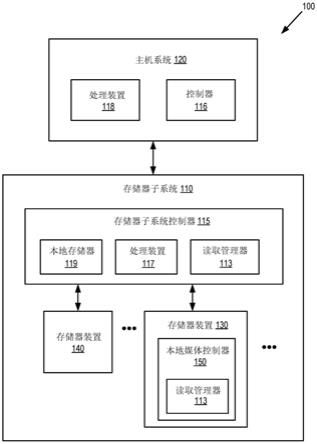
用于近数据处理的系统、方法和设备
1.相关申请的交叉引用
2.本技术要求2020年5月7日提交的序列号为63/021,675,标题为“dimm based near
‑
data
‑
processing accelerator for k
‑
mer counting”的美国临时专利申请的优先权和利益,该申请通过引用并入本文。
技术领域
3.本公开一般涉及数据处理,更具体地,涉及用于近数据处理的系统、方法和设备。
背景技术:
4.一些数据处理应用,诸如k
‑
mer计数,可能涉及访问和/或处理随机分散遍布存储在工作存储器空间中的数据集中的小数据单元。
5.在背景技术部分公开的上述信息仅用于增强对本发明的背景的理解,因此它可以包含不构成现有技术的信息。
技术实现要素:
6.一种存储器模块可以包括一个或多个存储器设备,以及耦合到一个或多个存储器设备的近存储器计算模块;近存储器计算模块包括被配置为处理来自一个或多个存储器设备的数据的一个或多个处理元件,以及被配置为协调来自主机和一个或多个处理元件的对一个或多个存储器设备的访问的存储器控制器。近存储器计算模块可以被配置为基于第一芯片选择信号控制一个或多个存储器设备中的第一存储器设备,并且基于第二芯片选择信号控制一个或多个存储器设备中的第二存储器设备。一个或多个存储器设备和近存储器计算模块被布置为第一级(rank),存储器模块还包括第二级,以及被配置为在第一级和第二级之间传输数据的分层总线结构。一个或多个存储器设备可以包括一个或多个第一存储器设备,近存储器计算模块可以包括第一近存储器计算模块,并且一个或多个处理元件可以包括一个或多个第一处理元件,并且第二级可以包括一个或多个第二存储器设备,以及耦合到一个或多个第二存储器设备的第二近存储器计算模块,第二近存储器计算模块包括被配置为处理来自一个或多个第二存储器设备的数据的一个或多个第二处理元件,以及被配置为协调来自主机和一个或多个第二处理元件的对一个或多个第二存储器设备的访问的第二存储器控制器。存储器模块还可以包括分层总线结构,并且近存储器计算模块还可以包括耦合在分层总线结构和一个或多个处理元件之间的输入缓冲器,以及耦合在分层总线结构和一个或多个处理元件之间的输出缓冲器。近存储器计算模块还可以包括工作负荷监视器,工作负荷监视器被配置为平衡一个或多个处理元件中的第一处理元件的第一工作负荷和一个或多个处理元件中的第二处理元件的第二工作负荷。
7.一种处理数据集的方法可以包括:将数据集的第一部分分布到第一存储器模块,将数据集的第二部分分布到第二存储器模块,基于数据集的第一部分在第一存储器模块处构建第一本地数据结构,基于数据集的第二部分在第二存储器模块处构建第二本地数据结
构,以及合并第一本地数据结构和第二本地数据结构。合并第一本地数据结构和第二本地数据结构可以形成合并的数据结构,并且方法还可以包括在第一存储器模块和第二存储器模块处对合并的数据结构执行计数操作。合并第一本地数据结构和第二本地数据结构可以包括简化(reduce)第一本地数据结构和第二本地数据结构。简化第一本地数据结构和第二本地数据结构可以形成合并的数据结构,并且该方法还可以包括将合并的数据结构分散到第一存储器模块和第二存储器模块。该方法还可以包括将数据集的第一部分分布到第一存储器模块处的两个或更多个存储器设备。该方法还可以包括将数据集的第一部分分布到第一存储器模块处的两个或更多个级。第一本地数据结构可以由第一处理元件和第二处理元件在第一存储器模块处构建,并且该方法还可以包括平衡第一处理元件的第一工作负荷和第二处理元件的第二工作负荷。该方法还可以包括在第一任务和第二任务之间交错数据集的第一部分的存储器访问。该方法还可以包括在数据集的第一部分的存储器访问之间在第一任务和第二任务之间切换。合并第一本地数据结构和第二本地数据结构可以形成第一合并的数据结构,并且该方法还可以包括将合并的数据结构分散到第一存储器模块和第二存储器模块,基于第一合并的数据结构在第一存储器模块处构建第三本地数据结构,基于第一合并的数据结构在第一存储器模块处构建第四本地数据结构,合并第三本地数据结构和第四本地数据结构以形成第二合并的数据结构,以及在第一存储器模块和第二存储器模块处对第二合并的数据结构执行计数操作。数据集可以包括基因序列(genetic sequence),第一本地数据结构可以包括布隆过滤器(bloom filter),并且布隆过滤器可以包括基因序列的一个或多个k
‑
mer。
8.一种系统可以包括:第一存储器模块,其被配置为基于数据集的第一部分构建第一本地数据结构;第二存储器模块,其被配置为基于数据集的第二部分构建第二本地数据结构;以及主机,其通过一个或多个存储器通道耦合到第一存储器模块和第二存储器模块,其中主机可以被配置为将数据集的第一部分分布到第一存储器模块,将数据集的第二部分分布到第二存储器模块,以及合并第一本地数据结构和第二本地数据结构。第一本地数据结构和第二本地数据结构可以形成合并的数据结构,并且主机还可以被配置为将合并的数据结构分散到第一存储器模块和第二存储器模块。第一存储器模块可以被配置为对合并的数据结构执行计数操作。
