基于ddt深度神经模型结构的监控图像地点信息识别方法
技术领域
1.本说明书涉及计算机视觉领域,特别是涉及一种基于深度学习的视频图像中叠加地点信息文字的识别方法。
背景技术:
2.视频监控在平安城市、智能交通、智慧城市等重点行业基础设施和公共服务的持续建设带动了安防监控行业的高速发展。根据公安部发布的《ga/t 751
‑
2008视频图像文字标注规范》,监控图像中的辖区地点信息,必须按照“视频图像设备基础信息”——简称“一机一档”,进行人工的正确标注。这不仅是贯彻落实公安部《关于加强公安大数据智能化建设应用的指导意见》的工作内容要求,也是“全国公安视频图像数据治理专项”任务的基础保障。
3.全国由公安部组织建设的视频监控规模已经达到1000万量级,采用人工方式对监控图像中的标注信息进行核查是极其低效、且不可持续的,所以通过一种ai算法自动识别监控图像中的地点信息,对当前公安部专项任务推进工作具有重要的现实意义。
4.常见基于深度学习的文字信息识别采用的是循环神经网络结构,或者使用纯基于注意力机制的transformer结构对文本数据进行识别。这两种结构识别地点信息都有很大的弊端,前者当字符过长时,模型只能保存部分提取到的特征;对图像提取的特征向量并非以单个字符为单元;最后导致不能保证稳定识别出整个文字行。后者使用注意力机制对图像进行特征提取缺少丰富性;需要配合增加位置编码信息,也会在一定程度上降低识别结果精度。
技术实现要素:
5.为解决上述问题,本文提出一种基于ddt深度模型结构的监控图像地点信息识别的方法。
6.所述ddt深度模型为deep feature
‑
decoder transformer深度神经模型。该模型的deep feature子结构对输入的监控图像进行特征提取,并对提取到的特征进行降维,使其序列化。之后将特征序列并行输入decoder子结构,在decoder子结构中,采用多头注意力机制对特征进行循环解码,将解码的结果与汉字库进行映射,选指定长度的字符作为地点识别的结果。并使用基于先验概率的交叉熵函数计算识别结果的损失,并将该损失反馈给网络模型,优化网络参数。
7.本发明提出的基于ddt深度模型结构的监控图像地点信息识别的方法,包括如下步骤:
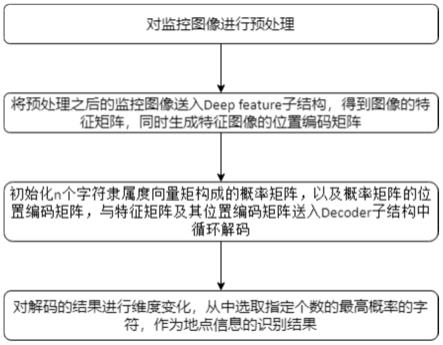
8.步骤i:对输入的监控图像进行预处理,调整图像尺寸等于深度神经网络的输入维度;
9.步骤ii:将预处理之后的图像送入所述的deep
‑
feature子结构中,得到监控图像的特征矩阵;
10.步骤iii:从标准正态分布n(0,1)中随机取值,生成与步骤ii中特征矩阵等尺寸的位置矩阵,该位置矩阵代表特征矩阵的位置信息;
11.步骤iv:从标准正态分布n(0,1)中随机取值,生成由隶属度向量构成的概率矩阵;以相同的取值方法,生成与概率矩阵等尺寸的位置矩阵,该位置矩阵代表概率矩阵的位置信息;
12.步骤v:载入深度神经网络模型,将特征矩阵及其位置矩阵、概率矩阵及其位置矩阵作为decoder子结构的输入,对特征矩阵进行循环解码,计算识别结果的概率矩阵;
13.步骤vi:使用线性映射矩阵将步骤v的结果映射至t维,其中t等于字符集合s={s1,s2,.......s
t
,}的大小,得到模型对字符集合中每个字符预测的概率。输出每个隶属度向量中概率值最高的索引值,根据字符集合中索引值与字符映射关系,将索引值替换为字符,作为地点信息识别结果输出。
14.优选地,步骤vi之后还设有步骤vii:使用所述的先验概率交叉熵公式计算识别结果与地点字符的损失,并将损失值反馈给网络模型使其更新参数,优化网络模型。
15.优选的,所述步骤ii的具体步骤如下:
16.步骤ii
‑
1:将经过预处理之后的监控图像,使用深度特征提取网络进行图像特征提取,从高到低得到c1,c2,c3三个深度特征图;
17.步骤ii
‑
2:使用卷积操作将特征图c1,c2,c3的通道维度统一,并使用如下公式形成融合特征p1,p2,p3;
18.p1=c119.p2=0.5c2 0.5up
×2(p1)
20.p3=0.5c3 0.5up
×2(p2)
21.其中up
×2(p)代表使用双线性插值函数对特征图p进行2倍上采样操作,之后采用等权相加融合高层与低层特征;
22.步骤ii
‑
3:使用如下公式对融合特征p3进行维度变换,得到监控图像的特征矩阵a:
23.a
c
×
hw
=f(p
c
×
h
×
w
)
24.函数f(p
c
×
h
×
w
)表示对尺寸为c
×
h
×
w的张量p进行维度变换得到尺寸为c
×
hw的矩阵a。
25.优选的,所述步骤v的具体步骤如下:
26.步骤v
‑
1:记特征矩阵为a,其位置矩阵记为a
loc
,将矩阵a与a
loc
进行矩阵相加得到矩阵a
′
,记概率矩阵为b,其位置矩阵记为b
loc
,将b与b
loc
进行矩阵相加得到矩阵b
′
;
27.步骤v_2:使用所述公式计算矩阵b
′
与矩阵b
′
的正负相关协方差矩阵,将该正负相关协方差矩阵与初始b
′
进行矩阵相加,并对相加的结果进行归一化得到矩阵b
ln
;
28.步骤v
‑
3:使用所述公式计算矩阵a
′
与矩阵b
ln
的正负相关协方差矩阵,将该正负相关协方差矩阵与矩阵b
ln
进行矩阵相加;
29.步骤v
‑
4:将步骤v
‑
3的结果与线性映射矩阵l1相乘,然后对相乘结果归一化;
30.步骤v
‑
5:将隶属度向量进行升维,之后使用激活函数对升维的向量进行激活,最后降维至初始维度,得到新一轮字符隶属度向量构成的矩阵b1;
31.步骤v
‑
6:将a、a
loc
、b1、b
loc
作为新一轮decoder子结构的输入,重复上述步骤,对特
征矩阵a循环解码。
32.优选的,所述步骤v
‑
2,v
‑
3计算正负相关协方差矩阵p公式如下:
33.q
i
,k
i
,v
i
=f
splite
(q,k,v)
[0034][0035]
p=f
concat
(f
att
(q1,k1,v1),f
att
(q2,k2,v3),...,f
att
(q
n’k
n
,v
n
))
[0036]
其中q,k,v表示输入特征的线性映射矩阵;
[0037]
f
splite
(q,k,v)表示分别将尺寸为h
×
w的线性映射矩阵q,k,v进行维度变换,形成n个尺寸为的子映射矩阵;
[0038]
f
att
(q
i
,k
i
,v
i
)表示计算q
i
,k
i
,v
i
的正负相关协方差矩阵;
[0039]
f
concat
(f
att
(q1,k1,v1),f
att
(q2,k2,v3),...,f
att
(q
n
,k
n
,v
n
))表示将n个尺寸为的子正负相关协方差矩阵进行维度变换,形成尺寸为h
×
w的正负相关协方差矩阵。
[0040]
优选的,所述步骤vii具体计算方式如下:
[0041][0042]
其中,w
i
代表模型预测第i字符的权重;t
i
代表第i字符标签对应的索引值,索引值格式采用one
‑
hot编码的形式;y
i
代表模型预测第i字符的概率,n代表地点信息字符串的长度。
[0043]
本发明的有益效果包括:
[0044]
(1)相比使用注意力机制,ddt模型的deep feature子结构采用卷积特征网络进行特征提取,使用卷积的方式能更好的提取图像的特征,并减少了对字符位置编码的需求。
[0045]
