1.本公开实施例涉及医疗保健信息学技术领域,尤其涉及一种基于机器翻译模型的先导化合物成药性优化方法。
背景技术:
2.目前,药物研发的最大的挑战之一就是如何高效的进行先导化合物优化,这也是药物化学家们面临的一大难题。超过50%化合物因为没有合适的吸收、分布、代谢、排泄(admet)和安全性质从而在药物研发的过程中失败,而admet性质优化是一个难度极高的多目标优化任务,要求在提高分子的成药性同时保持分子的活性;另一方面,空间大、经验少、成本高、耗时长等因素也使得高效进行化合物药代动力学性质和安全性的优化成为一大难题。而现有的技术一般是通过计算生成新分子,接着利用虚拟筛选程序对所产生的新化合物进行筛选以获得符合候选化合物,然而计算量巨大,或者通过预测模型对分子整体进行预测,不能针对成药性特定指标进行优化,且优化后药物的成药性不高,优化效率和适应性较差。
3.可见,亟需一种优化效率和适应性强的基于机器翻译模型的先导化合物成药性优化方法。
技术实现要素:
4.有鉴于此,本公开实施例提供一种基于机器翻译模型的先导化合物成药性优化方法,至少部分解决现有技术中存在优化效率和适应性较差的问题。
5.第一方面,本公开实施例提供了一种基于机器翻译模型的先导化合物成药性优化方法,包括:
6.利用预设数量的样本分子字符串训练翻译模型,其中,所述翻译模型包括编码器和解码器;
7.根据机器学习算法建立多个药代动力学终点对应的计算模型,形成预测模型组;
8.将初始分子字符串输入所述编码器,生成目标矢量;
9.根据接收到的优化指令将所述目标矢量输入预测模型组,得到所述优化指令对应的优化预测指标;
10.根据所述优化预测指标和所述初始分子字符串对应的计算指标进行加权平均计算,得到所述初始分子字符串的得分;
11.根据所述目标矢量和所述得分,利用优化算法迭代预设次数得到优化分数集合,其中,所述优化分数集合包括多个优化矢量和每个所述优化矢量对应的优化得分;
12.将所述优化分数集合输入所述解码器,利用预设算法计算每个所述优化矢量对应的字符串,形成目标分子字符串集合。
13.根据本公开实施例的一种具体实现方式,所述利用预设数量的样本分子字符串训练翻译模型的步骤,包括:
14.分别将每个所述样本分子字符串输入所述编码器,并将所述编码器的输出结果输入所述解码器;
15.将所述解码器的每个输出结果与其对应的样本分子字符串的真实标签的损失,并执行梯度更新。
16.根据本公开实施例的一种具体实现方式,所述根据机器学习算法建立多个药代动力学终点对应的计算模型,形成预测模型组的步骤,包括:
17.从初始数据库内提取样本数据集;
18.从所述样本数据集中提取与每个所述药代动力学终点对应的数据训练xgboost算法,得到每个所述药代动力学终点对应的计算模型;
19.根据全部所述药代动力学终点对应的计算模型形成所述预测模型组。
20.根据本公开实施例的一种具体实现方式,所述根据接收到的优化指令将所述目标矢量输入预测模型组,得到所述优化指令对应的优化预测指标的步骤,包括:
21.分析所述优化指令中包含的药代动力学终点;
22.根据所述优化指令中包含的药代动力学终点从所述预测模型组选取对应的计算模型;
23.将所述目标矢量分别输入每个所述计算模型,得到每个所述药代动力学终点对应的预测指标,并形成所述优化预测指标。
24.根据本公开实施例的一种具体实现方式,所述根据所述优化预测指标和所述初始分子字符串对应的计算指标进行加权平均计算,得到所述初始分子字符串的得分的步骤之前,所述方法还包括:
25.对每个所述药代动力学终点和所述计算指标设置对应的权重;
26.设定每个所述药代动力学终点和所述计算指标对应的常用性质范围和预设性质范围,其中,所述常用性质范围大于所述预设性质范围。
27.根据本公开实施例的一种具体实现方式,所述根据所述优化预测指标和所述初始分子字符串对应的计算指标进行加权平均计算,得到所述初始分子字符串的得分的步骤,包括:
28.分别根据每个所述药代动力学终点的权重和预测指标计算预测值,以及,根据根据所述计算指标的值和权重计算所述预测值;
