一种基于互注意力transformer的医学影像三维重建方法
技术领域
1.本发明属于计算机技术领域,涉及医疗智能辅助诊断中超声或ct影像三维重建,是一种借助于自然图像的成像规律,利用深度学习机制进行学习,采样人工智能的迁移学习策略及互注意力的transformer编码技术,建立有效的网络结构,能够实现对超声或ct影像三维几何信息的重建。
背景技术:
2.近年来,人工智能技术快速发展,智能医疗辅助诊断中,3d可视化技术对于现代医学临床中的诊断可以起到辅助的作用。同时,由于医学影像少纹理多噪声的客观事实,并且特别是对于超声摄像机的参数恢复存在一定的难度,导致目前超声或ct影像的三维重建技术的研究存在一定难点,这为医学影像的三维重建技术的研究带来挑战性。
3.同时,近年来出现的人工智能先进技术,使得超声或ct影像的三维重建的问题,可以通过三维重建技术,建立有效的深度学习的网络编码模型来解决,transformer模型由于具有强大的特征感知能力,目前在医学影像分析中被广泛应用。
技术实现要素:
4.本发明的目的是提供一种基于互注意力transformer的医学影像三维重建方法,该方法采用多尺度的transformer编码结构,设计多分支网络结构,另外,结合计算机视觉中几何成像的特点进行设计,采用互注意力机制,充分利用不同视图之间的互相作用,提高了三维重建的准确度,该发明可以得到较为精细的医学目标三维结构,具有较高的实用价值。
5.实现本发明目的的具体技术方案是:
6.一种基于互注意力transformer的医学影像三维重建方法,该方法输入一个超声或者ct影像序列,其影像分辨率为m
×
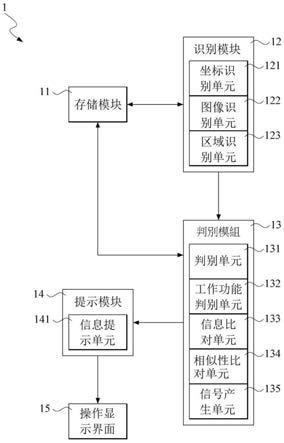
n,100≤m≤2000,100≤n≤2000,三维重建的过程具体包括以下步骤:
7.步骤1:构建数据集
8.(a)构建自然图像数据集
9.选取一个自然图像网站,要求具有图像序列及对应的摄像机内部参数,从所述自然图像网站下载a个图像序列及序列对应的内部参数,1≤a≤20,对于每个图像序列,每相邻3帧图像记为图像b、图像c和图像d,将图像b和图像d按照颜色通道进行拼接,得到图像τ,由图像c与图像τ构成一个数据元素,图像c为自然目标图像,图像c的采样视点作为目标视点,图像b、图像c和图像d的内部参数均为e
t
(t=1,2,3,4),其中e1为水平焦距,e2为垂直焦距,e3及e4是主点坐标的两个分量;如果同一图像序列中最后剩余图像不足3帧,则舍弃;利用所有序列构建自然图像数据集,所构建的自然图像数据集中有f个元素,而且3000≤f≤20000;
10.(b)构建超声影像数据集
11.采样g个超声影像序列,其中1≤g≤20,对于每个序列,每相邻3帧影像记为影像i、影像j和影像k,将影像i和影像k按照颜色通道进行拼接得到影像π,由影像j与影像π构成一个数据元素,影像j为超声目标影像,影像j的采样视点作为目标视点,如果同一影像序列中最后剩余影像不足3帧,则舍弃,利用所有序列构建超声影像数据集,所构建的超声影像数据集中有f个元素,而且1000≤f≤20000;
12.(c)构建ct影像数据集
13.采样h个ct影像序列,其中1≤h≤20,对于每个序列,每相邻3帧记为影像l、影像m和影像n,将影像l和影像n按照颜色通道进行拼接得到影像σ,由影像m与影像σ构成一个数据元素,影像m为ct目标影像,影像m的采样视点作为目标视点,如果同一影像序列中最后剩余影像不足3帧,则舍弃,利用所有序列构建ct影像数据集,所构建的ct影像数据集中有ξ个元素,而且1000≤ξ≤20000;
14.步骤2:构建神经网络
15.神经网络输入的图像或影像的分辨率均为p
×
o,p为宽度,o为高度,以像素为单位,100≤o≤2000,100≤p≤2000;
16.(1)深度信息编码网络
17.张量h作为输入,尺度为α
×
o
×
p
×
3,张量i作为输出,尺度为α
×
o
×
p
×
1,α为批次数量;
18.深度信息编码网络由编码器和解码器组成,对于张量h,依次经过编码和解码处理后,获得输出张量i;
19.编码器由5个单元组成,第一个单元为卷积单元,第2至第5个单元均由残差模块组成,在第一个单元中,有64个卷积核组成,这些卷积核的形状均为7
×
7,卷积的水平方向及垂直方向的步长均为2,卷积之后进行一次最大池化处理,第2至第5个单元分别包括3,4,6,3个残差模块,每个残差模块进行3次卷积,卷积核的形状均为3
×
3,卷积核的个数分别是64,128,256,512;
20.解码器由6个解码单元组成,每个解码单元均包括反卷积和卷积处理,反卷积和卷积处理的卷积核形状、个数相同,第1至第6解码单元中卷积核的形状均为3
×
3,卷积核的个数分别对应是512,256,128,64,32,16,编码器与解码器的网络层之间进行跨层连接,跨层连接的对应关系为:1与4、2与3、3与2、4与1;
21.(2)互注意力transformer学习网络
22.互注意力transformer学习网络由一个主干网络和4个网络分支构成,4个网络分支分别用于预测张量l、张量o、张量d和张量b;
23.张量j和张量c作为输入,尺度分别为α
×
o
×
p
×
3和α
×
o
×
p
×
6,,输出为张量l、张量o、张量d和张量b,张量l尺度为α
×2×
6,张量o尺度为α
×4×
1,张量d的尺度为α
×
3,张量b尺度为α
×
o
×
p
×
4,α为批次数量;
24.主干网络设计为3个阶段的跨视图编码:
25.1)第1个阶段的跨视图编码包括第1个阶段的嵌入编码和第1个阶段注意力编码
26.第1个阶段的嵌入编码,分别将张量j、张量c的最后一个维度的前3个特征分量、张量c最后一个维度的后3个特征分量进行卷积运算,卷积核尺度均为7
×
7,特征通道数为24,序列化处理将编码特征从图像特征空域形状变换为序列结构,层归一化处理,分别得到第1
个阶段嵌入编码1、第1个阶段嵌入编码2和第1个阶段嵌入编码3;
27.第1个阶段注意力编码,将第1个阶段嵌入编码1与第1个阶段嵌入编码2按照最后一个维度进行串接,得到注意力编码输入特征1;将第1个阶段嵌入编码1与第1个阶段嵌入编码3按照最后一个维度进行串接,得到第1个阶段注意力编码输入特征2;将第1个阶段嵌入编码2与第1个阶段嵌入编码1按照最后一个维度进行串接,得到第1个阶段注意力编码输入特征3;将第1个阶段嵌入编码3与第1个阶段嵌入编码1按照最后一个维度进行串接,得到第1个阶段注意力编码输入特征4;将所述第1个阶段注意力编码的4个输入特征,进行注意力编码:将第1个阶段每个注意力编码输入特征按照最后一个维度将前一半通道特征作为目标编码特征,将后一半通道特征作为源编码特征,再将目标编码特征和源编码特征分别进行可分离的卷积运算,其中卷积核尺度均为3
×
3,特征通道数为24,水平方向及垂直方向的步长均为1,将目标编码特征的处理结果作为注意力学习的查询关键词k编码向量和数值v编码向量,将源编码特征的处理结果作为注意力学习的查询q编码向量,然后,利用多头注意力方法计算每个注意力编码输入特征的注意力权重矩阵,头的个数为1,特征通道数为24,最后,将所述每个注意力权重矩阵与每个注意力编码输入特征的目标编码特征相加,得到第1个阶段4个跨视图编码特征,利用所述4个跨视图编码特征的第1个和第2个跨视图编码特征的平均特征作为第1个阶段跨视图跨层特征;将所述第1个阶段跨视图跨层特征、第1个阶段第3个跨视图编码特征、第1个阶段第4个跨视图编码特征作为第1个阶段跨视图编码结果;将所述第1个阶段跨视图编码结果作为第2个阶段跨视图编码输入,将所述第1个阶段跨视图编码结果按照最后一个维度进行串接得到第1个阶段串接编码结果;