(2)在decoder子结构中,采用注意力机制对图像特征进行解码。相比使用循环神经网络进行字符识别,使用注意力机制解决了对特征向量长度依赖的这一问题,对输入的全局特征进行解码,更好利用了图像特征,同时识别与原图像中等长的地点信息,大大增加了识别精度。
附图说明
[0046]
图1是基于ddt深度神经模型图像地点信息识别方法的流程示意图。
[0047]
图2是ddt深度神经模型结构图。
[0048]
具体实施方法
[0049]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0050]
结合图1、图2所示,基于ddt深度模型结构的监控图像地点信息识别的方法,包括如下步骤:
[0051]
步骤i:对输入的监控图像进行预处理,调整图像尺寸等于深度神经网络的输入尺
寸。
[0052]
本实施例中,输入神经网络的监控图像尺寸为96
×
32像素。
[0053]
步骤ii:将预处理之后的图像送入所述的deep
‑
feature子结构中,得到监控图像的特征矩阵。
[0054]
ii
‑
1、将经过预处理之后的监控图像,使用深度特征提取网络进行图像特征提取,从高到低得到c1,c2,c3三个深度特征图。
[0055]
ii
‑
2、使用卷积操作将特征图c1,c2,c3的通道维度统一,并使用如下公式形成融合特征p1,p2,p3。
[0056]
p1=c1[0057]
p2=0.5c2 0.5up
×2(p1)
[0058]
p3=0.5c3 0.5up
×2(p2)
[0059]
本实施例中,特征图c1,c2,c3的通道统一设置为768维。
[0060]
up
×2(p)代表使用双线性插值函数对特征图p进行2倍上采样操作,之后采用等权相加融合高层与低层特征。
[0061]
ii
‑
3、使用如下公式对融合特征p3进行维度变换,得到监控图像的特征矩阵a:
[0062]
a
c
×
hw
=f(p
c
×
h
×
w
)
[0063]
函数f(p
c
×
h
×
w
)表示对尺寸为c
×
h
×
w的张量p进行维度变换得到尺寸为c
×
hw的矩阵a。
[0064]
本实施例中,c=768,设置h=4,w=24,经过维度变换后得到96个768维的特征向量构成的特征矩阵,表示为:a
96
×
768
={a1,a2,...,a
96
}
t
。
[0065]
步骤iii:从标准正态分布n(0,1)中随机取值,生成与步骤ii中特征矩阵等尺寸的位置矩阵,该位置矩阵代表特征矩阵的位置信息。
[0066]
这里位置矩阵记为a
loc
。
[0067]
步骤iv:从标准正态分布n(0,1)中随机取值,生成由隶属度向量构成的概率矩阵。以相同的取值方法,生成与概率矩阵等尺寸的位置矩阵,该位置矩阵代表概率矩阵的位置信息。
[0068]
假设监控图像中待识别地点信息的字符串最大长度为n,生成n个768维隶属度向量构成的概率矩阵。
[0069]
在本实施例中,设置字符串最大长度为10,概率矩阵可表示为:b
10
×
768
={b1,b2,...,b
10
}
t
,其对应的位置矩阵记为b
loc
[0070]
步骤v:载入深度神经网络模型,将特征矩阵及其位置矩阵、概率矩阵及其位置矩阵作为decoder子结构的输入,对特征矩阵进行循环解码,计算识别结果的概率矩阵。
[0071]
v
‑
1、记特征矩阵为a,其位置矩阵记为a
loc
。将矩阵a与a
loc
进行矩阵相加得到矩阵a
′
。记概率矩阵为b,其位置矩阵记为b
loc
。将b与b
loc
进行矩阵相加得到矩阵b
′
。
[0072]
其中,矩阵a
′
的尺寸为96
×
768,b
′
的尺寸为10
×
768。