29.根据每个所述预测值所在的性质范围确定每个预测值对应的预测得分,并形成所述初始分子字符串的得分。
30.根据本公开实施例的一种具体实现方式,所述利用预设算法计算每个所述优化矢量对应的字符串,形成目标分子字符串集合的步骤,包括:
31.根据beam search算法和所述优化矢量预测每个字符,直到形成字符串;
32.根据全部所述优化矢量对应的字符串形成所述目标分子字符串集合。
33.本公开实施例中的基于机器翻译模型的先导化合物成药性优化方案,包括:利用预设数量的样本分子字符串训练翻译模型,其中,所述翻译模型包括编码器和解码器;根据机器学习算法建立多个药代动力学终点对应的计算模型,形成预测模型组;将初始分子字符串输入所述编码器,生成目标矢量;根据接收到的优化指令将所述目标矢量输入预测模型组,得到所述优化指令对应的优化预测指标;根据所述优化预测指标和所述初始分子字
符串对应的计算指标进行加权平均计算,得到所述初始分子字符串的得分;根据所述目标矢量和所述得分,利用优化算法迭代预设次数得到优化分数集合,其中,所述优化分数集合包括多个优化矢量和每个所述优化矢量对应的优化得分;将所述优化分数集合输入所述解码器,利用预设算法计算每个所述优化矢量对应的字符串,形成目标分子字符串集合。
34.本公开实施例的有益效果为:通过本公开的方案,对需要优化的每个药代动力学终点均建立一个计算模型,并分别对初始分子的各个指标进行独立优化并在加权平均计算后进行迭代优化,并将迭代结果整理输出为固定的目标分子字符串集合,提高了优化效率和适应性。
附图说明
35.为了更清楚地说明本公开实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
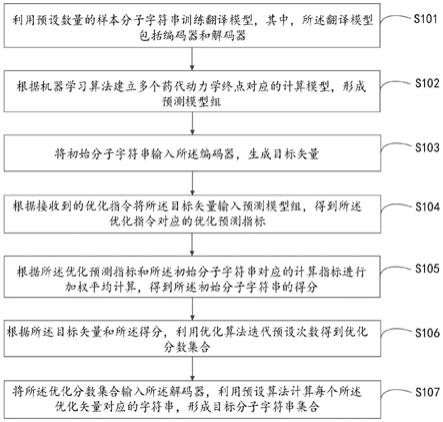
36.图1为本公开实施例提供的一种基于机器翻译模型的先导化合物成药性优化方法的流程示意图;
37.图2为本公开实施例提供的一种基于机器翻译模型的先导化合物成药性优化方法的部分流程示意图;
38.图3为本公开实施例提供的另一种基于机器翻译模型的先导化合物成药性优化方法的部分流程示意图;
39.图4为本公开实施例提供的一种基于机器翻译模型的先导化合物成药性优化方法的具体实施过程示意图。
具体实施方式
40.下面结合附图对本公开实施例进行详细描述。
41.以下通过特定的具体实例说明本公开的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本公开的其他优点与功效。显然,所描述的实施例仅仅是本公开一部分实施例,而不是全部的实施例。本公开还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本公开的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。基于本公开中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
42.需要说明的是,下文描述在所附权利要求书的范围内的实施例的各种方面。应显而易见,本文中所描述的方面可体现于广泛多种形式中,且本文中所描述的任何特定结构及/或功能仅为说明性的。基于本公开,所属领域的技术人员应了解,本文中所描述的一个方面可与任何其它方面独立地实施,且可以各种方式组合这些方面中的两者或两者以上。举例来说,可使用本文中所阐述的任何数目个方面来实施设备及/或实践方法。另外,可使用除了本文中所阐述的方面中的一或多者之外的其它结构及/或功能性实施此设备及/或实践此方法。
43.还需要说明的是,以下实施例中所提供的图示仅以示意方式说明本公开的基本构
想,图式中仅显示与本公开中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
44.另外,在以下描述中,提供具体细节是为了便于透彻理解实例。然而,所属领域的技术人员将理解,可在没有这些特定细节的情况下实践所述方面。
