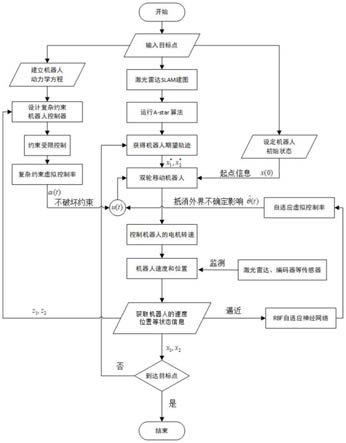
1.本发明属于机器人轨迹跟踪控制技术领域,具体涉及一种复杂约束下的移动机器人跟踪控制方法。
背景技术:
2.轮式移动机器人(wmrs)在工业和军事应用方面具有巨大的潜力,在过去的几十年里,这类小型车辆的智能控制发展取得了重大进展。移动机器人可用于工厂车间的自动货物装卸、野外道路环境勘测和数据测量和室内地形建模等等。为了更好地利用机器人协助完成各种任务,越来越多的研究人员从事相关研究。
3.在许多实际系统中,为了确保机器人运行的安全性和稳定性,对机器人做复杂约束是很有必要的。如果机器人在运行中破坏了约束条件,很有可能造成机器人故障甚至致命事故。因此在系统设计中加入复杂约束是很有意义的,也具有挑战性,现在关于移动机器人的大多数研究都没有考虑全状态包括位置、速度等复杂约束,而是只考虑一部分约束,因此如何设计满足约束条件的障碍lyapunov函数是一个亟待解决的问题。同时机器人在运动过程中会遇到轮胎打滑、风力等影响,因此也需要设计有个合适的自适应神经网络函数去逼近干扰,保证机器人可以稳定运行。另外,机器人的路径规划算法也是机器人移动跟踪控制很重要的一部分,研究者一般采用dijkstra算法或者最佳优先算法,dijkstra算法从起点开始,计算从起点到下一个节点的移动成本。慢慢向外延伸,访问所有节点直到目标点,然后从目标点回溯寻找路径。dijkstra算法可以确保找到最短路径,但需要大量计算。最佳优先算法有一个启发函数,该函数计算该节点到相对于目标节点的优先级,选择成本低的节点作为下一遍历点。虽然相比于dijkstra算法快得多,但不能保证找到最短路径。所以本发明采用两种算法的结合体a
‑
star算法,可以保证找到最优路径并且计算量较小。但a
‑
star算法中启发函数的设计不同,会造成结果的很大差异,因此设计一个适用的启发函数也很有挑战性。
技术实现要素:
4.为了解决上述问题,本发明提供了一种复杂约束下的移动机器人跟踪控制方法,主要包括以下步骤:
5.步骤1、输入机器人的目标点,并设定机器人的初始位置信息x1(0)和初始速度信息x2(0),同时对机器人的每个部件进行受力分析,建立机器人的动力学模型,设置复杂约束移动机器人控制器。
6.步骤2、遥控控制机器人使用二维激光雷达扫描周围环境,通过slam算法对机器人所处的环境创建地图。
7.步骤3、利用a
‑
star路径规划算法得到从起始点到目标点的最优路径,并计算得到最优路径,从而获得机器人期望轨迹,分别代表期望位置和期望速度。
8.步骤4、通过激光雷达、编码器实时监测机器人的状态信息,获取机器人实时的位
置信息和速度信息。
9.步骤5、设计复杂约束受限控制算法,根据机器人的实时状态信息,得到实际轨迹与期望轨迹的偏差,z1,z2分别代表位置偏差和速度偏差,把此偏差输入到复杂约束机器人控制器,通过约束受限控制算法得到复杂约束虚拟控制律,进而控制机器人不会破坏约束条件。
10.步骤6、同时将机器人的实时状态信息反馈给rbf神经网络,rbf自适应神经网络算法通过逼近未知非线性项,来确定自适应虚拟控制律进而抵消外界诸如轮胎打滑、风力等不确定影响。
11.步骤7、将复杂约束虚拟控制律和自适应虚拟控制律进行结合,得到最终的实际控制律;
12.步骤8、实际控制律控制双轮移动机器人的电机转速,来控制机器人持续平稳的运行;
13.步骤9:判断机器人是否到达目标点,如果到达目标点,机器人停止运行,如果没有到达目标点,重复步骤3至8,直至到达目标点。
14.进一步的,步骤1中所述的动力学模型设计如下:
15.步骤1.1、本发明考虑简单的轮式机器人系统,所述动力学方程描述如下:
[0016][0017]
其中,q=[x,y]
t
表示位置向量,x和y分别表示机器人几何中心的横坐标和纵坐标。m(q)∈r2×2表示正定惯性矩阵,表示向心矩阵和科里奥利矩阵,表示地面摩擦,τ
d
表示未知有界扰动,b(q)∈r2×2表示输入变换式矩阵,τ∈r2×1表示力矩的输入矢量,并且τ=[τ