28.2)第2个阶段的跨视图编码包括第2个阶段的嵌入编码和第2个阶段注意力编码
29.第2个阶段的嵌入编码,将第1个阶段跨视图编码结果中的每个特征进行嵌入编码,卷积运算的特征通道数为64,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,序列化处理将编码特征从图像特征空域形状变换为序列结构,特征的层归一化处理,得到第2个阶段嵌入编码1、第2个阶段嵌入编码2和第2个阶段嵌入编码3;
30.第2个阶段注意力编码,将第2个阶段嵌入编码1与第2个阶段嵌入编码2按照最后一个维度进行串接,得到第2阶注意力编码输入特征1;将第2个阶段嵌入编码1与第2个阶段嵌入编码3按照最后一个维度进行串接,得到第2个阶段注意力编码输入特征2;将第2个阶段嵌入编码2与第2个阶段嵌入编码1按照最后一个维度进行串接,得到第2个阶段注意力编码输入特征3;将第2个阶段嵌入编码3与第2个阶段嵌入编码1按照最后一个维度进行串接,得到第2个阶段注意力编码输入特征4,将所述每个输入特征,按照最后一个维度,将前一半通道特征作为目标编码特征,将后一半通道特征作为源编码特征,将目标编码特征和源编码特征分别进行可分离的卷积运算,卷积核尺度均为3
×
3,特征通道数为64,水平方向及垂直方向的步长均为2,将目标编码特征的处理结果作为注意力学习的查询关键词k编码向量和数值v编码向量,将源编码特征的处理结果作为注意力学习的查询q编码向量,然后,利用多头注意力方法计算每个注意力编码输入特征的的注意力权重矩阵,头的个数为3,特征通道数为64,最后,将所述每个注意力编码输入特征的注意力权重矩阵与每个注意力编码输入特征的目标编码特征相加,得到第2个阶段的4个跨视图编码特征,利用所述跨视图编码特征的第1个和第2个特征的平均特征作为第2个阶段跨视图跨层特征;将所述第2个阶段跨视图跨层特征、第2个阶段第3个跨视图编码特征、第2个阶段第4个跨视图编码特征作为第2
个阶段跨视图编码结果;将所述第2个阶段跨视图编码结果作为第3个阶段跨视图编码输入,将所述第2个阶段跨视图编码结果按照最后一个维度进行串接得到第2个阶段串接编码结果;
31.3)第3个阶段的跨视图编码包括第3个阶段的嵌入编码和第3个阶段注意力编码
32.第3个阶段的嵌入编码,将第2个阶段跨视图编码结果中的每个特征进行嵌入编码处理,卷积运算,卷积核尺度均为3
×
3,特征通道数为128,水平方向及垂直方向的步长均为2,序列化处理将编码特征从图像特征空域形状变换为序列结构,特征的层归一化处理,得到第3个阶段嵌入编码1、第3个阶段嵌入编码2和第3个阶段嵌入编码3;
33.第3个阶段注意力编码,将第3个阶段嵌入编码1与第3个阶段嵌入编码2按照最后一个维度进行串接,得到第3阶注意力编码输入特征1;将第3个阶段嵌入编码1与第3个阶段嵌入编码3按最后一个维度进行串接,得到第3个阶段注意力编码输入特征2;将第3个阶段嵌入编码2与第3个阶段嵌入编码1按照最后一个维度进行串接,得到第3个阶段注意力编码输入特征3;将第3个阶段嵌入编码3与第3个阶段嵌入编码1按照最后一个维度进行串接,得到第3个阶段注意力编码输入特征4;将所述每个输入特征,按照最后一个维度,将前一半通道特征作为目标编码特征,将后一半通道特征作为源编码特征,将目标编码特征和源编码特征分别进行可分离的卷积运算,其中卷积核尺度均为3
×
3,特征通道数为128,水平方向及垂直方向的步长均为2,将目标编码特征的处理结果作为注意力学习的查询关键词k编码向量和数值v编码向量,将源编码特征的处理结果作为注意力学习的查询q编码向量,然后,利用多头注意力方法计算每个注意力编码输入特征的注意力权重矩阵,头的个数为6,特征通道数为128,最后,将第3个阶段每个注意力编码输入特征的权重矩阵与每个注意力编码输入特征的目标编码特征相加,得到第3个阶段的4个跨视图编码特征,利用所述跨视图编码特征的第1个和第2个特征的平均特征作为第3个阶段跨视图跨层特征;将所述第3个阶段跨视图跨层特征、第3个阶段第3个跨视图编码特征、第3个阶段第4个跨视图编码特征作为第3个阶段跨视图编码结果;将所述第3个阶段跨视图编码结果按照最后一个维度进行串接得到第3个阶段串接编码结果;
34.对于第1个网络分支,将第1个阶段串接编码结果依次进行2个单元处理:在第1个单元处理中,卷积运算的特征通道数为16,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理;在第2个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;将所得到的特征依次进行2个单元处理:在第1个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理;在第2个单元处理中,卷积运算的特征通道数为64,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;然后,将所得到的特征与第3个阶段串接编码结果相串接,进行以下3个单元处理:在第1个单元处理中,卷积运算的特征通道数为64,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;在第2个单元处理中,卷积运算的特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;在第3个单元处理中,卷积运算的特征通道数为12,卷积核尺度均为1
×
1,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理;将所得的12通道的特征结果按照2
×
6的形式进行预测,得到张量l的
结果;
35.对于第2个网络分支,将第1个阶段串接编码结果依次进行2个单元处理:在第1个单元处理中,卷积运算的特征通道数为16,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理;在第2个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;然后将所得到的特征与第2个阶段串接编码结果相串接,进行以下2个单元处理:在第1个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理;在第2个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;将所得到的特征与第3个阶段串接编码结果相串接,进行2个单元处理:在第1个单元处理中,卷积运算的特征通道数为64,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;在第2个单元处理中,卷积运算的特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;在第3个单元处理中,卷积运算的特征通道数为4,卷积核尺度均为1