45.目前,药物研发的最大的挑战之一就是如何高效的进行先导化合物优化,这也是药物化学家们面临的一大难题。超过50%化合物因为没有合适的吸收、分布、代谢、排泄(admet)和安全性质从而在药物研发的过程中失败,而admet性质优化是一个难度极高的多目标优化任务,要求在提高分子的成药性同时保持分子的活性;另一方面,空间大、经验少、成本高、耗时长等因素也使得高效进行化合物药代动力学性质和安全性的优化成为一大难题。而现有的技术一般是通过计算生成新分子,接着利用虚拟筛选程序对所产生的新化合物进行筛选以获得符合候选化合物,然而计算量巨大,或者通过预测模型对分子整体进行预测,不能针对成药性特定指标进行优化,且优化后药物的成药性不高,优化效率和适应性较差。
46.本公开实施例提供一种基于机器翻译模型的先导化合物成药性优化方法,所述方法可以应用于计算机辅助药物设计场景的先导化合物成药性优化过程中。
47.参见图1,为本公开实施例提供的一种基于机器翻译模型的先导化合物成药性优化方法的流程示意图。如图1所示,所述方法主要包括以下步骤:
48.s101,利用预设数量的样本分子字符串训练翻译模型,其中,所述翻译模型包括编码器和解码器;
49.具体实施时,可以根据语言神经网络建立所述翻译模型,然后利用预设数量的样本分子字符串对所述翻译模型进行训练,提高了翻译的准确性和涉及化学空间的丰富性,以使得后续优化过程更精准。
50.s102,根据机器学习算法建立多个药代动力学终点对应的计算模型,形成预测模型组;
51.具体实施时,考虑到在优化过程中,是需要对分子的药代动力学(admet)性质进行具体改进,而一般影响成药性的药代动力学终点主要包括:logd7.4、logs、caco
‑
2、mdck细胞、血浆蛋白结合率(ppb)、ames毒性、心脏毒性(herg)、肝毒性和半数致死剂量(ld50)毒性共9个重要的admet终点。可以通过机器学习算法建立多个药代动力学终点对应的计算模型,形成预测模型组,可以根据9个重要的admet终点分别建立模型,也可以根据任意个admet终点分别建立模型,在此不进行列举。
52.s103,将初始分子字符串输入所述编码器,生成目标矢量;
53.具体实施时,可以将需要优化的先导化合物分子对应的smiles字符串作为所述初始分子字符串,然后将所述初始分子字符串输入所述编码器,生成所述目标矢量。
54.例如,为了避免循环神经网络(rnn)引发的梯度消失或梯度爆炸的问题,编码器和解码器都应用了3层堆积门循环单元(gru),每一层包含256、512和1024个单元。对于编码器模型,其最后一层为包含512个单元和双曲正切激活函数的完全连接层(信息瓶颈),并生成512维矢量作为所述目标矢量。通过信息瓶颈筛选后得到的512维矢量,象征smiles中最显著的统计特征。当然,所述编码器的具体设置以及生成的所述目标矢量的维度可以根据实
际需要进行设定。
55.s104,根据接收到的优化指令将所述目标矢量输入预测模型组,得到所述优化指令对应的优化预测指标;
56.具体实施时,所述优化指令可以为针对所述初始分子字符串中特定的药代动力学终点进行优化,例如,当所述优化指令为对所述初始分子字符串中的血浆蛋白结合率(ppb)、心脏毒性(herg)、肝毒性和半数致死剂量(ld50)进行优化时,则将所述目标矢量输入所述预测模型组中,由所述预测模型组中血浆蛋白结合率(ppb)、心脏毒性(herg)、肝毒性和半数致死剂量(ld50)对应的计算模型对所述目标矢量进行分析处理,得到所述优化指令对应的优化预测指标。
57.s105,根据所述优化预测指标和所述初始分子字符串对应的计算指标进行加权平均计算,得到所述初始分子字符串的得分;
58.所述初始分子字符串对应的计算指标可以根据所述初始分子字符串直接计算得到,在得到所述优化预测指标后,可以根据每个指标对成药性的影响进行所述加权平均计算,得到所述初始分子字符串的得分,以避免优化分子只关注性质的提升,而忽略重要结构信息,生成不期望的分子。
