1.本发明属于语音识别技术领域,具体涉及一种利用神经网络的语音活性检测方法。
背景技术:
2.在语音通话或者语音识别领域,语音活性检测技术可以有效的区分出语音片段和非语音片段,因此可以有效的降低需要处理的数据量。在识别中,只需要把语音活性段的数据进行识别;而通话领域中可以有效控制需要去传输的数据量。语音活性检测面临的最大问题就是,传统方法在非平稳噪声以及小噪声的环境下有较好的检测效果,而在大噪声以及非平稳噪声,比如音乐环境下,则无法很好的区分。
技术实现要素:
3.为克服现有技术存在的技术缺陷,本发明公开了一种利用神经网络的语音活性检测方法。
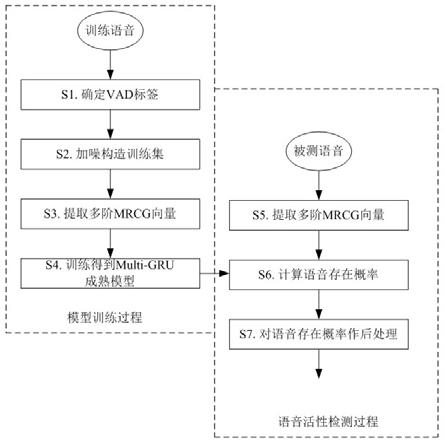
4.本发明所述利用神经网络的语音活性检测方法,包括模型训练过程和语音活性检测过程;所述模型训练过程包括以下步骤:s1.对用于训练的纯净语音确定端点检测标签;s2.对纯净语音进行随机加噪,构造训练集;s3.逐帧处理,提取训练集中每一帧语音的多阶多层门控制循环单元特征向量;s4.搭建初始多分辨率耳蜗图神经网络,将提取的多阶多层门控制循环单元特征向量作为神经网络输入,步骤s1中获取的端点检测标签作为训练目标,训练得到多分辨率耳蜗图成熟模型;所述语音活性检测过程包括以下步骤:s5.提取测试语音每一帧的多阶多层门控制循环单元特征向量;s6.经过神经网络的前向网络,对每一帧给出一个语音存在概率;s7.利用状态机对语音存在概率值进行后处理,输出语音活性检测标识;所述后处理为将离散的语音存在概率值归整为仅采用0和1表示。
5.优选的,所述步骤 s1具体为:设置一功率谱计数器, 定义该功率谱计数器当前值为fct,fct初始值为0,设置依次减小的第一经验值th1、第二经验值th2、第三经验值th3;其中第一经验值为语音帧功率谱的上限经验值、第二经验值为语音帧功率谱的中间经验值、第三经验值为语音帧功率谱的下限经验值;对纯净语音逐帧检测功率谱,当前帧的功率谱psc>第一经验值th1时,fct为0,当th2≤psc≤th1时,fct减5;当th3≤psc<th2时,fct加1;其余情况加2;最终对fct进行统计,若fct≥ 8 ,则该帧端点检测标签标注为1;否则为0。
6.优选的,所述步骤s3中多阶多层门控制循环单元特征向量提取过程为:s31.将训练集中的带噪语音通过一个n通道滤波器组变换到频域,获取n个信号子带;s32.按照两种不同帧长,提取n个信号子带的对数功率谱值,分别得到n维的第一功率谱向量coch1和第二功率谱向量coch2;s33.对第一功率谱向量coch1和第二功率谱向量coch2各自按照不同大小的矩形窗进行平均处理,得到n维的第三功率谱向量coch3和第四功率谱向量coch4;通过以上运算,每一帧可以得到n*4的多层门控制循环单元特征向量,包括四个功率谱向量coch1、coch2、coch3、coch4;s34.计算多层门控制循环单元特征向量的一阶差分特征向量和二阶差分特征向量,与多层门控制循环单元特征向量合并后得到多阶多层门控制循环单元特征向量。
7.优选的,所述s34 步骤中一阶差分特征向量计算方法如下:y(m)=b(1)*x(m) z1(m
‑
1)z1(m)=b(1)*x(m) z2(m
‑
1)
‑
a(2)*y(m)
…
z
n
‑2(m)=b(n
‑
1)*x(m) z
n
‑1(m
‑
1)
‑
a(n
‑
1)*y(m)z
n
‑1(m)=b(n)*x(m)
‑
a(n)*y(m)
ꢀꢀꢀꢀꢀ‑‑‑‑‑
(1)其中x(m)为多阶mrcg特征向量,b(1),b(2)
…
b(n)是分子的系数向量,y(m)为一阶差分特征向量,a(2)
…
a(n)是分母的系数向量,z1(m)
ꢀ…
z
n
‑1(m)为中间变量;初始化z
n
‑1(0)为0,a(2)
…
