1.本发明涉及中文语音处理技术领域,尤其是一种声学和语言模型训练及 联合优化的中文语音识别方法。
背景技术:
2.语音是人类最自然的交互方式。计算机发明之后让机器能够“听懂”人 类的语言、理解语言含义,并能做出正确回答就成为了人们追求的目标。随 着科学技术的不断发展,语音识别技术的出现使人类的这一理想得以实现。
[0003][0004]
现有技术中将cnn、rnn、lstm等网络结构应用于语音识别,但是这 些方法都需要大量的中文语音数据进行训练,存储和计算成本过高,且这些 模型对于特征信息的提取仍然有待提高。此外,语音识别场景中的噪声、口 音等因素,也在一定程度上影响着模型的准确率。
技术实现要素:
[0005]
为了克服现有技术中存在的上述问题,本发明提出一种声学和语言模型 训练及联合优化的中文语音识别方法。
[0006]
本发明解决其技术问题所采用的技术方案是:一种声学和语言模型训练 及联合优化的中文语音识别方法,包括如下步骤:
[0007]
步骤一,对声学模型进行训练;
[0008]
步骤二,对预训练语言模型进行训练;
[0009]
步骤三,将得到的声学模型输出特征与预训练语言模型的输出特征同时 输入联合优化网络,通过训练得到网络权重与偏置,最后使用ctc损失函数 得到模型预测值和训练样本之间的差异,将得到的损失信息利用后向传播算 法计算梯度优化网络模型参数,训练得到声学模型与语言模型联合优化的中 文语音识别算法;
[0010]
步骤四,输入语音通过步骤一到步骤三输入训练好的模型,获得最终的 识别结果。
[0011]
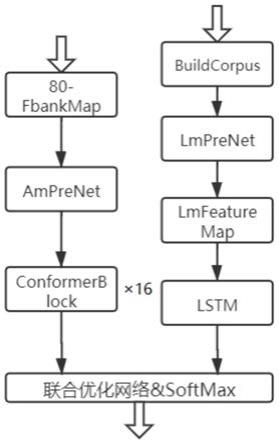
声学模型的具体训练方法如下:
[0012]
(1.1)对于输入训练语音,使用滤波器放大高频,随后通过窗长度为 25ms,步长为10ms的滑动窗口截取语音信号作为一帧,将得到的每帧信号进 行短时傅里叶变换,得到语音信号的声谱图,将得到的声谱图经过mel
‑
80滤 波器组得到符合人耳听觉习惯的声谱,取log得到输入语音信号的80
‑
channel fbank特征;
[0013]
(1.2)将步骤(1.1)中得到的80
‑
channel fbank特征通过amprenet网 络进行预处理;
[0014]
(1.3)amprenet输出的数据进入16层conformerblock进行解码。数据 依次通过前馈神经网络、多头注意力层、卷积块、层归一化得到输出,层与 层之间加入resnet加速神经
网络的收敛。
[0015]
预训练语言模型的具体训练方法如下:
[0016]
(2.1)对于输入的中文语料,首先根据汉字与拼音的映射关系建立语料 库,然后通过one
‑
hot编码转换为语料向量,语料向量进入lmprenet,通过 两层的前馈神经网络将网络原始输入映射到特征空间;
[0017]
(2.2)处理后的中文语料特征向量输入lmfeaturemap网络;
[0018]
(2.3)经过lmfeaturemap网络的数据进入lstm网络模型进行解码, 得到语言模型的特征输出信息。
[0019]
上述的一种声学和语言模型训练及联合优化的中文语音识别方法,所述 步骤(1.1)中使用的滤波器为pre
‑
emphasis滤波器,滤波器公式如下:
[0020]
x(n)
′
=x(n)
‑
λ*x(n
‑
1)
[0021]
所述短时傅里叶变换,公式如下:
[0022][0023]
其中,λ为0.97,
[0024]
其中w(τ
‑
t)为分析窗函数,公式如下:
[0025][0026]
将经过短时傅里叶变换的信号化为声谱图的公式如下:
[0027][0028]
其中nfft设置为512。
[0029]
上述的一种声学和语言模型训练及联合优化的中文语音识别方法,所述 步骤(1.2)中的amprenet网络包含两层二维卷积层、一层全连接层、一层 dropout层,二维卷积层的卷积核尺寸为3*3,步长为2*2,个数为32,激活 函数为relu,padding设置为samepadding,dropout的p
drop
=0.1。
[0030]
上述的一种声学和语言模型训练及联合优化的中文语音识别方法,所述 步骤(2.1)中建立语料库的具体方法为:首先将每条数据单独存储一行,根 据训练数据的字出现的次数进行统计,去除词频在5以下的字,每个字给予 一个id,一一对应后建立词典。
[0031]