[0073]
v
‑
2、使用所述公式计算矩阵b
′
与矩阵b
′
的正负相关协方差矩阵,将该正负相关协方差矩阵与初始b
′
进行矩阵相加,并对相加的结果进行归一化得到矩阵b
ln
。
[0074]
v
‑
3、使用所述公式计算矩阵a
′
与矩阵b
ln
的正负相关协方差矩阵,将该正负相关协方差矩阵与矩阵b
ln
进行矩阵相加。
[0075]
计算正负相关协方差矩阵p公式如下:
[0076]
q
i
,k
i
,v
i
=f
splite
(q,k,v)
[0077][0078]
p=f
concat
(f
att
(q1,k1,v1),f
att
(q2,k2,v3),...,f
att
(q
n’k
n
,v
n
))
[0079]
其中q,k,v表示输入特征的线性映射矩阵。
[0080]
f
splite
(q,k,v)表示分别将尺寸为h
×
w的线性映射矩阵q,k,v进行维度变换,形成n个尺寸为的子映射矩阵。
[0081]
f
att
(q
i
,k
i
,v
i
)表示计算q
i
,k
i
,v
i
的正负相关协方差矩阵。
[0082]
f
concat
(f
att
(q1,k1,v1),f
att
(q2,k2,v3),...,f
att
(q
n
,k
n
,v
n
))表示将n个尺寸为的子正负相关协方差矩阵进行维度变换,形成尺寸为h
×
w的正负相关协方差矩阵。
[0083]
其中,h和w等于输入矩阵的尺寸。
[0084]
在本实例中,h=10,w=768,并设置n=12。
[0085]
v
‑
4:将步骤v
‑
3的结果与线性映射矩阵l1相乘,然后对相乘结果归一化。
[0086]
在本实例中,线性映射矩阵l1的尺寸为768
×
768。
[0087]
v
‑
5:将隶属度向量进行升维,之后使用激活函数对升维的向量进行激活,最后降维至初始维度,得到新一轮字符隶属度向量构成的矩阵b1。
[0088]
在本实例中,使用尺寸为768
×
2048矩阵与步骤v
‑
4的结果相乘,将隶属度向量进行升维至2048,使用relu激活函数对升维的向量进行激活,最后降维至768,得到新一轮字符隶属度向量构成的矩阵b1。
[0089]
v
‑
6:将a、a
loc
、b1、b
loc
作为新一轮decoder子结构的输入,重复上述步骤,对特征矩阵a循环解码。
[0090]
步骤vi:使用线性映射矩阵将步骤v的结果映射至t维,其中t等于字符集合s={s1,s2,.......s
t
,}的大小,得到模型对字符集合中每个字符预测的概率。输出每个隶属度向量中概率值最高的索引值,根据字符集合中索引值与字符映射关系,将索引值替换为字符,作为地点信息识别结果输出。
[0091]
在本实施例中,t的值(参照汉字二级字库)应在6000以上。
[0092]
优选地,步骤vii:使用如下先验概率交叉熵公式计算识别结果与地点字符的损失,并将损失值反馈给网络模型使其更新参数,优化网络模型。
[0093][0094]
其中,w
i
代表模型预测第i字符的权重;t
i
代表第i字符标签对应的索引值,索引值格式采用one
‑
hot编码的形式;y
i
代表模型预测第i字符的概率,n代表地点信息字符串的长度。
[0095]
在本实施例中,与步骤iv相同,设置n=10。
[0096]
本发明,在4000例样本下——即从监控图像中随机选择4000行地点信息字符串(不含英文、数字、罗马字符、标点符号),识别精度指标如下:
[0097]
全匹配率91.8%,平均编辑距离百分比2.81%。
[0098]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。