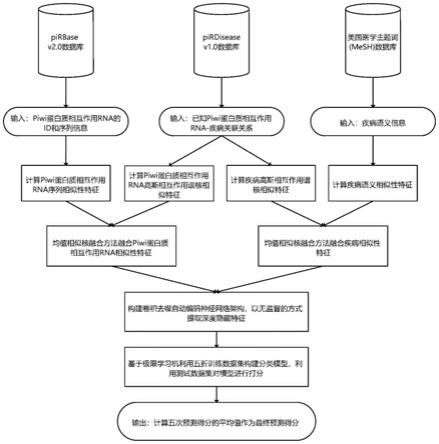
基于卷积去噪自编码机的pirna
‑
疾病关联关系预测方法
技术领域
1.本发明涉及涉及深度学习和生物信息学技术领域,更具体地说,特别涉及一种基于卷积去噪自编码机的pirna
‑
疾病关联关系预测方法。
背景技术:
2.近年来,piwi蛋白质相互作用rna被认为是细胞生物学的重要媒介,并成为小分子非编码rna家族的最新成员。piwi蛋白质相互作用rna是一种包含21
‑
30个核苷酸的单链rna,在不同的生物体中主要与argonaute家族piwi蛋白成员(argonaute3、piwi、aubergine)相互作用,形成与表观遗传调控、精子发生、转座子沉默、mrna调控和发育以及基因组重排相关的pirna/piwi复合物。该复合物可通过识别pirna序列引起异染色质修饰和转座子沉默,已成为高度保守的小分子rna引导基因调控机制的典范。
3.此外,piwi蛋白质相互作用rna是癌症基因组学的新兴参与者,参与多种人类疾病(包括癌症)相关的异常表达。传统的生物学实验技术对于识别潜在的piwi蛋白质相互作用rna与人类疾病之间的特异性表达结果通常是可靠的,如广泛的体内和体外核糖体实验技术,高通量转录组测序技术等。然而,目前越来越多的piwi蛋白质相互作用rna与疾病关联数据库已经出现,如pirnabank、pirbase和pirnaquest。这些已知的关联数据为构建高效、快速预测潜在关联关系的计算方法提供了坚实的基础,从而一定程度上解决传统生物实验方法耗时、昂贵和劳动密集型的问题。目前大多数计算预测方法仅仅考虑piwi蛋白质相互作用rna序列特征和疾病的相似性特征,而没有进一步对特征进行去噪以及进行深层隐藏特征提取,因此有必要设计一种能够利用到piwi蛋白质相互作用rna序列信息,高斯相互作用谱核相似信息以及疾病语义相似信息,疾病高斯相互作用谱核相似信息,能够对多种特征进行融合,去噪以及进行深层隐藏特征提取,达到更高预测精准度的预测方法。
技术实现要素:
4.本发明的目的在于提供一种基于卷积去噪自编码机的pirna
‑
疾病关联关系预测方法,以克服现有技术所存在的缺陷。
5.为了达到上述目的,本发明采用的技术方案为:
6.基于卷积去噪自编码机的pirna
‑
疾病关联关系预测方法,包括以下步骤:
7.s1、获取已知的piwi蛋白质相互作用rna与疾病关联关系数据、piwi蛋白质相互作用rna的id和序列信息,以及疾病语义信息;
8.s2、基于piwi蛋白质相互作用rna的核苷酸序列信息,利用基于重叠移动窗口的序列衍生特征提取方法计算每种piwi蛋白质相互作用rna序列特征,利用欧式相似性测量方法计算piwi蛋白质相互作用rna序列之间的相似性特征;
9.s3、利用有向无环图构建各种疾病之间的关系,定义两种不同的图中节点对目标疾病的语义贡献度,分别计算两种目标疾病的语义值,根据疾病之间有向无环图的共享部分计算两种疾病语义相似性特征;
10.s4、利用piwi蛋白质相互作用rna
‑
疾病关联关系对分别计算piwi蛋白质相互作用rna和疾病的高斯相互作用谱核相似特征;
11.s5、基于均值相似核融合方法分别融合piwi蛋白质相互作用rna与疾病的多种相似特征,构建卷积去噪自动编码神经网络架构,提取输入数据的更深层次的隐藏特征,同时将噪声数据添加到训练数据集中,得到无污染特征数据;
12.s6、以piwi蛋白质相互作用rna与疾病关联关系数据作为正样本,基于剩余所有未确定的piwi蛋白质相互作用rna与疾病关联对,随机抽取与正样本相同关联对作为负样本,将整个训练数据集进行五次随机划分,每次划分成五个部分,其中四部分作为训练数据集,剩余一部分作为测试数据集;