上述的一种声学和语言模型训练及联合优化的中文语音识别方法,所述 步骤(2.1)中lmprenet神经网络含有1个嵌入层、2个全连接层、2个dropout 层,所述嵌入层参数尺寸为[vocab_size,embed_size],其中vocab_size为词典 的大小,embed_size为一个one
‑
hot向量嵌入后向量的长度,大小设置为300; 2个所述全连接层输出维度分别为300和150,其激活函数为relu函数;2个 所述dropout层的p
drop
=0.5。
[0032]
上述的一种声学和语言模型训练及联合优化的中文语音识别方法,步骤(2.2)中,所述lmfeaturemap网络由膨胀卷积层、最大池化层、加性自注 意力层、高速卷积层、前馈神经网络,所述膨胀卷积层由4个结构相同的 dilatedcnn block构成,每个所述dilatedcnn block由膨胀步长为1、1、2 的3层dilatedcnn构成,所述dilatedcnn卷积核大小为3*3,步长为1*1, 激活函数为relu,padding设置为samepadding;所述最大池化层是池化窗口大 小
为2,步长为1,padding为samepadding的一维池化层。
[0033]
上述的一种声学和语言模型训练及联合优化的中文语音识别方法,所述 步骤三中的联合优化网络由三层全连接层、tanh激活层与softmax构成,声学 模型与语言模型输入分别流入全连接层,该全连接层输入维度为1024,随后 将两个全连接层输出扩大一个维度,通过tanh激活层后流入第三层全连接层, 该层输入维度与vocabulary大小相同,最后第三层全连接层输出流入softmax 做归一化后输出,该输出为联合优化网络输出,可表述为如下公式:
[0034][0035][0036][0037]
p(y)=softmax(z
t,u
)
[0038]
其中,lm(),am()分别表示预训练语言模型与声学模型,z
t,u
,p(y)分 别表示预训练语言模型、声学模型、联合优化网络、softmax层的输出。
[0039]
本发明的有益效果是:
[0040]
(1)本发明采用amprenet、16层conformerblock等模块构成声学模型, 可以有效的将提取长序列依赖与提取局部特征相结合,从而获取更深层次的 特征信息;
[0041]
(2)本发明采用lmprenet、lmfeaturemap、lstm等模块构成语言模 型,其中lmfeaturemap由膨胀卷积层(idcnn)、最大池化层(maxpool)、 加性自注意力层(addself
‑
attention)、高速卷积层(highwaynet)、前馈神 经网络(feedforward)5个模块构成,膨胀卷积层(idcnn)可以有效扩大 卷积感受野,提取局部特征,加性自注意力层(addself
‑
attention)可以有效 提取到与当前输入关联性强的特征信息,投入更多的注意力资源所需要关注 的目标的细节信息,并抑制其它无用信息,高速卷积层(highwaynet)则可 以解决多层深度神经网络的训练收敛慢问题;
[0042]
(3)本发明采用预训练语言模型训练、声学模型与语言模型联合优化训 练的方式,将大量语音训练转变为部分语音训练与大量易于得到中文语料训 练,降低了训练难度与复杂度,还可以根据特殊场景中文训练语料训练定制 语音情景,增大了特定场景中文语音识别的适用性,且通过联合优化网络充 分利用声学和语言特征信息,解决了输出之间无关联问题,极大的提高了模 型整体的识别效果。
附图说明
[0043]
下面结合附图和实施例对本发明进一步说明。
[0044]
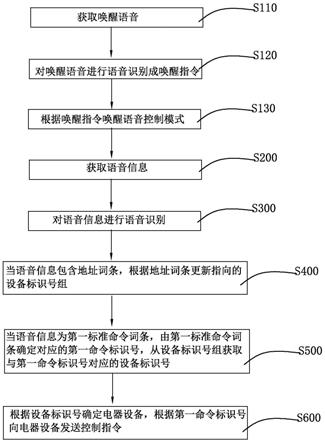
图1为本发明所公开的一种声学和语言模型训练及联合优化的中文语音 识别方法流程示意图;
[0045]
图2为amprenet网络结构示意图;
[0046]
图3为conformerblock网络结构示意图;
[0047]
图4为convolution module网络结构示意图;
[0048]
图5为lmprenet网络结构示意图;
[0049]
图6为lmfeaturemap网络结构示意图;
[0050]
图7为lstm网络结构示意图;
[0051]
图8为声学模型与预训练语言模型联合优化流程示意图。
具体实施方式
[0052]
