例进行详细的阐述,但是如下实施例并不限制本发明的保护范围。
[0071]
本发明的实施例中,没有多作说明的都是采用常规分子生物学实验方法完成,实施例中所涉及pcr、酶切、连接、密码子优化等过程都是本领域技术人员根据产品说明书或本领域基础知识可以理解并且容易实现的,因此不再详细描述。
[0072]
实施例1.氨基酸序列的设计和合成
[0073]
人ⅰ型胶原蛋白α1链(记为α1(ⅰ))的氨基酸序列参考uniprot数据库p02452-1(https://www.uniprot.org/uniprot/p02452)序列中第162
–
1218部分(pro_0000005720),是成熟形态人ⅰ型胶原蛋白α1链氨基酸序列,不含信号肽、c端前肽、n端前肽等α1(ⅰ)前体蛋白中会加工脱落的部分,其序列如seq.id.no.1所示。
[0074]
seq.id.no.1:
[0075]
qlsygydekstggisvpgpmgpsgprglpgppgapgpqgfqgppgepgepgasgpmgprgppgppgkngddgeagkpgrpgergppgpqgarglpgtaglpgmkghrgfsgldgakgdagpagpkgepgspgengapgqmgprglpgergrpgapgpagargndgatgaagppgptgpagppgfpgavgakgeagpqgprgsegpqgvrgepgppgpagaagpagnpgadgqpgakgangapgiagapgfpgargpsgpqgpggppgpkgnsgepgapgskgdtgakgepgpvgvqgppgpageegkrgargepgptglpgppgerggpgsrgfpgadgvagpkgpagergspgpagpkgspgeagrpgeaglpgakgltgspgspgpdgktgppgpagqdgrpgppgppgargqagvmgfpgpkgaagepgkagergvpgppgavgpagkdgeagaqgppgpagpagergeqgpagspgfqglpgpagppgeagkpgeqgvpgdlgapgpsgargergfpgergvqgppgpagprgangapgndgakgdagapgapgsqgapglqgmpgergaaglpgpkgdrgdagpkgadgspgkdgvrgltgpigppgpagapgdkgesgpsgpagptgargapgdrgepgppgpagfagppgadgqpgakgepgdagakgdagppgpagpagppgpignvgapgakgargsagppgatgfpgaagrvgppgpsgnagppgppgpagkeggkgprgetgpagrpgevgppgppgpagekgspgadgpagapgtpgpqgiagqrgvvglpgqrgergfpglpgpsgepgkqgpsgasgergppgpmgppglagppgesgregapgaegspgrdgspgakgdrgetgpagppgapgapgapgpvgpagksgdrgetgpagpagpvgpvgargpagpqgprgdkgetgeqgdrgikghrgfsglqgppgppgspgeqgpsgasgpagprgppgsagapgkdglnglpgpigppgprgrtgdagpvgppgppgppgppgppsagfdfsflpqppqekahdggryyra
[0076]
经过长期的实验研究,获得了重组人ⅰ型胶原蛋白α1链的变体,记为α1(ⅰ)m1。α1(ⅰ)m1相对于α1(ⅰ)氨基酸序列中改变4个氨基酸,将这4个氨基酸突变为脯氨酸(pro,简写为p),在seq.no.id.1所示的氨基酸序列第106位的m、109位的r、190位的m、193位的r,均改变为p;其余部分的氨基酸序列不变。α1(ⅰ)m1与α1(ⅰ)的同源性为99.6%。
[0077]
改变后的氨基酸序列(α1(ⅰ)m1)全长1057aa,序列如seq.id.no.2所示。
[0078]
seq.id.no.2:
[0079]
qlsygydekstggisvpgpmgpsgprglpgppgapgpqgfqgppgepgepgasgppgppgppgppgkngddgeagkpgrpgergppgpqgarglpgtaglpgmkghrgfsgldgakgdagpagpkgepgspgengapgqpgppglpgergrpgapgpagargndgatgaagppgptgpagppgfpgavgakgeagpqgprgsegpqgvrgepgppgpagaagpagnpgadgqpgakgangapgiagapgfpgargpsgpqgpggppgpkgnsgepgapgskgdtgakgepgpvgvqgppg
pageegkrgargepgptglpgppgerggpgsrgfpgadgvagpkgpagergspgpagpkgspgeagrpgeaglpgakgltgspgspgpdgktgppgpagqdgrpgppgppgargqagvmgfpgpkgaagepgkagergvpgppgavgpagkdgeagaqgppgpagpagergeqgpagspgfqglpgpagppgeagkpgeqgvpgdlgapgpsgargergfpgergvqgppgpagprgangapgndgakgdagapgapgsqgapglqgmpgergaaglpgpkgdrgdagpkgadgspgkdgvrgltgpigppgpagapgdkgesgpsgpagptgargapgdrgepgppgpagfagppgadgqpgakgepgdagakgdagppgpagpagppgpignvgapgakgargsagppgatgfpgaagrvgppgpsgnagppgppgpagkeggkgprgetgpagrpgevgppgppgpagekgspgadgpagapgtpgpqgiagqrgvvglpgqrgergfpglpgpsgepgkqgpsgasgergppgpmgppglagppgesgregapgaegspgrdgspgakgdrgetgpagppgapgapgapgpvgpagksgdrgetgpagpagpvgpvgargpagpqgprgdkgetgeqgdrgikghrgfsglqgppgppgspgeqgpsgasgpagprgppgsagapgkdglnglpgpigppgprgrtgdagpvgppgppgppgppgppsagfdfsflpqppqekahdggryyra
[0080]
α1(ⅰ)m1与α1(ⅰ)氨基酸序列的差异如图1中灰色背景、加粗的氨基酸所示。
[0081]
编码seq.id.no.2所示的α1(1)m1的基因(记为col1a1m1)dna序列如seq.id.no.3所示:
[0082]
seq.id.no.3:
[0083]
caacttagttatggatacgatgaaaaatccacaggtggaatcagtgttcctggacctatgggtccatcaggtccaagaggtttaccaggacctccaggtgccccaggtccccagggatttcaaggtccaccaggagagcctggtgagccaggagcttctggtccacctggtccccctggaccacctggtcctccaggaaagaatggagatgatggtgaagctggaaaacctggaagacctggagaaagaggaccaccaggaccccagggtgccagaggactgccaggtaccgcaggtctgcctggaatgaaaggtcatagaggattttcaggattagacggtgcaaagggagacgctggacctgcaggaccaaagggtgagccaggaagtccaggagagaatggtgcaccaggacagccaggtccacctggactgcccggtgaaagaggtagacccggagcaccaggaccagcaggtgcaagaggaaatgatggagctacaggtgctgcaggacccccaggtccaacaggaccagccggtcctcccggtttcccaggtgccgttggagcaaaaggtgaagctggtccacagggtccaagaggttctgaaggtccacagggagttagaggagaaccaggaccccctggaccagctggtgcagcaggaccagctggtaaccctggtgctgacggtcagccaggtgctaagggagcaaatggagcaccaggaatagctggtgccccaggatttcccggtgctagaggtccaagtggtccacaaggaccaggaggtccacccggtcccaaaggaaacagtggagaaccaggtgcacccggttcaaagggagatacaggagctaaaggagagcccggtccagtgggtgttcagggaccacccggacctgctggagaggaaggtaaaagaggtgcaagaggtgagccaggaccaacaggtctgcctggtccccctggtgaaagaggtggtccaggtagtagaggatttccaggagctgatggtgttgcaggaccaaagggacccgcaggtgagagaggatcacccggtccagccggaccaaaaggatcaccaggagaagctggtagaccaggagaagctggtctgccaggtgctaaaggattgacaggatcacccggttcacctggtcctgatggaaagacaggacctccaggtcccgctggtcaggacggtagaccaggacccccaggacccccaggtgcaagaggtcaggcaggtgtaatgggtttccccggacctaaaggagcagctggagaacctggtaaagctggagagagaggagtgcctggaccccctggagctgttggtccagcaggaaaggatggtgaggcaggtgcacaaggtccacctggacccgctggacctgcaggtgagagaggagagcaaggtcccgcaggttctccaggttttcagggtttgccaggtccagccggtcctcctggagaggcaggaaagccaggagaacaaggagttccaggagacctgggtgcaccaggaccctctggtgcaagaggagagagaggatttcctggagaaagaggtgtgcagggaccaccaggtcccgccggtccaagaggagcaaatggagcccctggaaatgacggagctaagggtgacgctggtgcaccaggagcaccaggttctcaaggtgctcccggattgcagggtatgcctggagagagaggtgcagctggactgccaggtccaaaaggtgacagaggagacgccggtcctaagggagctgacggttctcctggaaaggacggtgtgagaggtttgacaggaccaataggtccacccggtcctgctggagcccctggagacaaaggtgaatcaggtccttccggtccagccggaccaacaggagcaagaggagcacctgga
gacagaggagagccaggtcctccaggacctgcaggtttcgctggtcctcccggagcagatggacagccaggagctaagggagaacccggtgacgctggtgctaagggagatgcaggtccaccaggtcctgctggtcctgctggacctcccggaccaataggtaatgttggagcacccggagcaaaaggtgccagaggttccgcaggtcctcccggagcaactggttttccaggagctgccggaagagtgggtccacctggtccttctggaaatgcaggaccaccaggtcctcctggtccagccggaaaggaaggtggaaagggacctagaggagaaacaggtcccgcaggtagacccggtgaggtgggtccacctggtccacccggtccagctggtgagaaaggaagtcctggagcagacggaccagctggtgcccctggtacaccaggaccccaaggaatagctggtcaaagaggtgttgttggtttaccaggtcagagaggagaaagaggttttccaggattaccaggtccctcaggtgagcccggaaaacagggtccctcaggagcaagtggtgaaagaggaccaccaggaccaatgggacctccaggattagctggtccaccaggagaatcaggaagagagggtgctcctggagcagaaggttcaccaggaagagacggttcacccggagccaagggagacagaggtgaaacaggtcccgcaggtccaccaggagcacccggagcccctggtgctccaggacctgtcggaccagcaggaaaatccggtgacagaggtgagactggacccgcaggtcctgctggtcctgttggaccagtgggtgcaagaggaccagcaggtccacaaggtccaagaggtgacaaaggtgagacaggtgagcagggtgacagaggaattaaaggtcacagaggattttcaggactgcagggaccacccggtcctcccggttccccaggagagcaaggtccatccggtgcatccggtccagctggacccagaggaccacctggttctgctggtgcaccaggtaaagatggattgaacggtttgcctggtccaataggacctcctggtccaagaggaagaactggtgacgccggtcccgtcggaccacccggtccaccaggtcccccaggtccacccggaccaccatccgcaggatttgatttctcattccttcctcaacctcctcaagagaaagcacatgatggaggtagatactatagagcc
[0084]
人ⅱ型胶原蛋白α1链(记为α1(ⅱ))的氨基酸序列参uniprot数据库p02458(https://www.uniprot.org/uniprot/p02458)序列中第182
–
1241部分(pro_0000005730)是成熟形态人ⅱ型胶原蛋白α1链氨基酸序列,不含信号肽、c端前肽、n端前肽等α1(ⅱ)前体蛋白中加工脱落的部分,其序列如seq.id.no.4所示:
[0085]
seq.id.no.4:
[0086]
qmaggfdekaggaqlgvmqgpmgpmgprgppgpagapgpqgfqgnpgepgepgvsgpmgprgppgppgkpgddgeagkpgkagergppgpqgargfpgtpglpgvkghrgypgldgakgeagapgvkgesgspgengspgpmgprglpgergrtgpagaagargndgqpgpagppgpvgpaggpgfpgapgakgeagptgargpegaqgprgepgtpgspgpagasgnpgtdgipgakgsagapgiagapgfpgprgppgpqgatgplgpkgqtgepgiagfkgeqgpkgepgpagpqgapgpageegkrgargepggvgpigppgergapgnrgfpgqdglagpkgapgergpsglagpkgangdpgrpgepglpgargltgrpgdagpqgkvgpsgapgedgrpgppgpqgargqpgvmgfpgpkgangepgkagekglpgapglrglpgkdgetgaagppgpagpagergeqgapgpsgfqglpgppgppgeggkpgdqgvpgeagapglvgprgergfpgergspgaqglqgprglpgtpgtdgpkgasgpagppgaqgppglqgmpgergaagiagpkgdrgdvgekgpegapgkdggrgltgpigppgpagangekgevgppgpagsagargapgergetgppgpagfagppgadgqpgakgeqgeagqkgdagapgpqgpsgapgpqgptgvtgpkgargaqgppgatgfpgaagrvgppgsngnpgppgppgpsgkdgpkgargdsgppgragepglqgpagppgekgepgddgpsgaegppgpqglagqrgivglpgqrgergfpglpgpsgepgkqgapgasgdrgppgpvgppgltgpagepgregspgadgppgrdgaagvkgdrgetgavgapgapgppgspgpagptgkqgdrgeagaqgpmgpsgpagargiqgpqgprgdkgeagepgerglkghrgftglqglpgppgpsgdqgasgpagpsgprgppgpvgpsgkdgangipgpigppgprgrsgetgpagppgnpgppgppgppgpgidmsafaglgprekgpdplqymra