59.s106,根据所述目标矢量和所述得分,利用优化算法迭代预设次数得到优化分数集合,其中,所述优化分数集合包括多个优化矢量和每个所述优化矢量对应的优化得分;
60.具体实施时,为了进一步提高优化效率,在得到所述初始分子字符串的得分后,可以根据所述目标矢量和所述得分,利用优化算法迭代预设次数,得到多个优化矢量和每个所述优化矢量对应的优化得分,形成所述优化分数集合。
61.例如,利用粒子群优化算法(particle swarm optimization,简称pso)结合翻译模型计算所得的优化矢量和优化得分,从而实现高效的分子优化。pso是一种模拟群体智能,通过多个粒子在空间搜索中信息记录和比较,从而寻找最优点的随机优化方法。在此过程中,群中的每个粒子的信息由其位置x和速度v定义,其中评分f用于探索空间和指导优化。在本研究中,位置x为512维矢量值,评分f为优化分数。第i个粒子在迭代步骤k的运动受其自身历史最佳点和所有粒子的历史最佳点影响;每次迭代后,每个粒子将根据收集的信息及其状态更新其速度和位置,然后可以根据所述优化得分对所述优化分数集合内的优化矢量进行排序。
62.s107,将所述优化分数集合输入所述解码器,利用预设算法计算每个所述优化矢量对应的字符串,形成目标分子字符串集合。
63.具体实施时,在得到所述优化分数集合后,可以将所述优化分数集合输入所述解码器,由所述解码器对所述优化分数集合中的每个优化矢量进行解码,生成规范的字符串canonical smiles,形成所述目标分子字符串集合,所述目标分子字符串集合中包含多个根据所述优化指令进行优化的分子,以便后续的验证与应用。
64.本实施例提供的基于机器翻译模型的先导化合物成药性优化方法,通过对需要优化的每个药代动力学终点均建立一个计算模型,并分别对初始分子的各个指标进行独立优化并在加权平均计算后进行迭代优化,并将迭代结果整理输出为固定的目标分子字符串集合,提高了优化效率和适应性。
65.在上述实施例的基础上,步骤s101所述的,利用预设数量的样本分子字符串训练
翻译模型,包括:
66.分别将每个所述样本分子字符串输入所述编码器,并将所述编码器的输出结果输入所述解码器;
67.将所述解码器的每个输出结果与其对应的样本分子字符串的真实标签的损失,并执行梯度更新。
68.具体实施时,可以分别将每个所述样本分子字符串输入所述编码器,所述编码器生成每个所述样本分子字符串对应的512维矢量,然后将每个所述样本分子字符串对应的512维矢量输入所述解码器,然后将所述解码器的输出与真实标签进行损失计算,并执行梯度更新,以提高所述翻译模型的翻译精度。
69.在上述实施例的基础上,如图2所示,步骤s102所述的,根据机器学习算法建立多个药代动力学终点对应的计算模型,形成预测模型组的步骤,包括:
70.s201,从初始数据库内提取样本数据集;
71.例如,可以通过对chembl、epa和drugbank数据库检索和文献收集,得到admet数据集并对其进行数据预处理,筛除admet数据集的干扰数据和无效数据,形成所述样本数据集。
72.s202,从所述样本数据集中提取与每个所述药代动力学终点对应的数据训练xgboost算法,得到每个所述药代动力学终点对应的计算模型;
73.例如,可以针对logd7.4、logs、caco
‑
2、mdck细胞、血浆蛋白结合率(ppb)、ames毒性、心脏毒性(herg)、肝毒性和半数致死剂量(ld50)毒性共9个重要的admet终点对所述样本数据集中提取对应的数据,并结合所述xgboost算法对不同admet终点对应的数据进行学习,建立每个所述药代动力学终点对应的计算模型。当然,还可以采用其他的机器学习算法进行学习和建立模型。
74.s203,根据全部所述药代动力学终点对应的计算模型形成所述预测模型组。
75.在得到每个所述药代动力学终点对应的计算模型后,根据全部所述药代动力学终点对应的计算模型形成所述预测模型组。
