1.本发明属于生物信号处理领域,涉及一种针对于脑机接口的跨域脑电信号识别方法。
背景技术:
2.脑机接口(bci)逐渐成为一种新的通信途径,通过直接将人们的神经元活动解码成特定的命令来操纵外部硬件设备。在头皮脑电信号(eeg)中,通常缺乏大量有标签样本来用于传统机器学习中的训练模型,进行数据标注时费时费力,给我们带来了很大的阻碍。并且,不同的用户对相同的刺激也有不同的神经反应,即使是相同的用户也可以在不同的时间和地点对相同的刺激有不同的神经反应。对于如何解决不同脑电信号差异性,将他人的脑电数据能够用于其他人的训练是一个富有挑战性的问题。
3.迁移学习不同于传统机器学习,它取消了训练和测试样本位于相同的特征空间中,并具有相同分布的假设。它的核心是利用算法来最大限度地利用有标注的领域知识,来辅助目标领域的知识获取和学习。简而言之就是寻找到源域和目标域的相似性。因此能够解决不同脑电信号差异性问题,在eeg领域中得到广泛的关注。
4.迁移学习面临着如何迁移的问题,即如何有效地适应另一个领域。脑电信号中通常有更多的通道,但这导致了维度冗余,使得脑机接口的迁移学习变得困难。针对这一问题,本发明提出了一种基于多流形嵌入分布式对齐eeg识别算法,该算法在高维空间中具有低维流形结构,可以很好地近似源域和目标域的分布。因此,本发明提取每个主体的黎曼流形的切线空间特征(而不是统一在一个切线空间中)。随后,将其映射到格拉斯曼流形,在映射到格拉斯曼流形之前,对特征进行主成分分析,以确保算法的计算性能。在这个框架下,再进行更深层次的自适应分布适应。最后,在格拉斯曼流形空间中学习了一个与主题相适应的特征。
技术实现要素:
5.本发明公开了一种基于多流形嵌入式分布对齐的领域自适应脑电信号识别方法。我们所做的是在eeg运动想象(mi)数据集上分别提取每个人的黎曼流形的切空间特征,而不是统一在一个切空间中。此时再映射到格拉斯曼流形中,将黎曼切空间得到的特征经过主成分分析后的数据作为子空间,每个子空间在格拉斯曼流形中看作一个点,在此框架下再进行更深层次的自适应分布适配,最终在格拉斯曼流形空间中学习到一个适应于受试者的特征。
6.本发明提供一种基于多流形嵌入式分布对齐的领域自适应方法,包括以下步骤:给定一个源域有标签数据集d
s
={x
s
,y
s
}和目标域的一个无标签数据集d
t
={x
t
},其中x
s
表示源域数据,y
s
表示源域标签;n
s
,n
t
分别用来表示源域和目标域的样本数,d是数据实例的维数;并且用a,b表示子空间映射后的源域和目标域;设定假设条件为在特征空间上x
s
=x
t
,在标签空间上y
s
=y
t
,但在边际概率上p
s
(x
s
)≠p
t
(x
t
)和条
件概率上q
s
(y
s
|x
s
)≠q
t
(y
t
|x
t
);经过格拉斯曼流形的映射后源域依旧使用x
s
来表示,目标域用x
t
来表示;
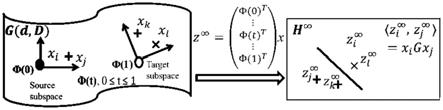
7.步骤一,将原始信号在黎曼流形中进行质心对齐并且提取各域的切空间特征。
8.在提取黎曼流形的切空间特征时需要利用黎曼均值与切线空间映射。在黎曼几何中两个spd矩阵spd1和spd2之间的黎曼距离为:
[0009][0010]
其中||
·
||
f
是f范数。
[0011]
的黎曼均值为:
[0012][0013]
在切空间映射中它将每一个协方差矩阵p
i
投影到黎曼均值上的黎曼流形的切空间上:
[0014][0015]
其中,upper为取矩阵上三角元素;
[0016]
步骤二,将各自域的切空间特征统一映射入格拉斯曼流形中。
[0017]
格拉斯曼流形问题设定为:假如w是n维向量空间,考虑w中全体k维子空间构成的集合g=grass(k,w),因为g上有自然的流形结构,因此它被称为格拉斯曼流形;流形空间中的特征被表示为z=φ(t)
t
x,其中φ(t)
t
为投影矩阵;变换后的特征z
i
和z
j
的内积定义了一个半正定的测地线流式核:
[0018][0019]
步骤三,在统一的流形空间内进行域适应操作。
[0020]
域适应方法具体如下:
[0021]