r
,τ
l
],a
t
(q)λ∈r2×1表示非完整约束力。
[0018]
步骤1.2、确定所述动力学方程模型后,我们定义x1=q=[x,y]
t
,,然后将所述动力学方程模型转换成下面形式:
[0019][0020]
其中,x1为位置状态信息,x2为速度状态信息;
[0021]
g(t)表示系统的集总不确定性。
[0022]
进一步的,步骤3中所述的a
‑
star路径规划算法如下:
[0023]
f(n)=g(n) h(n)
[0024]
其中g(n)表示从节点n到起始点的移动代价;f(n)表示第n个节点的综合优先级,算法根据节点的优先级大小选择下一个要遍历的节点;h(n)表示节点n到终点的期望代价,是快速优先算法的启发式函数;
[0025]
所述a
‑
star路径规划算法完整步骤描述如下:
[0026]
步骤3.1、初始化开集和闭集;
[0027]
步骤3.2、把初始点放入开集,并设优先级为最高;
[0028]
步骤3.3、如果开集不为空,则从开集中选择优先级最高的节点作为节点n;
[0029]
步骤3.3.1、如果节点n是目标节点:则完成路径规划,跟踪父节点n从终点到起点;
[0030]
步骤3.3.2、如果节点n不是目标节点:将节点n从开集中移除,并置于闭集中。遍历节点n相邻的所有节点;
[0031]
步骤3.3.2.1、如果n相邻的节点m在闭集中:跳过并检测下一个节点;
[0032]
步骤3.3.2.2、如果n相邻的节点m既不在开集也不在闭集中:赋值n为m的父节点,把节点n设置为节点m的父节点,计算m的优先级,将节点m加入开集;
[0033]
步骤3.3.2.3、如果n相邻的节点m在开集中:计算比较综合优先级f(m)的值,如果f(m)是开集中的最小值,则该节点m为父节点;
[0034]
步骤3.3.3、判断节点m是否为目标节点,如果节点m是目标节点,则完成路径规划,跟踪父节点m从终点到起点;如果节点m不是目标节点,重复步骤3.3.2~步骤3.3.2.3,直至到达目标节点。
[0035]
进一步的,所述启发式函数h(n)在a
‑
star算法中有至关重要的作用。在极端情况下,如果h(n)是0,函数f(n)中只有g(n)发挥作用,a
‑
star算法会变成dijkstra算法。也就是说h(n)足够小,a
‑
star算法遍历节点越多,算法运行速度越慢。反之,h(n)越大,a
‑
star就会变成快速优先算法。
[0036]
可以用下述启发式函数计算计算期望代价:
[0037][0038]
这个形式的启发函数可以计算直线距离和对角线距离。
[0039]
其中n
x
,n
y
分别表示当前点的横纵坐标,中p
x
,p
y
分别表示目标点的横纵坐标。
[0040]
进一步的,在步骤5中所述的复杂约束包括速度约束和位置约束,所述复杂约束受限控制算法的设计包括的速度约束受限控制设计和位置约束受限控制算法的设计:
[0041]
步骤5.1、位置约束受限控制算法设计如下:
[0042]
采用backstepping的方法,基于对数函数z1为位置偏差,然后选取满足约束条件的lyapunov函数v1,v1>0,为满足位置约束条件的lyapunov函数,对所选取的lyapunov函数求一阶导数,并化简得到其中位置约束虚拟控制律束虚拟控制律运用杨氏不等式使得进而确定合适的位置约束虚拟控制律α1;其中a1>2k1h1,b1<s1h1z1,a1、b1分别代表位置约束状态的上下限,a1、b1、k1均为常数。
[0043]
步骤5.2、速度约束受限控制算法设计如下:
[0044]
采用backstepping的方法,基于对数函数z2为速度偏差,然后选取满足约束条件的lyapunov函数v2,v2>0,为满足速度约束条件的lyapunov函数,对所选取的lyapunov函数求一阶导数,并化简得到其中速度约
束虚拟控制律束虚拟控制律运用杨氏不等式使得进而确定合适的速度虚拟控制律α2;其中a2>2k2h2,b2<s2h2z2,a2、b2分别代表速度约束状态的上下限,a2、b2、k2均为常数。