为使本领域技术人员更好的理解本发明的技术方案,下面结合附图和具 体实施方式对本发明作详细说明。
[0053]
本发明提供了一种声学模型与语言模型的训练与联合优化的中文语音识 别方法,如图1所示,具体实施例如下:
[0054]
一、声学模型训练
[0055]
(1)对于输入训练语音,使用pre
‑
emphasis滤波器放大高频。滤波器公 式如下:
[0056]
x(n)
′
=x(n)
‑
λ*x(n
‑
1)
[0057]
其中,设置λ为0.97。
[0058]
随后通过窗长度为25ms,步长为10ms的滑动窗口截取语音信号作为一 帧,然后对信号做短时傅里叶变换(stft),去除各维信号之间的相关性, 将信号映射到低维空间,公式如下:
[0059][0060]
其中w(τ
‑
t)为分析窗函数,公式如下:
[0061][0062]
将经过stft的信号化为声谱图,其公式如下:
[0063][0064]
其中nfft设置为512。
[0065]
得到的声谱图经过mel
‑
80滤波器组,这样可以对频谱进行平滑化,消除 谐波的作用,突显原先语音的共振峰。其公式如下:
[0066][0067]
其中m设置为80。
[0068]
经过滤波后得到符合人耳听觉习惯的声谱,取log得到输入语音信号的 80
‑
channel fbank特征。
[0069]
(2)处理后的80
‑
channelfbank特征通过amprenet网络进行预处理, amprenet网络如图2所示。所述amprenet网络包含两层二维卷积层、一层 全连接层、一层dropout,二维卷积层的卷积核尺寸为3*3,步长为2*2,个 数为32,激活函数为relu,padding设置为samepadding,dropout的p
drop
=0.1。 输入进amprenet的特征向量首先进行卷积下采样,这
样可以降低特征图的维 度并且在训练时避免过拟合,得到的数据经过一层linear层与dropout层输出。
[0070]
(3)amprenet的输出数据进入16层conformerblock进行解码,如图3 所示。数据依次通过前馈神经网络(feedforward)、多头自注意力层(multi
‑
headself attention)、卷积块(convolution module)、层归一化(layernorm)后 得到输出,层与层之间加入resnet加速神经网络的收敛。所述前馈神经网络 (feedforward)由一层layernorm、两层全连接层、两层dropout层、一层 activation层构成,其中第一层全连接层输入维度为前馈神经网络 (feedforward)输入维度的4倍,第二层全连接层输入维度与前馈神经网络 (feedforward)输入维度相同。激活层激活函数为swish_activation。两层 dropout层的p
drop
=0.1。
[0071]
其输出y可由公式如下表示:
[0072]
y=(x*sigmoid(β(xw1 b1)))w2 b2[0073]
其中β设置为0.3。w1,w2,b1,b2为两个全连接层的权重矩阵与偏置。
[0074]
随后将前馈神经网络(feedforward)输入与输出向量加入残差网络得到 输出,其公式如下:
[0075]
r
out
=ffn
in
λ*ffn
out
[0076]
其中λ设置为0.5。
[0077]
随后数据x进入多头自注意力层(multi
‑
head self attention),通过线性变 换得到查询向量矩阵q,键向量矩阵k和值向量矩阵v,其公式如下:
[0078]
q=w
q
x
[0079]
k=w
k
x
[0080]
v=w
v
x
[0081]
其中w
q
,w
k
,w
v
分别为查询向量、键向量、值向量的权重矩阵。初始化方式 为glorot_uniform。
[0082]
然后根据注意力计算公式求出输出向量序列,其公式如下:
[0083]
head(i)=v
i
*softmax(s(k,q))
[0084]
其中s(k,q)为打分公式,其公式如下:
[0085][0086]
其中d
k
设置为32。
[0087]
最后得到多头自注意力层(multi
‑
head self attention)的输出,其公式如下:
[0088]
y=concat(head1,
…
,head
h
)w
o