13.s7、基于极限学习机利用训练数据集构建分类模型,利用测试数据集对模型进行打分,重复进行五次实验,取五次实验的平均结果作为模型的性能评价指标。
14.进一步地,所述步骤s2中利用基于重叠移动窗口的序列衍生特征提取3
‑
mer方法,计算表观遗传标记的每种piwi蛋白质相互作用rna序列的核苷酸序列信息集合上所有3
‑
聚体出现次数占整个序列长度的统计概率,生成特征向量作为其序列特征,利用欧几里得距离测度方法计算piwi蛋白质相互作用rna之间的序列相似性特征。
15.进一步地,所述步骤s3中是基于mesh数据库利用有向无环图构建各种疾病之间的关系,某种疾病d可以被表示为dag(d)=(d,t(d),e(d)),其中t(d)为包含d及其祖先的节点集,e(d)为从父节点到子节点的边集,疾病d的语义值可以表示为:
[0016][0017]
其中,有向无环图中的疾病项目d对d的语义贡献通过以下公式定义:
[0018][0019]
其中δ是语义贡献衰减因子。
[0020]
进一步地,如两种疾病d
i
和d
j
的有向无环图相似,则可以将疾病d
i
和d
j
视为相似的疾病,并定义第一种类型的疾病d
i
和d
j
之间的语义相似度ds1(d
i
,d
j
)为:
[0021][0022]
以及第二种类型疾病语义相似度为:
[0023][0024]
[0025][0026]
再将两种不同疾病d
i
和d
j
的语义相似性特征由均值相似核融合方法表示为:
[0027][0028]
进一步地,所述步骤s4是基于具有相似特征的piwi蛋白质相互作用rna大概率与具有相似特征的疾病相关联的假设,该假设具体为:
[0029]
首先、基于已知的piwi蛋白质相互作用rna
‑
疾病关联关系对构建邻接矩阵a为:
[0030][0031]
其中,当piwi蛋白质相互作用rna p
i
与疾病d
j
存在关联关系时,a
i,j
被设为1,否则,a
i,j
被设为0,piwi蛋白质相互作用rna p
i
的相互作用谱信息可以表示为列向量a(:,i),piwi蛋白质相互作用rna p
i
与p
j
的高斯相互作用谱核相似性定义为:
[0032]
p
gip
(i,j)=exp(
‑
σ
r
|a(:,i)
‑
a(:,j)|2)
[0033]
其中,参数σ
r
用于控制内核带宽,被定义为:
[0034][0035]
其中,n为邻接矩阵a的列向量个数;
[0036]
然后、疾病d
i
的相互作用谱信息表示为邻接矩阵a的行向量a(i,:),疾病d
i
与d
j
的高斯相互作用谱核相似性定义为:
[0037]
d
gip
(i,j)=exp(
‑
σ
d
|a(i,:)
‑
a(j,:)|2)
[0038][0039]
其中,n为邻接矩阵a的行向量个数。
[0040]
进一步地,所述步骤s5中对于卷积去噪自动编码神经网络提取输入数据的更深层次的隐藏特征的过程具体为:
[0041]
首先、执行编码过程,其中卷积层的输出定义为:
[0042][0043]
其中x为输入特征向量,x
noise
为添加噪声数据,为卷积运算,w
′1为权重参数,b
′1为偏置向量,s
f
为激活函数;
[0044]
卷积层之后为池化层,池化层的输出定义为:
[0045]
h2=pool(h1)=s
f
(down(x) b
′1)
[0046]
其中pool表示池操作,down表示下采样操作
[0047]
然后、执行解码过程,定义反卷积和上采样层的输出为:
[0048][0049]
h
′1=up(h
′2)=s
g
(up(x) b
′2)
[0050][0051]
其中,h
′2表示解码过程中反卷积输出,w
′2与b
′2分别表示权重向量和偏置向量,up表示上采样操作,h
′1表示解码过程的池化输出,s
g
表示解码过程中的激活函数,x
′
表示重构后的x;
[0052]