附图说明
9.附图不一定是按比例绘制的,并且为了说明的目的,在所有附图中,相似的结构或功能的元素通常可以由类似的附图标记或其部分表示。附图仅旨在便于描述本文描述的各种实施例。附图没有描述在本文公开的教导的每个方面,并且没有限制权利要求的范围。为了防止附图变得模糊,并非所有的组件、连接等都可以被示出,并且并非所有的组件都具有附图标记。然而,组件配置的模式可以从附图中容易地显而易见。附图与说明书一起示出了本公开的示例实施例,并且与描述一起用于解释本公开的原理。
10.图1示出了根据本公开的示例实施例的k
‑
mer计数方法的实施例。
11.图2示出了根据本公开的示例实施例的k
‑
mer计数方法和数据结构的实施例。
12.图3示出了根据本公开的示例实施例的用于k
‑
mer计数方法的布隆过滤器的实施例。
13.图4示出了根据本公开的示例实施例的近数据处理系统的实施例。
14.图5示出了根据本公开的示例实施例的具有近数据处理能力的存储器模块的实施例。
15.图6示出了根据本公开的示例实施例的具有多级和近数据处理能力的存储器模块的实施例。
16.图7示出了根据本公开的示例实施例的近数据处理系统的示例实施例。
17.图8示出了根据本公开的示例实施例的存储器模块的示例实施例。
18.图9示出了根据本公开的示例实施例的存储器模块的级或存储器模块的部分的更详细的示例实施例。
19.图10示出了根据本公开的示例实施例的处理元件的示例实施例。
20.图11a示出了根据本公开的示例实施例的第一布隆过滤器构建操作和第二布隆过滤器构建操作的实施例。
21.图11b示出了根据本公开的示例实施例的第一合并操作和第二合并操作的实施例。
22.图11c示出了根据本公开的示例实施例的计数操作的实施例。
23.图12示出了根据本公开的示例实施例的使用全局数据集的k
‑
mer计数方法的实施例。
24.图13示出了根据本公开的示例实施例的k
‑
mer计数方法工作流的实施例。
25.图14a示出了根据本公开的示例实施例的计数布隆过滤器构建操作的实施例。
26.图14b示出了根据本公开的示例实施例的合并操作的实施例。
27.图14c示出了根据本公开的示例实施例的计数操作的实施例。
28.图15a示出了根据本公开的示例实施例的用于存储器设备的合并地址映射方案的实施例。
29.图15b示出了根据本公开的示例实施例的用于存储器设备的分散地址映射方案的另一实施例。
30.图16a示出了根据本公开的示例实施例的布隆过滤器的顺序存储器访问方法的示例实施例。
31.图16b示出了根据本公开的示例实施例的布隆过滤器的分散存储器访问方法的示例实施例。
32.图17示出了根据本公开的示例实施例的处理数据集的方法的实施例。
具体实施方式
33.概述
34.一些数据处理应用可能涉及访问和/或处理随机分散遍布存储在工作存储器空间中的大数据集中的许多小数据单元(例如,一个比特)。这种类型的细粒度数据访问和处理在用中央处理单元(cpu)或具有较大数据宽度(例如,32或64比特)的其他处理单元实施时是低效且耗时的,尤其是当数据远离处理器存储在存储器系统中时,该存储器系统具有被配置为顺序访问较大数据单元(例如,存储在连续存储位置中的多个64比特字(word)的总线。
35.根据本公开的示例实施例的近数据处理(ndp)系统可以包括具有一个或多个处理资源的存储器模块,该存储器模块被配置为处理模块处的数据,从而减少或消除到主机处理单元的数据传输。在一些实施例中,近数据处理系统可以包括一个或多个特征,这一个或多个特征可以有助于访问和/或处理细粒度数据单元,和/或存储器模块内的有效通信。
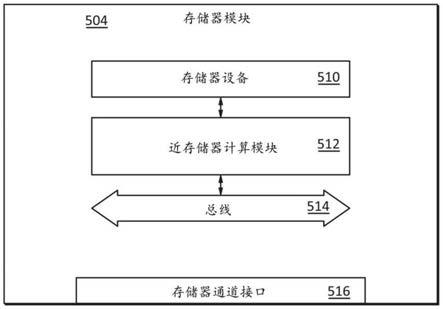
36.例如,一些实施例可以包括一个或多个近存储器计算(near
‑
memory computing,nmc)模块,该一个或多个近存储器计算(nmc)模块可以包括一个或多个处理元件,该一个或多个处理元件被配置为并行处理多个相对小的数据单元和/或实施一个或多个特定算法或其部分。在一些实施例中,近存储器计算模块可以包括一个或多个特征,诸如存储器控制器、工作负荷监视器、总线控制器、一个或多个缓冲器、多路复用器等,以支持数据通信和/或同步、实现任务调度和/或存储器访问等。在一些实施例中,对于存储器模块中的每一级存储器设备,可以包括近存储器计算模块。
37.作为另一个示例,一些实施例可以实施分层总线架构,该分层总线架构可以实现模块内的级之间、级内的存储器设备之间等的有效数据传输。一些实施例可以实施独立的芯片选择(chip select,cs)信号,芯片选择(cs)信号可以实现单个存储器设备的细粒度存储器访问。
38.根据本公开的示例实施例的工作流可以将数据集的部分分布(distribute)到具有近数据处理能力的多个存储器模块。存储器模块可以处理它们各自的数据集的部分,以构建本地数据结构,该本地数据结构然后可以被合并和/或重新分布到存储器模块用于进一步处理。
39.例如,工作流的实施例可以实施k
‑
