一种基于改进ddpg算法的移动机器人路径规划方法
技术领域
1.本发明属于移动机器人运动控制技术领域,尤其涉及一种基于改进ddpg算法的移动机器人路径规划方法。
背景技术:
2.移动机器人完成其它任务的首要前提就是要移动到指定目标位置,因此路径规划技术是移动机器人技术中关键的技术之一。移动机器人在城市环境中要完成路径规划,不仅要考虑到静态的障碍物,同时也要考虑到动态的障碍物;由于城市环境十分复杂多变,要建立完整的地图信息十分困难,因此未知环境下的移动机器人路径规划十分重要,同时也给移动机器人进行路径规划增加了很大的难度。
3.目前传统路径规划算法可以分为全局路径规划和局部路径规划两大类。全局算法包括a*算法,dijkstra算法,可视图算法,自由空间法等;全局路径规划算法通常需要提前获取全局地图信息,但是移动机器人工作的环境通常是动态的,并且难以获取准确的环境信息,因此只能将全局路径规划,划分为若干个子规划过程,即局部路径规划。局部路径规划大致可以分为4类:随机采样规划方法、人工势场法、图搜索法和群智能优化法。快速扩展随机树算法(rapidly-exploring random trees,rrt)是经典的基于随机采样的算法之一,该算法能快速实现路径规划而得到广泛的应用,但是其无法保证路径最优。人工势场法虽然能应用于未知环境中,但是其容易陷入局部最优。基于群智能算法的代表算法包含,遗传算法、粒子算法、蚁群算法及一些融合算法等,群智能算法因其计算复杂度高,不适用于未知动态环境中机器人路径规划。
4.近年来随着强化学习和神经网络的发展,深度强化学习算法被认为是解决未知动态环境最具有潜力的方法。根据采用的(deep reinforcement learning,深度强化学习)drl算法框架的不同,可以分为基于价值的drl路径规划和基于actor-critic的drl路径规划方法。基于价值的drl算法主要有(deep q-learning network,深度q网络)dqn,double dqn算法等,该种方法只能处理移动机器人离散的动作集合,对于连续的动作空间则有较大的局限性。基于actor-critic的方法主要包含ddpg(deep deterministic policy gradient深度确定性策略梯度)、trpo、ppo等,较好的解决了移动机器人连续控制的问题,但是存在着收敛速度慢,不稳定等问题急需解决。
5.因此,能否很好的实现移动机器人在未知动态环境中的路径规划。决定着移动机器人的发展和应用,所以移动机器人路径规划技术是十分重要的。
技术实现要素:
6.发明目的:针对ddpg算法在未知动态环境进行路径规划时收敛速度慢的问题,本发明提出了一种基于改进ddpg算法的移动机器人路径规划方法。
7.技术方案:本发明提出了一种基于ddpg算法的移动机器人路径规划方法,实现移动机器人找到一条从起点到达终点的无碰撞路径,包括如下步骤:
8.步骤1,建立基于深度强化学习的移动机器人路径规划模型,将移动机器人路径规划问题,描述为马尔科夫决策过程。
9.步骤2,设计ddpg算法的状态空间、动作空间、actor网络、critic网络及奖励函数。
10.步骤3:对ddpg算法的经验回放池进行改进,将经验回放池划为多个不同优先级的经验回放池,移动机器人在训练过程中,根据移动机器人是否到达目标点,以及是否发生碰撞,将获取的训练数据放入不同的经验回放池中。
11.步骤4:设计仿真环境,移动机器人与环境进行交互,获取训练数据,采样训练数据对移动机器人进行仿真训练,完成无碰撞的路径规划。
12.进一步的,步骤2中ddpg算法的状态空间包括:激光雷达数据、移动机器人当前的控制指令、移动机器人上一时刻的控制指令、目标点的方位和距离;所述移动机器人当前的控制指令是指移动机器的角速度和线速度;ddpg算法的动作空间包括:移动机器人体坐标系下绕z轴旋转的角速度和沿x轴的线速度。
13.进一步的,步骤2中ddpg算法的奖励函数根据移动机器人是否到达目标点、移动机器人与目标点的距离变化以及是否与障碍物发生碰撞设计如下:
14.根据移动机器人是否到达目标点设计的奖励函数:
[0015][0016]
式中,χ
t
为t时刻移动机器人与目标点的距离,d1为设定的阈值,当移动机器人与目标点小于d1时表示到达目标点。
[0017]
根据移动机器人与障碍物是否发生碰撞设计的奖励函数:
[0018][0019]