×
1,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理;将所得的4通道特征作为张量o的结果;
36.对于第3个网络分支,将第3个阶段串接编码结果进行以下4个单元的处理:在第1个单元处理中,卷积运算的特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理;在第2个单元处理中,卷积运算的特征通道数为512,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理;在第3个单元处理中,卷积运算的特征通道数为1024,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,在第4个单元处理中,卷积运算的特征通道数为3,卷积核尺度均为1
×
1,水平方向及垂直方向的步长均为1,将所得到的特征作为张量d的结果;
37.对于第4个网络分支,将第1个阶段跨视图跨层特征进行一次反卷积运算、特征激活、批归一化处理,反卷积运算中,卷积的特征通道数为16,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2;将得到的结果记为解码器跨层特征1,再将第1个阶段跨视图跨层特征进行以下2个单元的处理:第1个单元处理时,卷积运算特征通道数为32,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,并将处理特征记为解码器跨层特征2;第2个单元处理,卷积运算,特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将所得到的特征与第2个阶段跨视图跨层特征进行串接,将所述串接结果进行以下2个单元的处理:第1个单元处理时,卷积的特征通道数为64,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,并将处理特征记为解码器跨层特征3;第2个单元处理时,卷积的特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,然后将所得到的特征与第3个阶段跨视图跨层特征进行串接,再进行以下3个单元处理,第1个单元处理时,卷积的特征通道数为128,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,并将处理特征记为解码器跨层特征4;第2个单元处理时,卷积的特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,将并将处理特征记为解码器跨层特征5;第3个单元处理时,卷积的特征通道数为512个,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,处理后得到第4个网络分支编码特征;
38.进一步进行解码,将所述第4个网络分支编码特征进行1次反卷积运算:卷积的特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,并将得到的结果与解码器跨层特征5相串接,进行一次卷积运算:特征通道数为512,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的结果进行反卷积运算:特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将所得到的结果与解码器跨层特征4相串接,进行一次卷积运算:特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的结果进行一次进行反卷积运算:特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将所得到的结果与解码器跨层特征3相串接,进行一次卷积运算:特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的特征作为张量b的第4个尺度结果,同时,将所得到的特征进行1次反卷积运算,反卷积的特征通道数为64,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将所得到的特征与解码器跨层特征2相串接,进行一次卷积运算:特征通道数为64,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的特征作为张量b的第3个尺度结果,同时,将所得到的特征进行1次反卷积运算:反卷积的特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,再将所得到的特征与解码器跨层特征1相串接,然后进行一次卷积运算:特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的特征作为张量b的第2个尺度结果,同时,将所得到的特征进行1次反卷积运算:特征通道数为16,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将所得到的特征与第3个尺度特征的上采样结果进行相串接,然后进行一次卷积运算:特征通道数为16,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的特征作为张量b的第1个尺度结果,利用所述张量b的4个尺度结果,得到第4个网络分支的输出;
39.步骤3:神经网络的训练
40.分别将自然图像数据集、超声影像数据集和ct影像数据集中样本按照9:1划分为训练集和测试集,训练集中数据用于训练,测试集数据用于测试,在训练时,分别从对应的数据集中获取训练数据,统一缩放到分辨率p
×
o,输入到对应网络中,迭代优化,通过不断修改网络模型参数,使得每批次的损失达到最小;
41.在训练过程中,各损失的计算方法:
42.内部参数监督合成损失:在自然图像的网络模型训练中,将深度信息编码网络输出的张量i作为深度,将互注意力transformer学习网络输出的张量l与训练数据的内部参数标签e
t
(t=1,2,3,4)分别作为位姿参数和摄像机内部参数,根据计算机视觉原理算法,利用图像b和图像d分别合成图像c视点处的两个图像,利用图像c分别与所述的两个合成图像,按照逐像素、逐颜色通道强度差之和计算得到;
43.无监督合成损失:在超声或者ct影像的网络模型训练中,将深度信息编码网络的输出张量i作为深度,将互注意力transformer学习网络的第1个网络分支的输出张量l和互注意力transformer学习网络的第2个网络分支的输出张量o分别作为位姿参数和摄像机内
部参数,根据计算机视觉算法,利用目标影像的两相邻影像分别合成目标影像视点处的影像,利用目标影像分别与所述目标影像视点处的影像,按照逐像素、逐颜色通道强度差之和计算得到;
44.内部参数误差损失:在自然图像的网络模型训练中,利用互注意力transformer学习网络的第2个网络分支的输出张量o与训练数据的内部参数标签e
t
(t=1,2,3,4)按照各分量差的绝对值之和计算得到;