mer计数过程,其中存储器模块可以构建本地布隆过滤器。来自布隆过滤器的数据然后可以被合并(例如,通过简化过程),然后被分散到存储器模块。存储器模块然后可以对它们的合并的和分散的布隆过滤器的副本执行本地计数过程。在一些实施例中,存储器模块可以实施计数布隆过滤器,这可以促进本地处理的使用。
40.一些实施例可以实施分布式数据映射方案,以跨存储器设备、级、存储器模块等分布数据。取决于实施方式细节,这可以提高存储器带宽利用率和/或能量利用率,例如,通过减少或消除存储器设备、级、存储器模块等内的数据的集中(concentration)。
41.一些实施例可以基于监视一个或多个计算资源的工作负荷来实施任务调度方案。例如,任务调度方案可以平衡近存储器计算模块中的处理元件之间的工作负荷。取决于实施方式细节,这可以提高一个或多个计算资源的利用率。
42.一些实施例可以实施分散的存储器访问和/或任务切换方案。例如,一个任务的存储器访问可以与一个或多个其他任务的存储器访问交错(interleaved)。取决于实施方式细节,这可以减少或消除不可用的数据访问。附加地或可替代地,任务可以在存储器访问之间切换,例如,用可用数据的访问来填充存储器访问时隙。取决于实施方式细节,这可以提高存储器带宽利用率和/或降低能耗。
43.本文公开的原理具有独立的实用性,并且可以单独体现,并且不是每个实施例都可以利用每个原理。然而,这些原理也可以以各种组合来体现,其中一些可以以协同的方式放大各个原理的益处。
44.k
‑
mer计数
45.k
‑
mer计数可以用于确定包含基因序列(例如,脱氧核糖核酸(dna)序列)的数据集中具有长度为k的子序列的数量。例如,可以使用k=3的k
‑
mer计数过程来寻找图1顶部所示的dna序列中每种类型的3
‑
mer的数量。k=3的3
‑
mer计数过程的结果可以显示在图1底部的表格中。因此,dna序列可能包括一个atc 3
‑
mer,两个tct 3
‑
mer,一个ctc 3
‑
mer等。在一些实施例中,k
‑
mer计数可以用于诸如生物信息学、药物开发、进化研究、作物改良、法医分析、基因治疗、下一代测序(ngs)等的应用。在一些实施例中,诸如ngs技术的应用可以帮助表征2019年全球大流行性冠状病毒疾病(covid
‑
19)。
46.在一些应用中,独特的k
‑
mer(例如,在数据集中可能只出现一次的k
‑
mer)很可能包含错误。因此,一些k
‑
mer计数过程可能会过滤掉独特的k
‑
mer。例如,在一些应用中,高达75%的k
‑
mer可能是独特的,因此,消除独特的k
‑
mer可以显著减少dna序列数据集的存储器印迹(footprint)。
47.图2示出了根据本公开的示例实施例的k
‑
mer计数方法和数据结构的实施例。图2所示的方法可以接收dna序列211作为输入。该方法可以读取并处理dna序列211中的k
‑
mer,以构建三个数据结构的系列,在该实施例中,该三个数据结构可以被实施为第一布隆过滤器213、第二布隆过滤器215和哈希表217。
48.第一布隆过滤器213可以包括具有m比特容量的比特阵列,并且可以使用n个独立的哈希函数来将k
‑
mer插入阵列。布隆过滤器最初可以用全零填充。当从dna序列211中读取k
‑
mer时,n个哈希函数可以应用于k
‑
mer以计算n个哈希值。然后可以设置比特阵列中对应于n个哈希值的n个比特。例如,如果n=3,将三个独立的哈希函数h1、h2和h3应用于第一k
‑
mer(x)可以分别生成哈希值1、5和13(例如,h1(x)=1、h2(x)=5和h3(x)=13)。因此,位置1、5和13处的比特可以如图3所示进行设置。将三个哈希函数应用于第二个k
‑
mer(y)可以分别生成哈希值4、11和16。因此,位置4、11和16处的比特可以如图3所示进行设置。将三个哈希函数应用于第三k
‑
mer(z)可以分别生成哈希值3、5和11。因此,位置3处的比特可以(位置5和11处的比特可能已经被设置)如图3所示进行设置。
49.为了检查第一布隆过滤器213中特定的k
‑
mer的存在,可以将n个哈希函数应用于特定的k
‑
mer以计算n个哈希值。然后可以检查比特阵列中对应于n个哈希值的n个比特位置中的条目。如果n个条目中的任何一个是零,则它可以指示布隆过滤器213中不存在特定的k
‑
mer。(在一些实施例中,布隆过滤器213可以具有零漏报(false negative)率。)如果所有n个条目都是1,则可以高度确定地指示在该阵列中存在特定的k
‑
mer。(在一些实施例中,布隆过滤器213可能具有低误报(false positive)率。)
50.例如,如果n=3,则将三个独立的哈希函数应用于特定的k
‑
mer(w)可以生成哈希值4、13和15,如图3所示。因为布隆过滤器213可能在比特位置15处包含零,所以可能推断出特定的k
‑
mer不存在。
51.再次参考图2,第二布隆过滤器215可以以类似于第一布隆过滤器213的方式构建和操作。在一些实施例中,两个布隆过滤器213和215的系列可以用于实施修剪(pruning)处理,修剪处理可以如下过滤出独特的k
‑
mer。每当从数据集211读取新的k
‑
mer(w)时,该方法可以检查第一布隆过滤器213中新的k
‑