式中,di为激光雷达检测到最近的障碍物的距离,d2为设定的常数阈值,当移动机器人与障碍物的距离小于d2时,表示与障碍物发生碰撞。
[0020]
为引导移动机器人向着目标点前进,根据移动机器人与目标点之间的距离变化,设计的奖励函数:
[0021][0022]
其中,χ
t-1
为t-1时刻移动机器人与目标点的距离,χ
t
为t时刻移动机器人与目标点的距离;
[0023]
最后总的奖励函数为:
[0024]
r=r
arrival
r
collision
r
dis
[0025]
进一步的,步骤4中的设计仿真环境,移动机器人与环境进行交互,获取训练数据,采样训练数据对移动机器人进行仿真训练,完成无碰撞的路径规划,具体包括如下步骤:
[0026]
步骤4.1,设计仿真环境,移动机器人与环境进行交互,获取训练数据;
[0027]
步骤4.2,采样获取训练数据,训练actor网络和critic网络;
[0028]
步骤4.3,将移动机器人当前状态信息输入到经过训练后的策略网络中,其输出移动机器人下一步的动作指令。
[0029]
进一步的,步骤3中将经验回放池划为多个不同优先级的经验回放池,具体为:划
为三个不同优先级的经验回放池,当移动机器人到达目标点时,将获取的训练数据放入优先级最高的经验回放池一中;当移动机器人处于正常的探索阶段时,将获取的训练数据放入优先级次之的经验回放池二中;当移动机器机器人与障碍物发生碰撞时,将获取的训练数据放入优先级最低的经验回放池三中;
[0030]
所述训练数据包括状态信息、当前时刻及上一时刻的动作指令及奖励值数据,所述状态信息包括激光雷达数据、以及目标点的方位和距离信息。
[0031]
进一步的,步骤4.2中采样获取训练数据具体是按不同的比例从经验回放池中采样。
[0032]
进一步的,步骤4.2中采样获取训练数据具体是先按3:4:3的比例进行采样,训练到多个回合后,再按照4:3:3的比例从三个不同优先级的经验回放池中采样。
[0033]
有益效果:本发明的一种面向城市环境下改进ddpg算法的移动机器人路径规划方法,将原有随机采样的经验回放池划分为多个不同优先级的经验回放池,提高了ddpg算法的收敛速度。在没有对移动机器人进行运动学建模,直接通过改进的ddpg算法实现了端到端的导航控制。我在四种仿真实验环境中进行了验证,仿真实验表明,本发明能够有效提升ddpg算法的收敛速度。
附图说明
[0034]
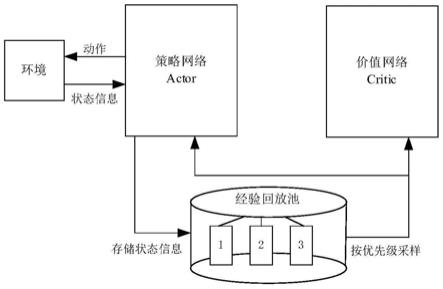
图1为本发明改进后ddpg算法框架示意图。
[0035]
图2是本发明设计的环境示意图。
[0036]
图2(a)是环境一示意图;图2(b)是环境二示意图;图2(c)是环境三示意图;图2(d)是环境四示意图。
[0037]
图3是改进后的ddpg算法与传统的ddpg算法奖励值对比图
[0038]
图3(a)是环境一中的奖励值对比图;图3(b)是环境二中奖励值对比图;图3(c)是环境三奖励值对比图;图3(d)是环境四中奖励值对比图。
具体实施方式
[0039]
下面结合附图对本发明做更进一步的解释。
[0040]
一种基于改进ddpg算法的面向城市环境下移动机器人路径规划方法,主要针对传统ddpg算法收敛速度慢的问题进行了改进,对传统ddpg算法的经验回放进行了改进,将原有随机采样变为按比例从不同等级经验回放池中进行采样。具体步骤如下:
[0041]
本发明的一种基于改进ddpg算法的移动机器人路径规划方法,包括如下步骤:
[0042]
步骤1,建立基于深度强化学习的移动机器人路径规划模型:将移动机器人路径规划问题,描述为马尔科夫决策过程。
[0043]
步骤2,设计ddpg算法的状态空间、动作空间、actor网络、critic网络及奖励函数。
[0044]
所述ddpg算法的状态空间包括:激光雷达数据、移动机器人当前的控制指令、移动机器人上一时刻的控制指令、目标点的方位和距离;所述移动机器人当前的控制指令是指移动机器的角速度和线速度。
[0045]
动作空间包括:移动机器人体坐标系下绕z轴旋转的角速度和沿x轴的线速度。其中z轴垂直于移动机器人底盘所在平面,向上为正;x轴位于移动机器人底盘所在平面,垂直
于z轴,指向移动机器人前轮连线的中心。
[0046]
actor网络采用4层全连接神经网络,每一层均采用relu非线性激活函数。
[0047]
critic网络同样采用4层全连接神经网络结构。
[0048]
所述奖励函数根据移动机器人否到达目标点、与目标点的距离变化以及是否与障碍物发生碰撞设计如下:
[0049]
根据移动机器人是否到达目标点设计的奖励函数:
[0050][0051]
式中,χ
t
为t时刻移动机器人与目标点的距离,d1为设定的阈值,当移动机器人与目标点小于d1时表示到达目标点。
[0052]
根据移动机器人与障碍物是否发生碰撞设计的奖励函数:
[0053][0054]
式中,di为激光雷达检测到最近的障碍物的距离,d2为设定的常数阈值,当移动机器人与障碍物的距离小于d2时,表示与障碍物发生碰撞。
[0055]
为引导移动机器人向着目标点前进,根据移动机器人与目标点之间的距离变化,设计的奖励函数:
[0056][0057]
最后总的奖励函数为:
[0058]
r=r
arrival
r
collision
r
dis
[0059]
步骤3:对ddpg算法的经验回放池进行改进,以达到提高收敛速度的目的。
[0060]
所述对ddpg算法的经验回放池改进,是指将原有的随机采样的经验回放池划分为多个不同优先级的经验回放池,移动机器人在训练过程中,根据移动机器人是否到达目标点,以及是否发生碰撞,将每一条训练数据放入不同的经验回放池中,改进后的ddpg算法结构如图1所示,然后再按照不同的比例从经验回放池中抽取数据对策略网络和价值网络进行训练。
[0061]
步骤4:设计仿真环境,移动机器人与环境进行交互,获取训练数据,采样训练数据对移动机器人进行仿真训练,完成无碰撞的路径规划。具体步骤如下:
[0062]
步骤4.1,设计仿真环境,移动机器人与环境进行交互,获取训练数据,根据奖励值的大小存入不同优先级的经验回放池中;
[0063]
本发明设计了四种仿真环境如图2所示,其中图2(a)是环境一示意图,为无障碍物的静态环境;图(a)中黑色正方形表示移动机器人,黑色方框表示目标点;图2(b)中四个圆形表示静态障碍物,图2(c)黑色方框表示目标点,黑色实心正方形和黑心实心圆体表示三个动态障碍物;图中2(d)方框表示三个目标点,两个黑色实心正方形和一个实心圆分别表示动态障碍物,空心五边形表示为静态障碍物,且环境四的大小为环境三的两倍。
[0064]
移动机器人分别在四种环境中获取训练数据。首先进行初始化仿真环境、移动机器人的状态信息、actor网络和critic网络;然后移动机器人与仿真环境进行交互,从环境中获取状态信息,所述状态信息包含激光雷达数据、以及目标点的方位和距离信息,并计算
奖励值;将每一步获取的状态信息、奖励值、当前时刻及上一时刻的动作指令作为训练数据存入经验回放池中。
[0065]
具体的,当移动机器人到达目标点时,将获取的训练数据放入优先级最高的经验回放池一中;当移动机器人处于正常的探索阶段时,既没有发生碰撞也没有到达目标点,将获取的训练数据放入优先级次之的经验回放池二中;当移动机器机器人与障碍物发生碰撞时,将获取的训练数据放入优先级最低的经验回放池三中。
[0066]
在进行ddpg算法训练前,移动机器人需要获取足够多的经验数据,因此本发明在训练的初始阶段将每一条表现好的数据重复添加三次,达到快速增加训练数据的目的。
[0067]
步骤4.2,按不同的比例从经验回放池中采样获取训练数据,训练actor网络和critic网络。
[0068]
当经验回放池中的数据达到设定的数量时,开始对策略网络和价值网络进行训练。在训练的前期由于到达目标点的数据量较少,本实施例中经验回放池划分为三个,分别从三个不同优先级的经验回放池中按照3:4:3的比例进行采样;训练到500回合后,按照4:3:3的比例从三个不同优先级的经验回放池中采样;然后将采样的数据合并在一起,送入到策略网络和价值网络中进行训练。
[0069]
步骤4.3,移动机器人根据策略网络输出的动作指令执行动作,完成路径规划。
[0070]
将移动机器人当前状态信息输入到经过训练后的策略网络中,其输出移动机器人下一步的动作指令,完成路径规划任务;所述动作指令包括移动机器人体坐标系下绕z轴旋转的角速度和沿x轴的线速度。
[0071]
经过一千回合训练后,传统ddpg算法与改进后的ddpg算法奖励值对比如图3所示。从图3中可以看出,改进后的ddpg算法比传统的ddpg算法奖励值更早的趋于稳定,收敛速度更快,其中图3(a)是环境一中的奖励值对比图;图3(b)是环境二中奖励值对比图;图3(c)是环境三奖励值对比图;图3(d)是环境四中奖励值对比图。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。