[0087]
经过长期的实验研究,获得重组人ⅱ型胶原蛋白α1链的变体,记为α1(ⅱ)m6。α1(ⅱ)m6于α1(ⅱ)的氨基酸序列中改变9个氨基酸,将这9个氨基酸突变为脯氨酸(pro,简写为p),在seq.no.id.4所示的氨基酸序列第67位的v、68位的m、72位的m、75位的m、78位的r、
108位的m、111位的r、162位的m、165位的r,均改变为p;其余部分的氨基酸序列不变,α1(ⅱ)m6与α1(ⅱ)的同源性为99.2%。
[0088]
改变后的序列(α1(ⅱ)m6)全长1060aa,序列如seq.id.no.5所示:
[0089]
seq.id.no.5:
[0090]
qmaggfdekaggaqlgppqgppgppgppgppgpagapgpqgfqgnpgepgepgvsgppgppgppgppgkpgddgeagkpgkagergppgpqgargfpgtpglpgvkghrgypgldgakgeagapgvkgesgspgengspgppgppglpgergrtgpagaagargndgqpgpagppgpvgpaggpgfpgapgakgeagptgargpegaqgprgepgtpgspgpagasgnpgtdgipgakgsagapgiagapgfpgprgppgpqgatgplgpkgqtgepgiagfkgeqgpkgepgpagpqgapgpageegkrgargepggvgpigppgergapgnrgfpgqdglagpkgapgergpsglagpkgangdpgrpgepglpgargltgrpgdagpqgkvgpsgapgedgrpgppgpqgargqpgvmgfpgpkgangepgkagekglpgapglrglpgkdgetgaagppgpagpagergeqgapgpsgfqglpgppgppgeggkpgdqgvpgeagapglvgprgergfpgergspgaqglqgprglpgtpgtdgpkgasgpagppgaqgppglqgmpgergaagiagpkgdrgdvgekgpegapgkdggrgltgpigppgpagangekgevgppgpagsagargapgergetgppgpagfagppgadgqpgakgeqgeagqkgdagapgpqgpsgapgpqgptgvtgpkgargaqgppgatgfpgaagrvgppgsngnpgppgppgpsgkdgpkgargdsgppgragepglqgpagppgekgepgddgpsgaegppgpqglagqrgivglpgqrgergfpglpgpsgepgkqgapgasgdrgppgpvgppgltgpagepgregspgadgppgrdgaagvkgdrgetgavgapgapgppgspgpagptgkqgdrgeagaqgpmgpsgpagargiqgpqgprgdkgeagepgerglkghrgftglqglpgppgpsgdqgasgpagpsgprgppgpvgpsgkdgangipgpigppgprgrsgetgpagppgnpgppgppgppgpgidmsafaglgprekgpdplqymra
[0091]
α1(ⅱ)m6与α1(ⅱ)氨基酸序列的差异如图2中灰色背景和加粗的氨基酸所示。
[0092]
编码seq.id.no.5所示的α1(ⅱ)m6的基因(记为col2a1m6)dna序列如seq.id.no.6所示:
[0093]
seq.id.no.6:
[0094]
caaatggctggtggattcgatgaaaaggctggtggagcccaattaggtcctccacaaggtcctcccggtccacctggtcctcccggtcctccaggtcccgccggtgctcctggaccacagggtttccaaggaaaccccggtgaaccaggtgagcctggtgtttcaggtcctcccggtcctccaggaccacctggaccaccaggaaagcctggtgacgacggagaagctggtaaaccaggaaaggcaggagagagaggtccacctggacctcagggtgccagaggtttcccaggtacccctggtcttcctggtgtcaagggtcatagaggttaccccggtttggatggtgccaagggtgaagccggtgcccctggtgttaagggtgaatcaggaagtcccggtgaaaatggaagtcccggtccacccggtccacctggactgccaggtgagagaggaagaaccggaccagctggtgctgcaggtgctagaggaaatgacggacagcccggaccagccggacctcccggtcctgttgggcccgcaggtggtcctggtttccctggtgctcctggagccaaaggagaagccggacccaccggagccagaggtcccgagggagcacagggacctagaggagaaccaggtacaccaggtagtcccggtcctgctggtgcatcaggaaatcccggaactgacggtattccaggagcaaagggatctgcaggagcaccaggaatagctggtgctcctggatttccaggtcccagaggacctcccggtcctcaaggagcaacaggtcctttgggaccaaaaggtcaaacaggagaaccaggtattgctggattcaaaggagagcaaggtccaaagggagagcccggtcccgcaggtccccaaggagccccaggaccagctggtgaagaaggaaaaagaggagccagaggtgaacctggaggagtaggacctattggtcctcctggtgagagaggtgctcccggaaacagaggttttcctggtcaagatggtctggctggacctaaaggtgctccaggagagagaggaccttcaggacttgctggtccaaaaggtgctaacggagatccaggaagacccggtgaacctggtctgcctggagctagaggattaacaggaagaccaggtgacgcaggtccccagggtaaagtgggtcccagtggtgccccaggtgaagatggaagacctggtcctcccggaccccaaggtgcaagaggtcagcctggagtgatgggatttcctggacccaagggtgctaacgga
gaacctggaaaagctggtgagaaaggactgcccggtgccccaggtcttagaggtttgccaggtaaagatggagaaacaggagccgcaggaccacccggtccagccggaccagcaggagagagaggtgaacaaggagcacctggtccaagtggttttcagggtcttccaggtccccctggtccaccaggagagggaggtaaaccaggtgaccaaggtgtccctggagaagcaggtgcacccggtcttgtgggtccaagaggtgaaagaggattccctggtgagagaggatctcccggagcccagggacttcaaggtcctagaggtctgccaggtacccctggtacagacggaccaaagggagcatcaggacccgctggacctcccggagcccaaggtcctccaggtttacaaggtatgcctggtgaaagaggtgctgcaggtatagctggaccaaaaggagacagaggtgacgttggtgagaagggtcccgaaggagcccctggaaaagatggtggaagaggattaacaggtcctataggaccacccggtccagccggtgctaatggagaaaaaggagaagtaggtcctccaggtccagcaggatctgcaggtgctagaggtgcccctggagagagaggtgaaacaggaccacctggtccagctggtttcgctggtcccccaggagctgatggacagcccggtgcaaaaggtgaacaaggagaagccggacagaagggagatgctggagcccccggtccacaaggtccctcaggagcaccaggtcctcaaggtccaactggtgtgaccgggccaaagggtgcaagaggagcacagggacctccaggagcaacaggtttcccaggagctgctggtagagtcggtccacccggatctaatggtaaccccggaccaccaggaccacctggaccatctggaaaggatggacccaaaggagcaagaggagattcaggaccacccggaagagcaggagaacctggattacagggtcccgccggtccaccaggagagaaaggagagcccggagatgatggtccctcaggtgcagagggacccccaggaccccaaggtctggcaggtcaaagaggtatagtgggtcttccaggtcaaagaggtgaaagaggatttccaggacttccaggtccttcaggtgaacccggtaaacagggagcccccggagcctcaggtgacagaggtcctccaggaccagtaggacccccaggtttaaccggaccagcaggtgagccaggaagagaaggttctcctggagccgatggacctccaggaagagacggtgcagctggtgttaagggtgacagaggtgaaactggagccgtaggagccccaggtgcccccggaccacccggatcacccggacctgcaggtcctactggtaaacaaggagatagaggagaagccggtgcccagggtcctatgggtccttctggtcctgcaggagcaagaggtatacaaggtccacagggtcccagaggtgacaagggtgaagcaggagaacccggtgagagaggtctgaagggtcatagaggattcaccgggttacagggtttgccaggaccccctggaccaagtggtgaccagggtgcatccggtccagcaggtccttctggaccaagaggtcctcccggtccagttggtccatcaggtaaagacggagccaacggtatcccaggtcccatcggtcctccaggtcctagaggaagaagtggagagactggtcctgctggacctcctggaaaccctggtcctccaggacctccaggtcctccaggtcccggaatagatatgtccgctttcgctggattgggaccaagagagaaaggtcctgaccctcttcaatatatgagagca
[0095]
在编码α1(ⅰ)m1的dna序列两端分别修饰添加氨基端添加编码strep-tag ii标签的dna序列、羧基端添加编码6
×
his tag标签的dna序列后,α1(ⅰ)m1最终表达获得的是含有标签的蛋白,共1071个氨基酸,如seq.id.no.7所示:
[0096]
seq.id.no.7:
[0097]
wshpqfekqlsygydekstggisvpgpmgpsgprglpgppgapgpqgfqgppgepgepgasgppgppgppgppgkngddgeagkpgrpgergppgpqgarglpgtaglpgmkghrgfsgldgakgdagpagpkgepgspgengapgqpgppglpgergrpgapgpagargndgatgaagppgptgpagppgfpgavgakgeagpqgprgsegpqgvrgepgppgpagaagpagnpgadgqpgakgangapgiagapgfpgargpsgpqgpggppgpkgnsgepgapgskgdtgakgepgpvgvqgppgpageegkrgargepgptglpgppgerggpgsrgfpgadgvagpkgpagergspgpagpkgspgeagrpgeaglpgakgltgspgspgpdgktgppgpagqdgrpgppgppgargqagvmgfpgpkgaagepgkagergvpgppgavgpagkdgeagaqgppgpagpagergeqgpagspgfqglpgpagppgeagkpgeqgvpgdlgapgpsgargergfpgergvqgppgpagprgangapgndgakgdagapgapgsqgapglqgmpgergaaglpgpkgdrgdagpkgadgspgkdgvrgltgpigppgpagapgdkgesgpsgpagptgargapgdrgepgppgpagfagppgadgqpgakgepgdagakgdagppgpagpagppgpignvgapgakgargsagppgatgfpgaagrvgppgpsgnagppgppgpagkeggkgprgetgp
agrpgevgppgppgpagekgspgadgpagapgtpgpqgiagqrgvvglpgqrgergfpglpgpsgepgkqgpsgasgergppgpmgppglagppgesgregapgaegspgrdgspgakgdrgetgpagppgapgapgapgpvgpagksgdrgetgpagpagpvgpvgargpagpqgprgdkgetgeqgdrgikghrgfsglqgppgppgspgeqgpsgasgpagprgppgsagapgkdglnglpgpigppgprgrtgdagpvgppgppgppgppgppsagfdfsflpqppqekahdggryyrahhhhhh
[0098]
经过优化设计后,编码seq.id.no.7氨基酸序列(α1(ⅰ)m1)的基因(记为col1a1m1)的dna序列如seq.id.no.8所示:
[0099]
seq.id.no.8:
[0100]
tggtctcatccacaatttgaaaagcaacttagttatggatacgatgaaaaatccacaggtggaatcagtgttcctggacctatgggtccatcaggtccaagaggtttaccaggacctccaggtgccccaggtccccagggatttcaaggtccaccaggagagcctggtgagccaggagcttctggtccacctggtccccctggaccacctggtcctccaggaaagaatggagatgatggtgaagctggaaaacctggaagacctggagaaagaggaccaccaggaccccagggtgccagaggactgccaggtaccgcaggtctgcctggaatgaaaggtcatagaggattttcaggattagacggtgcaaagggagacgctggacctgcaggaccaaagggtgagccaggaagtccaggagagaatggtgcaccaggacagccaggtccacctggactgcccggtgaaagaggtagacccggagcaccaggaccagcaggtgcaagaggaaatgatggagctacaggtgctgcaggacccccaggtccaacaggaccagccggtcctcccggtttcccaggtgccgttggagcaaaaggtgaagctggtccacagggtccaagaggttctgaaggtccacagggagttagaggagaaccaggaccccctggaccagctggtgcagcaggaccagctggtaaccctggtgctgacggtcagccaggtgctaagggagcaaatggagcaccaggaatagctggtgccccaggatttcccggtgctagaggtccaagtggtccacaaggaccaggaggtccacccggtcccaaaggaaacagtggagaaccaggtgcacccggttcaaagggagatacaggagctaaaggagagcccggtccagtgggtgttcagggaccacccggacctgctggagaggaaggtaaaagaggtgcaagaggtgagccaggaccaacaggtctgcctggtccccctggtgaaagaggtggtccaggtagtagaggatttccaggagctgatggtgttgcaggaccaaagggacccgcaggtgagagaggatcacccggtccagccggaccaaaaggatcaccaggagaagctggtagaccaggagaagctggtctgccaggtgctaaaggattgacaggatcacccggttcacctggtcctgatggaaagacaggacctccaggtcccgctggtcaggacggtagaccaggacccccaggacccccaggtgcaagaggtcaggcaggtgtaatgggtttccccggacctaaaggagcagctggagaacctggtaaagctggagagagaggagtgcctggaccccctggagctgttggtccagcaggaaaggatggtgaggcaggtgcacaaggtccacctggacccgctggacctgcaggtgagagaggagagcaaggtcccgcaggttctccaggttttcagggtttgccaggtccagccggtcctcctggagaggcaggaaagccaggagaacaaggagttccaggagacctgggtgcaccaggaccctctggtgcaagaggagagagaggatttcctggagaaagaggtgtgcagggaccaccaggtcccgccggtccaagaggagcaaatggagcccctggaaatgacggagctaagggtgacgctggtgcaccaggagcaccaggttctcaaggtgctcccggattgcagggtatgcctggagagagaggtgcagctggactgccaggtccaaaaggtgacagaggagacgccggtcctaagggagctgacggttctcctggaaaggacggtgtgagaggtttgacaggaccaataggtccacccggtcctgctggagcccctggagacaaaggtgaatcaggtccttccggtccagccggaccaacaggagcaagaggagcacctggagacagaggagagccaggtcctccaggacctgcaggtttcgctggtcctcccggagcagatggacagccaggagctaagggagaacccggtgacgctggtgctaagggagatgcaggtccaccaggtcctgctggtcctgctggacctcccggaccaataggtaatgttggagcacccggagcaaaaggtgccagaggttccgcaggtcctcccggagcaactggttttccaggagctgccggaagagtgggtccacctggtccttctggaaatgcaggaccaccaggtcctcctggtccagccggaaaggaaggtggaaagggacctagaggagaaacaggtcccgcaggtagacccggtgaggtgggtccacctggtccacccggtccagctggtgagaaaggaagtcctggagcagacggaccagctggtgcccct
ggtacaccaggaccccaaggaatagctggtcaaagaggtgttgttggtttaccaggtcagagaggagaaagaggttttccaggattaccaggtccctcaggtgagcccggaaaacagggtccctcaggagcaagtggtgaaagaggaccaccaggaccaatgggacctccaggattagctggtccaccaggagaatcaggaagagagggtgctcctggagcagaaggttcaccaggaagagacggttcacccggagccaagggagacagaggtgaaacaggtcccgcaggtccaccaggagcacccggagcccctggtgctccaggacctgtcggaccagcaggaaaatccggtgacagaggtgagactggacccgcaggtcctgctggtcctgttggaccagtgggtgcaagaggaccagcaggtccacaaggtccaagaggtgacaaaggtgagacaggtgagcagggtgacagaggaattaaaggtcacagaggattttcaggactgcagggaccacccggtcctcccggttccccaggagagcaaggtccatccggtgcatccggtccagctggacccagaggaccacctggttctgctggtgcaccaggtaaagatggattgaacggtttgcctggtccaataggacctcctggtccaagaggaagaactggtgacgccggtcccgtcggaccacccggtccaccaggtcccccaggtccacccggaccaccatccgcaggatttgatttctcattccttcctcaacctcctcaagagaaagcacatgatggaggtagatactatagagcccatcaccaccatcatcattaa
[0101]
在编码α1(ⅱ)m6的dna序列两端分别修饰添加氨基端添加编码strep-tag ii标签的dna序列、羧基端添加编码6
×
his tag标签的dna序列后,α1(ⅱ)m6最终表达获得的是含有标签的蛋白,共1076个氨基酸,序列如seq.id.no.9所示:
[0102]
seq.id.no.9:
[0103]
efwshpqfekqmaggfdekaggaqlgppqgppgppgppgppgpagapgpqgfqgnpgepgepgvsgppgppgppgppgkpgddgeagkpgkagergppgpqgargfpgtpglpgvkghrgypgldgakgeagapgvkgesgspgengspgppgppglpgergrtgpagaagargndgqpgpagppgpvgpaggpgfpgapgakgeagptgargpegaqgprgepgtpgspgpagasgnpgtdgipgakgsagapgiagapgfpgprgppgpqgatgplgpkgqtgepgiagfkgeqgpkgepgpagpqgapgpageegkrgargepggvgpigppgergapgnrgfpgqdglagpkgapgergpsglagpkgangdpgrpgepglpgargltgrpgdagpqgkvgpsgapgedgrpgppgpqgargqpgvmgfpgpkgangepgkagekglpgapglrglpgkdgetgaagppgpagpagergeqgapgpsgfqglpgppgppgeggkpgdqgvpgeagapglvgprgergfpgergspgaqglqgprglpgtpgtdgpkgasgpagppgaqgppglqgmpgergaagiagpkgdrgdvgekgpegapgkdggrgltgpigppgpagangekgevgppgpagsagargapgergetgppgpagfagppgadgqpgakgeqgeagqkgdagapgpqgpsgapgpqgptgvtgpkgargaqgppgatgfpgaagrvgppgsngnpgppgppgpsgkdgpkgargdsgppgragepglqgpagppgekgepgddgpsgaegppgpqglagqrgivglpgqrgergfpglpgpsgepgkqgapgasgdrgppgpvgppgltgpagepgregspgadgppgrdgaagvkgdrgetgavgapgapgppgspgpagptgkqgdrgeagaqgpmgpsgpagargiqgpqgprgdkgeagepgerglkghrgftglqglpgppgpsgdqgasgpagpsgprgppgpvgpsgkdgangipgpigppgprgrsgetgpagppgnpgppgppgppgpgidmsafaglgprekgpdplqymrahhhhhh
[0104]
经过优化设计后,编码seq.id.no.10(α1(ⅱ)m6)氨基酸序列的基因(记为col2a1m6)的dna序列如seq.id.no.10所示:
[0105]
seq.id.no.10:
[0106]
gaattctggagtcatcctcaattcgaaaaacaaatggctggtggattcgatgaaaaggctggtggagcccaattaggtcctccacaaggtcctcccggtccacctggtcctcccggtcctccaggtcccgccggtgctcctggaccacagggtttccaaggaaaccccggtgaaccaggtgagcctggtgtttcaggtcctcccggtcctccaggaccacctggaccaccaggaaagcctggtgacgacggagaagctggtaaaccaggaaaggcaggagagagaggtccacctggacctcagggtgccagaggtttcccaggtacccctggtcttcctggtgtcaagggtcatagaggttaccccggtttggatggtgccaagggtgaagccggtgcccctggtgttaagggtgaatcaggaagtcccggtgaaaatggaagtcccg