mer(w)的存在。如果第一布隆过滤器213中存在新的k
‑
mer(w),这可以指示它不是独特的k
‑
mer。因此,新的k
‑
mer(w)可以被写入第二布隆过滤器215。然而,如果新k
‑
mer(w)不存在于第一布隆过滤器213中,则它可以被添加到第一布隆
过滤器213,使得第一布隆过滤器213的未来检查将指示已经遇到了该新的k
‑
mer(w)的一个实例。
52.在输入dna序列数据集211中的所有k
‑
mer以这种方式被读取和处理之后,所有非独特的k
‑
mer可以被存储在第二布隆过滤器215中,其中独特的k
‑
mer已经被过滤出。在一些实施例中,第一布隆过滤器213然后可以被丢弃。
53.然后,存储在第二布隆过滤器215中的非独特的k
‑
mer可以如下计数。对于从dna序列数据集211中读取的每个输入k
‑
mer(w),可以针对输入序列k
‑
mer(w)的存在检查第二布隆过滤器215。如果输入k
‑
mer(w)存在于第二布隆过滤器215中,则哈希表217中的输入k
‑
mer(w)的对应条目(例如,频率计数器)可以增加。在一些实施例中,用于k
‑
mer(w)的频率计数器的值可以指示在dna序列数据集211中k
‑
mer(w)的实例的数量。因此,在已经读取并处理了所有k
‑
mer之后,哈希表217可以存储数据集211中所有非独特的k
‑
mer的出现频率。
54.在一些实施例中,图2所示的方法可以涉及对于布隆过滤器213和215两者以及哈希表217,对于相对小的数据单元执行的许多细粒度存储器访问和/或处理操作。
55.近数据处理架构
56.图4示出了根据本公开的示例实施例的近数据处理系统的实施例。图4所示的系统可以包括主机402和两个或多个存储器模块404。主机402可以通过一个或多个存储器通道406连接到存储器模块404。图4所示的系统还可以包括逻辑408和/或410,其可以使组件将数据集的部分分布到存储器模块404,处理数据集的部分以在存储器模块404处构建本地数据结构,合并本地数据结构,和/或对合并的数据结构执行一个或多个计数操作。
57.逻辑408和/或410和/或其部分可以位于图4所示的任何组件处。例如,在一些实施例中,逻辑408可以位于主机402处,并且可以控制数据集到存储器模块404的分布和/或本地数据结构的合并,而逻辑410可以位于每个存储器模块404处,并且可以控制数据集的分布部分的处理、本地数据结构的构建和/或存储器模块404处的计数操作。
58.主机402可以用任何类型的处理装置来实施,诸如一个或多个cpu、图形处理单元(gpu)、神经处理单元(npu)、张量处理单元(tpu)等,包括运行存储在任何类型的存储器中的指令的复杂指令集计算机(cisc)处理器(诸如x86处理器)和/或精简指令集计算机(risc)处理器(诸如arm处理器)等。
59.一个或多个存储器通道406可以用适合于存储器互连的任何类型的接口来实施,诸如任何一代的双数据速率(ddr)接口、开放存储器接口(omi)、外围组件互连高速(pcie)、计算高速链路(cxl)、高级可扩展接口(axi)、开放相干加速器处理器接口(opencapi)、gen
‑
z等。一个或多个存储器通道406可以以任何配置布置,例如,以两个存储器模块404通过单个多点总线连接到主机402来布置,以每个存储器模块404通过单独的点对点总线连接到主机402来布置,等等。
60.存储器模块404可以用以任何物理配置布置的任何类型和/或配置的存储器设备、缓冲器、接口(包括上述那些)等来实施。例如,存储器模块404可以用任何类型的存储器设备来实施,包括易失性存储器(诸如动态随机存取存储器(dram)和/或静态随机存取存储器(sram))、非易失性存储器(诸如包括非与非(nand)存储器的闪存)、持久性存储器(诸如交叉网格非易失性存储器)、具有体电阻变化的存储器等、和/或其任意组合。存储器模块404可以被配置为单直列存储器模块(simm)、双直列存储器模块(dimm)、小外形存储器模块
(so
‑
dimm)、减轻负载的存储器模块(lrdimm)等。在一些实施例中,存储器模块404中的一个或多个可以不被实施为单独的物理组件,而是可以被简单地实施为例如电路板的一部分,电路板具有一个或多个存储器设备和任何支持电路、迹线等,并且能够用作存储器模块。
61.逻辑408和/或410和/或其部分可以用硬件、软件或其任意组合来实施。诸如,在一些实施例中,任何逻辑可以用组合逻辑、时序逻辑、一个或多个定时器、计数器、寄存器、状态机、易失性存储器(诸如dram和sram)、非易失性存储器(诸如闪存)、复杂可编程逻辑器件(cpld)、现场可编程门阵列(fpga)、专用集成电路(asic)、运行指令的cisc处理器和/或risc处理器等,等等,以及cpu、gpu、npu、tpu等来实施。
62.图5示出了根据本公开的示例实施例的具有近数据处理能力的存储器模块的实施例。图5所示的存储器模块504可以用于,例如,实施图4所示的任何存储器模块404。图5所示的存储器模块504可以包括一个或多个存储器设备510的级、近存储器计算模块512、总线结构514和存储器通道接口516。
