1.本发明属于模式识别与人工智能技术领域,特别涉及一种文本识别中识别网络与语言模型的联合优化方法。
背景技术:
2.随着深度学习技术的发展和相关硬件的逐渐完善,越来越多用于文本识别的人工智能神经网络被应用于实际生产和生活中。但是,复杂的背景、多种多样的书写风格和字体格式、庞大的字符种类数量使得识别效果仍然较差。人类在识别文本时,通常会结合语义信息进行快速而准确的识别。因而,如何设计一种能够高效利用识别网络的输出信息并结合语义进行推理的语言模型成为一项重要的研究课题。现有的方法通常将语言模型作为识别网络的后处理,对于识别网络的输出,通过传统的统计语言模型或者基于循环神经网络的语言模型进行处理,没有考虑到识别网络和语言模型是相互促进、相辅相成的。
技术实现要素:
3.本发明为了实现文本行识别,提供一种文本识别中识别网络与语言模型的联合优化方法,该方案联合优化识别网络和语言模型,可以极大地提升识别准确率,具有很高的使用价值。
4.本发明采用如下技术方案来实现,一种文本识别中识别网络与语言模型的联合优化方法,包括:
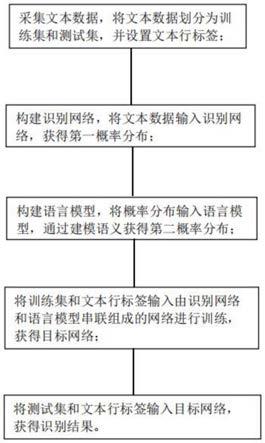
5.采集文本数据,将所述文本数据划分为训练集和测试集,并设置文本行标签;构建识别网络,将所述文本数据输入所述识别网络,获得第一概率分布;构建语言模型,将所述概率分布输入所述语言模型,通过建模语义,获得第二概率分布;将所述训练集和所述文本行标签输入识别网络和语言模型串联组成的网络进行训练,获得目标网络;将所述测试集和所述文本行标签输入所述目标网络,获得识别结果。
6.优选地,采集所述文本数据包括采集文本语料合成数据、现有文本行数据、待测文本行数据;
7.将所述文本数据划分为训练集和测试集包括,将所述文本语料合成数据以及所述现有文本行数据作为训练集,所述待测文本行数据作为测试集。
8.优选地,设置所述文本行标签包括基于所述文本语料合成数据的文本语料和单字数据,合成联机和脱机文本行的同时返回标签信息;
9.基于所述现有文本行数据,读取记录的文本行标签。
10.优选地,所述文本识别网络采用ctc识别网络或attention识别网络;
11.采用所述ctc识别网络,对于需要识别的输入x,输出为概率分布p
ctc
;
12.所述概率分布p
ctc
表示为:
[0013][0014]
其中net
ctc
表示基于ctc的识别神经网络,t为时间点数量,n
cls
为字符类别数;
表示为:
[0039]
f3=layernorm(f2 f1)
[0040]
f4=layernorm(ffn(f3) f3)
[0041]
其中,layernorm为层归一化操作,ffn为两层全连接层组成的网络。
[0042]
优选地,基于所述transformer编码层构建基于transformer编码器的语言模型,针对不同的识别网络,将所述第一可学习嵌入或所述第二可学习嵌入作为所述语言模型的输入,获得建模语义后的特征;基于所述建模语义后的特征,通过分类器获得所述第二概率分布;基于所述第二概率分布,获得每个时间点的预测结果,将所述预测结果去除连续重复的预测和空类别,获得识别结果。
[0043]
优选地,获得所述目标识别网络还包括基于自适应的梯度下降法,将所述训练集和所述文本行标签输入所述文本识别网络进行训练;
[0044]
对于采用所述ctc识别网络的情况,根据标签计算的ctc损失p
ctc
的ctc损失相加获得第一总损失l
ctc
;
[0045]
或者对于采用所述attention识别网络的情况,根据标签计算的交叉熵损失p
attn
的交叉熵损失相加获得第二总损失l
attn
。
[0046]
本发明公开了以下技术效果:
[0047]
(1)本发明提出了一种文本识别中识别网络与语言模型的联合优化方法,不再将两者当作独立的两部分,而是通过联合优化使得两者更好地融合,其中语言模型的回传梯度可以指导识别网络的训练,识别网络可以进一步为语言模型提供更好的初始结果。
[0048]
(2)本发明采用了transformer编码器构建语言模型,可以极大地提升全局建模能力和计算的并行性。
[0049]
(3)本发明识别准确率高、鲁棒性强,适用于各种识别网络。
附图说明
[0050]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0051]
图1为本发明实施例的方法流程图;
[0052]
图2为本发明实施例的文本识别流程图;
[0053]
图3为本发明实施例的语言模型结构图。
具体实施方式
[0054]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0055]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实
施方式对本发明作进一步详细的说明。
[0056]
如图1所示,本发明提供了一种文本识别中识别网络与语言模型的联合优化方法,包括以下步骤:
[0057]