gtccacccggtccacctggactgccaggtgagagaggaagaaccggaccagctggtgctgcaggtgctagaggaaatgacggacagcccggaccagccggacctcccggtcctgttgggcccgcaggtggtcctggtttccctggtgctcctggagccaaaggagaagccggacccaccggagccagaggtcccgagggagcacagggacctagaggagaaccaggtacaccaggtagtcccggtcctgctggtgcatcaggaaatcccggaactgacggtattccaggagcaaagggatctgcaggagcaccaggaatagctggtgctcctggatttccaggtcccagaggacctcccggtcctcaaggagcaacaggtcctttgggaccaaaaggtcaaacaggagaaccaggtattgctggattcaaaggagagcaaggtccaaagggagagcccggtcccgcaggtccccaaggagccccaggaccagctggtgaagaaggaaaaagaggagccagaggtgaacctggaggagtaggacctattggtcctcctggtgagagaggtgctcccggaaacagaggttttcctggtcaagatggtctggctggacctaaaggtgctccaggagagagaggaccttcaggacttgctggtccaaaaggtgctaacggagatccaggaagacccggtgaacctggtctgcctggagctagaggattaacaggaagaccaggtgacgcaggtccccagggtaaagtgggtcccagtggtgccccaggtgaagatggaagacctggtcctcccggaccccaaggtgcaagaggtcagcctggagtgatgggatttcctggacccaagggtgctaacggagaacctggaaaagctggtgagaaaggactgcccggtgccccaggtcttagaggtttgccaggtaaagatggagaaacaggagccgcaggaccacccggtccagccggaccagcaggagagagaggtgaacaaggagcacctggtccaagtggttttcagggtcttccaggtccccctggtccaccaggagagggaggtaaaccaggtgaccaaggtgtccctggagaagcaggtgcacccggtcttgtgggtccaagaggtgaaagaggattccctggtgagagaggatctcccggagcccagggacttcaaggtcctagaggtctgccaggtacccctggtacagacggaccaaagggagcatcaggacccgctggacctcccggagcccaaggtcctccaggtttacaaggtatgcctggtgaaagaggtgctgcaggtatagctggaccaaaaggagacagaggtgacgttggtgagaagggtcccgaaggagcccctggaaaagatggtggaagaggattaacaggtcctataggaccacccggtccagccggtgctaatggagaaaaaggagaagtaggtcctccaggtccagcaggatctgcaggtgctagaggtgcccctggagagagaggtgaaacaggaccacctggtccagctggtttcgctggtcccccaggagctgatggacagcccggtgcaaaaggtgaacaaggagaagccggacagaagggagatgctggagcccccggtccacaaggtccctcaggagcaccaggtcctcaaggtccaactggtgtgaccgggccaaagggtgcaagaggagcacagggacctccaggagcaacaggtttcccaggagctgctggtagagtcggtccacccggatctaatggtaaccccggaccaccaggaccacctggaccatctggaaaggatggacccaaaggagcaagaggagattcaggaccacccggaagagcaggagaacctggattacagggtcccgccggtccaccaggagagaaaggagagcccggagatgatggtccctcaggtgcagagggacccccaggaccccaaggtctggcaggtcaaagaggtatagtgggtcttccaggtcaaagaggtgaaagaggatttccaggacttccaggtccttcaggtgaacccggtaaacagggagcccccggagcctcaggtgacagaggtcctccaggaccagtaggacccccaggtttaaccggaccagcaggtgagccaggaagagaaggttctcctggagccgatggacctccaggaagagacggtgcagctggtgttaagggtgacagaggtgaaactggagccgtaggagccccaggtgcccccggaccacccggatcacccggacctgcaggtcctactggtaaacaaggagatagaggagaagccggtgcccagggtcctatgggtccttctggtcctgcaggagcaagaggtatacaaggtccacagggtcccagaggtgacaagggtgaagcaggagaacccggtgagagaggtctgaagggtcatagaggattcaccgggttacagggtttgccaggaccccctggaccaagtggtgaccagggtgcatccggtccagcaggtccttctggaccaagaggtcctcccggtccagttggtccatcaggtaaagacggagccaacggtatcccaggtcccatcggtcctccaggtcctagaggaagaagtggagagactggtcctgctggacctcctggaaaccctggtcctccaggacctccaggtcctccaggtcccggaatagatatgtccgctttcgctggattgggaccaagagagaaaggtcctgaccctcttcaatatatgagagcacaccatcaccatcatcactaa
[0107]
dna序列的合成委托南京金斯瑞生物科技股份有限公司完成,合成seq.id.no.8、seq.id.no.10两种基因的dna片段。
[0108]
实施例2.重组表达载体的构建、菌种筛选
[0109]
(1)重组表达载体的构建
[0110]
将合成后的基因片段seq.id.no.8、seq.id.no.10重组至ppic9k空载体(购自赛默飞世尔科技公司)中,使目的片段准确插入到含有分泌信号α-因子的分泌型载体读码框内,获得表达α1(ⅱ)m6的ppic9k-col2a1m6和表达α1(ⅰ)m1的ppic9k-col1a1m1两种重组表达载体质粒。
[0111]
将ppic9k-col2a1m6、ppic9k-col1a1m1质粒转化进入感受态大肠杆菌dh5α(购自生工生物工程(上海)股份有限公司),在含有氨苄青霉素的lb抗性平板筛选阳性克隆,提取重组质粒进行测序鉴定(交由生工生物工程(上海)股份有限公司完成),验证正确。ppic9k-col1a1m1、ppic9k-col2a1m6的质粒图谱分别如图3和图4所示。
[0112]
(2)菌种筛选
[0113]
将上述重组表达载体质粒10μg,用sacⅰ(购自大连takara公司,具体操作按试剂盒说明书进行)37℃酶切消化过夜,使其线性化,再使用以pcr产物纯化试剂盒(购自生工生物工程(上海)股份有限公司),回收线性化质粒,使体积控制在10μl左右。
[0114]
将线性化质粒电转化入宿主菌种毕赤酵母smd1168(购自赛默飞世尔科技公司)感受态细胞中,将电转后的菌液涂布于md平板上,每100μl~200μl涂布一块平板,室温静置10min,于30℃倒置培养2-5天,直至有单菌落(阳性转化子)出现。
[0115]
向md平板表面加入2ml无菌双蒸水,然后用无菌三角涂布器轻轻刮下平板表面的his