63.一个或多个存储器设备510可以用任何类型和/或配置的存储器设备来实施,例如,如上关于存储器模块404所述存储器设备。
64.近存储器计算模块512可以包括一个或多个处理元件,其能够处理通过总线结构514等从存储器设备510的级、存储器设备的另一级和/或另一存储器模块接收的任何数据单元。在一些实施例中,近存储器计算模块512可以包括一个或多个特征,例如,任何类型的通用和/或专用控制器(诸如存储器控制器、总线控制器等)、工作负荷监视器、一个或多个输入和/或输出缓冲器、一个或多个多路复用器和/或多路分解器等,以实施任务调度、存储器访问等。在一些实施例中,近存储器计算模块512可以实施多种功能中的任何一种,例如,k
‑
mer计数、加密和/或解密、去重复、编码和/或解码、纠错、任何类型的数据过滤等。在一些实施例中,近存储器计算模块512可以实施任何类型的通用控制器功能,例如,输入和/或输出(i/o)控制、一个或多个控制算法、监督控制、基板控制、可编程逻辑控制、过程控制等。近存储器计算模块512和/或其任何部分和/或特征可以用硬件、软件或其任意组合来实施,如上文关于逻辑408和/或410所述。
65.总线结构514可以例如用分层总线架构来实施,分层总线架构可以在级内的存储器设备之间、存储器设备和存储器通道接口516之间等传输数据。在一些实施例中,独立的芯片选择信号可以实现单个存储器设备510的细粒度存储器访问。总线结构514可以使用任何类型的信令和/或配置来实施,包括多点、点到点等。
66.图6示出了根据本公开的示例实施例的具有近数据处理能力的存储器模块的另一实施例。图6中示出的存储器模块604可以包括类似于图5中示出的组件,然而,一个或多个存储器设备610、近存储器计算模块612和/或总线结构614的多个实例可以被配置为例如多个级618。
67.在图6所示的实施例中,一个或多个总线结构614可以用分层总线架构来实施,分层总线架构可以在不同的级618之间以及在级内的存储器设备之间、在存储器设备和存储器通道接口616之间等传输数据。
68.图4至图6中示出的实施例不限于任何特定应用,并且可以用于实施多种处理方法、工作流等。然而,取决于实施方式细节,它们对于实施可能是存储器受限的和/或可能涉及细粒度存储器访问的数据处理应用(诸如k
‑
mer计数、dna播种(seeding)等)可能特别有
效。
69.为了说明本公开的原理,系统、存储器模块、近存储器计算模块、方法、工作流等的一些示例实施例可以在k
‑
mer计数应用的上下文中描述,并且具有一些特定的实施方式细节,诸如lrdimm、ddr存储器接口等。然而,这些原理不限于k
‑
mer计数应用,并且可以应用于各种各样的其他应用和/或可以用许多不同的实施方式细节来实现。
70.为了说明的目的,根据本公开的示例实施例,图7至图10共同示出了近数据处理系统的示例架构和可以与其一起使用的一些示例组件。
71.图7示出了根据本公开的示例实施例的近数据处理系统的示例实施例。图7所示的系统700可以包括主机cpu 702和一个或多个存储器控制器703,存储器控制器703被配置为实施ddr存储器通道,在图7所示的实施例中,ddr存储器通道可以包括存储器通道ch1、ch2、ch3和/或ch4。存储器通道中的一个或多个可以安装一个或多个dimm 704。图7中示出的组件的数量仅是说明性的,可以使用更少或更多的组件。为防止绘图变得模糊,可能不会显示所有组件。
72.图8示出了根据本公开的示例实施例的存储器模块的示例实施例。图8所示的实施例可以,例如,用于实施图7所示的任何dimm 704。图8所示的存储器模块804可以用,例如,lrdimm和近存储器计算模块824来实现,lrdimm可以包括一个或多个级820,每个级可以包括一个或多个存储器设备810。存储器模块804还可以包括寄存时钟驱动器(rcd)826和一个或多个数据缓冲器828,一个或多个数据缓冲器828可以共同形成存储器缓冲器。寄存时钟驱动器826可以缓冲和/或重复通过ddr存储器通道从主机(例如702)接收的命令和/或地址信号(c/a)。一个或多个数据缓冲器828可以缓冲去往和/或来自存储器设备810的数据信号dq,以保持和/或改善信号的完整性。存储器模块804可以通过卡边缘连接器物理连接到存储器通道(例如,ch1、ch2
……
)中的一个。
73.图9示出了根据本公开的示例实施例的存储器模块的级或其部分的更详细的示例实施例。图9所示的实施例可以用于,例如,实施图8所示的级820中的一个的虚线830所示的部分。图9所示的级920可以包括一个或多个存储器设备910,存储器设备910中的每一个可以具有用于存储具有输入dna序列的数据集的一部分的区域(dna),用于存储作为k
‑
mer计数操作的输出的一个或多个哈希表的一部分的区域(哈希(hash)),以及用于存储用于k
‑
mer计数操作的一个或多个布隆过滤器的区域(过滤器(filter))。