45.空间结构误差损失:在超声或者ct影像的网络模型训练中,将深度信息编码网络的输出张量i作为深度,将互注意力transformer学习网络的第1个网络分支的输出张量l和互注意力transformer学习网络的第2个网络分支的输出张量o分别作为位姿参数和摄像机内部参数,根据计算机视觉算法,分别利用目标视点处影像的两个相邻影像重建目标视点处影像的三维坐标,采用ransac算法对重建点进行空间结构拟合,空间结构误差损失利用拟合得到的法向量与互注意力transformer学习网络的第3个网络分支的输出张量d,利用余弦距离计算得到;
46.变换合成损失:在超声或者ct影像的网络参数训练中,将深度信息编码网络的输出张量i作为深度,将互注意力transformer学习网络的第1个网络分支的输出张量l和互注意力transformer学习网络的第2个网络分支的输出张量o分别作为位姿参数和摄像机内部参数,利用目标影像的两个相邻影像构建目标影像视点处的两个合成影像,对于所述合成影像中的每个影像,在合成过程得到每个像素位置后,将第4个网络分支的输出张量b作为合成影像空域变形的位移量,构成合成结果影像,然后利用目标视点处的图像或者影像与所述合成目标视点处的结果,按照逐像素、逐颜色通道强度差之和计算得到;
47.具体训练步骤:
48.(1)在自然图像数据集上,分别对深度信息编码网络及互注意力transformer学习网络主干网络及第1个网络分支,训练80000次
49.每次从自然图像数据集中取出训练数据,统一缩放到分辨率p
×
o,将图像c输入深度信息编码网络,将图像c及图像τ输入互注意力transformer学习网络,对深度信息编码网络及视觉互注意力transformer学习网络主干网络及第1个网络分支,训练80000次,每批次的训练损失由内部参数监督合成损失计算得到;
50.(2)在自然图像数据集上,对互注意力transformer学习网络第2个网络分支,训练50000次
51.每次从自然图像数据集中取出训练数据,统一缩放到分辨率p
×
o,将图像c输入深度信息编码网络,将图像c及图像τ输入互注意力transformer学习网络,对第2个网络分支进行训练,每批次的训练损失由无监督合成损失和内部参数误差损失之和计算得到;
52.(3)在超声影像数据集上,对深度信息编码网络、互注意力transformer学习网络的主干网络及网络分支1
‑
4训练80000次,得到模型参数ρ
53.每次从超声影像数据集上取出超声训练数据,统一缩放到分辨率p
×
o,将影像j输入深度信息编码网络,将影像j及影像π输入到互注意力transformer学习网络,对深度信息编码网络、互注意力transformer学习网络的主干网络及网络分支1
‑
4进行训练,每批次的训练损失由变换合成损失、空间结构误差损失之和计算得到;
54.(4)在ct影像数据集上,对于互注意力transformer学习网络训练60000次,得到模
型参数ρ
′
55.每次从ct影像数据集中取出ct影像训练数据,统一缩放到分辨率p
×
o,将影像m及影像σ输入到互注意力transformer学习网络,将深度信息编码网络输出结果作为深度,主干网络及第1及第2个网络分支的输出结果分别作为位姿参数和摄像机内部参数,将互注意力transformer学习网络的第4个网络分支的输出张量b作为空域变形的位移量,分别根据影像l和影像n合成影像m视点处的两张影像,对所述网络进行训练,不断修改网络的参数,迭代优化,针对每批次每幅影像损失达到最小,迭代后得到最优的网络模型参数ρ
′
,使得每批次的每幅影像的损失达到最小,网络优化的损失计算时,除了变换合成损失、空间结构误差损失,还附加摄像机平移运动的损失;
56.步骤4:对超声或者ct影像三维重建
57.利用自采样的一个超声或者ct序列影像,同时进行以下3个处理实现三维重建:
58.(1)对序列影像中任一目标影像,按照如下方法计算摄像机坐标系下的三维坐标:缩放到分辨率p
×
o,对于超声序列影像,将影像j输入深度信息编码网络,将影像j及影像π输入到互注意力transformer学习网络,对于ct序列影像,将影像m输入深度信息编码网络,将,影像m及影像σ输入到输入互注意力transformer学习网络,分别利用模型参数ρ和模型参数ρ
′
进行预测,从深度信息编码网络得到每一帧目标影像的深度,将互注意力transformer学习网络的第1个网络分支的输出张量l和第2个网络分支的输出张量o分别作为摄像机位姿参数及摄像机内部参数,根据目标影像的深度信息及摄像机内部参数,依据计算机视觉的原理,计算目标影像的摄像机坐标系下的三维坐标;
59.(2)序列影像三维重建过程中,建立关键帧序列:将序列影像第一帧作为关键帧序列的第一帧,并作为当前关键帧,当前关键帧之后的帧作为目标帧,按照目标帧顺序依次动态选取新的关键帧:首先,用单位矩阵初始化目标帧相对于当前关键帧的位姿参数矩阵,针对任一目标帧,将所述位姿参数矩阵累乘目标帧摄像机位姿参数,并利用累乘结果,结合所述目标帧的内部参数及深度信息,合成所述目标帧视点处的影像,利用所述合成影像与所述目标帧之间逐像素逐颜色通道强度差之和的大小计算误差λ,再根据所述目标帧的相邻帧,利用摄像机位姿参数和内部参数,合成所述目标帧视点处的影像,利用所述合成的影像与所述目标帧之间逐像素逐颜色通道强度差之和的大小计算误差γ,进一步利用公式(1)计算合成误差比z:
[0060][0061]
满足z大于阈值η,1<η<2,将所述目标帧作为新的关键帧,并将所述目标帧相对于当前关键帧的位姿参数矩阵作为新的关键帧的位姿参数,同时将所述目标帧更新为当前关键帧;以此迭代,完成关键帧序列建立;
[0062]
(3)将序列影像第一帧的视点作为世界坐标系的原点,对任一目标影像,将其分辨率缩放到m
×
n,根据网络输出得到的摄像机内部参数及深度信息,计算得到摄像机坐标系下的三维坐标,根据网络输出的摄像机位姿参数,并结合关键帧序列中每一关键帧的位姿参数以及目标帧相对于当前关键帧的位姿参数矩阵,计算得到所述目标帧的每个像素的世界坐标系中的三维坐标。
[0063]
本发明的有益效果:
[0064]
本发明设计了一种基于互注意力的transformer网络模型,采用不同视图之间互注意力机制进行学习,使得在医学影像的三维重建中充分发挥深度学习的智能感知能力,能够从二维的超声或者ct影像自动获取三维几何信息,利用本发明可以对医学临床诊断目标进行可视化显示,可以为人工智能的医疗辅助诊断提供有效的3d重建解决方案,提高人工智能辅助医学诊断的效率。
附图说明
[0065]
图1为本发明超声影像的三维重建结果图;
[0066]
图2为本发明ct影像的三维重建结果图。
具体实施方式
[0067]
下面结合附图及实施例对本发明进一步说明。
[0068]
实施例
[0069]
本实施例在pc机上windows10 64位操作系统下进行实施,其硬件配置是cpu i7
‑
9700f,内存16g,gpu nvidia geforce gtx 2070 8g;深度学习库采用tensorflow1.14;编程采用python语言3.7版本。
[0070]
一种基于互注意力transformer的医学影像三维重建方法,该方法输入一个超声或者ct影像序列,分辨率为m
×
n,对于超声影像,m取450,n取300,对于ct影像,m和n均取512,三维重建的过程具体包括以下步骤:
[0071]
步骤1:构建数据集
[0072]
(a)构建自然图像数据集
[0073]
选取一个自然图像网站,要求具有图像序列及对应的摄像机内部参数,从该网站下载19个图像序列及序列对应的内部参数,对于每个图像序列,每相邻3帧图像记为图像b、图像c和图像d,将图像b和图像d按照颜色通道进行拼接,得到图像τ,由图像c与图像τ构成一个数据元素,图像c为自然目标图像,图像c的采样视点作为目标视点,图像b、图像c和图像d的内部参数均为e
t
(t=1,2,3,4),其中e1为水平焦距,e2为垂直焦距,e3及e4是主点坐标的两个分量;如果同一图像序列中最后剩余图像不足3帧,则舍弃;利用所有序列构建自然图像数据集,其数据集有3600个元素;
[0074]
(b)构建超声影像数据集
[0075]
采样10个超声影像序列,对于每个序列,每相邻3帧影像记为影像i、影像j和影像k,将影像i和影像k按照颜色通道进行拼接得到影像π,由影像j与影像π构成一个数据元素,影像j为超声目标影像,影像j的采样视点作为目标视点,如果同一影像序列中最后剩余影像不足3帧,则舍弃,利用所有序列构建超声影像数据集,其数据集有1600个元素;
[0076]
(c)构建ct影像数据集
[0077]
采样1个ct影像序列,对于所述序列,每相邻3帧记为影像l、影像m和影像n,将影像l和影像n按照颜色通道进行拼接得到影像σ,由影像m与影像σ构成一个数据元素,影像m为ct目标影像,影像m的采样视点作为目标视点,如果同一影像序列中最后剩余影像不足3帧,则舍弃,利用所有序列构建ct影像数据集,其数据集有2000个元素;
[0078]
步骤2:构建神经网络
[0079]
神经网络处理的图像或影像的分辨率均为416
×
128,416为宽度,128为高度,以像素为单位;
[0080]
(1)深度信息编码网络的结构
[0081]
张量h作为输入,尺度为4
×
128
×
416
×
3,张量i作为输出,尺度为4
×
128
×
416
×
1;
[0082]
深度信息编码网络由编码器和解码器组成,对于张量h,依次经过编码和解码处理后,获得输出张量i;
[0083]
编码器由5个单元组成,第一个单元为卷积单元,第2至第5个单元均由残差模块组成,在第一个单元中,有64个卷积核组成,这些卷积核的形状均为7
×
7,卷积的水平方向及垂直方向的步长均为2,卷积之后进行一次最大池化处理,第2至第5个单元分别包括3,4,6,3个残差模块,每个残差模块进行3次卷积,卷积核的形状均为3
×
3,卷积核的个数分别是64,128,256,512;
[0084]
解码器由6个解码单元组成,每个解码单元均包括反卷积和卷积处理,反卷积和卷积处理的卷积核形状、个数相同,第1至第6解码单元中卷积核的形状均为3
×
3,卷积核的个数分别对应是512,256,128,64,32,16,编码器与解码器的网络层之间进行跨层连接,跨层连接的对应关系为:1与4、2与3、3与2、4与1;
[0085]
(2)互注意力transformer学习网络
[0086]
互注意力transformer学习网络由一个主干网络和4个网络分支构成,4个网络分支分别用于预测张量l、张量o、张量d和张量b;
[0087]
张量j和张量c作为输入,尺度分别为4
×
128
×
416
×
3和4
×
128
×
416
×
6,输出为张量l、张量o、张量d和张量b,尺度分别为:张量l尺度为4
×2×
6,张量o尺度为4
×4×
1,张量d的尺度为4
×
3,张量b尺度为4
×
128
×
416
×
4;
[0088]
主干网络设计为3个阶段的跨视图编码:
[0089]
1)第1个阶段的跨视图编码包括第1个阶段的嵌入编码和第1个阶段注意力编码
[0090]
第1个阶段的嵌入编码,分别将张量j、张量c的最后一个维度的前3个特征分量、张量c最后一个维度的后3个特征分量进行卷积运算卷积核尺度均为7
×
7,序列化处理将编码特征从图像特征空域形状变换为序列结构,层归一化处理,分别得到第1个阶段嵌入编码1、第1个阶段嵌入编码2和第1个阶段嵌入编码3;
[0091]
第1个阶段注意力编码,将第1个阶段嵌入编码1与第1个阶段嵌入编码2按照最后一个维度进行串接,得到注意力编码输入特征1,将第1个阶段嵌入编码1与第1个阶段嵌入编码3按照最后一个维度进行串接,得到第1个阶段注意力编码输入特征2,将第1个阶段嵌入编码2与第1个阶段嵌入编码1按照最后一个维度进行串接,得到第1个阶段注意力编码输入特征3,将第1个阶段嵌入编码3与第1个阶段嵌入编码1按照最后一个维度进行串接,得到第1个阶段注意力编码输入特征4,将所述第1个阶段注意力编码的4个输入特征,分别进行注意力编码处理:先利用多头自注意力方法计算第1个阶段注意力编码输入特征的注意力权重矩阵,具体地,将第1个阶段每个注意力编码输入特征按照最后一个维度将前一半通道特征作为目标编码特征,将后一半通道特征作为源编码特征,再将前一半通道特征和后一半通道特征分别进行可分离的卷积运算,其中卷积核尺度均为3
×
3,特征通道数为24,水平
方向及垂直方向的步长均为1,将目标编码特征的处理结果作为注意力学习的查询关键词k编码向量和数值v编码向量,将源编码特征的处理结果作为注意力学习的查询q编码向量,然后,利用多头注意力方法计算注意力权重矩阵,头的个数为1,特征通道数为24,最后,将第1个阶段所述特征的注意力权重矩阵与所述目标编码特征相加得到第1个阶段注意力编码,由第1个阶段4个注意力编码输入特征进行注意力编码处理后得到第1个阶段4个跨视图编码特征,利用所述跨视图编码特征的第1个和第2个特征的平均特征作为第1个阶段跨视图跨层特征,将所述第1个阶段跨视图跨层特征、第1个阶段第3个跨视图编码特征、第1个阶段第4个跨视图编码特征作为第1个阶段跨视图编码结果,将所述第1个阶段跨视图编码结果作为第2个阶段跨视图编码输入,将所述第1个阶段跨视图编码结果按照最后一个维度进行串接得到第1个阶段串接编码结果;
[0092]
2)第2个阶段的跨视图编码包括第2个阶段的嵌入编码和第2个阶段注意力编码
[0093]
第2个阶段的嵌入编码,将第1个阶段跨视图编码结果中的每个特征进行嵌入编码:卷积运算的特征通道数为64,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,序列化处理将编码特征从图像特征空域形状变换为序列结构,特征的层归一化处理,得到第2个阶段嵌入编码1、第2个阶段嵌入编码2和第2个阶段嵌入编码3;
[0094]
第2个阶段注意力编码,将第2个阶段嵌入编码1与第2个阶段嵌入编码2按照最后一个维度进行串接,得到第2阶注意力编码输入特征1,将第2个阶段嵌入编码1与第2个阶段嵌入编码3按照最后一个维度进行串接,得到第2个阶段注意力编码输入特征2,将第2个阶段嵌入编码2与第2个阶段嵌入编码1按照最后一个维度进行串接,得到第2个阶段注意力编码输入特征3,将第2个阶段嵌入编码3与第2个阶段嵌入编码1按照最后一个维度进行串接,得到第2个阶段注意力编码输入特征4,将所述每个输入特征,按照最后一个维度,将前一半通道特征作为目标编码特征,将后一半通道特征作为源编码特征,将目标编码特征和源编码特征分别进行可分离的卷积运算,卷积核尺度均为3
×