1)目标域类内类间散度矩阵保持数据差异属性;在子空间的映射过程中,根据流形的假设,两个不同的样本在原始空间的距离关系与映射空间的距离关系保持一致,通过下式来保留目标域数据的可区分性:
[0022][0023][0024]
其中,s
w1
为目标域的类内散射矩阵,s
b1
为源域的类间散射矩阵,其定义如下:
[0025]
[0026][0027]
其中是属于e类的目标域数据集,是属于e类的目标域数据集,是e类的数据中心矩阵,为中心矩阵,是所有矩阵的列向量,n
t(e)
是e类中的目标样本的数量;
[0028]
2)源域类内类间散度矩阵保持数据差异属性;和目标域的可区分性保留一致,得到源域的保留条件:
[0029][0030][0031]
其中,s
b2
为源域的类间散度矩阵,s
w2
为源域的类内散度矩阵,定义与目标域散度矩阵一致;
[0032]
3)目标域构造拉普拉斯图保持局部信息;图的正则化试图在低维空间中保留当地的相邻关系,在格拉斯曼流形中能够起到很好的作用,因此本文加入拉普拉斯正则化项来进一步利用流形g中最近点的相似几何性质;将具有成对的亲和力矩阵表示为
[0033][0034]
其中,n
p
(x
i
)是x
i
的p
‑
最邻域集合,σ为范围参数,通常为1;这里使用归一化图拉普拉斯矩阵l
t
=i
‑
d
‑
1/2
vd
‑
1/2
,其中d是对角矩阵,其中得到图的正则化形式为:
[0035][0036]
其中f(x
i
),f(x
j
)为在流形空间中的数据表达形式;
[0037]
4)正则化与域漂移;将黎曼切空间特征映射到格拉斯曼流形中后,目标域和源域拥有了相同特征空间,利用ca让它们的概率分布逼近,同时优化a和b,来保留源类信息和目标域方差,与有着不同比例的关系,所以设置β参数来获得最佳的比例;使用以下方法将a,b子空间逼近:
[0038][0039]
5)目标域方差最大化
[0040]
将共同投影后的目标域做方差最大化,实现方式为:
[0041]
max
b
tr(b
t
s
t
b)
ꢀꢀꢀ
(14)
[0042][0043]
其中为目标域的中心矩阵,是全为1的矩阵;
[0044]
6)适配概率分布自适应;使用mmd距离来衡量各域之间的分布差异性,mmd计算的是k维嵌入后源域的样本均值和目标域之间的距离,如下式:
[0045][0046]
其中φ(
·
)为映射函数。
[0047]
在目标域的条件分布表示上,利用源域数据训练得到的分类器直接预测目标域数据来得到伪标签,用伪标签来表示目标域的类条件分布;利用多次迭代更新目标域的伪标签,逐渐缩小两个域之间的条件分布差异;通过下式实现:
[0048][0049][0050]
其中,
[0051][0052][0053][0054][0055]
其中o
t
o
s
为全一矩阵,c为所属的类别。
[0056]
本发明与已有的诸多迁移学习方法相比,具有如下特点:
[0057]
在分析方法上,本发明利用流形空间中的低维结构特性,首次采用多流形嵌入的方式来进行领域自适应。利用多流形的目的是能够得到低维结构中的信息和剔除多余信息,并且保持很好的可计算性。此外本发明首次采用了利用训练所得到的伪标签来迭代更新目标域的散度矩阵。在最大化类间距离的同时,最小化类内距离。本发明对于脑机接口领域的跨域分析具有积极意义。
[0058]
在验证本发明的有效性上,采用了三个脑电数据集进行科学的验证,并分别做了单源测试和多源测试,证明了本发明在不同数据集上的效果一样显著,并且本发明不仅在脑机接口领域有效,在其他领域同样适用,可在图像,文本,语音等领域进行延伸。
附图说明
[0059]
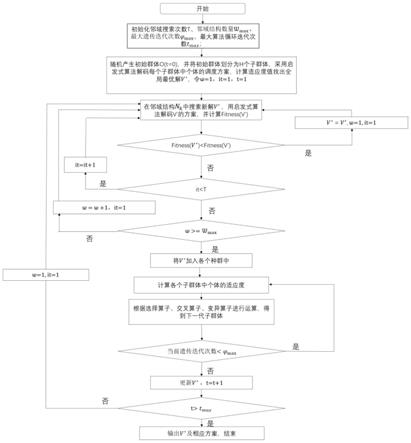
图1所示为格拉斯曼流形迁移学习方法示意图;
[0060]
图2所示为数据集采集过程图
[0061]
图3(a)所示为mi2中s1,s2的t
‑
sne可视化:原始信号进行共空间模式滤波;
[0062]
图3(b)所示为mi2中s1,s2的t
‑
sne可视化:原始信号进行质心对齐;
[0063]
图3(c)所示为mi2中s1,s2的t
‑
sne可视化:原始信号使用多流形嵌入式分布对齐的领域自适应算法。
具体实施方式