转化子,并转移到50ml离心管中。以无菌双蒸水稀释菌悬液,105个细胞涂布于含有0.5mg/mlg418的ypd平板上,倒置,30℃培养3~4d后至单菌落出现。从ypd平板上挑取菌落至无菌96孔板中(200μl ypd/孔),混匀,于30℃培养48h;混匀孔中菌液,各取10μl接入至一块新的无菌96孔板,于30℃培养24h后再重复一次此操作;24h后,从第三块96孔板中取出1μl分别点在含有1.0mg/ml和4mg/ml g418的ypd平板上,于30℃继续培养96h~120h。毕赤酵母转化子若能在含高浓度(4mg/ml)g418的平板上生长,说明该转化子含有多拷贝的目的基因,即有多个重组片段进入了酵母体内并通过同源重组整合到酵母的染色体上。经过这一步筛选可得到的高拷贝、可高效表达的重组酵母工程菌种。
[0116]
构建含ppic9k-col1a1m1、ppic9k-col2a1m6的两种工程菌样本均送至中国微生物菌种保藏管理委员会普通微生物中心保藏。
[0117]
含重组表达载体ppic9k-col1a1m1的工程菌表达重组α1(ⅰ)m1胶原蛋白,保藏于中国微生物菌种保藏管理委员会普通微生物中心,保藏编号是:cgmcc no.21891,地址:北京市朝阳区北辰西路1号院3号;保藏日期:2021年03月11日;分类命名:巴斯德毕赤酵母pichia pastoris。
[0118]
含重组表达载体ppic9k-col2a1m6的工程菌表达重组α1(ⅱ)m6胶原蛋白,保藏于中国微生物菌种保藏管理委员会普通微生物中心,保藏编号是:cgmcc no.21892。地址:北京市朝阳区北辰西路1号院3号;保藏日期:2021年03月11日;分类命名:巴斯德毕赤酵母pichia pastoris。
[0119]
实施例3.诱导表达与重组胶原蛋白的鉴定
[0120]
分别取实施例2得到的表达α1(ⅰ)m1、α1(ⅱ)m6的重组工程菌,同时取已知专利中的表达全长ⅰ型胶原α1链蛋白毕赤酵母工程菌株和表达全长ⅱ型胶原α1链蛋白的毕赤酵母
工程菌株作为对照,2个对照工程菌株均为发明人团队前期研究成果,所表达的全长胶原α1链同样于肽链氨基端添加strep-tag ii标签、羧基端添加6
×
his tag标签),其分别来自于申请号201911135958.0(名称:酵母重组人源ⅰ型胶原α1链蛋白、合成方法及其应用,专利中表达全长α1(ⅰ)链的毕赤酵母工程菌种保藏于中国微生物菌种保藏管理委员会普通微生物中心,保藏编号:cgmcc no.17150)、申请号201911088025.0(名称:毕赤酵母生产重组人源ⅱ型胶原蛋白单链的方法,专利中表达全长α1(ⅱ)链的毕赤酵母工程菌种保藏于中国微生物菌种保藏管理委员会普通微生物中心,保藏编号:cgmcc no.17149)的专利。将4种工程菌置于装有10ml bmgy培养基的100ml三角瓶中,于28-30℃、220rpm培养至od600为2~6(16-18h)。室温下1500~3000g离心5min,收集菌体,用bmmy培养基重悬菌体,使od600为2左右,放置于28-30℃、220rpm的摇床上继续生长3天,每24h向培养基中添加100%甲醇至培养基中甲醇的终浓度为1.0%。加甲醇诱导16h以上,就可收取菌液样品,取样量为1ml,置于1.5ml ep管中,4℃下以12000g离心5min,收集表达上清,待检测样品于-80℃保存备用。
[0121]
收取的表达上清,加入5
×
上样缓冲液(250mm tris-hcl、ph值为6.8,10%sds,0.5%溴酚蓝,50%甘油,5%β-巯基乙醇),置于100℃金属浴加热10min,进行sds-page检测。因表达的目的蛋白氨基端有srtep-tagⅱ标签,羧基端有6
×
his tag标签,可以抗srtep-tagⅱ、抗6
×
his tag的抗体(购自南京金斯瑞生物科技股份有限公司)进行western blot检测(具体操作参看说明书进行)。
[0122]
表达上清的sds-page如下图5所示,α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)在诱导表达24h均可高效分泌表达于胞外的表达上清中,α1(ⅰ)、α1(ⅱ)在预期的目的条带(》116kda)下出现了明确的主降解条带(《116kda),而本发明的α1(ⅰ)m1、α1(ⅱ)m6则只有预期的目的条带(》116kda)。
[0123]
使用image lab软件(bio-rad gel doc xr 成像仪)测算,结果如下:
[0124]
(1)α1(ⅰ)m1目的条带表观分子量(116.3kda)与α1(ⅰ)目的条带表观分子量(116.4kda)、α1(ⅱ)m6目的条带表观分子量(118.2kda)与α1(ⅱ)目的条带表观分子量(118.1kda)相比基本一致,明显大于α1(ⅰ)的主降解条带的表观分子量(104.5kda)与α1(ⅱ)的主降解条带的表观分子量(106.9kda)。
[0125]
(2)α1(ⅰ)电泳结果中目的条带与主降解条带的比值为51.5%:48.3%;α1(ⅱ)电泳结果中目的条带与主降解条带的比值为52.1%:47.8%,主降解产物与目的产物占比基本相同。
[0126]
从图6的ecl化学发光显色结果(全自动化学发光图像分析系统tanon 5200将蛋白质分子质量标准合成于图像)中可以看到,氨基端srtep-tagⅱ标签,羧基端6
×
his tag标签均可检测到,且目的条带均与sds-page中表观分子量大小相同,说明α1(ⅰ)m1、α1(ⅱ)m6两种重组胶原蛋白成功的进行了全长序列的高效分泌表达,目的条带的表达符合预期,而α1(ⅰ)、α1(ⅱ)两种胶原蛋白的目的条带序列虽然是全长完整的,但是主降解条带缺失了氨基端的序列,只能检测到羧基端6
×
his tag标签。
[0127]
将α1(ⅰ)m1和α1(ⅱ)m6在sds-page上的目的条带、α1(ⅰ)和α1(ⅱ)在sds-page上的目的条带与主降解带条带切割下来,用胰蛋白酶将其酶解,nano-hplc-ms/ms质谱检测重组胶原的胰蛋白酶解后肽段(委托苏州普泰生物技术有限公司完成),并将检测到肽段进行序列比对(uniprot数据库),数据比对结果及鉴定肽段与天然序列比对覆盖图(底色为灰色部
分:条带中质谱鉴定到肽段与天然序列相完全相同的部分),如图7和图8所示,结果可见:
[0128]
(1)α1(ⅰ)m1、α1(ⅰ)的目的条带及α1(ⅰ)的主降解带被酶解后检测到的肽段均属于ⅰ型胶原α1链上的序列。
[0129]
(2)α1(ⅱ)m6和α1(ⅱ)的目的条带及α1(ⅱ)的主降解带被酶解后检测到的肽段均属于人ⅱ型胶原α1链上的序列。
[0130]
以上结果说明α1(ⅰ)m1、α1(ⅱ)m6与α1(ⅰ)、α1(ⅱ)一样成功表达,分别属于人ⅰ型胶原α1链、人ⅱ型胶原α1链的重组胶原蛋白,但α1(ⅰ)、α1(ⅱ)表达时产生了降解,主降解条带也属于相应种类胶原蛋白。
[0131]
实施例4.高密度发酵与纯化
[0132]
(1)对基因工程菌进行高密度发酵
[0133]
重组α1(ⅰ)m1、α1(ⅱ)m6胶原蛋白规模化表达生产,获取含有重组胶原蛋白的发酵液。
[0134]
种子培养基ypg(含酵母粉10g/l、酵母蛋白胨20g/l、无水甘油10g/l);发酵培养基(含nh4h2po
4 190.4g/l、kh2po
4 10.06g/l、caso4·
2h2o 1.18g/l、k2so
4 18.2g/l、mgso4·
7h2o 14.9g/l、甘油40g/l);补料培养基(含50%w/v甘油,每升加12ml ptm1微量元素);诱导培养基(含100%甲醇,每升加入12ml ptm1微量元素);ptm1:用0.22μm的滤膜过滤除菌,4℃保存。发酵培养基高温灭菌后待温度降至室温后加入ptm1,用氨水调节ph值至5.0。
[0135]
工程菌株分批培养条件和诱导表达条件为:
[0136]
采用分批补料培养方法,培养温度30℃。
[0137]
工程菌接入含种子培养基ypg的1l摇瓶,220rpm、30℃,培养18-20h,至od600=2~10。使用5l发酵罐(保兴生物),装液量2l发酵培养基,2%甘油分开灭菌,接种前调节转速为300rpm,通气量4l/min,温度30℃,用浓氨水配制好的碱液调ph,设置ph至4.5。然后先接入0.9ml ptm1,然后再将制备好的200ml种子液接入罐内(火焰圈接种),然后点击溶氧电极校百,校百后开始发酵。待生长溶氧第一次掉至30%时,采用溶氧串级转速功能,保持生长溶氧为30%;等待甘油耗完,溶氧反弹、溶氧大于70%(od600值约20),取消溶氧串级转速,调高搅拌650rpm,甘油采用30%联动补料,补料80ml。停止补甘油,溶氧反弹至70%以上后,设置ph值为4、温度29℃,以甲醇、甘油混合碳源(甲醇:50%甘油=7:3)进行诱导培养。手动补加5ml,待溶氧反弹至70%以上后,设定补料速度为8ml/h,一小时后提高到为10ml/h,一小时后再次提高设定到20ml/h。待溶氧值低于30%,停止补料,等待溶氧反弹,溶氧回升至30%后联动补料。诱导40~60h,uv测量蛋白浓度增长幅度不明显或下降即可放罐。uv蛋白定量公式:c(mg/ml)=0.144*(a215-a225),a215《1.5。同时,分别同时取表达全长α1(ⅰ)链的毕赤酵母工程菌种(中国微生物菌种保藏管理委员会普通微生物中心菌种保藏编号:cgmcc no.17150)、表达全长α1(ⅱ)链的毕赤酵母工程菌种(中国微生物菌种保藏管理委员会普通微生物中心菌种保藏编号:cgmcc no.17149)进行高密度发酵。