a(n)均为1;二阶差分特征向量计算是在得到一阶差分特征向量的基础上,采用公式组(1)计算一阶差分特征向量y(m)的差分特征向量y
′
(m);二阶差分特征向量计算时,分子系数向量为b
′
(1),b
′
(2)
…
b
′
(n),分母系数向量a
′
(1),a
′
(2)
…
a
′
(n)依然为1。
8.优选的,所述s4 步骤中初始多分辨率耳蜗图神经网络包括至少3个门控制循环单元模块,将当前帧、当前帧之前帧、当前帧之后帧的多阶多层门控制循环单元特征向量分别输入各个门控制循环单元模块中进行训练。
9.优选的,所述s7步骤中.利用状态机对语音存在概率值进行后处理的具体方法为:设置状态机状态0为初始态,1为确定态,2为退出态;设置启动数组、结束数组,设置存在门限值;在状态机状态为确定态下时,当语音存在概率>存在门限值时,启动数组对应元素的值置为1,同时对启动数组元素序号加1;直到元素序号超过启动数组长度后重置;当语音存在概率<存在门限值时, 结束数组对应元素的值置为1,同时对结束数组元素序号加1;直到元素序号超过结束数组长度后重置。
10.优选的,所述s7步骤中还包括以下步骤:
设置启动数组计数器和结束数组计数器,启动数组计数器对启动数组中的连续取值为1次数进行计数,结束数组计数器对结束数组中所有的1进行计数,并设置一个提前结束门限值,在结束数组计数器计数超过所述提前结束门限值时,结束运算;设置最小开始门限值、最大结束门限值、超时门限值、语音计数器;当状态机状态为0时,如果启动数组计数器> 最小开始门限值,将状态机状态置为1,并把结束数组置为0;启动数组计数器 <最小开始门限值,则维持状态机状态0,。
11.当状态机状态为1时,语音计数器加1,如果语音计数器>超时门限值,或者结束数组计数器>最大结束门限值,强制结束并把状态机状态置为2;否则维持状态机状态为1;状态机状态置为2后,将启动数组和结束数组内全部元素清零,启动数组和结束数组的元素序号均置为1,再将状态机状态置为0。
12.本发明利用神经网络良好的分类性能,提取带噪语音的特定特征,并通过预先训练好的神经网络模型,对语音以及噪声进行一个初步的分类并求得一个语音存在概率。通过状态机对获得的语音存在概率进行后处理,从而得到一个平滑且相对准确的语音活性检测标识。
附图说明
13.图1为本发明所述检测方法的一个具体流程示意图;图2为本发明所述multi
‑
gru网络的一个具体实施方式示意图;图2中relu和softmax表示不同的函数名。
具体实施方式
14.下面对本发明的具体实施方式作进一步的详细说明。
15.本发明所述本发明所述利用神经网络的语音活性检测方法,将神经网络结合传统方法实现非稳态噪声、稳态噪声和人声区分的语音活性检测,具体包括以下步骤:模型训练过程s1.对用于训练的纯净语音确定vad标签;s2.对纯净语音进行随机加噪,构造训练集;s3.逐帧处理,提取训练集中每一帧语音的多阶mrcg(多分辨率耳蜗图,multi
‑
resolution cochleagram)特征向量。
16.s4.构建multi
‑
gru(多层门控制循环单元)网络,利用训练集对其进行训练,得到multi
‑
gru成熟模型;语音活性检测过程:s5.提取测试语音每一帧的多阶mrcg特征向量;s6.经过神经网络的前向网络,对每一帧给出一个语音存在概率;s7.利用状态机对语音存在概率值进行后处理,输出一个平滑且稳定的语音活性检测标识。
17.实施方式中的具体的的流程如下:
s1.对训练集中的纯净语音进行标注,将语音帧vad(端点检测)标签标注为1,将静音帧vad标签标注为0。
18.由于是纯净语音,使用现有技术下基于能量的语音活性检测和标记方法就可以起到比较准确且高效的标注作用。
