1.本发明涉及文献识别技术领域,具体地说,涉及一种交通运输领域变革性研究文献早期识别方法。
背景技术:
2.在创新驱动发展战略中,制定科学、合理的科技规划和科技政策是建立创新型社会的关键。在科技规划和科技政策中,如何快速,准确地预测未来科技热点、发展趋势尤为关键。科技政策制定中最重要的挑战始终是如何选择“正确的”未来技术,预测未来的社会需求。技术预测有助于发现未来关键的科技领域和科技技术,预测未来的社会需求,使研发工作与社会需求保持一致,在此基础上,制定可持续发展的科技规划、政策,为全社会的科技工作提供前瞻性的指导。
3.技术预测是对科技发展的未来目标和可能途径及资源条件做出的预先推测或测定。技术预测主要着眼于准确地预言、推测未来的技术发展动向,强调如何适应未来的发展趋势,是为适应未来提供决策依据。通过一定的方法提前发现未来能够引起范式转变或开辟新的前沿的研究,则可以认为在一定程度上实现了某一领域的预测。未来能够引起范式转变或开辟新的前沿的研究即为变革性研究,识别变革性研究是实现技术预测的一个重要方面。
4.科学界普遍有这样一种共识“论文的影响和学术水平其实不是一回事,好的科研往往独辟蹊径,所出的成果需要过一段时间甚至很多年以后才会慢慢被主流接受,在短期引用率上反映不出来”。根据科学发展的自身规律,真正好的、创新性的研究(变革性研究)总是少数人开创的、容易被忽视或抵制、开始阶段不可能纷纷跟风涌入的。高品质、重大原创性论文(变革性的研究产出)往往会有一个“沉睡期”,会遭遇延迟承认,科学研究中的延迟承认现象又被称之为睡美人现象。故基于该种延迟承认的现象,当前很难对变革性研究进行早期识别。
技术实现要素:
5.本发明提供了一种交通运输领域变革性研究文献早期识别方法,其能够克服现有技术的某种或某些缺陷。
6.根据本发明的交通运输领域变革性研究文献早期识别方法,其包括如下步骤:
7.步骤s1、构建待识别数据集a
8.该步骤中,待识别数据集a={a
i
|i∈[1,n]},待识别数据集a表示自n本期刊中所选取相关领域的n篇文献,a
i
为第i篇文献;
[0009]
步骤s2、获取所述n篇文献的年度被引频次数据集b
[0010]
该步骤中,b={b
i
|i∈[1,n]},b
i
表示第i篇文献的被引频次数列,b
i
={b
it
|i∈[1,n],t∈[t
i0
,t
n
]},b
it
表示第i篇文献在第t年度的被引频次;t
i0
表示第i篇文献的发表当年,t
n
表示当前年度;
[0011]
步骤s3、计算获取每篇文献的b
cp
指数
[0012]
该步骤中,对应第i篇文献,其b
cp
指数为b
cpi
;
[0013]
步骤s4、计算获取所述n篇文献的年度被引频次最大增量序列δc
[0014]
该步骤中,δc={δc
i
|i∈[1,n]},δc
i
表示第i篇文献的年度被引频次最大增量,其中,b
″
i
为第i篇文献的在区间[t
i0
,t
n
]中的总被引频次,
[0015]
步骤s5、计算获取所述n篇文献的总被引频次标准化数据集b
′
[0016]
该步骤中,b
′
={b
′
i
|i∈[1,n]},b
′
i
表示第i篇文献的总被引频次经标准化处理后的数值,其中,μ为所述n篇文献的总被引频次的均值,σ为所述n篇文献的总被引频次的标准差;
[0017]
步骤s6,基于预定规则对所述n篇文献进行排序,进而筛选出m篇文献作为变革性研究文献。
[0018]
通过本发明中的方法,能够首先自现有文献库中筛选出n篇文献,之后能够对每篇文献的b
cp
指数、年度被引频次最大增量及总被引频次标准化数据进行计算获取,之后能够基于预定的规则对变革性研究文献进行早期识别,故而能够较佳地提供一种较为科学的变革性研究文献早期识别方法,故而便于运用。
[0019]
作为优选,步骤s3中具体包括如下步骤,
[0020]
步骤s31,计算获取每篇文献的年度被引频次累积百分比集合c,c={c