[0138]
结果如表1所示,在诱导48h后,α1(ⅰ)与α1(ⅰ)m1相比、α1(ⅱ)m6与α1(ⅱ)相比,菌浓度(od600)、菌湿重、发酵液中表达蛋白浓度uv定量三个指标并无明显差异。但收集发酵上清进行sds-page电泳检测,结果如图9所示,可发现在高密度发酵的条件下,α1(ⅰ)、α1(ⅱ)的主降解条带极为明显,与摇瓶诱导表达无区别;而α1(ⅰ)m1、α1(ⅱ)m6最主要的产物仍是其目的条带,主降解条带没有出现,这说明α1(ⅰ)m1、α1(ⅱ)m6在消除主降解条带(主降
and collagen-like polypeptides.biopolymers,1975.14(5):p.937-957.[3].周爱梅等,重组人源胶原蛋白的分离纯化及其结构表征.食品与发酵工业,2015(03):第46-52页.)。
[0149]
(2)重组胶原蛋白细胞黏附活性检测
[0150]
重组胶原蛋白的细胞黏附活检测方法参考文献juming yao,satoshi yanagisawa,tetsuo asakura.design,expression and characterization of collagen-like proteins based on the cell adhesive and crosslinking sequences derived from native collagens,j biochem.136,643-649(2004)。委托常州大学药学院功能纳米材料与生物医学检测实验室完成。
[0151]
具体实施方法:正常培养nih/3t3细胞(购自中国科学院细胞库,货号gnm6,培养、传代方法参照细胞说明书执行)。取重组α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)胶原蛋白冻干海绵、对照人胶原蛋白(购买自sigma,货号c7774)及牛血清白蛋白(bsa,购自生工生物(上海)股份有限公司)溶解(用超纯水或1m hcl溶液),以uv蛋白定量经验公式:c(mg/ml)=0.144
×
(a215-a225)测定蛋白浓度,再以pbs(ph 7.4)稀释至0.5mg/ml。向96孔细胞培养板中加入100μl各种蛋白溶液和空白pbs溶液对照,室温静置60min;再向每孔中加入105个培养状态良好的nih/3t3细胞,37℃、5%co2孵育60min。以pbs清洗4次孔中细胞。使用ldh检测试剂盒(roche,04744926001)检测od492nm的吸光度值(具体操作参照说明书执行)。
[0152]
od492nm的吸光度相应的表征可以代表胶原蛋白样品的细胞粘附活性:od492nm的吸光度越高,说明蛋白粘附的细胞越多,黏附活性越高,胶原蛋白越能在短时间内帮助细胞贴壁或粘附于细胞外基质之上,更利于构建更佳的细胞外环境。结果如图13所示,重组α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)胶原蛋白均与商品化的天然人胶原蛋白有类似的细胞黏附活性,且都显著高于对照组;α1(ⅰ)m1与α1(ⅰ)相比、α1(ⅱ)m6与α1(ⅱ)相比,细胞黏附活性基本一致,无显著差异。
[0153]
(3)重组胶原蛋白水凝胶的制备与检测
[0154]
取重组α1(ⅰ)m1、α1(ⅱ)m6、α1(ⅰ)、α1(ⅱ)胶原蛋白,以10%浓度溶于注射用水,调节ph值控制在4~6的范围内,0.22μm无菌滤器过滤除菌;以每1g胶原干粉的比例加入0.1g 10%(w/w)无菌n-羟基琥珀酰亚胺(nhs)溶液,混匀;然后以每g胶原干粉的比例加入0.13g 50%(w/w)无菌1-(3-二甲基氨丙基)-3-乙基碳二亚胺盐酸盐(edc)溶液;室温(20-30℃)静置反应2-6h,形成水凝胶。将水凝胶置于无菌pbs溶液中(nacl 8.5g/l、na2hpo
4 0.5g/l、nah2po
4 0.15g/l,ph 7.2)透析,凝胶:pbs透析液=1:6(m/m),连续透析120h,每24h彻底更换一次透析液,去除nhs、edc残留。将透析后的水凝胶装入无菌容器中,室温放置。
[0155]
将水凝胶冷冻干燥去除水分,取冻干后水凝胶称重,再置于无菌pbs溶液中放置24h,待其彻底吸水溶胀,取出水凝胶,吸水纸将表面水分吸干后称重。参考文献中方法计算溶胀率:q
溶胀率
=(w
吸水溶胀质量-w
干凝胶重量
)/w
干凝胶重量
。流变仪(discovery hr-2)检测水凝胶的弹性模量(储能模量,小振幅频率扫描,25℃、应力0.5%、0.1-100.0rad/s)、动力粘度(流动峰值保持,25℃、剪切速率2.0s-1
)。将冻干后水凝胶转入液氮中速冻,掰断,使用扫描电镜(日立tm3030plus)对冻干后水凝胶表面进行扫描。弹性模量、动力粘度、溶胀率结果如表2所示,α1(ⅰ)m1与α1(ⅰ)相比、α1(ⅱ)m6与α1(ⅱ)相比,相同条件下所制备的水凝胶的流体力学性质基本一致,并无明显改变。
[0156]
表2.四种水凝胶的弹性模量、动力粘度、溶胀率检测
[0157]
凝胶种类弹性模量(pa)粘度(pa
·
s)溶胀率(g/g干凝胶)α1(ⅱ)104.6382.8714.18α1(ⅱ)m6102.0277.8014.01α1(ⅰ)234.67190.6712.53α1(ⅰ)m1292.68170.9712.22
[0158]
如图14、15所示,由α1(ⅰ)m1、α1(ⅱ)m6所制备的水凝胶与由α1(ⅰ)、α1(ⅱ)所制备的水凝胶一样,均为多孔网状结构,孔径范围集中于100-200μm,具有良好的通透性,具备保持大量水分的空间结构基础,可作为细胞提供黏附、支撑、生长迁移的空间和输送营养物质与新陈代谢产物的通道,有应用于生物医学材料领域的潜力。
[0159]
(4)重组胶原蛋白水凝胶的细胞检测
[0160]
无菌存放的水凝胶放置于24孔细胞培养板中。取正常培养nih/3t3细胞(购自中国科学院细胞库,货号gnm6,培养、传代方法参照细胞说明书执行),pbs清洗、胰酶消化、加培养基吹打均匀并计数,105细胞/孔接入到含水凝胶的培养皿中,共培养24-72小时,观察细胞于水凝胶上的粘附与增值情况。
[0161]
(1)取一块24孔板用dmso制备1mm的钙黄黄绿am(购于碧云天生物技术研究所),并用d-pbs将其稀释成50μm的钙黄绿素工作液。吸去孔中培养基,用pbs清洗数次,加入1ml的含血清dmem培养基,加入100μl钙黄绿素am溶液(培养基的1/10),孵育30min,对细胞进行染色,再更换生长培养基,培养30min,轻取出水凝胶,置入新的培养孔中,荧光显微镜下拍照(最大激发光波长为494nm,最大发射光波长为514nm)。
[0162]
(2)另取一块24孔板中加入200μl mtt溶液(购于碧云天生物技术研究所),培养nih/3t3细胞4h后,观察细胞中蓝紫色结晶形成情况,弃培养基,用pbs清洗水凝胶,纵切开水凝胶,置入新的培养孔中,显微镜下拍照。
[0163]
该实施例实验委托常州大学药学院功能纳米材料与生物医学检测实验室完成。
[0164]
结果如图16、17所示,由α1(ⅰ)m1、α1(ⅱ)m6所制备的水凝胶与由α1(ⅰ)、α1(ⅱ)所制备的水凝胶一样,明场显微镜下观察nih/3t3细胞形态正常,为典型的成纤维细胞形态;水凝胶上黏附生长的nih/3t3细胞被钙黄绿素am染色后可检测到绿色荧光(照片中明亮部分);水凝胶中生长的nih/3t3细胞在加入mtt后,可形成的蓝紫色结晶(照片中黑色部分);绿色荧光与蓝紫色结晶只能由活细胞形成,说明nih/3t3细胞均能正常黏附、生长、迁移于水凝胶中,由α1(ⅰ)m1、α1(ⅱ)m6制备的水凝胶与天然序列的α1(ⅰ)、α1(ⅱ)所制备的水凝胶有类似的生物学功能,可作为新型生物医疗器械应用于创伤修复、组织再生等领域。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
