技术特征:
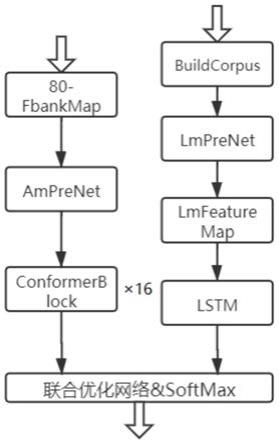
1.一种声学和语言模型训练及联合优化的中文语音识别方法,其特征在于,包括如下步骤:步骤一,对声学模型进行训练;步骤二,对预训练语言模型进行训练;步骤三,将得到的声学模型输出特征与预训练语言模型的输出特征同时输入联合优化网络,通过训练得到网络权重与偏置,最后使用ctc损失函数得到模型预测值和训练样本之间的差异,将得到的损失信息利用后向传播算法计算梯度优化网络模型参数,训练得到声学模型与语言模型联合优化的中文语音识别算法;步骤四,输入语音通过步骤一到步骤三输入训练好的模型,获得最终的识别结果。声学模型的具体训练方法如下:(1.1)对于输入训练语音,使用滤波器放大高频,随后通过窗长度为25ms,步长为10ms的滑动窗口截取语音信号作为一帧,将得到的每帧信号进行短时傅里叶变换,得到语音信号的声谱图,将得到的声谱图经过mel
‑
80滤波器组得到符合人耳听觉习惯的声谱,取log得到输入语音信号的80
‑
channel fbank特征;(1.2)将步骤(1.1)中得到的80
‑
channel fbank特征通过amprenet网络进行预处理;(1.3)amprenet输出的数据进入16层conformerblock进行解码。数据依次通过前馈神经网络、多头注意力层、卷积块、层归一化得到输出,层与层之间加入resnet加速神经网络的收敛。预训练语言模型的具体训练方法如下:(2.1)对于输入的中文语料,首先根据汉字与拼音的映射关系建立语料库,然后通过one
‑
hot编码转换为语料向量,语料向量进入lmprenet,通过两层的前馈神经网络将网络原始输入映射到特征空间;(2.2)处理后的中文语料特征向量输入lmfeaturemap网络;(2.3)经过lmfeaturemap网络的数据进入lstm网络模型进行解码,得到语言模型的特征输出信息。2.根据权利要求1所述的一种声学和语言模型训练及联合优化的中文语音识别方法,其特征在于,所述步骤(1.1)中使用的滤波器为pre
‑
emphasis滤波器,滤波器公式如下:x(n)
′
=x(n)
‑
λ*x(n
‑
1)所述短时傅里叶变换,公式如下:其中,λ为0.97,其中w(τ
‑
t)为分析窗函数,公式如下:将经过短时傅里叶变换的信号化为声谱图的公式如下:其中nfft设置为512。
3.根据权利要求2所述的一种声学和语言模型训练及联合优化的中文语音识别方法,其特征在于,所述步骤(1.2)中的amprenet网络包含两层二维卷积层、一层全连接层、一层dropout层,二维卷积层的卷积核尺寸为3*3,步长为2*2,个数为32,激活函数为relu,padding设置为samepadding,dropout的p
drop
=0.1。4.根据权利要求1所述的一种声学和语言模型训练及联合优化的中文语音识别方法,其特征在于,所述步骤(2.1)中建立语料库的具体方法为:首先将每条数据单独存储一行,根据训练数据的字出现的次数进行统计,去除词频在5以下的字,每个字给予一个id,一一对应后建立词典。5.根据权利要求4所述的一种声学和语言模型训练及联合优化的中文语音识别方法,其特征在于,所述步骤(2.1)中lmprenet神经网络含有1个嵌入层、2个全连接层、2个dropout层,所述嵌入层参数尺寸为[vocab_size,embed_size],其中vocab_size为词典的大小,embed_size为一个one
‑
hot向量嵌入后向量的长度,大小设置为300;2个所述全连接层输出维度分别为300和150,其激活函数为relu函数;2个所述dropout层的p
drop
=0.5。6.根据权利要求5所述的一种声学和语言模型训练及联合优化的中文语音识别方法,其特征在于,步骤(2.2)中,所述lmfeaturemap网络由膨胀卷积层、最大池化层、加性自注意力层、高速卷积层、前馈神经网络,所述膨胀卷积层由4个结构相同的dilatedcnn block构成,每个所述dilatedcnn block由膨胀步长为1、1、2的3层dilatedcnn构成,所述dilatedcnn卷积核大小为3*3,步长为1*1,激活函数为relu,padding设置为samepadding;所述最大池化层是池化窗口大小为2,步长为1,padding为samepadding的一维池化层。7.根据权利要求6所述的一种声学和语言模型训练及联合优化的中文语音识别方法,其特征在于,所述步骤三中的联合优化网络由三层全连接层、tanh激活层与softmax构成,声学模型与语言模型输入分别流入全连接层,该全连接层输入维度为1024,随后将两个全连接层输出扩大一个维度,通过tanh激活层后流入第三层全连接层,该层输入维度与词典大小相同,最后第三层全连接层输出流入softmax做归一化后输出,该输出为联合优化网络输出,可表述为如下公式:可表述为如下公式:可表述为如下公式:p(y)=softmax(z
t,u
)其中,lm(),am()分别表示预训练语言模型与声学模型,z
t,u
,p(y)分别表示预训练语言模型、声学模型、联合优化网络、softmax层的输出。
技术总结
本发明公开了一种声学和语言模型训练及联合优化的中文语音识别方法,分别对声学模型和预训练语言模型进行训练,将得到的声学模型和预训练语言模型的输出特征同时输入联合优化网络,训练得到声学模型与语言模型联合优化的中文语音识别算法,然后输入语音经过上述处理获得最终的识别结果。本发明采用预训练语言模型训练、声学模型与语言模型联合优化训练的方式,将大量语音训练转变为部分语音训练与大量易于得到中文语料训练,降低了训练难度,还可以根据特殊场景中文训练语料训练定制语音情景,增大了特定场景中文语音识别的适用性,且通过联合优化网络充分利用声学和语言特征信息,解决了输出之间无关联问题,极大的提高了模型整体的识别效果。了模型整体的识别效果。了模型整体的识别效果。
技术研发人员:熊海良 刘凯 朱维红 周洪超 周斌 周智伟 许玉丹
受保护的技术使用者:山东大学
技术研发日:2021.08.17
技术公布日:2021/12/16
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。