最后,卷积去噪自动编码神经网络通过前向传播和后向传播最小化重构误差,提取深度隐藏特征,其中前向传播过程中的卷积、池化和反卷积、池化操作为:
[0053][0054][0055][0056]
进一步地,所述步骤s7中的极限学习机为单隐层前馈神经网络,该极限学习机第一阶段的训练过程为特征映射并定义其输出为:
[0057][0058]
其中,x表示输入特征向量,h(x)表示隐含层输出向量,β表示输出权值;
[0059]
极限学习机的第二阶段是输出权值求解,使输出权值的frobenius范数和训练误差最小化,目标函数为:
[0060][0061]
其中,ω表示正则化参数,n表示样本数,ξ
i
表示第i个样本训练误差,表示frobenius范数。
[0062]
与现有技术相比,本发明的优点在于:
[0063]
1、本发明能够充分利用piwi蛋白质相互作用rna和疾病的多模态特征,包括序列特征,语义相似特征,高斯相互作用谱核相似特征,利用卷积去噪自动编码神经网络自动挖掘深层隐藏特征,并利用极限学习机高效预测潜在的piwi蛋白质相互作用rna
‑
疾病关联关系;
[0064]
2、本发明能够将piwi蛋白质相互作用rna和疾病特征视为图像,并利用深度学习
方法卷积去噪自动编码器神经网络进行深度特征学习,提高模型的预测准确性,利用具有特定良好泛化性能和高速学习能力的极限学习机来训练深度特征并预测piwi蛋白质相互作用rna和疾病之间的潜在关联,得到比较好的预测效果;
[0065]
3、本发明相比于传统生物实验方法,耗时少、价格低廉以及不需要密集劳动力;五折交叉验证下的预测准确率达到了auc值达到85%以上,实例验证下对于胃癌、肾细胞癌、心血管疾病的潜在piwi蛋白质相互作用rna预测准确率达到80%,80%和60%。
附图说明
[0066]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0067]
图1是本发明基于卷积去噪自编码机的pirna
‑
疾病关联关系预测方法的流程图。
[0068]
图2为本发明在五折交叉验证下基于pirdisease v1.0数据集生成的roc曲线。
[0069]
图3为本发明不使用卷积去噪自动编码神经网络在五折交叉验证下基于pirdisease v1.0数据集生成的roc曲线。
[0070]
图4为本发明与其他计算方法在五折交叉验证下基于pirdisease v1.0数据集的auc对比。
具体实施方式
[0071]
下面结合附图对本发明的优选实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
[0072]
实施例一
[0073]
参阅图1所示,本实施例公开了一种基于卷积去噪自编码机的pirna
‑
疾病关联关系预测方法,包括以下步骤:
[0074]
步骤s1、数据集的选择与建立:基于pirdisease v1.0数据库获取已知的piwi蛋白质相互作用rna与疾病关联关系数据;基于pirbase v2.0数据库获取piwi蛋白质相互作用rna的id和序列信息;基于美国医学主题词(mesh)数据库获取疾病语义信息;
[0075]
步骤s2、piwi蛋白质相互作用rna序列相似性特征的生成:基于piwi蛋白质相互作用rna的核苷酸序列信息,即腺嘌呤,胞嘧啶,尿嘧啶和鸟嘌呤四种核苷酸排列信息,利用基于重叠移动窗口的序列衍生特征提取方法计算每种piwi蛋白质相互作用rna序列特征,利用欧式相似性测量方法计算piwi蛋白质相互作用rna序列之间的相似性特征;
[0076]
步骤s3、疾病语义相似性特征的生成:基于美国国家医学图书馆的mesh数据库利用有向无环图构建各种疾病之间的关系,定义两种不同的图中节点对目标疾病的语义贡献度,分别计算两种目标疾病的语义值,根据疾病之间有向无环图的共享部分计算两种疾病语义相似性特征;