74.近存储器计算模块924可以包括一个或多个处理元件932和控制模块934,控制模块934可以包括存储器控制器936、工作负荷监视器938和/或总线控制器940中的一个或多个。近存储器计算模块924还可以包括用于处理元件932的输入缓冲器942和输出缓冲器944。输入缓冲器942可以通过多路复用器946耦合到分层总线结构914,以及输出缓冲器944可以通过多路分解器948耦合到分层总线结构914。多路复用器946和多路分解器948可以由来自控制模块934的一个或多个使能信号en控制。
75.存储器装置910可至少部分地响应于通过寄存时钟驱动器926从主机接收的一个或多个主机c/a信号,由控制模块934产生的一个或多个c/a信号和/或cs信号控制。数据可以通过数据总线914a传输到存储器设备910和/或从存储器设备910传输,数据总线914a可以是分层总线结构914的一部分。分层总线结构914可以通过一个或多个数据缓冲器928将级920耦合到ddr存储器通道。
76.图10示出了根据本公开的示例实施例的处理元件的示例实施例。图10所示的处理元件可以用于,例如,实施图9所示的任何处理元件932。图10所示的处理元件1032可以包括输入缓冲器1050和哈希模块1052,哈希模块1052可以从输入缓冲器1050接收输入,并且可以通过反馈连接1051向输入缓冲器1050提供反馈输出。处理元件1032还可以包括地址转换模块1054,该地址转换模块1054可以从哈希模块1052接收输入,并且向存储器控制器936和/或输出缓冲器944提供输出。
77.参考图7至图10,在一些实施例中,并且取决于实施方式细节,集中逻辑(诸如一个或多个处理元件)和/或控制功能(诸如存储器控制、工作负荷监视、工作负荷控制和/或每个级内的总线控制)可以改善每个级内的和/或级间的组件之间的通信和/或同步。集中逻辑还可以改善存储器访问管理、任务管理等。
78.分层总线的使用可以提高存储器模块内通信的速度和/或效率(例如,增强dimm内通信)和/或可以减少存储器模块之间的通信(例如,简化dimm间通信)。在一些实施例中,分层总线可以使得数据能够在存储器设备之间传输(例如,芯片间通信)。在一些实施例中,分层总线可以包括可以在同一存储器模块内的不同级之间传输c/a信号的级
‑
级c/a总线,和/或可以在同一存储器模块内的不同级之间传输数据的级
‑
级数据总线。在一些实施例中,利用一个或多个级间总线,可以在本地实现dimm内通信,而无需通过存储器通道向主机发送数据,这可以减少或消除通信瓶颈的来源。
79.参考图9,在一些实施例中,每个近存储器计算模块内的处理元件(pe)932的数量可以是可配置的。处理元件932可以从输入缓冲器942读取输入数据,并将输出数据写入近存储器计算模块924中的输出缓冲器944。在一些实施例中,处理元件932中的一个或多个可以被配置为并行处理多个相对小的数据单元和/或实施一个或多个特定算法或其部分。例如,在一些实施例中,处理元件932中的一个或多个的主要功能可以是将一个或多个哈希函数(例如,murmurhash3)应用于输入数据,例如,从存储在存储器设备910中的dna序列数据集的一部分读取的k
‑
mer。
80.参考图10,在处理元件1032的一些实施例中,缓冲器1050可以存储来自dna序列的输入k
‑
mer,哈希模块1052可以包括对k
‑
mer执行一个或多个哈希函数的逻辑(例如,独立具有功能),并且地址转换模块1054可以包括将虚拟地址转换成本地存储器设备(例如,dram)地址的逻辑。在一些实施例中,地址转换模块1054可以用于至少部分地实施地址映射方案,以分布细粒度数据,例如,以提高存储器带宽利用率。
81.参考图9,在一些实施例中,存储器控制器936可以协调来自主机和一个或多个处理元件932的对一个或多个存储器设备910的访问。主机侧存储器控制器(例如,图7中的存储器控制器703之一)和一个或多个近存储器计算模块924内的存储器控制器936之间的协调可以例如利用主机优先的请求调度来实施。
82.在一些实施例中,主机侧存储器控制器可能不知道存储器模块中的模块侧存储器控制器936可以向存储器设备910发送请求。因此,如果主机侧存储器控制器和模块侧存储器控制器936两者都向存储器设备910中第一个发送重叠(overlapping)请求,则可能出现定时问题。主机优先的请求调度可以解决这种类型的定时问题,例如,通过在主机侧实施关闭页面策略,为模块侧实施主机优先的请求调度。例如,利用关闭页面策略,主机侧存储器控制器可以期望其对存储器设备910的存储器请求符合一个或多个ddr定时约束。因为模块
侧存储器控制器936可以向存储器设备910发出请求,所以来自主机侧存储器控制器的存储器请求的时延可能是不可预测的,因此可能与一个或多个ddr定时约束冲突。因此,一旦存储器设备910完成当前任务,主机优先的请求调度就可以服务来自主机的存储器请求。在一些实施例中,可以修改一个或多个主机侧ddr定时参数,使得主机侧存储器管理器可以具有更长的数据返回时间预期,以允许模块侧存储器控制器936调度请求。
83.工作负荷监视器938可以监视和/或与输入缓冲器942和/或一个或多个处理元件932协作,以例如在k
‑
mer计数期间平衡处理元件的工作负荷,这可以提高处理元件932的利用率。