[0045]
步骤5.3、综合位置约束虚拟控制律和速度约束虚拟控制律,得到的动态复杂约束虚拟控制律α(t)。
[0046]
进一步的,在步骤6中所述rbf自适应神经网络是一种三层的神经网络,包括输入层、隐含层和输出层;输入层到隐含层的转换是非线性的,而隐含层到输出层的转换是线性的。
[0047]
所述rbf自适应神经网络算法设计如下:
[0048]
对于一个未知的连续非线性函数g(z),在紧集ω∈r中,可以近似为:
[0049]
g(z)=w
t
φ(z) δ(z)
[0050]
其中z∈ω是输入向量,w∈r
l
是理想权向量,l是节点数。δ(z)是近似误差,φ(z)=[φ1(z),...,φ
l
(z)]
t
∈r
l
是高斯函数:
[0051][0052]
是高斯函数的中心,v
i
是高斯函数的宽度。
[0053]
定义所述rbf自适应神经网络θtφ(z) δz(z),去近似不确定量g(t),使得
[0054]
g(t)=θ
t
φ(z) δ
z
(z)
[0055]
上述等式近似成立时的θ
t
,即为最合适的自适应虚拟控制律
[0056]
进一步的,所述rbf自适应神经。网络算法通过对未知非线性项逼近,最终确定的自适应虚拟控制律为
[0057]
其中z2为速度偏差,a2、b2为常数,φ(z)=[φ1(z),...,φ
l
(z)]
t
∈r
l
是高斯函数,为虚拟控制律的导数。
[0058]
进一步的步骤7中所述实际控制律为:
[0059][0060]
其中m为正定惯性矩阵,τ∈r2×1表示力矩的输入矢量,对数函数表示力矩的输入矢量,对数函数z2为速度偏差,a2、b2、k为常数,为自适应虚拟控制律,φ(z)=[φ1(z),...,φ
l
(z)]
t
∈r
l
是高斯函数。
[0061]
进一步的,所选取的位置和速度lyapunov函数其一阶导数均小于0,使得所设计的最终复杂约束虚拟控制律能使系统在时间趋于无穷大时稳定。
[0062]
本发明提供的技术方案带来的有益效果是:本发明充分考虑了机器人运行过程中的复杂约束情况,通过位置约束受限控制和速度约束受限控制,保证机器人运行的安全性和稳定性,同时采用自适应rbf神经网络去逼近未知非线性项,进一步保证机器人运行的稳定性。另外,给出目标点,使用slam算法和激光雷达建图,通过a
‑
star路径规划算法可自动
计算出机器人的预定轨迹,避开障碍物。整个机器人系统运行稳定,抗干扰能力强。
附图说明
[0063]
下面将结合附图及实施例对本发明作进一步说明,附图中:
[0064]
图1是本发明实施例中种复杂约束下的移动机器人跟踪控制方法的流程图。
[0065]
图2是表示系统位置状态的仿真图。
[0066]
图3是表示系统速度状态的仿真图。
[0067]
图4是表示系统位置偏差的仿真图。
[0068]
图5是表示系统速度偏差的仿真图。
[0069]
图6是本发明实施例中的机器人slam建图。
[0070]
图7是本发明实施例中a
‑
star算法循迹图。
具体实施方式
[0071]
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
[0072]
本发明的实施例提供了一种复杂约束下的移动机器人跟踪控制方法
[0073]
步骤1、matlab软件中,设置机器人质量m1=10kg,,机器人车轮直径r=0.1m,机器人宽度b=0.5m,,机器人长度h=0.5m,输入机器人的目标点,并设定机器人的初始位置信息x1(0)=0.8和初始速度信息x2(0)=0.6,同时对机器人的每个部件进行受力分析,建立机器人的动力学模型,设置复杂约束移动机器人控制器。
[0074]
步骤2、使用turtlebot3机器人,机器人上装载了激光雷达扫描,树莓派3以及32位mcu。遥控控制机器人使用二维激光雷达扫描周围环境,树莓派处理数据通过slam算法对机器人所处的环境进行地图建模。设置速度为0.2m/s,角速度为2rad/s。
[0075]
步骤3、利用a
‑