19.以下是步骤s1中利用语音能量的快速语音活性标注方法流程介绍。可以按照图1所示方式进行:所述步骤 s1具体为:设置一功率谱计数器, 定义功率谱计数器当前值为fct,其初始值为0,设置依次减小的第一经验值th1、第二经验值th2、第三经验值th3;其中第一经验值为语音帧功率谱的上限经验值、第二经验值为语音帧功率谱的中间经验值、第三经验值为语音帧功率谱的下限经验值;对纯净语音逐帧检测功率谱,当前帧的功率谱psc>第一经验值th1时,fct为0,当th2≤psc≤th1时,fct减5;当th3≤psc<th2时,fct加1;其余情况加2;最终对fct进行统计,若fct≥ 8 ,则该帧端点检测标签标注为1;否则为0。
20.第一经验值表示识别为语音的下限,高于第一经验值,可以断定为语音,而在第一经验值th1和第二经验值th2之间,根据经验表明语音可能性较大,因此设置减5,而在第二经验值th2和第三经验值th3之间 ,语音可能性低 ,其余情况下 ,表示几乎不可能是语音 。为避免vad标签中间的1由于干扰而出现不连续,一旦判定为语音,则尽可能让状态保持在语音,而不因个别帧干扰退出语音状态 ,因此设置单次减值较多,而加值较少;除非出现连续多帧低于最小门限th3。
21.一个设置方式为th1设置为109,th2设置为108,th3设置为107。
22.每帧对当前的fct值进行统计,若fct≥ 8 ,则该帧vad标签标注为0;否则为1。
23.s2.对纯净语音进行随机加噪,构造训练集;可进行随机信噪比和常见场景噪声的加噪。
24.s3.对训练集逐帧处理,提取训练集中每一帧语音的多阶mrcg特征向量;一个具体的特征提取方法如下:s31.首先将训练集中的带噪语音通过一个64通道gammatone滤波器组变换到频域,获取64个信号子带;s32.按照40ms一帧,帧移10ms提取64个子带的对数功率谱值得到64维的第一功率谱向量coch1,按照200ms一帧,帧移10ms 提取64个子带的对数功率谱值得到64维的第二功率谱向量coch2。
25.s33.对第一功率谱向量coch1按照5*5矩形窗进行平均处理,得到64维的第三功率谱向量coch3。
26.5*5矩形窗表示有5帧时间长度,且同一帧临近的5个频带组成的矩形窗。
27.对第二功率谱向量coch2按照20*20的矩形窗进行平均处理,得到64维的第四功率谱向量coch4。
28.通过以上运算,每一帧可以得到64*4的mrcg特征向量,包括四个功率谱向量coch1、coch2、coch3、coch4。
29.s34.再计算mrcg特征向量的一阶差分特征向量和二阶差分特征向量,与mrcg特征向量合并后得到64*4*3=768维的多阶mrcg特征向量。
30.其中一阶差分特征向量计算方法如下:y(m)=b(1)*x(m) z1(m
‑
1)z1(m)=b(1)*x(m) z2(m
‑
1)
‑
a(2)*y(m)
…
z
n
‑2(m)=b(n
‑
1)*x(m) z
n
‑1(m
‑
1)
‑
a(n
‑
1)*y(m)z
n
‑1(m)=b(n)*x(m)
‑
a(n)*y(m)
ꢀꢀꢀ‑‑‑‑
(1)其中x(m)为多阶mrcg特征向量,m=1,2
…
768,b(1),b(2)
…
b(n)是分子的系数向量,y(m)为计算的一阶差分特征向量,a(1),a(2)
…
a(n)是分母的系数向量。
31.初始化x(0),y(0), z
n
‑1(0)为0,a(1),a(2)
…
a(n)均为1。
32.二阶差分特征向量计算是在得到一阶差分特征向量的基础上,利用公式组(1)计算一阶差分特征向量y(m)的差分特征向量y
′
(m);二阶差分特征向量计算时,分子系数向量为b
′
(1),b
′
(2)
…
b
′
(n),分母系数向量a
′
(1),a
′
(2)
…
a
′
(n)依然为1。
33.s4.搭建初始multi
‑