[0064]
下面结合图和表格对本发明的实施例作详细说明:本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程。
[0065]
本实施例的具体实现流程如图1所示。
[0066]
在数据预处理阶段,首先将mi1,mi2,mi3进行8
‑
30hz滤波处理,来获得实验所用的信号,再将整体信号做分段处理,选取新线索后的0.5
‑
3.5s时间段来做实验。数据集的采集实验范式如图2所示。
[0067]
接下来,对于三个mi数据集,使用了csp筛选试验的六个对数方差特性作为基础特征。再利用协方差矩阵质心对齐方法获得对齐后的协方差矩阵,即在预处理阶段进行了初步的数据边缘概率分布差异的缩小。
[0068]
最后,将得到的子空间特征进行领域自适应操作,得到变换后的可跨域特征,将此特征用于分类器的分类。特征变换过程中维度发生了多次改变,具体如表1所示。
[0069]
表1不同数据集的空间输入维度;
[0070] mi1mi2mi3tangent space200
×
200253
×
144
×
280riemannian59
×
59
×
20022
×
22x144188
×
188
×
280grassmann25
×
20025
×
14425
×
280
[0071]
针对mi的迁移特性,本发明将进行单源与多源的相关实验,在单源的本方法中,采用单个被试者为目标域,同时数据集中单个被试者作为源域。设v是一个数据集中的主题的数量。拥有v(v
‑
1)个不同的实验。在多源的本方法中,单个受试者作为目标域,数据集中其他的受试者作为源域共同训练,拥有v个不同的实验。以mi2为例,mi2拥有9名受试者,因此
在单源实验中,拥有9
×
8=72次不同的实验。多源实验中,当以s1作为目标域时,s1
→
s2,s3,s4,s5,s6,s7,s8,s9,其中s2,s3,s4,s5,s6,s7,s8,s9共同作为源域。由于s2,s3,s4,s5,s6,s7,s8,s9都可分别做源域,因此有9次不同的实验。
[0072]
采用平衡分类精度(bca)作为性能指标:
[0073][0074]
其中tp
k
和n
k
分别是类别k中的正确分类的数量和样本的数量。
[0075]
本发明的目标是降低目标域与源域之间的差异性和增强类别之间的差异性,利用t
‑
sne可视化来展现本发明在eeg信号中迁移学习的优势,以mi2数据集中s1,s2为例,并画出原始信号的各域分布和类别的分布进行对比,如图3(a),图3(b),图3(c)所示。
[0076]
图3(a)为原始信号经过csp空间滤波处理后的分布图,原始图为红蓝两色,其中红色部分由实线框起,为target class,并且可见source class的源域与target class的目标域的界限十分明显,在类别上具有区分度,但对于得到的模型,明显不具有良好的泛化能力;图3(b)为原始信号经过ca对齐目标域与源域协方差矩阵,在黎曼空间中提取切空间特征的分布图,经过预处理后的数据边缘分布有了进一步的逼近,但是泛化能力依旧不足,类间的差异性并没被很好的体现出来;图3(c)为经过预处理后的数据通过本发明得到的分布图,在该算法下,目标域与源域的边缘分布与条件分布得到了很好的对齐,消除了域间差异,模型具有较强的泛化能力,并在类别的差异上被充分体现出来。
[0077]
本发明在三个运动想象的数据集上分别进行单源迁移学习和多源迁移学习来验证算法的可靠性。采用平衡分类精度bca作为指标,并且在所有方案中固定参数α=0.01,μ=0.86,β=0.1,ρ=20,将伪标签迭代次数设置为4,实验结果如表2(a),表2(b)所示:
[0078]
表2(a)本发明进行单源实验在各数据集的平均准确率
[0079][0080]
表2(b)本发明进行多源实验在各数据集的平均准确率
[0081][0082][0083]
表中最终的平均准确率采用黑体加粗。在与其他最新迁移学习方法的比较中,本发明在单源迁移和多源迁移中均取得了平均最佳结果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。