[0077]
步骤s4、piwi蛋白质相互作用rna和疾病高斯相互作用谱核相似特征的生成:基于具有相似特征的piwi蛋白质相互作用rna大概率与具有相似特征的疾病相关联的假设,利用已知的piwi蛋白质相互作用rna
‑
疾病关联关系对分别计算piwi蛋白质相互作用rna和疾
病的高斯相互作用谱核相似特征;
[0078]
步骤s5、深度隐藏特征挖掘:基于均值相似核融合方法分别融合piwi蛋白质相互作用rna与疾病的多种相似特征,构建卷积去噪自动编码神经网络架构,以无监督的方式提取输入数据的更深层次的隐藏特征,同时将噪声数据添加到训练数据集中,迫使编码器去除噪声,得到真实的无污染特征数据;
[0079]
步骤s6、训练集和测试集的构建:基于pirdisease v1.0数据库中已知的piwi蛋白质相互作用rna与疾病关联关系数据作为正样本,基于剩余所有未确定的piwi蛋白质相互作用rna与疾病关联对,随机抽取与正样本相同关联对作为负样本,将整个训练数据集进行五次随机划分,每次划分成五个部分,其中四部分作为训练数据集,剩余一部分作为测试数据集;
[0080]
步骤s7、分类器模型的构建:基于极限学习机利用训练数据集构建分类模型,利用测试数据集对模型进行打分,重复进行五次实验,取五次实验的平均结果作为模型的性能评价指标。
[0081]
如图1所示,在步骤s1中,数据集的选择与建立,本实施例使用的已知的piwi蛋白质相互作用rna与疾病关联数据来源于pirdisease v1.0数据库,在此基础上,本实施例进行了数据预处理操作,消除重复关联,删除公共数据库pirbase中没有id的piwi蛋白质相互作用rna,最终获得5002条piwi蛋白质相互作用rna
‑
疾病关联,包含4350种piwi蛋白质相互作用rna和21种人类疾病;piwi蛋白质相互作用rna的id和序列信息来源于pirbase v2.0数据库;疾病语义信息来源于美国医学主题词(mesh)数据库。
[0082]
piwi蛋白质相互作用rna序列相似性特征的生成,piwi蛋白质相互作用rna序列信息,通常用四种核苷酸的简写字母表示,即腺嘌呤(a),胞嘧啶(c),尿嘧啶(u)和鸟嘌呤(g)四种核苷酸排列信息,利用基于重叠移动窗口的序列衍生特征提取方法将piwi蛋白质相互作用rna序列分割成多个3
‑
单体单元(3
‑
mers),计算每种3
‑
mers的出现频率作为piwi蛋白质相互作用rna的序列特征,利用欧式相似性测量方法计算piwi蛋白质相互作用rna序列之间的相似性特征。
[0083]
疾病语义相似性特征的生成,基于美国国家医学图书馆mesh数据库构建有向无环图(dag)来表示各种疾病之间的关联关系,在此基础上,某种疾病d可以被表示为dag(d)=(d,t(d),e(d)),其中t(d)为包含d及其祖先的节点集,e(d)为从父节点到子节点的边集。因此,疾病d的语义值可以表示为:
[0084][0085]
其中有向无环图中的疾病项目d对d的语义贡献被定义为:
[0086][0087]
其中δ是语义贡献衰减因子,在本发明中,它的值被设置为0.5。因此,如果两种疾病d
i
和d
j
的有向无环图相似,则可以将它们视为相似的疾病,并定义它们之间的语义相似度ds1(d
i
,d
j
)为:
[0088][0089]
此外,即使在dag(d)的同一层,不同的疾病项目也有不同的贡献度,换句话说,如果一种疾病出现的次数越多,它对疾病d的贡献就越大,在此基础上进一步计算另一种疾病语义相似度。
[0090]
具体的说,第二种类型疾病语义相似度定义为:
[0091][0092][0093][0094]
最后,两种不同疾病d
i
和d
j
的语义相似性特征由均值相似核融合方法表示为:
[0095][0096]
piwi蛋白质相互作用rna和疾病高斯相互作用谱核相似性特征的生成,基于具有相似特征的piwi蛋白质相互作用rna大概率与具有相似特征的疾病相关联,反之亦然的假设,首先基于已知的piwi蛋白质相互作用rna
‑
疾病关联关系对构建邻接矩阵a为:
[0097][0098]
其中,当piwi蛋白质相互作用rna p
i
与疾病d
j
存在关联关系时,a
i,j
被设为1,否则,a
i,j
被设为0。在此基础上,piwi蛋白质相互作用rna p
i
的相互作用谱信息可以表示为列向量a(:,i),piwi蛋白质相互作用rna p
i
与p
j
的高斯相互作用谱核相似性定义为:
[0099]
p
gip
(i,j)=exp(
‑
σ
r
|a(:,i)
‑
a(:,j)|2)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0100]
其中,参数σ
r
用于控制内核带宽,被定义为:
[0101][0102]
其中,n为邻接矩阵a的列向量个数。
[0103]
同样的,疾病d
i
的相互作用谱信息可以表示为邻接矩阵a的行向量a(i,:),疾病d
i
与d
j
的高斯相互作用谱核相似性定义为:
[0104]
d
gip
(i,j)=exp(
‑
σ
d
|a(i,:)
‑
a(j,:)|2)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0105][0106]
其中,n为邻接矩阵a的行向量个数。
[0107]
深层隐藏特征挖掘,基于均值相似核融合方法分别融合piwi蛋白质相互作用rna与疾病的多种相似特征,构建卷积去噪自动编码神经网络架构,以无监督的方式提取输入数据的更深层次的隐藏特征,同时将噪声数据添加到训练数据集中,迫使编码器去除噪声,得到真实的无污染特征数据,对于卷积去噪自动编码神经网络提取潜在特征的过程首先执行编码过程,其中卷积层的输出定义为:
[0108][0109]
其中x为输入特征向量,x
noise
为添加噪声数据,为卷积运算,w
′1为权重参数,b
′1为偏置向量,s
f
为激活函数,包括relu,tanh和sigmoid函数,本实施例中选用训练时间小,网络收敛速度快的relu激活函数。
[0110]
卷积层之后是池化层,池化层的输出定义为:
[0111]
h2=pool(h1)=s
f
(down(x) b
′1)
ꢀꢀꢀꢀꢀꢀ
(14)
[0112]
其中,pool表示池操作,down表示下采样操作。
[0113]
接下来,卷积去噪自动编码神经网络执行解码过程,定义反卷积和上采样层的输出为:
[0114][0115]
h
′1=up(h
′2)=s
g
(up(x) b
′2)
ꢀꢀꢀꢀꢀꢀ
(16)
[0116][0117]
其中,h
′2表示解码过程中反卷积输出,w
′2与b
′2分别表示权重向量和偏置向量,up表示上采样操作,h
′1表示解码过程的池化输出,s
g
表示解码过程中的激活函数,x表示重构后的x。
[0118]
最后,卷积去噪自动编码神经网络通过前向传播和后向传播最小化重构误差,提取深度隐藏特征,其中前向传播过程中的卷积、池化和反卷积、池化操作为:
[0119][0120][0121]
[0122]
分类器模型的构建,极限学习机是一种特殊的单隐层前馈神经网络(slfns),用于解决传统梯度下降神经网络学习缓慢的问题,因为不当的学习速率会导致大量的延迟,使其收敛到局部最大值。与传统的bp神经网络不同,极限学习机的输入隐含层权值和偏差是随机分配的。极限学习机第一阶段的训练过程为特征映射,并定义其输出为:
[0123][0124]