gru神经网络,将提取的多阶mrcg特征向量作为神经网络输入,步骤s1中获取的vad标签作为训练目标,训练得到multi
‑
gru成熟模型。
34.一个具体的multi
‑
gru网络应用如图2所示如下:将不同帧的多阶mrcg特征向量xi
‑
3、xi、xi 3分别输入至3个h维度的gru模块中,得到3个维度均为h的输出量h1、h2、h3;将其分别通过m维的全连接层(fully connected layers,fc),其维度变为m;再经过relu函数的激活层处理后进行拼接,得到3m维的数据;将数据传入至下一个2维全连接层,输出维度为2的数据;最后通过一个softmax函数激活层计算得到期望目标,即网络模型的输出。
35.其中,输入的xi表示当前语音帧的多阶mrcg特征向量,xi
‑
3表示当前语音帧之前的第三帧语音信号的多阶mrcg特征向量,xi 3表示当前语音帧之后的第三帧语音信号的多阶mrcg特征向量。如果帧数超出给定的帧,则用0补充。虽然multi
‑
gru网络传入一帧数据也可进行计算,但是增加2帧即前面的第三帧多阶mrcg特征向量xi
‑
3和后面的第三帧多阶mrcg特征向量xi 3,可以让网络获取音频的前后信息,更有利于做出当前帧是否为语音的判断。
36.语音活性检测过程如下:s5.提取待检测语音的多阶mrcg特征向量,可按照步骤s3的方式进行。
37.s6.待检测语音的多阶mrcg特征向量输入multi
‑
gru成熟模型,输出每一帧的语音存在概率pred(l),l表示帧数。
38.s7.对s6中输出的语音存在概率pred(l)做后处理。
39.后处理目的是使数据大小分散在0到1之间的语音存在概率变成一个稳定连续的只有0和1的标签,从而简化语音应用场景中的运算,降低数据处理量。采用连续标签也可以将实际语音中常见的短暂停顿以若干0标签表示,避免停顿造成数据标签的中断。
40.如果没有后处理,那中间的停顿可能会被标签为0,一段话变成两段话,不符合实际需求。
41.由网络输出的每一帧语音存在概率是0~1之间的离散值,通过和门限值比较的处理,可以将离散值转变为仅有0,1两种取值。
42.可采用设置数组和门限值的方式,对后处理以状态机形式进行,一个具体实施方式如下:先设置启动数组start_buf和结束数组end_buf,设置存在门限值threshold为 0.5。start_buf和end_buf主要目的是记录连续帧中语音存在概率pred(l)和门限大小的比较情况。start_buf长度可设置为30,end_buf长度可设置为70,start_buf和end_buf的数组元素序号分别用start_idx和end_idx表示,初始值都为1。
43.即start_buf(start_idx)为start_buf数组中第start_idx个元素;end_buf(end_idx) 为end_buf数组中第end_idx个元素;start_idx =end_idx=1时,初始值start_buf(1)和end_buf(1)均为1。
44.end_buf的长度比start_buf长是为了语音在结束的时候可以更慢的结束,以减少对能量较弱的语音误判。
45.当pred(l)>threshold时,start_buf(start_idx)的值置为1,同时对start_idx加1;当pred(l)<threshold时,end_buf(end_idx)的值为1,同时对end_idx加1。当start_idx超过30或end_idx超过70的时候,分别将start_idx或end_idx重置为1,表示重新开始统计。
46.如有10帧网络输出的
ꢀ“
语音存在概率”分别为0.1,0.3,0.41, 0.45, 0.44, 0.8, 0.9, 0.2, 0.4, 0.1;threshold值为 0.5那经过运算处理后;startbuf中对应这10帧的值就为0 0 1 1 1 1 1 0 1 0endbuf中对应这10帧的值就为1 1 0 0 0 0 0 1 0 1。