3,特征通道数为64,水平方向及垂直方向的步长均为2,将目标编码特征的处理结果作为注意力学习的查询关键词k编码向量和数值v编码向量,将源编码特征的处理结果作为注意力学习的查询q编码向量,然后,利用多头注意力方法计算所述特征的注意力权重矩阵,头的个数为3,特征通道数为64,最后,将第2个阶段所述特征的注意力权重矩阵与所述目标编码特征相加得到第2个阶段注意力编码,由第2个阶段4个注意力编码输入特征进行注意力编码处理后得到第2个阶段4个跨视图编码特征,利用所述跨视图编码特征的第1个和第2个特征的平均特征作为第2个阶段跨视图跨层特征,将所述第2个阶段跨视图跨层特征、第2个阶段第3个跨视图编码特征、第2个阶段第4个跨视图编码特征作为第2个阶段跨视图编码结果,将所述第2个阶段跨视图编码结果作为第3个阶段跨视图编码输入,将所述第2个阶段跨视图编码结果按照最后一个维度进行串接得到第2个阶段串接编码结果;
[0095]
3)第3个阶段的跨视图编码包括第3个阶段的嵌入编码和第3个阶段注意力编码
[0096]
第3个阶段的嵌入编码,将第2个阶段跨视图编码结果中的每个特征进行嵌入编码处理:卷积运算,卷积核尺度均为3
×
3,特征通道数为128,水平方向及垂直方向的步长均为2,序列化处理将编码特征从图像特征空域形状变换为序列结构,特征的层归一化处理,得到第3个阶段嵌入编码1、第3个阶段嵌入编码2和第3个阶段嵌入编码3;
[0097]
第3个阶段注意力编码,将第3个阶段嵌入编码1与第3个阶段嵌入编码2按照最后
一个维度进行串接,得到第3阶注意力编码输入特征1,将第3个阶段嵌入编码1与第3个阶段嵌入编码3按最后一个维度进行串接,得到第3个阶段注意力编码输入特征2,将第3个阶段嵌入编码2与第3个阶段嵌入编码1按照最后一个维度进行串接,得到第3个阶段注意力编码输入特征3,将第3个阶段嵌入编码3与第3个阶段嵌入编码1按照最后一个维度进行串接,得到第3个阶段注意力编码输入特征4,将所述每个输入特征,按照最后一个维度,将前一半通道特征作为目标编码特征,将后一半通道特征作为源编码特征,将目标编码特征和源编码特征分别进行可分离的卷积运算,其中卷积核尺度均为3
×
3,特征通道数为128,水平方向及垂直方向的步长均为2,将目标编码特征的处理结果作为注意力学习的查询关键词k编码向量和数值v编码向量,将源编码特征的处理结果作为注意力学习的查询q编码向量,然后,利用多头注意力方法计算所述特征的注意力权重矩阵,头的个数为6,特征通道数为128,最后,将第3个阶段所述特征的注意力权重矩阵与所述目标编码特征相加得到第3个阶段注意力编码,这样,第3个阶段的4个注意力编码输入特征经过所述的嵌入编码处理及注意力编码处理后,得到第3个阶段4个跨视图编码特征,利用所述跨视图编码特征的第1个和第2个特征的平均特征作为第3个阶段跨视图跨层特征,将所述第3个阶段跨视图跨层特征、第3个阶段第3个跨视图编码特征、第3个阶段第4个跨视图编码特征作为第3个阶段跨视图编码结果,将所述第3个阶段跨视图编码结果按照最后一个维度进行串接得到第3个阶段串接编码结果;
[0098]
对于第1个网络分支,将第1个阶段串接编码结果依次进行2个单元处理:在第1个单元处理中,卷积运算的特征通道数为16,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理,在第2个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,将所得到的特征依次进行2个单元处理:在第1个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理,在第2个单元处理中,卷积运算的特征通道数为64,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,然后,将所得到的特征与第3个阶段串接编码结果相串接,进行以下3个单元处理:在第1个单元处理中,卷积运算的特征通道数为64,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,在第2个单元处理中,卷积运算的特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,在第3个单元处理中,卷积运算的特征通道数为12,卷积核尺度均为1
×
1,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理,将所得的12通道的特征结果按照2
×
6的形式进行预测,得到张量l的结果;
[0099]
对于第2个网络分支,将第1个阶段串接编码结果依次进行2个单元处理:在第1个单元处理中,卷积运算的特征通道数为16,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理,在第2个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,然后将所得到的特征与第2个阶段串接编码结果相串接,进行以下2个单元处理:在第1个单元处理中,卷积运算的特征通道数为32,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理,在第2个单元处理中,卷积运算的特征通道数
为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,将所得到的特征与第3个阶段串接编码结果相串接,进行2个单元处理:在第1个单元处理中,卷积运算的特征通道数为64,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,在第2个单元处理中,卷积运算的特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,在第3个单元处理中,卷积运算的特征通道数为4,卷积核尺度均为1
×
1,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理,将所得的4通道的特征结果作为张量o的结果;
[0100]
对于第3个网络分支,将第3个阶段串接编码结果进行以下4个单元的处理:在第1个单元处理中,卷积运算的特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,再进行特征激活、批归一化处理,在第2个单元处理中,卷积运算的特征通道数为512,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,再进行特征激活、批归一化处理,在第3个单元处理中,卷积运算的特征通道数为1024,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,在第1个单元处理中,卷积运算的特征通道数为3,卷积核尺度均为1
×
1,水平方向及垂直方向的步长均为1,将所得到的特征作为张量d的结果;
[0101]