i
|i∈[1,n]},c
i
表示第i篇文献的年度被引频次累积百分比数列;c
i
={c
ti
|i∈[1,n],t∈[t
i0
,t
n
]},c
ti
表示第i篇文献在第t年度的年度被引频次累积百分比,
[0021]
步骤s32,根据公式获取每篇文献的b
cp
指数。
[0022]
通过上述,即可较佳地获取每篇文献的b
cp
指数,其中,对去每篇文献,其发表年份t
i0
能够定义为0,故而能够能够较佳地便于b
cp
指数的计算。
[0023]
作为优选,步骤s6具体包括如下步骤,
[0024]
步骤s61,建立规则集合p,p={p
j
|j=1,2,3,
…
q},p
j
表示第j条规则,q为规则集合p的元素总数;
[0025]
步骤s62,基于规则集合p将所述n篇文献划分为q组;
[0026]
步骤s63,按b
cp
指数自大到小的顺序自每组文献中筛选出m/q篇文献作为变革性研究文献。
[0027]
通过上述,能够基于不同的规则将n篇文献划分为多组,且能够自没组文献中均筛选出排序靠前的m/q篇文献,从而形成m篇变革性研究文献;基于此种方法,能够较佳地自不同特征类别的文献中均进行变革性研究文献的识别,故而能够较佳地提升文献早期识别的精确性。
[0028]
作为优选,步骤s61中,规则集合p中共有4条规则,即q=4;其中,
[0029][0030][0031][0032][0033]
通过构建规则p1和规则p2,能够较佳地基于3σ准则,对文献进行分类,从而能够充分保障大部分的文献均能够被列入识别的列表中。
[0034]
通过构建规则p3,能够较佳地对当前年份近2年内达到被引频次最大值的文献进行早期识别,故而能够较佳地对当前较为热门的文献进行筛选识别。
[0035]
通过构建规则p4,能够较佳地基于3σ准则,对在当前年份的近2年内达到年度被引频次最大增量的文献进行早期识别,故而能够较佳地对当前较为热门的文献进行筛选识别。
[0036]
作为优选,步骤s2中,所构建的年度被引频次数据集b中加入专利引用标签h;即b={(b
i
,h
i
)|i∈[1,n],h
i
=0或1},h
i
表示第i篇文献的专利引用标签,若第i篇文献未被专利引用则h
i
=0,反之则h
i
=1;
[0037]
步骤s61中,规则集合p还具有规则p5,
[0038]
故而能够较佳地对被专利引用的文献进行筛选,故而能够较佳地对可能已经投入实际生产的文献进行筛选。
[0039]
作为优选,步骤s6具体包括如下步骤,
[0040]
步骤s6a,构建每篇文献的特征序列t
i
,t
i
={b
cpi
,δc,b
′
i
,max(b
i
)};
[0041]
步骤s6b,基于神经网络构建识别模型,识别模型用于对特征序列t
i
进行处理并输出对应文献属于变革性研究文献的概率r
i
;
[0042]
步骤s6c,按概率r
i
自大到小的顺序选取m篇文献作为变革性研究文献。
[0043]
故而能够较佳地对被专利引用的文献进行筛选,故而能够较佳地对可能已经投入实际生产的文献进行筛选。
[0044]
作为优选,步骤s2中,所构建的年度被引频次数据集b中加入专利引用标签h;即b={(b
i
,h
i
)|i∈[1,n],h
i
=0或1},h
i
表示第i篇文献的专利引用标签,若第i篇文献未被专利引用则h
i
=0,反之则h
i
=1;
[0045]
步骤s6a中,t
i
={b
cpi
,δc,b
′
i
,max(b
i
),h
i
}。
[0046]
故而能够较佳地引入是否被专利进行引用最为参考因素,从而能够较佳地增加特征序列的复杂性,使得识别结果更加科学。
[0047]
作为优选,步骤s6b具体包括如下步骤,
[0048]
步骤s6b1,搭建识别模型的构架;
[0049]
步骤s6b2,构建训练集对识别模型进行训练。
[0050]
从而能够较佳地实现对识别模型的构建及训练。