star路径规划算法得到从起始点到目标点的最优路径,从而获得机器人期望轨迹,器人期望轨迹,分别代表a
‑
star算法计算出来的期望位置和期望速度。
[0076]
步骤4、通过激光雷达、编码器实时监测机器人的状态信息,获取机器人实时的位置信息和速度信息。
[0077]
步骤5、设计复杂约束受限控制算法,根据机器人的实时状态信息,得到实际轨迹与期望轨迹的偏差,z1,z2分别代表位置偏差和速度偏差,把此偏差输入到复杂约束机器人控制器,通过约束受限控制算法得到复杂约束虚拟控制律,进而控制机器人不会破坏约束条件。
[0078]
步骤6、同时将机器人的实时状态信息反馈给rbf神经网络,rbf自适应神经网络算法通过逼近未知非线性项,来确定自适应虚拟控制律进而抵消外界诸如轮胎打滑、风力等不确定影响。
[0079]
步骤7、将复杂约束虚拟控制律和自适应虚拟控制律进行结合,得到最终的实际控制律;
[0080]
步骤8、实际控制律控制双轮移动机器人的电机转速,来控制机器人持续平稳的运
行;
[0081]
步骤9:判断机器人是否到达目标点,如果到达目标点,机器人停止运行,如果没有到达目标点,重复步骤3至8,直至到达目标点。
[0082]
进一步的,步骤1中所述的动力学模型设计如下:
[0083]
步骤1.1、本发明考虑简单的轮式机器人系统,所述动力学方程描述如下:
[0084][0085]
其中,q=[x,y]
t
表示位置向量,x和y分别表示机器人几何中心的横坐标和纵坐标。m(q)∈r2×2表示正定惯性矩阵,表示向心矩阵和科里奥利矩阵,表示地面摩擦,τ
d
表示未知有界扰动,b(q)∈r2×2表示输入变换式矩阵,τ∈r2×1表示力矩的输入矢量,并且τ=[τ
r
,τ
l
],a
t
(q)λ∈r2×1表示非完整约束力。
[0086]
步骤1.2、确定所述动力学方程模型后,我们定义x1=q=[x,y]
t
,,然后将所述动力学方程模型转换成下面形式:
[0087][0088]
其中,x1为位置状态信息,x2为速度状态信息;
[0089]
g(t)表示系统的集总不确定性。
[0090]
进一步的,步骤3中所述的a
‑
star路径规划算法如下:
[0091]
f(n)=g(n) h(n)
[0092]
其中g(n)表示从节点n到起始点的移动代价;f(n)表示第n个节点的综合优先级,算法根据节点的优先级大小选择下一个要遍历的节点;h(n)表示节点n到终点的期望代价,是快速优先算法的启发式函数;
[0093]
所述a
‑
star路径规划算法完整步骤描述如下:
[0094]
步骤3.1、初始化开集和闭集;
[0095]
步骤3.2、把初始点放入开集,并设优先级为最高;
[0096]
步骤3.3、如果开集不为空,则从开集中选择优先级最高的节点作为节点n;
[0097]
步骤3.3.1、如果节点n是目标节点:则完成路径规划,跟踪父节点n从终点到起点;
[0098]
步骤3.3.2、如果节点n不是目标节点:将节点n从开集中移除,并置于闭集中。遍历节点n相邻的所有节点;
[0099]
步骤3.3.2.1、如果n相邻的节点m在闭集中:跳过并检测下一个节点;
[0100]
步骤3.3.2.2、如果n相邻的节点m既不在开集也不在闭集中:赋值n为m的父节点,即把节点n设置为节点m的父节点,计算m的优先级,将节点m加入开集;
[0101]
步骤3.3.2.3、如果n相邻的节点m在开集中:计算比较综合优先级f(m)的值,如果f(m)是开集中的最小值,则该节点m为父节点,并重新计算该值。
[0102]
进一步的,在步骤3中所述启发式函数h(n)在a
‑
star算法中有至关重要的作用。在极端情况下,如果h(n)是0,函数f(n)中只有g(n)发挥作用,a
‑
star算法会变成dijkstra算法。也就是说h(n)足够小,a
‑
star算法遍历节点越多,算法运行速度越慢。反之,h(n)越大,
a
‑
star就会变成快速优先算法。
[0103]
可以用下述启发式函数计算计算期望代价:
[0104][0105]
这个形式的启发函数可以计算直线距离和对角线距离。