其中,x表示输入特征向量,h(x)表示隐含层输出向量,β表示输出权值。此外,任何非线性分段连续函数都可以作为激活函数h,例如sigmoid,、gaussian等为:
[0125]
h
i
(x)=g(a
i
,b
i
,x),a
i
∈r
d
,b
i
∈r
ꢀꢀꢀꢀꢀ
(22)
[0126]
极限学习机的第二阶段是输出权值求解,使输出权值的frobenius范数和训练误差最小化,目标函数为:
[0127][0128]
其中,ω表示正则化参数,n表示样本数,ξ
i
表示第i个样本训练误差,表示frobenius范数。
[0129]
本实施例中,极限学习机参数
′
elm_type
′
设置为1,
′
activation function
′
设置为sigmoid,
′
number of hidden neurous
′
设置为60,其他参数设置为默认值。
[0130]
实施例二
[0131]
为了能够更好的说明本发明预测方法的效果,将此预测方法与不使用卷积去噪自动编码神经网络进行深层特征提取的模型(对比模型)进行了对比,表1列出了本实施例和对比模型使用五折交叉验证法在基准数据集上生成的结果:
[0132]
表1 在五折交叉验证下基于基准数据集本发明与对比模型结果的比较
[0133][0134]
图2和图3分别展示了本发明和对比模型生成的roc曲线;通过对比可以看出,本实施例在多种评价指标上均取得了更高的得分,其结果均高于不使用卷积去噪自动编码神经网络进行深层特征提取的对比模型,这个结果表明,本本发明的综合性能要优于不进行深
层特征提取的模型。
[0135]
实施例三
[0136]
为了进一步对比本发明方法的性能表现,将本发明方法与两种最新的计算方法进行了对比,图4展示了在五折交叉验证下基于相同的基准数据集下,两种最新的计算方法与本发明在每一折数据下的auc对比柱状图;auc值的大小更能代表方法的预测性能。
[0137]
通过对比可以看到:本发明相对于最新的计算模型拥有更高的auc值,综合表现优于其他模型。
[0138]
实施例四
[0139]
为了进一步验证本发明方法在实际应用中预测piwi蛋白质相互作用rna与疾病之间潜在关联的能力,选择了三种重要的人类疾病(胃癌、肾细胞癌、心血管疾病)作为病例研究。
[0140]
首先、在训练数据集中删除这三种疾病的所有正相关关联数据。
[0141]
其次、将其余的正相关和所有负相关数据用于训练模型。
[0142]
然后、预测由三种人类疾病和所有piwi蛋白质相互作用rna组成的测试数据集。
[0143]
最后、选择每种疾病预测得分最高的前5个piwi蛋白质相互作用rna,并通过pubmed(https://pubmed.ncbi.nlm.nih.gov/)上的生物学文献进行验证。
[0144]
从表格2中可以看出,本发明方法预测胃癌相关的前5个piwi蛋白质相互作用rna中有4个被验证,预测准确率为80%;预测与肾细胞癌相关的前5个piwi蛋白质相互作用rna中,已有4个被验证,预测准确率为80%;预测与心血管疾病相关的前5个piwi蛋白质相互作用rna中的3个已被验证,预测的准确率为60%。案例研究的预测结果可以说明本发明方法在实际应用中预测潜在的piwi蛋白质相互作用rna与疾病关联性能可靠。
[0145][0146]
本发明在五折交叉验证实验下取得了优异的性能表现,证明了卷积去噪自编码神
经网络在piwi蛋白质相互作用rna和疾病关联预测中的有效性。案例研究证明了本发明在发现潜在piwi蛋白质相互作用rna和疾病关联关系的实际应用能力。
[0147]
虽然结合附图描述了本发明的实施方式,但是专利所有者可以在所附权利要求的范围之内做出各种变形或修改,只要不超过本发明的权利要求所描述的保护范围,都应当在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。