84.可以被实施为例如总线仲裁器的总线控制器940可以调节分层总线结构914上的数据和/或c/a传输。在一些实施例中,总线控制器940可以将分层总线结构的资源分配给一个或多个处理元件932。
85.近数据处理工作流
86.图11a至图11c示出了根据本公开的示例实施例的k
‑
mer计数工作流的示例实施例。图11a示出了根据本公开的示例实施例的第一布隆过滤器构建操作和第二布隆过滤器构建操作的实施例。图11b示出了根据本公开的示例实施例的第一和第二合并操作的实施例。图11c示出了根据本公开的示例实施例的计数操作的实施例。出于说明的目的,图11a至图11c所示的实施例可以在图7所示的系统的上下文中描述,但是工作流可以与任何合适的系统一起使用。图11a至图11c所示的实施例可以各自包括主机cpu 1102、一个或多个存储器控制器1103以及一个或多个存储器模块1104。
87.为了在k
‑
mer计数工作流中实现并行处理,可以包括例如dna序列的输入数据集可以被均匀地分割成可以被分布到不同存储器模块1104的部分,在该示例中,存储器模块1104可以被实施为dimm。在第一布隆过滤器构建操作
①
期间,如图11a所示,每个存储器模块1104可以独立地构建第一本地布隆过滤器,如箭头所示。在操作期间,每个存储器模块可以读取数据集的本地部分,并使用数据来构建也可以本地存储的第一本地布隆过滤器。在此操作期间,可以通过使用任务分割和/或数据本地化来减少或消除模块间通信。
88.在完成第一布隆过滤器构建之后,可以在第一合并操作
②
期间简化和分散本地布隆过滤器,第一合并操作
②
可以同步不同存储器模块1104中的布隆过滤器,如图11b所示。在一些实施例中,布隆过滤器可以仅包含0和1,因此,布隆过滤器可以如无阴影箭头所示被简化,例如,通过在对应的布隆过滤器条目之间使用or运算。在简化之后,简化的布隆过滤器可以如阴影箭头所示被分散,例如,通过向存储器模块1104广播简化的布隆过滤器。在一些实施例中,简化和/或分散操作可以仅涉及数据传输的顺序读取和/或写入操作。
89.在存储器模块1104中的第一布隆过滤器同步之后,每个存储器模块1104可以在第二布隆过滤器构建操作
③
期间独立地和/或并行地构建第二布隆过滤器,如图11a中的箭头所示。该操作可以类似于第一布隆过滤器构建操作,除了存储器模块可以使用来自第一合并操作的合并的布隆过滤器作为输入来构建第二布隆过滤器。在每个存储器模块1104处构建的第二布隆过滤器可以本地存储在对应的存储器模块处。如同第一布隆过滤器构建操作一样,可以通过使用任务分割和/或数据本地化来减少或消除模块间通信。
90.在构建第二布隆过滤器之后,第二布隆过滤器可以在第二合并操作
④
期间被简化和分散,第二合并操作
④
可以同步不同存储器模块1104中的第二布隆过滤器,如图11b所
示。在一些实施例中,第二布隆过滤器可以仅包含0和1,因此,第二布隆过滤器可以如无阴影箭头所示被简化,例如,通过在对应的布隆过滤器条目之间使用or运算。在简化之后,第二简化的布隆过滤器可以如阴影箭头所示被分散,例如,通过向存储器模块1104广播简化的布隆过滤器。如同第一合并操作一样,在一些实施例中,第二简化和/或分散操作可以仅涉及数据传输的顺序读取和/或写入操作。
91.在完成第二布隆过滤器的构建之后,每个存储器模块1104可以包含第二布隆过滤器的副本。然后,可以在存储器模块处并行执行k
‑
mer计数操作。在k
‑
mer计数操作期间,对于每个k
‑
mer,存储器模块可以如图11c中无阴影箭头所示的首先检查第二布隆过滤器,以确定当前k
‑
mer是否是非独特的。如果当前k
‑
mer是非独特的,则可以如图11c中阴影箭头所示的访问哈希表中对应于当前k
‑
mer的条目并且增加1,该条目可以在不同的存储器模块1104中分布。在一些实施例中,该操作可以减少或消除模块间通信,例如,因为模块间通信可以仅用于已验证的非独特的k
‑
mer。
92.因此,在图11a至图11c所示的实施例中,取决于实施方式细节,用于k
‑
mer计数的处理可以由存储器模块1104并行执行。此外,第一布隆过滤器和第二布隆过滤器的本地构建可以提高系统性能,因为它可能涉及很少或不涉及模块间通信。第一布隆过滤器和第二布隆过滤器的简化和分散可能仅涉及连续的顺序读取和/或写入操作,这可能对性能影响很小或没有影响。此外,在k
‑
mer计数操作期间,通过检查可以本地存储的第二布隆过滤器,可以避免不必要的模块间存储器访问。
93.在一些实施例中,并且取决于实施方式细节,在输入数据集可以被分布到多个存储器模块的系统和/或工作流中串联使用两个布隆过滤器可能导致一个或多个漏报结果。这可以在图12中示出,在图的左侧示出了使用全局数据集的k
‑
mer计数方法。包括3
‑
mer atc的三个实例的dna序列1211可以作为输入被应用,而无需任何分割。第一全局布隆过滤器1213可以读取atc3
‑
mer的三个实例,并将3
‑
mer传递给第二全局布隆过滤器1215,因为第一全局布隆过滤器1213可以识别atc 3
‑
mer是非独特的。第二全局布隆过滤器1215然后可以增加哈希表1217中对应于atc 3