76.进一步的,所述根据接收到的优化指令将所述目标矢量输入预测模型组,得到所述优化指令对应的优化预测指标的步骤,包括:
77.分析所述优化指令中包含的药代动力学终点;
78.根据所述优化指令中包含的药代动力学终点从所述预测模型组选取对应的计算模型;
79.将所述目标矢量分别输入每个所述计算模型,得到每个所述药代动力学终点对应的预测指标,并形成所述优化预测指标。
80.具体实施时,当所述优化指令中包含的药代动力学终点为对所述初始分子字符串中的血浆蛋白结合率(ppb)、心脏毒性(herg)、肝毒性和半数致死剂量(ld50)进行优化时,则将所述目标矢量输入所述预测模型组中,由所述预测模型组中血浆蛋白结合率(ppb)、心脏毒性(herg)、肝毒性和半数致死剂量(ld50)对应的计算模型,然后将将所述目标矢量分别输入每个所述计算模型,得到每个所述药代动力学终点对应的预测指标,并形成所述优化预测指标。
81.可选的,所述根据所述优化预测指标和所述初始分子字符串对应的计算指标进行
加权平均计算,得到所述初始分子字符串的得分的步骤之前,所述方法还包括:
82.对每个所述药代动力学终点和所述计算指标设置对应的权重;
83.设定每个所述药代动力学终点和所述计算指标对应的常用性质范围和预设性质范围,其中,所述常用性质范围大于所述预设性质范围。
84.具体实施时,考虑到需要保证实现多目标优化任务且量化优化分子期望值,可以对每个所述药代动力学终点和所述计算指标设置对应的权重,以及,设定每个所述药代动力学终点和所述计算指标对应的常用性质范围和预设性质范围,从而保证对先导化合物成药性的优化,生成期望的分子。
85.进一步的,所述根据所述优化预测指标和所述初始分子字符串对应的计算指标进行加权平均计算,得到所述初始分子字符串的得分的步骤,包括:
86.分别根据每个所述药代动力学终点的权重和预测指标计算预测值,以及,根据根据所述计算指标的值和权重计算所述预测值;
87.根据每个所述预测值所在的性质范围确定每个预测值对应的预测得分,并形成所述初始分子字符串的得分。
88.例如,可以分别根据每个所述药代动力学终点的权重和预测指标计算预测值,以及,根据根据所述计算指标的值和权重计算所述预测值,然后判断所述预测值所在的范围,若所述预测值在所述预设性质范围内,则所述预测值对应的性质得分值为1,若所述预测值在所述预设性质范围外但仍在所述常用性质范围内,根据与目标范围距离远近对应为(0,1)的得分值,若所述预测值超出常用性质范围,则所述预测值对应的性质得分为0。
89.在上述实施例的基础上,如图3所示,步骤s107所述的,利用预设算法计算每个所述优化矢量对应的字符串,形成目标分子字符串集合,包括:
90.s301,根据beam search算法和所述优化矢量预测每个字符,直到形成字符串;
91.具体实施时,beam search算法是一种启发式搜索算法,通过在有限的集合中扩展最有希望的节点来探索单词的最佳组合,以此迭代预测每个字符,可以将所述优化分数集合中的每个所述优化矢量代入所述beam search算法,迭代预测每个所述优化矢量中的每个字符,直到形成完整的字符串序列。当然,也可以选用其他的算法进行解码。
92.s302,根据全部所述优化矢量对应的字符串形成所述目标分子字符串集合。
93.具体实施时,进行相同步骤直到每个所述优化矢量均生成对应的字符串,然后将全部所述优化矢量对应的字符串形成所述目标分子字符串集合。上述本公开实施例提供的机器翻译模型的先导化合物成药性优化方法的具体优化流程如图4所示,最终生成所述目标分子字符串集合。
94.以上所述,仅为本公开的具体实施方式,但本公开的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本公开揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本公开的保护范围之内。因此,本公开的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。