1.本发明涉及气候预测领域,具体涉及一种基于差分法消除多重共线性的逐步聚类统计降尺度方法。
背景技术:
2.现有的气候预测方法主要包括动力学方法和统计学方法。动力学方法是基于大气、陆地、海洋过程的物理过程编写的气候模型,通过提供初始条件及边界条件,可以算出未来的气候状态。统计学方法则是基于统计的数学方法,分析历史气候数据间的统计关系,以此求解未来的气候数据。目前,逐步聚类的统计方法已应用于气候、水文等领域进行未来数据的预测。逐步聚类方法通过切割或合并一系列历史的预报因子及预测量组成的矩阵,产生出预报因子与预测量之间的聚类树,假定未来预报因子与预测量之间的聚类树与历史的相同,通过全球气候模型中未来的预报因子的值,以此计算出未来的预报量。逐步聚类统计降尺度方法的优势在于不用假设预报因子与预测量之间的函数关系,通过聚类树解释多个预报因子和多个预测量之间的响应关系。
3.在应用中,逐步聚类统计降尺度方法要求预报因子之间不存在线性关系。然而,现实中,气候因子间往往存在多重共线性关系,例如降雨作为预测量,预报因子包括温度,气压,蒸散发,风速等,其中蒸散发与温度、风速相关,风速与气压相关,各因子间存在多重共线性关系。预报因子间的共线性问题会导致逐步聚类过程中产生不必要的切割或合并,导致聚类树无法反映真实的预报因子与预测量之间的关系,增加未来预测量的预测误差。
4.因此,亟需需要研发出一种能消除预报因子间共线性问题的逐步聚类统计降尺度方法。
5.发明目的
6.本发明的目的即在于解决现有技术中所存在的难题,消除逐步聚类统计降尺度过程中预报因子之间存在的多重共线性,更真实的反映预测因子与预报量之间的关系。
技术实现要素:
7.本发明公开一种基于差分法消除多重共线性的逐步聚类统计降尺度方法,包括以下步骤:
8.(1)搜集并筛选数据,将地面观测站点或再分析气候数据作为预报量,将全球气候模型gcm或区域气候模型rcm模拟的气候数据作为备选的预测因子,通过计算备选的预测因子与预报量之间的相关性,筛选出与预报量相关性高的预测因子;
9.(2)将步骤(1)中的所述预报量按照时间序列分为两部分数据,第一部分为逐步聚类统计降尺度的模型训练阶段数据ty,第二部分为模型验证阶段数据cy;同时将所述备选的预测因子的历史数据分为训练阶段数据tx以及验证阶段数据cx;由预测因子的未来数据px组成模型预报阶段数据;若搜集到的所述备选的预测因子的历史数据时间序列为(a
‑
b),则训练阶段划分为(a
‑
c),验证阶段划分为(c
‑
b);
10.(3)差分阶段,针对步骤(2)中所述训练阶段数据tx所存在的多重共线性问题,首先对该训练阶段数据tx做多重共线性检验,若检验不通过,则对tx中存在共线性的预报因子进行差分,差分后的预报因子设为txd,预测量设为tyd,将差分后的txd与tyd分别表示为txd=xd
t
‑
xd
t
‑1,tyd=yd
t
‑
yd
t
‑1,其中xd
t
、xd
t
‑1分别表示t时刻和t
‑
1时刻预报因子x的值,yd
t
、yd
t
‑1分别表示t时刻和t
‑
1时刻预测量y的值;
11.(4)模型训练阶段,构建逐步聚类统计降尺度训练阶段矩阵t,如式(1)所示:
[0012][0013]
式中,p、q分别为预报因子x的个数,以及预报因子x的时间序列长度,k为预测量y的个数;
[0014]
采用wilks准则进行聚类的切割或合并,直到无法切割或合并,从而生成预报因子与预测量间的聚类树模型;
[0015]
(5)模型验证阶段,将cx作为模型的输入数据,通过步骤(4)中所生成的聚类树模型求解验证阶段的cy’,分析验证阶段的预报量cy与模型求解的cy’之间的关系,求解rmse,r2,其中其中,n
cy
为cy的样本量,为cy的样本均值;
[0016]
(6)模型预测阶段,将px作为模型输入数据,通过步骤(4)中所生成的聚类树模型求解预测阶段的py,以此得到预报量的未来数据。
[0017]