[0089]
其中h为head个数,设置为16。
[0090]
多头自注意力层(multi
‑
head self attention)的输出进入卷积块(convolution module)提取特征,如图4所示。所述卷积块(convolution module)由2层 归一化层、3层一维卷积层、1层激活层、一层dropout、4层残差网络构成。 3层卷积层卷积核大小为1,步长为1,padding为same padding,不同之处在 于前2层卷积层卷积核个数为2*input_size,第三层与input_size相同,dropout 层p
drop
=0.1,激活层激活函数为swish_activation。随后数据再经过一层前馈神 经网络(feedforward)得到conformerblock的输出。可将
conformerblock输 出表示成如下公式:
[0091]
x
′
=x 1/2ffn(x)
[0092]
x
″
=x
′
1/2mhsa(x
′
)
[0093]
x
″′
=x
″
1/2conv(x
″
)
[0094]
y=x
″′
1/2ln(x
″′
)
[0095]
其中ffn(),mhsa(),conv(),ln()分别表示前馈神经网络(feedforward)、多 头自注意力层(multi
‑
head self attention)、卷积块(convolution module)、 层归一化(layernorm)。
[0096]
二、预训练语言模型训练
[0097]
(1)对于输入的中文语料,首先根据汉字与拼音的映射关系建立语料库。 每条数据单独存储一行,其存储形式如下:id拼音汉字;
[0098]
具体例子如下:
[0099]
7788yigerenbuxiangde,fouzejiubiepashi。一_个_人__不_想____得_,否__ 则_就__别__怕_失__。
[0100]
根据训练数据的字出现的次数进行统计,去除词频在5以下的字,每个 字给予一个id一一对应后建立词典,然后通过one
‑
hot编码转换为语料向量。 语料向量进入lmprenet,该模块如图5所示。所述lmprenet神经网络含有1 个嵌入(embedding)层、2个全连接层、2个dropout层;嵌入(embedding) 层张量参数大小为[vocab_size,embed_size],其中vocab_size为词典的大小, embed_size为一个one
‑
hot向量嵌入后向量的长度,其大小为300。所述2个 全连接层输出维度分别为300、150;其激活函数为relu函数。所述2个dropout 层的p
drop
=0.5;经过嵌入将高维稀疏的id类特征转换为稠密向量,然后通过 两层的前馈神经网络将网络原始输入映射到特征空间。
[0101]
(2)处理后的中文语料特征向量通过lmfeaturemap模块,如图6所示。 所述lmfeaturemap网络由膨胀卷积层(idcnn)、最大池化层(maxpool)、 加性自注意力层(addself
‑
attention)、高速卷积层(highwaynet)、前馈神 经网络(feedforward)5个模块构成,所述膨胀卷积层(idcnn)为4个结 构相同的dilatedcnn block构成,每个dilatedcnn block由膨胀步长为1、1、 2的3层dilatedcnn构成,dilatedcnn卷积核大小为3*3、步长为1*1、激 活函数为relu,padding设置为samepadding;所述最大池化层(maxpool)是 池化窗口大小为2、步长为1、padding为samepadding的一维池化层。输入向 量x=[x1,x2,
…
,x
n
]经过上述模块后流入加性自注意力层(addself
‑
attention), 该模块计算过程与声学模型训练步骤(3)大体相似。不同之处在于加性自注 意力层(addself
‑
attention)只采用了一个head,而且其打分公式如下所示:
[0102]
s(k,q)=w
α
*tanh(k q)
[0103]
其中w
α
是得分向量的权重矩阵,初始化方式为glorot_uniform。
[0104]
对于输入语料向量x,可将lmfeaturemap模块的输出y表述为以下公 式:
[0105]
x
′
=maxpool(idcnn(x))