对于第4个网络分支,将第1个阶段跨视图跨层特征进行一次反卷积运算、特征激活、批归一化处理,反卷积运算中,卷积的特征通道数为16,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,将得到的结果记为解码器跨层特征1,再将第1个阶段跨视图跨层特征进行以下2个单元的处理:第1个单元处理时,卷积运算特征通道数为32,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,并将处理特征记为解码器跨层特征2,第2个单元处理,卷积运算,特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将所得到的特征与将第2个阶段跨视图跨层特征进行串接,将所述串接结果进行以下2个单元的处理:第1个单元处理时,卷积的特征通道数为64,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,并将处理特征记为解码器跨层特征3,将所述跨层特征进行第2个单元处理,第2个单元处理时,卷积的特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,然后将所得到的特征与第3个阶段跨视图跨层特征进行串接,再进行以下3个单元处理,每个单元的处理功能均为卷积运算、特征激活、批归一化处理,在所述3个单元处理中,第1个单元处理时,卷积的特征通道数为128,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为1,并将处理特征记为解码器跨层特征4,将所述跨层特征进行第2个单元处理,第2个单元处理时,卷积的特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,将并将处理特征记为解码器跨层特征5,将所述跨层特征进行第3个单元处理,第3个单元处理时,卷积的特征通道数为512个,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,处理后得到第4个分支编码特征;
[0102]
进一步进行解码,将所述第4个分支编码特征进行1次反卷积运算:卷积的特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,并将得到的结果与解码器跨层特征5相串接,进行一次卷积运算:特征通道数为512,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的结果进行反卷积运算:特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向
的步长均为2,特征激活、批归一化处理,将所得到的结果与解码器跨层特征4相串接,进行一次卷积运算:特征通道数为256,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的结果进行一次进行反卷积运算:特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将所得到的结果与解码器跨层特征3相串接,进行一次卷积运算:特征通道数为128,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的特征作为张量b的第4个尺度结果,同时,将所得到的特征进行1次反卷积运算,反卷积的特征通道数为64,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将做得到的特征与解码器跨层特征2相串接,进行一次卷积运算:特征通道数为64,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的特征作为张量b的第3个尺度结果,同时,将所得到的特征进行1次反卷积运算:反卷积的特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,再将所得到的特征与解码器跨层特征1相串接,然后进行一次卷积运算:特征通道数为32,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的特征作为张量b的第2个尺度结果,同时,将所得到的特征进行1次反卷积运算:特征通道数为16,卷积核尺度均为7
×
7,水平方向及垂直方向的步长均为2,特征激活、批归一化处理,将所得到的特征与第3个尺度特征的上采样结果进行相串接,然后进行一次卷积运算:特征通道数为16,卷积核尺度均为3
×
3,水平方向及垂直方向的步长均为1,特征激活、批归一化处理,将所得到的特征作为张量b的第1个尺度结果,利用所述张量b的4个尺度结果,得到第4个分支的输出;
[0103]
步骤3:神经网络的训练
[0104]
分别将自然图像数据集、超声影像数据集和ct影像数据集中样本按照9:1划分为训练集和测试集,训练集中数据用于训练,测试集数据用于测试,在训练时,分别从对应的数据集中获取训练数据,统一缩放到分辨率416
×
128,输入到对应网络中,迭代优化,通过不断修改网络模型参数,使得每批次的损失达到最小;
[0105]
在训练过程中,各损失的计算方法:
[0106]
内部参数监督合成损失:在自然图像的网络模型训练中,将深度信息编码网络输出的张量i作为深度,将互注意力transformer学习网络输出的张量l与训练数据的内部参数标签e
t
(t=1,2,3,4)分别作为位姿参数和摄像机内部参数,根据计算机视觉原理算法,利用图像b和图像d分别合成图像c视点处的两个图像,利用图像c分别与所述的两个合成图像,按照逐像素、逐颜色通道强度差之和计算得到;
[0107]
无监督合成损失:在超声或者ct影像的网络模型训练中,将深度信息编码网络的输出张量i作为深度,将互注意力transformer学习网络的第1个网络分支的输出张量l和互注意力transformer学习网络的第2个网络分支的输出张量o分别作为位姿参数和摄像机内部参数,根据计算机视觉算法,利用目标影像的两相邻影像分别合成目标影像视点处的影像,利用目标影像分别与所述目标影像视点处的影像,按照逐像素、逐颜色通道强度差之和计算得到;
[0108]
内部参数误差损失:在自然图像的网络模型训练中,利用互注意力transformer学习网络的第2个网络分支的输出张量o与训练数据的内部参数标签e
t
(t=1,2,3,4)按照各
分量差的绝对值之和计算得到;
[0109]
空间结构误差损失:在超声或者ct影像的网络模型训练中,将深度信息编码网络的输出张量i作为深度,将互注意力transformer学习网络的第1个网络分支的输出张量l和互注意力transformer学习网络的第2个网络分支的输出张量o分别作为位姿参数和摄像机内部参数,根据计算机视觉算法,分别利用目标视点处影像的两个相邻影像重建目标视点处影像的三维坐标,采用ransac算法对重建点进行空间结构拟合,空间结构误差损失利用拟合得到的法向量与互注意力transformer学习网络的输出张量d,利用余弦距离计算得到;
[0110]
变换合成损失:在超声或者ct影像的网络参数训练中,将深度信息编码网络的输出张量i作为深度,将互注意力transformer学习网络的第1个网络分支的输出张量l和互注意力transformer学习网络的第2个网络分支的输出张量o分别作为位姿参数和摄像机内部参数,利用目标影像的两个相邻影像构建目标影像视点处的两个合成影像,对于所述合成影像中的每个影像,在合成过程得到每个像素位置后,将第5个网络分支输出张量b作为合成影像空域变形的位移量,构成合成结果影像,然后利用目标视点处的图像或者影像与所述合成目标视点处的结果,按照逐像素、逐颜色通道强度差之和计算得到;