优选地,步骤(1)中筛选出与预报量相关性高的预测因子的标准为相关性大小,所述标准分为绝对标准和相对标准,其中,绝对标准是根据备选预报因子的个数n,选取其中相关性最高的前m个预报因子,且m≤n;相对标准则是选取相关性最高的前α%,其中,0≤α≤100。
[0018]
优选地,步骤(4)中在切割或合并阶段,对矩阵t
q
×
(p k
‑
2)
进行切割,首先,按照矩阵t中的第j列按升序排序,其中1≤j≤p
‑
1,然后,矩阵t中的第i列将矩阵分为上下两个矩阵t
u
和t
l
,其中1≤i≤q,矩阵t
q
×
(p k
‑
2)
表示为如式(2)所示:
[0019][0020]
判断是否切割或合并的wilks准则为其中w为组内平方和及外积矩阵之和,h为的组间平方和及外积矩阵之和;对t
u
和t
l
则有如式(3)、(4)所示关系:
[0021]
[0022][0023]
其中,分别为t
u
,t
l
的样本均值,i(p
‑
1),(q
‑
i)(p
‑
1)分别为t
u
,t
l
的样本量,对λ进行f检验来判断聚类t
u
,t
l
是否应该切割或合并,f检验标准如式(5)所示:
[0024][0025]
其中,d为筛选的预报因子的个数,当f>f
0.05
,则拒绝原假设t
u
,t
l
两类被切割;当f<f
0.05
,接受原假设t
u
,t
l
两类被合并;
[0026]
当t被分为t
u
,t
l
后,对t
u
重复所述切割或合并的步骤,同时对t
l
重复所述切割或合并的步骤,令分割后的任一矩阵为e,f,其中n
e
,n
f
为矩阵的样本量,对e,f进行wilks准则检验,当f>f
0.05
,则拒绝原假设u
e
=u
f
,e,f两类被切割;当f<f
0.05
,接受原假设u
e
=u
f
,e,f两类合并,以此类推,直至针对任意矩阵无法被切割或合并时,停止所述切割或合并的步骤,此时产生的结果为聚类树模型。
附图说明
[0027]
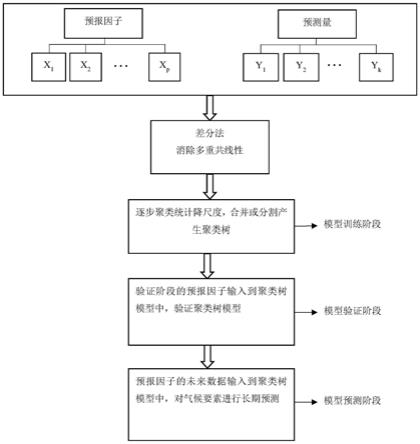
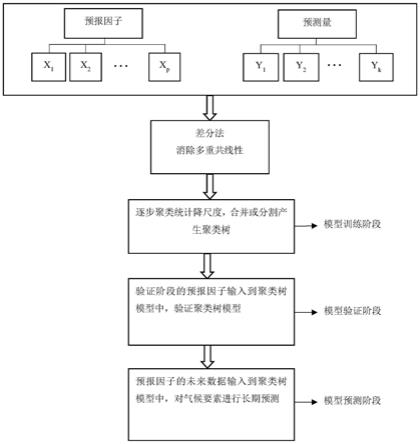
图1为本发明所述基于差分法消除多重共线性的逐步聚类统计降尺度方法的流程图。
[0028]
图2为本发明所述方法中构建聚类树模型的流程图。
具体实施方式
[0029]
下面结合附图和具体实施例对本发明作进一步详述。
[0030]
如图1所示,改进的逐步聚类降尺度方法包括以下步骤:
[0031]
(1)搜集并筛选数据,将地面观测站点或再分析气候数据作为预报量,将全球气候模型(gcm)或区域气候模型(rcm)模拟的气候数据作为备选的预测因子,通过计算备选的预测因子与预报量之间的相关性,筛选出与预报量相关性高的预测因子。筛选预报因子的标准为相关性大小,标准可分为两种,绝对标准和相对标准,其中绝对标准是根据备选预报因子的个数(n),选取其中相关性最高的前m个预报因子,且m≤n,相对标准则是选取相关性最高的前α%,其中,0≤α≤100。
[0032]
(2)将步骤(1)中的预报量按照时间序列分为两部分数据,第一部分为逐步聚类统计降尺度的模型训练阶段数据(ty),第二部分为模型验证阶段数据(cy),同时将预测因子的历史数据分为相同的两部分数据,训练阶段数据(tx)以及验证阶段数据(cx),模型预报阶段数据由预测因子的未来数据(px)组成。若搜集到的历史数据时间序列为(a
‑
b),则训练阶段划分为(a
‑
c),验证阶段划分为(c
‑
b)。
[0033]
(3)差分阶段,针对预报因子中存在的多重共线性问题,首先对预报因子做多重共线性检验,若检验不通过,则对存在共线性的预报因子进行差分,差分后的预报因子为txd,预测量为tyd。
[0034]
由原始数据矩阵计算得到差分后的数据矩阵过程如下:
[0035]
针对原模型,表示为如式(ⅰ)所示:
[0036]
y
t
=β0 β1x1t β2x
2t
…
β
m
x
mt
μ
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(ⅰ),