采集文本数据,将所述文本数据划分为训练集和测试集,并设置文本行标签;构建识别网络,将所述文本数据输入所述识别网络,获得第一概率分布;构建语言模型,将所述概率分布输入所述语言模型,通过建模语义,获得第二概率分布;将所述训练集和所述文本行标签输入识别网络和语言模型串联组成的网络进行训练,获得目标网络;将所述测试集和所述文本行标签输入所述目标网络,获得识别结果。
[0058]
采集所述文本数据包括采集文本语料合成数据、现有文本行数据、待测文本行数据;
[0059]
将所述文本数据划分为训练集和测试集包括,将所述文本语料合成数据以及所述现有文本行数据作为训练集,所述待测文本行数据作为测试集。
[0060]
设置所述文本行标签包括基于所述文本语料合成数据的文本语料和单字数据,合成联机和脱机文本行的同时返回标签信息;
[0061]
基于所述现有文本行数据,读取记录的文本行标签。
[0062]
所述文本识别网络采用ctc识别网络或attention识别网络;
[0063]
采用所述ctc识别网络,对于需要识别的输入x,输出为概率分布p
ctc
;
[0064]
所述概率分布p
ctc
表示为:
[0065][0066]
其中net
ctc
表示基于ctc的识别神经网络,t为时间点数量,n
cls
为字符类别数;
[0067]
采用所述attention识别网络,对于需要识别的输入,输出为概率分布p
attn
:
[0068][0069]
其中,net
attn
表示基于attention的识别神经网络,t为时间点数量,n
cls
为字符类别数。
[0070]
获得所述第二概率分布还包括,针对不同的文本类别,初始化不同的可学习嵌入;基于所述可学习嵌入构建可微分的预测嵌入;构建transformer编码层;基于所述transformer编码层构建基于transformer编码器的语言模型,将所述可微分的预测嵌入作为所述语言模型的输入,获得建模语义后的特征;基于所述建模语义后的特征,通过分类器获得所述第二概率分布。
[0071]
所述可学习嵌入为针对ctc识别网络的第一可学习嵌入或针对attention识别网络的第二可学习嵌入;
[0072]
所述第一可学习嵌入表示为:
[0073][0074]
所述第二可学习嵌入表示为:
[0075][0076]
其中,d
emb
为嵌入的维度。
[0077]
所述可微分的预测嵌入为针对ctc识别网络的第一可微分预测嵌入或针对attention识别网络的第二可微分预测嵌入;
[0078]
所述第一可微分预测嵌入表示为:
[0079][0080]
所述第二可微分预测嵌入表示为:
[0081][0082]
构建所述transformer编码层包括,基于输入特征f1,经过多头注意力层获得特征f2,对所述特征f2进行归一化操作并通过两层全连接层组成的网络,获得目标输出f4;
[0083]
所述特征f2表示为:
[0084]
f2=multihead(q,k,v)=concat(head1,head2,...,head
h
)w
o
[0085]
其中head
i
为:
[0086][0087]
其中attention为:
[0088][0089]
q,k,v均等于f1;目d
k
=d
v
=d
emb
/h;
[0090]
对所述特征f2进行归一化操作并通过两层全连接层组成的网络,获得目标输出f4表示为:
[0091]
f3=layernorm(f2 f1)
[0092]
f4=layernorm(ffn(f3) f3)
[0093]
其中,layernorm为层归一化操作,ffn为两层全连接层组成的网络。
[0094]
基于所述transformer编码层构建基于transformer编码器的语言模型,针对不同的识别网络,将所述第一可学习嵌入或所述第二可学习嵌入作为所述语言模型的输入,获得建模语义后的特征;基于所述建模语义后的特征,通过分类器获得所述第二概率分布;基于所述第二概率分布,获得每个时间点的预测结果,将所述预测结果去除连续重复的预测和空类别,获得识别结果。
[0095]
获得所述目标识别网络还包括基于自适应的梯度下降法,将所述训练集和所述文本行标签输入所述文本识别网络进行训练;
[0096]
对于采用所述ctc识别网络的情况,根据标签计算的ctc损失p
ctc
的ctc损失相加获得第一总损失l
ctc
;
[0097]
或者对于采用所述attention识别网络的情况,根据标签计算的交叉熵损失p
attn
的交叉熵损失相加获得第二总损失l
attn
。
[0098]
进一步地,本发明的文本识别中识别网络与语言模型的联合优化方案包括:
[0099]
(1)数据获取:使用根据真实语料合成的数据以及公开的真实文本行数据作为训
练数据,使用真实场景采集的文本行作为测试数据。
[0100]
(2)标签制作:采用有监督的方法训练识别网络,每个文本行都有对应的文本信息。
[0101]
(3)识别网络:采用现有的已经训练完成的基于ctc或者attention的网络。
[0102]
(4)语言模型:语言模型以识别网络输出的概率分布为输入,通过transformer编码器建模语义,提升识别效果。
