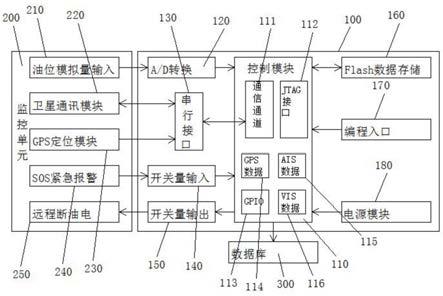
技术特征:
1.一种基于强化学习和注意力机制的无人机群调度方法,其特征在于,包括如下步骤:步骤1,根据所观测到的状态信息的维度,调整transformer编码器的输入维度和输出头的个数,并给定其他超参数,其他超参数包括编码层的个数、前馈层的维度和编码维度;步骤2,收集仿真器给出的关于飞机状态信息,包括飞机编号id、空间横坐标x和纵坐标y、是否打开雷达干扰is_radar_on、干扰频点freq,将收集的信息经过预先编码后组装成为transformer编码器的状态输入s=(id,x,y,is_radar_on,freq);步骤3,将当前transformer编码器的输出送入指针网络得到解码结果,解码结果为基于注意力机制得到的索引,也就是当前状态下最应该给予关注的目标单位的索引,并将该索引作为第一个输出头的结果;步骤4,将transformer编码器的输出和指针网络的输出送入下一层全连接网络得到第二个输出头,第二个输出头的输出动作代表所选动作类型是飞行或者打击;最后将transformer编码器的输出加上第一个输出头的输出、第二个输出头的输出送入后续的全连接网络得到第三个输出头,代表所选的目标地点;根据解码得到的目标单位的索引,以及第二个输出头、第三个输出头的内容,给出无人机群的相应动作,转换为仿真平台能够接收的指令并发送给仿真平台;步骤5,收集仿真平台返回的新状态和即时奖励信息,在收集了x批次的数据之后,在ppo近端策略优化算法的框架下,得到梯度下降方向,并基于反向传播算法修正网络参数。2.根据权利要求1所述的方法,其特征在于,步骤2中,对空间坐标作[
‑
1,1]区间的归一化编码、对是否打开雷达干扰作独热编码,同时保证每一架飞机的状态信息在transformer编码器的状态输入中的位置固定。3.根据权利要求2中所述的方法,其特征在于,步骤3中,将当前transformer编码器的输出送入指针网络,将输出记为(e1,...,e
n
)=trans(s),其中(e1,...,e
n
)为transformer编码器的编码输出矩阵的列向量,trans代表transformer对状态输入s所进行的操作;基于注意力机制进行解码的时候,最终希望得到一个索引序列c1,c2,...,c
i
,其中c
i
代表无人机群中的第c
i
架无人机,将任务建模为在已知序列c1,c2,...,c
i
‑1的情形下,最大化c
i
出现的后验概率在指针网络的注意力机制中,所述任务形式化为如下公式:在指针网络的注意力机制中,所述任务形式化为如下公式:其中,v,w1,w2为transformer
‑
pointernet网络的可训练参数,v
t
为可训练参数v的转置,transformer
‑
pointernet网络是transformer编码器和指针网络合成的编码解码结构,指针网络是基于lstm网络实现的,tanh为双曲正切激活函数,softmax是一类最大值函数,(d1,...,d
m
)是解码的lstm网络每一步输出的隐状态,d
m
表示解码的lstm网络第m步输出的隐状态;代表transformer
‑
pointernet网络的第i个输出e
i
与解码的lstm网络的第j个输出d
j
之间的关联分数,u
i
为所有组成的向量,即4.根据权利要求3中所述的方法,其特征在于,步骤4中,将三个输出头的动作进行组装,第一个输出头指定整体动作的主语,也就是由指针网络选出的单位去执行动作;第二个输出头指定该执行的动作;第三个输出头指定动作的客体;每一个输出头的输出都会作为输入进入到下一个输出头中去。
5.根据权利要求4中所述的方法,其特征在于,步骤5中,收集固定长度间隔的时间步上的对应状态s
t
、动作a
t
、即时价值函数r
t
,得到优势函数为:其中t表示当前时刻,γ为价值折现因子,λ为价值衰减因子,δ
t
=r
t
γv(s
t 1
)
‑
v(s
t
),δ
t
为时序差分误差,t代表最长时间步,v(s
t
)是价值网络对于当前状态的价值估计,v(s
t 1
)为当前步的下一个时间步所处于状态的价值估计,损失函数l
t
(θ)通过下式计算:其中其中为策略损失函数,为策略损失函数,为价值估计损失函数,代表求到当前时刻为止的期望,s[π
θ
](s
t
)是策略π
θ
之下状态s
t
的熵损失,v
θ
(s
t
)为当前网络参数θ之下对状态s
t
的价值函数的估计值,v
ttarg
为从采样数据中得到的当前状态所对应价值函数的真实值,r
t
(θ)为在旧参数网络之下的价值函数和新参数网络下的价值函数的比值,clip为截断函数,将比值r
t
(θ)的值限制在1
‑
ε和1 ε之间,ε为阈值因子;c1,c2为待定常数;将损失函数l
t
(θ)对神经网络参数θ作梯度下降:得到更新后的参数θ
t 1
,其中为梯度算子,α为每一次更新的步长,重复此过程,直到算法收敛。
技术总结
本发明提供了一种基于强化学习和注意力机制的无人机群调度方法,包括:步骤1,设置作为编码器的Transformer的各个超参数,获取仿真器的状态;步骤2,将状态做特征预处理之后送入Transformer编码器;步骤3,将Transformer编码器的编码输出作为指针网络解码器的输入,通过解码选出当前状态下最应该关注的单位;步骤4,神经网络的多头输出结果构造仿真平台能接受的指令,将其输入仿真平台驱动其前进。本发明通过组合注意力机制和强化学习实现了不同状态下对于无人机群中不同单位的关注,通过神经网络的多头输出实现了对于动作空间的良好分解,这一设计对于无人机群的扩容不敏感。这一设计对于无人机群的扩容不敏感。这一设计对于无人机群的扩容不敏感。
技术研发人员:江天舒 郭成昊 李秀成 汪亚斌
受保护的技术使用者:中国电子科技集团公司第二十八研究所
技术研发日:2021.08.12
技术公布日:2021/11/8
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。