47.通过上述处理方式,将0~1之间的离散值语音存在概率转化为仅有0,1两种取值。
48.为了减少对能量较弱的语音误判,提高抗误检测的能力及延缓结束;可以设置启动数组计数器start_count和结束数组计数器end_count,计数器start_count对启动数组start_buf中的连续取值为1次数进行计数,end_count计数器对结束数组end_buf中所有的1进行计数。这样设置的目的是:start_count通过计算连续的1来提高抗误检测的能力,end_buf通过计算所有的1来延缓结束时间。
49.例如:数组start_buf:0 1 0 0 0 0 1 1 1 1 1 0,有5个连续1出现;则start_count为5;而start_buf中出现的第2个 1很可能是误判值,通过计算连续的1,结合后面的运算,可以将这个误判值忽略,提高抗误检测的能力;数组end_buf :1 1 1 0 0 0 1 1 1 1 0 1 1 1 ,共有10个1,end_count=10。
50.其中可能语音间隙段为0,通过计算所有的1,并设置一个提前结束门限值,在end_count计数器计数超过所述提前结束门限值时,结束运算,可以避免提前结束。
51.然后用状态机来输出最终语音活性检测标签,具体实施方法如下:
状态机是语音活性检测中常用的一种方式,可以根据需求定制状态以及对应状态中的行为,设置状态机好处主要是,可以在不同的状态 使用不同的状态所对应的判断条件。
52.假设状态机状态用vad_state表示,0为初始态,1为确定态表示确定语音段,2为退出态。
53.设置最小开始门限值vad_start_min_frms=8,设置最大结束门限值vad_end_max_frms=20;设置超时门限值1vad_expire_frms=400。
54.设置一个语音计数器vad_on_frames,其目的是记录语音活性检测标志连续为1的次数,初始值为0;运算从初始态0开始。
55.当vad_state为0时,如果start_count > vad_start_min_frms,表示满足语音段start的标准,vad_state置为1.vad_on_frames初始化为0,并把end_buf置为0。start_count < vad_start_min_frms,则维持vad_state=0,表示不符合进入语音段的标准。
56.状态0为初始态,可以理解成准备阶段;本方法中,初始状态为0,该状态主要就是去做start_count 与最小开始门限值vad_start_min_frms的比较。
57.当vad_state为1时,vad_on_frames计数器加1,如果vad_on_frames> vad_expire_frms ,表示一段语音已经超时,则强制结束并把vad_state置为2;或者end_count > vad_end_max_frms,表示结束计数器已经大于一个门限,vad_state置为2。否则维持vad_state=1。
58.状态1为确定态,即满足状态0后切入状态1,也就是确定是语音段.状态1下根据文中描述的在满足条件时去结束。
59.当vad_state为2时,将vad_state置为0,将start_buf和end_buf全部清零,start_idx和end_idx置为1。表示整个状态机重新开始运算。
60.状态2为退出态,退出态下状态机可重置状态和清零各类寄存器。
61.上述过程处理可以提高语音活性检测的稳定性,把离散且不连续的0
‑
1的数变为稳定连续的0,1值,使得最终输出连续。
62.前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