[0037]
其中,y
t
代表预测量y在t时刻的值,x
1t
、x
2t
…
x
mt
表示步骤(1)中筛选出m个预报因子,β0、β1…
β
m
分别代表预报因子x
it
的系数,μ
t
代表t时刻的误差量;
[0038]
则对于t
‑
1时刻,表示为如式(ⅱ)所示:
[0039]
y
t
‑1=β0 β1x
1t
‑1 β2x
2t
‑1
…
β
m
x
m,t
‑1 μ
t
‑1ꢀꢀꢀꢀꢀꢀꢀ
(ⅱ),
[0040]
原模型t时刻与t
‑
1时刻的差分形式则表示为如式(ⅲ)所示:
[0041][0042]
式(ⅰ)减去式(ⅱ)可得差分模型,如式(ⅳ)所示:
[0043]
△
y
t
=β1△
x
1t
β2△
x
2t
…
β
m
△
x
mt
△
μ
t
ꢀꢀꢀꢀꢀꢀꢀꢀ
(ⅳ),
[0044]
因此,差分后的txd与tyd分别表示为txd=xd
t
‑
xd
t
‑1,tyd=yd
t
‑
yd
t
‑1,其中xd
t
、xd
t
‑1分别表示t时刻和t
‑
1时刻预报因子x的值,yd
t
、yd
t
‑1分别表示t时刻和t
‑
1时刻预测量y的值。
[0045]
(4)模型训练阶段,构建逐步聚类统计降尺度训练阶段矩阵t如式(1)所示:
[0046][0047]
式中,p、q分别为预报因子x的个数,以及预报因子x的时间序列长度,k为预测量y的个数;
[0048]
采用wilks准则进行聚类的切割或合并,直到无法切割或合并,生成预报因子与预测量间的聚类树模型。
[0049]
具体的,如图2所示,在切割或合并阶段,对矩阵t
q
×
(p k
‑
2)
进行切割,首先按照矩阵t中的第j列按升序排序,其中1≤j≤p
‑
1,然后矩阵t中的第i列将矩阵分为上下两个矩阵t
u
和t
l
,其中1≤i≤q,矩阵t
q
×
(p k
‑
2)
如式(2)所示:
[0050][0051]
判断是否切割或合并的wilks准则为其中w为组内平方和及外积矩阵之和,h为的组间平方和及外积矩阵之和,对t
u
和t
l
则有如式(3)、(4)所示关系:
[0052][0053]
[0054]
其中,分别为t
u
,t
l
的样本均值,i(p
‑
1),(q
‑
i)(p
‑
1)分别为t
u
,t
l
的样本量,对λ进行f检验来判断聚类t
u
,t
l
是否应该切割或合并,f检验标准如式(5)所示:
[0055][0056]
其中,d为筛选的预报因子的个数,当f>f
0.05
,拒绝原假设t
u
,t
l
两类应该被切割;当f<f
0.05
,接受原假设t
u
,t
l
两类应该被合并。
[0057]
当t被分为t
u
,t
l
后,对t
u
重复上述步骤,同时对t
l
重复上述步骤,令分割后的任一两矩阵为e,f,n
e
,n
f
为矩阵的样本量,对e,f进行wilks准则检验,当f>f
0.05
,拒绝原假设u
e
=u
f
,e,f两类应该被切割;当f<f
0.05
,接受原假设u
e
=u
f
,e,f两类应该合并,以此类推,直至针对任意矩阵无法被切割或合并时,停止此步骤,此时产生的结果为聚类树模型。
[0058]
(5)模型验证阶段,将cx作为模型输入数据,通过聚类树模型求解验证阶段的cy’,分析验证阶段的预报量cy与模型求解的cy’之间的关系,求解rmse,r2。其中其中n
cy
为cy的样本量,为cy的样本均值。
[0059]
(6)模型预测阶段,将px作为模型输入数据,通过聚类树模型求解预测阶段的py,以此得到预报量的未来数据。
[0060]
相对现有技术,本发明的有益效果主要包括:
[0061]
1、解决了气候统计降尺度模型中出现得多重共线性问题,改进了逐步聚类统计降尺度方法。
[0062]
2、改进后的逐步聚类法所产生的聚类树更能反映真实的预测因子与预报量之间的关系,为计算未来气候要素提供更可靠的统计方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。