附图说明
[0051]
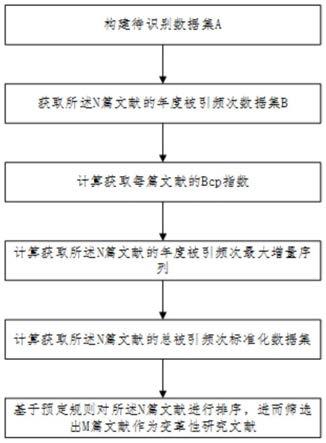
图1为实施例1中的一种交通运输领域变革性研究文献早期识别方法的流程示意图。
具体实施方式
[0052]
为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。
[0053]
实施例1
[0054]
结合图1所示,本实施例提供了一种交通运输领域变革性研究文献早期识别方法,其包括如下步骤:
[0055]
步骤s1、构建待识别数据集a
[0056]
该步骤中,待识别数据集a={a
i
|i∈[1,n]},待识别数据集a表示自n本期刊中所选取相关领域的n篇文献,a
i
为第i篇文献;
[0057]
步骤s2、获取所述n篇文献的年度被引频次数据集b
[0058]
该步骤中,b={b
i
|i∈[1,n]},b
i
表示第i篇文献的被引频次数列,b
i
={b
it
|i∈[1,n],t∈[t
i0
,t
n
]},b
it
表示第i篇文献在第t年度的被引频次;t
i0
表示第i篇文献的发表当年,t
n
表示当前年度。
[0059]
步骤s3、计算获取每篇文献的b
cp
指数
[0060]
该步骤中,对应第i篇文献,其b
cp
指数为b
cpi
;
[0061]
步骤s4、计算获取所述n篇文献的年度被引频次最大增量序列δc
[0062]
该步骤中,δc={δc
i
|i∈[1,n]},δc
i
表示第i篇文献的年度被引频次最大增量,其中,b
″
i
为第i篇文献的在区间[t
i0
,t
n
]中的总被引频次,
[0063]
步骤s5、计算获取所述n篇文献的总被引频次标准化数据集b
′
[0064]
该步骤中,b
′
={b
′
i
|i∈[1,n]},b
′
i
表示第i篇文献的总被引频次经标准化处理后的数值,其中,μ为所述n篇文献的总被引频次的均值,σ为所述n篇文献的总被引频次的标准差;
[0065]
步骤s6,基于预定规则对所述n篇文献进行排序,进而筛选出m篇文献作为变革性研究文献。
[0066]
通过本实施例中的方法,能够首先自现有文献库中筛选出n篇文献,之后能够对每篇文献的b
cp
指数、年度被引频次最大增量及总被引频次标准化数据进行计算获取,之后能够基于预定的规则对变革性研究文献进行早期识别,故而能够较佳地提供一种较为科学的变革性研究文献早期识别方法,故而便于运用。
[0067]
本实施的步骤s1中,能够设置8≤n≤15,且所述n本期刊能够均自交通运输领域的q1区的sci期刊中选取,且所选的n篇期刊,其发表年份区间选择当前年份前30年至当前年份前10年,故而能够较佳地提升数据处理结果的精确性。
[0068]
本实施例的步骤s3中具体包括如下步骤:
[0069]
步骤s31,计算获取每篇文献的年度被引频次累积百分比集合c,c={c
i
|i∈[1,n]},c
i
表示第i篇文献的年度被引频次累积百分比数列;c
i
={c
ti
|i∈[1,n],t∈[t
i0
,t
n
]},c
ti
表示第i篇文献在第t年度的年度被引频次累积百分比,
[0070]
步骤s32,根据公式获取每篇文献的b
cp
指数。
[0071]
通过上述,即可较佳地获取每篇文献的b
cp
指数,其中,对去每篇文献,其发表年份t
i0
能够定义为0,故而能够能够较佳地便于b
cp
指数的计算。
[0072]
本实施例中,步骤s6具体包括如下步骤,
[0073]
步骤s61,建立规则集合p,p={p
j
|j=1,2,3,
…
q},p
j
表示第j条规则,q为规则集合p的元素总数;
[0074]
步骤s62,基于规则集合p将所述n篇文献划分为q组;
[0075]
步骤s63,按b
cp
指数自大到小的顺序自每组文献中筛选出m/q篇文献作为变革性研究文献。
[0076]