[0106]
x
″
=x
′
asat(x
′
)
[0107]
x
″′
=hw(x
″
)
[0108]
y=x
″′
1/2ffn(x
″′
)
[0109]
其中asat(),hw()分别代表addself
‑
attention、highwaynet。
[0110]
lmfeaturemap模块通过膨胀卷积层(idcnn)尽可能多提取到输入序列 从local到context的完整特征信息、使用最大池化层(maxpool)保证conv 的局部不变性和时间维度的粒度、然后依次通过加性自注意力层 (addself
‑
attention)、高速卷积层(highwaynet)、前馈神经网络(feedforward) 进行高层次特征的提取映射得到输出。在最大池化层(maxpool)与高速卷积 层(highwaynet)之间加入resnet加速神经网络的收敛。
[0111]
(3)经过lmfeaturemap的数据进入lstm网络模型进行解码,如图7 所示。该网络具有对时序数据建模和捕捉数据中时域相关性的强大能力,它 可以被看作是一个由多个门组成的记忆结构。门可以允许或阻止信息沿着序 列传递,从而捕获长期依赖关系,得到语言模型的特征输出信息。lstm的 公式如下所示:
[0112][0113][0114][0115][0116][0117][0118]
其中,是隐藏层l
‑
1层在时刻t的隐藏状态,是隐藏层l层在时刻t
‑
1 的记忆单元,分别是隐藏层l层的遗忘门权重矩阵、输入门权重矩 阵、更新门权重矩阵、输出门权重矩阵,分别是隐藏层l层的遗忘门 偏差、输入门偏差、更新门偏差、输出门偏差。
[0119]
(4)训练阶段采用损失函数为均方误差,通过adam优化方式计算每个 参数的自适应学习率,来优化目标函数的模型参数。θ
t
是要优化的参数,而g
t
是相应的梯度,则θ
t 1
优化公式如下所示:
[0120]
α
t
=r1α
t
‑1 (1
‑
r1)g
t
[0121][0122]
α
t
=α
t
/(1
‑
r1)
[0123]
β
t
=β
t
/(1
‑
r2)
[0124][0125]
其中,α
t
和β
t
分别是梯度的第一矩和第二矩,η是学习率,参数r1,r2和ε 分别设置为0.9,0.999,10
‑8。
[0126]
训练完成后得到预训练语言模型。
[0127]
三、声学模型与语言模型的训练与联合优化
[0128]
将得到的声学模型输出特征与预训练语言模型的输出特征同时输入联合 优化网
络,如图8所示。该联合优化网络由三层全连接层、tanh激活层与 softmax构成。声学模型与语言模型输入分别流入全连接层,该全连接层输入 维度为1024,随后将两个全连接层输出扩大一个维度,通过tanh激活层后流 入第三层全连接层,该层输入维度与词典大小相同。最后第三层全连接层输 出流入softmax做归一化后输出通过训练得到其网络权重与偏置。可表述为如 下公式:
[0129][0130][0131][0132]
p(y)=softmax(z
t,u
)
[0133]
其中,lm(),am()分别表示预训练语言模型与声学模型,z
t,u
,p(y)分 别表示预训练语言模型、声学模型、联合优化网络、softmax层的输出。
[0134]
最后使用ctc损失函数得到模型预测值和训练标签的差异。优化器采用 adamax,此方法对学习率的上限提供了一个更简单的范围。其参数设置如下:
[0135]
learning_rate:0.0001β1:0.9β2:0.98epsilon:0.000001
[0136]
将得到的损失信息利用后向传播算法计算梯度优化网络模型参数。训练 得到声学模型与语言模型联合优化的中文语音识别算法。
[0137]
四、最后输入语音通过步骤一至步骤三输入训练好的模型,获得最终识 别结果。
[0138]
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的 保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范 围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落 在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。