[0106]
其中n
x
,n
y
分别表示当前点的横纵坐标,中p
x
,p
y
分别表示目标点的横纵坐标。
[0107]
进一步的,在步骤5中所述的复杂约束包括速度约束和位置约束,所述复杂约束受限控制算法的设计包括的速度约束受限控制设计和位置约束受限控制算法的设计:
[0108]
步骤5.1、位置约束受限控制算法设计如下:
[0109]
采用backstepping的方法,基于对数函数z1为位置偏差,然后选取满足约束条件的lyapunov函数v1,v1>0,为满足位置约束条件的lyapunov函数,对所选取的lyapunov函数求一阶导数,并化简得到其中位置约束虚拟控制律束虚拟控制律运用杨氏不等式使得进而确定合适的位置约束虚拟控制律α1;其中a1>2k1h1,b1<s1h1z1,a1、b1分别代表位置约束状态的上下限,a1、b1、k1均为常数。
[0110]
步骤5.2、速度约束受限控制算法设计如下:
[0111]
采用backstepping的方法,基于对数函数z2为速度偏差,然后选取满足约束条件的lyapunov函数v2,v2>0,为满足速度约束条件的lyapunov函数,对所选取的lyapunov函数求一阶导数,并化简得到其中速度约束虚拟控制律束虚拟控制律运用杨氏不等式使得进而确定合适的速度虚拟控制律α2;其中a2>2k2h2,b2<s2h2z2,a2、b2分别代表速度约束状态的上下限,a2、b2、k2均为常数。
[0112]
步骤5.3、综合位置约束虚拟控制律和速度约束虚拟控制律,得到的动态复杂约束虚拟控制律α(t)。
[0113]
进一步的,在步骤6中所述rbf自适应神经网络是一种三层的神经网络,包括输入层、隐含层和输出层;输入层到隐含层的转换是非线性的,而隐含层到输出层的转换是线性的。所述rbf自适应神经网络算法设计如下:
[0114]
对于一个未知的连续非线性函数g(z),在紧集ω∈r,可以近似为:
[0115]
g(z)=w
t
φ(z) δ(z)
[0116]
其中z∈ω是输入向量,w∈r
l
是理想权向量,l是节点数。δ(z)是近似误差,φ(z)=[φ1(z),...,φ
l
(z)]
t
∈r
l
是高斯函数:
[0117]
[0118]
是高斯函数的中心,v
i
是高斯函数的宽度。
[0119]
这里定义所述rbf自适应神经网络θ
t
φ(z) δ
z
(z),去近似不确定量g(t),使得
[0120]
g(t)=θ
t
φ(z) δ
z
(z)
[0121]
上述等式近似成立时的θ
t
,即为最合适的自适应虚拟控制律
[0122]
进一步的,所述rbf自适应神经网络算法通过对未知非线性项逼近,最终确定的自适应虚拟控制律为
[0123]
其中z2为速度偏差,a2、b2为常数,φ(z)=[φ1(z),...,φ
l
(z)]
t
∈r
l
是高斯函数,为虚拟控制律的导数。
[0124]
进一步的,步骤7中所述实际控制律为:
[0125][0126]
其中m为正定惯性矩阵,τ∈r2×1表示力矩的输入矢量,对数函数表示力矩的输入矢量,对数函数z2为速度偏差,a2、b2、k为常数,为自适应虚拟控制律,φ(z)=[φ1(z),...,φ
l
(z)]
t
∈r
l
是高斯函数。
[0127]
进一步的,所选取的位置和速度lyapunov函数其一阶导数均小于0,使得所设计的最终复杂约束虚拟控制律能使系统在时间趋于无穷大时稳定。
[0128]
根据仿真图图2和图3可以看出,系统状态可以稳定的跟踪期望值,偏差很小;根据仿真图图4和图5中,可以看出系统的跟踪偏差都限制在非对称的时变约束范围内,从而确保系统全状态在整个过程中都不违背约束条件。
[0129]
图6是机器人用激光雷达在实验室中slam建图。图7是采用a
‑
star算法循迹图。每间隔5s采样一张图片,可以看到机器人稳定运行躲过墙体障碍物,在20s后达到目标位置,并且没用破坏约束条件。
[0130]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。