通过上述,能够基于不同的规则将n篇文献划分为多组,且能够自没组文献中均筛选出排序靠前的m/q篇文献,从而形成m篇变革性研究文献;基于此种方法,能够较佳地自不同特征类别的文献中均进行变革性研究文献的识别,故而能够较佳地提升文献早期识别的精确性。
[0077]
本实施例的步骤s61中,规则集合p中共有4条规则,即q=4;其中,
[0078][0079][0080]
[0081][0082]
通过构建规则p1和规则p2,能够较佳地基于3σ准则,对文献进行分类,从而能够充分保障大部分的文献均能够被列入识别的列表中。
[0083]
通过构建规则p3,能够较佳地对当前年份近2年内达到被引频次最大值的文献进行早期识别,故而能够较佳地对当前较为热门的文献进行筛选识别。
[0084]
通过构建规则p4,能够较佳地基于3σ准则,对在当前年份的近2年内达到年度被引频次最大增量的文献进行早期识别,故而能够较佳地对当前较为热门的文献进行筛选识别。
[0085]
本实施例的步骤s2中,所构建的年度被引频次数据集b中加入专利引用标签h;即b={(b
i
,h
i
)|i∈[1,n],h
i
=0或1},h
i
表示第i篇文献的专利引用标签,若第i篇文献未被专利引用则h
i
=0,反之则h
i
=1;
[0086]
步骤s61中,规则集合p还具有规则p5,
[0087]
故而能够较佳地对被专利引用的文献进行筛选,故而能够较佳地对可能已经投入实际生产的文献进行筛选。
[0088]
实施例2
[0089]
本实施例也提供了一种交通运输领域变革性研究文献早期识别方法,其与实施例1的区别在于:本实施例中的步骤s6,通过构建识别模型对变革性研究文献进行早期识别,而非按照认为经验构建规则对其进行识别,故而效率更高,且能够较佳地保证识别的精准性。
[0090]
本实施例的步骤s6具体包括如下步骤,
[0091]
步骤s6a,构建每篇文献的特征序列t
i
,t
i
={b
cpi
,δc,b
′
i
,max(b
i
)};
[0092]
步骤s6b,基于神经网络构建识别模型,识别模型用于对特征序列t
i
进行处理并输出对应文献属于变革性研究文献的概率r
i
;
[0093]
步骤s6c,按概率r
i
自大到小的顺序选取m篇文献作为变革性研究文献。
[0094]
通过上述步骤s6a
‑
s6c,能够对每篇文献属于变革性研究文献的概率r
i
进行计算,通过对概率的排序,即可较佳地实现对变革性研究文献的筛选。
[0095]
此外,其步骤s2中,所构建的年度被引频次数据集b中加入专利引用标签h;即b={(b
i
,h
i
)|i∈[1,n],h
i
=0或1},h
i
表示第i篇文献的专利引用标签,若第i篇文献未被专利引用则h
i
=0,反之则h
i
=1;
[0096]
步骤s6a中,t
i
={b
cpi
,δc,b
′
i
,max(b
i
),h
i
}。
[0097]
故而能够较佳地引入是否被专利进行引用最为参考因素,从而能够较佳地增加特征序列的复杂性,使得识别结果更加科学。
[0098]
另外,步骤s6b具体包括如下步骤,
[0099]
步骤s6b1,搭建识别模型的构架;
[0100]
步骤s6b2,构建训练集对识别模型进行训练。
[0101]
从而能够较佳地实现对识别模型的构建及训练。
[0102]
本实施例的步骤s6b1中,所构建的识别模型具有输入层、全连接层及输出层,输入层用于输入特征序列,全连接层用于对特征序列进行加权计算处理,输出层为一二分类模型,其用于输出文献属于变革性研究文献的概率。
[0103]
本实施的步骤s6b2中,能够基于历史数据建立训练集,从而能够较佳地实现对识别模型的训练。
[0104]
本领域的技术人员可以理解是的,基于神经网络对识别模型的构建及训练,采用现有常规手段即可,故而本实施例中不予赘述。
[0105]
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。