[0103]
(5)训练网络:将训练数据和标签输入到网络中进行训练,网络损失为识别网络和语言模型损失的相加之和。
[0104]
(6)测试网络:输入测试数据到训练完成的网络中,得到识别结果。
[0105]
所述步骤(1)使用根据真实语料合成的数据以及公开的真实文本行数据作为训练数据,使用真实场景采集的文本行作为测试数据,其中合成数据为边训练边合成。
[0106]
所述步骤(2)包括以下步骤:
[0107]
(2
‑
1)使用公开的文本语料和单字数据,合成联机和脱机文本行,在合成的同时返回标签信息。
[0108]
(2
‑
2)对于公开文本行数据集,读取其记录的文本行标签。
[0109]
所述步骤(3)包括以下步骤:
[0110]
(3
‑
1)使用已经训练完成的基于ctc的识别网络,该网络对于需要识别的输入x,输出为概率分布p
ctc
:
[0111][0112]
其中net
ctc
表示基于ctc的识别神经网络,t为时间点数量,n
cls
为字符类别数(多出的一个类别为空类别)。
[0113]
(3
‑
2)或者使用已经训练完成的基于attention的识别网络,该网络对于需要识别的输入x,输出为概率分布p
attn
:
[0114][0115]
其中,net
attn
表示基于attention的识别神经网络,t为时间点数量,n
cls
为字符类别数(多出的两类分别为开始类和结束类)。文本识别流程图如图2所示。
[0116]
所述步骤(4)包括以下步骤:
[0117]
(4
‑
1)首先,对于每一个类别,初始化一个可学习的嵌入。特别地,对于基于ctc的方法,可学习的嵌入e
ctc
表示为:
[0118][0119]
其中,d
emb
为嵌入的维度。
[0120]
对于基于attention的方法,可学习的嵌入e
attn
表示为:
[0121][0122]
(4
‑
2)接着,构建可微分的预测嵌入。特别地,对于基于ctc的识别网络的输出p
ctc
,可微分的预测嵌入为:
[0123][0124]
对于基于attention的识别网络的输出p
attn
,可微分的预测嵌入为:
[0125][0126]
由于矩阵操作可微,语言模型的梯度可以回传至识别网络。
[0127]
(4
‑
3)构建transformer编码层,功能如下。
[0128]
对于transformer编码层的输入特征f1,首先经过多头注意力层得到特征f2:
[0129]
f2=multihead(q,k,v)=concat(head1,head2,...,head
h
)w
o
[0130]
其中head
i
为:
[0131][0132]
其中attention为:
[0133][0134]
在上述公式中,q,k,v均等于f1;;且d
k
=d
v
=d
emb
/h。
[0135]
然后,对于特征f2,进行如下操作:
[0136]
f3=layernorm(f2 f1)
[0137]
f4=layernorm(ffn(f
a
) f3)
[0138]
其中,layernorm为层归一化操作(layer normalization),ffn为两层全连接层组成的网络。f4即为该层的输出。
[0139]
(4
‑
4)构建基于transformer编码器的语言模型,语言模型结构图如图3所示,由数个transformer编码层组成。该语言模型的输入为可微分的预测嵌入或输出为
[0140]
(4
‑
5)基于f
cls
,通过分类器得到语言模型输出的概率分布。特别得,对于基于ctc的方法,输出的概率分布为:
[0141][0142]
其中通过该输出概率,得到每个时间点的预测结果,再去除连续重复的预测和空类别,得到最终的识别结果。
[0143]
对于基于attention的识别方法,输出的概率分布为:
[0144][0145]
其中通过该输出概率,得到每个时间点的预测结果,从开始类到结束类中间的序列即为最终的识别结果。
[0146]
所述步骤(5)包括以下步骤:
[0147]
(5
‑
1)训练参数设定:将训练数据送入网络训练,使用的优化算法是一种自适应的梯度下降法(adamw),学习率为0.0001,每次迭代送入32条数据,其中50%为真实数据,50%
为合成数据。
[0148]
(5
‑
2)训练卷积神经网络:对于基于ctc的识别网络,分别根据标签计算的ctc损失p
ctc
的ctc损失总损失l
ctc
即为两者的加和:
[0149][0150]
对于基于attention的识别网络,分别根据标签计算的交叉熵损失p
attn
的交叉熵损失总损失l
attn
即为两者的加和:
[0151][0152][0153][0154]
其中c
i
为第i个时间点对应的标签类别。
[0155]
所述步骤(6)包括以下步骤:
[0156]
(6
‑
1)把测试集中的图片以及标签输入到已训练好的网络中,进行测试。
[0157]
(6
‑
2)识别完成后,程序计算准确率。
[0158]
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。