[0111]
具体训练步骤:
[0112]
(1)在自然图像数据集上,分别对深度信息编码网络及互注意力transformer学习网络主干网络及第一个网络分支,训练80000次
[0113]
每次从自然图像数据集中取出训练数据,统一缩放到分辨率416
×
128,将图像c输入深度信息编码网络,将图像c及图像τ输入互注意力transformer学习网络,对深度信息编码网络及视觉互注意力transformer学习网络主干网络及第一个网络分支,训练80000次,每批次的训练损失由内部参数监督合成损失计算得到;
[0114]
(2)在自然图像数据集上,对互注意力transformer学习网络第2个网络分支,训练50000次
[0115]
每次从自然图像数据集中取出训练数据,统一缩放到分辨率416
×
128,将图像c输入深度信息编码网络,将图像c及图像τ输入互注意力transformer学习网络,对第2个网络分支进行训练,每批次的训练损失由无监督合成损失和内部参数误差损失之和计算得到;
[0116]
(3)在超声影像数据集上,对深度信息编码网络、互注意力transformer学习网络主干网络及网络分支1
‑
4训练80000次,得到模型参数ρ
[0117]
每次从超声影像数据集上取出超声训练数据,统一缩放到分辨率416
×
128,将影像j输入深度信息编码网络,将影像j及影像π输入到互注意力transformer学习网络,对深度信息编码网络、互注意力transformer学习网络主干网络及网络分支1
‑
4进行训练,每批次的训练损失由变换合成损失、空间结构误差损失之和计算得到;
[0118]
(4)在ct影像数据集上,对于互注意力transformer学习网训练60000次,得到模型参数ρ
′
[0119]
每次从ct影像数据集中取出ct影像训练数据,统一缩放到分辨率416
×
128,将影像m及影像σ输入到互注意力transformer学习网络,将深度信息编码网络输出结果作为深度,主干网络及第1及第2个网络分支的输出结果分别作为位姿参数和摄像机内部参数,将互注意力transformer学习网络的第4个网络分支的输出张量b作为空域变形的位移量,分
别根据影像l和影像n合成影像m视点处的两张影像,通过不断修改网络的参数,对所述网络进行训练,迭代优化,针对每批次每幅影像损失达到最小,迭代后得到最优的网络模型参数ρ
′
,使得每批次的每幅影像的损失达到最小,网络优化的损失计算时,除了变换合成损失、空间结构误差损失,还附加摄像机平移运动的损失;
[0120]
步骤4:对超声或者ct影像三维重建
[0121]
利用自采样的一个超声或者ct序列影像,同时进行以下3个处理实现三维重建:
[0122]
(1)对序列影像中任一目标影像,按照如下方法计算摄像机坐标系下的三维坐标:缩放到分辨率416
×
128,对于超声序列影像,将影像j输入深度信息编码网络,将影像j及影像π输入到互注意力transformer学习网络,对于ct序列影像,将影像m输入深度信息编码网络,将,影像m及影像σ输入到输入互注意力transformer学习网络,分别利用模型参数ρ和模型参数ρ
′
进行预测,从深度信息编码网络得到每一帧目标影像的深度,将互注意力transformer学习网络的第1个网络分支的输出张量l和第2个网络分支的输出张量o分别得到摄像机位姿参数及摄像机内部参数,根据目标影像的深度信息及摄像机内部参数,依据计算机视觉的原理,计算目标影像的摄像机坐标系下的三维坐标;
[0123]
(2)序列影像三维重建过程中,建立关键帧序列:将序列影像第一帧作为关键帧序列的第一帧,并作为当前关键帧,当前关键帧之后的帧作为目标帧,按照目标帧顺序依次动态选取新的关键帧:首先,用单位矩阵初始化目标帧相对于当前关键帧的位姿参数矩阵,针对任一目标帧,将所述位姿参数矩阵累乘目标帧摄像机位姿参数,并利用累乘结果,结合所述目标帧的内部参数及深度信息,合成所述目标帧视点处的影像,利用所述合成影像与所述目标帧之间逐像素逐颜色通道强度差之和的大小计算误差λ,再根据所述目标帧的相邻帧,利用摄像机位姿参数和内部参数,合成所述目标帧视点处的影像,利用所述合成的影像与所述目标帧之间逐像素逐颜色通道强度差之和的大小计算误差γ,进一步利用公式(1)计算合成误差比z:
[0124][0125]
满足z大于1.2时,将所述目标帧作为新的关键帧,并将所述目标帧相对于当前关键帧的位姿参数矩阵作为新的关键帧的位姿参数,同时将所述目标帧更新为当前关键帧;以此迭代,完成关键帧序列建立;
[0126]
(3)将序列影像第一帧的视点作为世界坐标系的原点,对任一目标帧,将其分辨率缩放到m
×
n,对于超声影像,m取450,n取300,对于ct影像,m和n均取512,根据网络输出得到的摄像机内部参数及深度信息,计算得到摄像机坐标系下的三维坐标,根据网络输出的摄像机位姿参数,并结合关键帧序列中每一关键帧的位姿参数以及目标帧相对于当前关键帧的位姿参数矩阵,计算得到所述目标帧的每个像素的世界坐标系中的三维坐标。
[0127]
本实施例在构建的自然图像训练集、超声影像训练集和ct影像训练集进行网络训练,利用公共数据集的10个超声影像序列及1个ct影像序列,分别进行测试,采用变换合成损失进行误差计算,在超声或者ct影像的误差计算中,利用目标影像的两个相邻影像构建目标影像视点处的两个合成影像,对于所述合成影像中的每个影像,利用所述两个目标视点处的合成影像,按照逐像素、逐颜色通道强度差之和计算得到。
[0128]
表1为在超声影像序列重建时,计算得到的误差,表2为在ct影像序列重建时,计算得到的误差,本实施例,采用densenet对超声或者ct影像进行分割,然后进行3d重建,图1表示利用本发明得到的超声影像的三维重建结果,图2表示利用本发明得到的ct影像的三维重建结果,从中可以看出本发明能够得到较为准确的重建结果。
[0129]
表1
[0130]
序号误差10.129916466881872720.036891531681180630.0733986185447130440.0974490617831647650.101802858937469260.0810942017171998570.05197330311007452480.098888782075969790.10880799129583894100.06647273849340957
[0131]
表2
[0132]
序号误差10.05854478360600131520.066720051341995430.0682181661123074540.0678072927160419150.1186243742363273160.1005460112942065570.1244218949220088180.1506565601424598790.10756279393662936100.11451064929672831
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。