‑
mer的计数。
94.然而,如果包括dna序列的数据集被分布到三个不同的存储模块,并且如图12右侧所示,只有atc 3
‑
mer1211a的一个实例被分布到每个存储模块,则每个存储模块处的第一本地布隆过滤器1219可以确定atc 3
‑
mer是独特的,因此不将atc 3
‑
mer传递给存储模块处的第二本地布隆过滤器1221。因此,在最终哈希表1223中可能没有atc 3
‑
mer的条目。
95.在一些实施例中,可以通过在每个存储器模块处使用计数布隆过滤器来减少或消除漏报。计数布隆过滤器可以以类似于具有单比特阵列的布隆过滤器的方式使用n个独立的哈希函数。然而,计数布隆过滤器可以包含与可以由n个哈希函数计算的可能哈希值相对应的计数器阵列,而不是单比特阵列。例如,具有4比特计数器阵列的计数布隆过滤器可以能够跟踪特定的k
‑
mer的零到15个实例。因此,对于特定的k
‑
mer(x),如果n=3,则对应于所计算的哈希值h1(x)、h2(x)和h3(x)的计数器可以各自增加1。为了在计数布隆过滤器中查找特定的k
‑
mer,可以使用n个独立的哈希函数来计算特定的k
‑
mer的n个哈希值,并且可以读取对应于所计算的哈希值的计数器。具有最小计数的计数器的值可以被假设为特定的k
‑
mer的实例的数量。
96.图13示出了根据本公开的示例实施例的k
‑
mer计数方法工作流的实施例。在图13
所示的实施例中,包括atc 3
‑
mer的三个实例的数据集可以被分布到三个不同的存储器模块,并且只有atc 3
‑
mer 1311的一个实例可以被分布到每个存储器模块。然而,每个存储器模块可以包括本地计数布隆过滤器1319,其可以对atc的一个实例进行计数,并且计数1可以被传递到全局布隆过滤器1321。因此,atc可以被识别为非独特的3
‑
mer,并被添加到最终哈希表1323。
97.图14a至图14c示出了根据本公开的示例实施例的使用计数布隆过滤器的k
‑
mer计数工作流的示例性实施例。图14a示出了根据本公开的示例实施例的计数布隆过滤器构建操作的实施例。图14b示出了根据本公开的示例实施例的合并操作的实施例。图14c示出了根据本公开的示例实施例的计数操作的实施例。图14a至图11c所示的实施例可以各自包括主机cpu 1402、一个或多个存储器控制器1403以及一个或多个存储器模块1404。出于说明的目的,图14a至图14c所示的实施例可以在图7所示的系统的上下文中描述,但是工作流可以与任何合适的系统一起使用。
98.与图11a至图11c所示的实施例一样,为了能够在图14a至图14c所示的实施例中的k
‑
mer计数工作流中进行并行处理,可以包括例如dna序列的输入数据集可以被均匀地分割成可以被分布到不同的存储器模块1404的部分,在该示例中,存储器模块1404可以被实施为dimm。在如图14a所示的计数布隆过滤器构建操作期间,每个存储器模块1404可以独立地构建本地计数布隆过滤器,如箭头所示。在此操作期间,每个存储器模块可以读取数据集的本地部分,并且使用数据来构建本地计数布隆过滤器,本地计数布隆过滤器也可以本地存储。在此操作期间,可以通过使用任务分割和/或数据本地化来减少或消除模块间通信。
99.在完成计数布隆过滤器构建之后,可以在合并操作期间简化和分散本地计数布隆过滤器,合并操作可以同步不同存储器模块1404中的计数布隆过滤器,如图14b所示。在一些实施例中,计数布隆过滤器可以通过如无阴影箭头所示的添加计数布隆过滤器的对应条目(例如,计数器)来简化。在已经添加条目之后,如果简化的布隆过滤器中的计数器条目大于2,则合并的布隆过滤器中的对应条目可以被设置为1,否则可以被设置为零。在一些实施例中,合并的计数布隆过滤器可以通过如阴影箭头所示的将合并的布隆过滤器分布到每个存储器模块1404来分散。在一些实施例中,简化和/或分散操作可以仅涉及数据传输的顺序读取和/或写入操作。
100.在分散合并的布隆过滤器之后,每个存储器模块1404可以包含合并的布隆过滤器的副本。然后可以在存储器模块1404处并行执行k
‑
mer计数操作。在k
‑
mer计数操作期间,对于每个k
‑
mer,存储器模块可以首先如无阴影箭头所示的检查第二布隆过滤器,以确定当前k
‑
mer是否是非独特的。如果当前k
‑
mer是非独特的,则可以如阴影箭头所示的访问哈希表中对应于当前k
‑
mer的条目并且增加1,该条目可以在不同的存储器模块1404中分布。在一些实施例中,该操作可以减少或消除模块间通信,例如,因为模块间通信可以仅用于已验证的非独特的k
‑
mer。
101.因此,在图14a至图14c所示的实施例中,取决于实施方式细节,用于k
‑
mer计数的处理可以由存储器模块1404并行执行。此外,计数布隆过滤器的本地构建可以提高系统性能,因为它可以涉及很少或没有模块间通信。计数布隆过滤器的简化和分散可能仅涉及对性能影响很小或没有影响的连续顺序读取和/或写入操作。此外,在k
‑
mer计数操作期间,通过检查可以本地存储的合并的布隆过滤器,可以避免不必要的模块间存储器访问。
102.在一些实施例中,并且取决于实施方式细节,根据本公开的示例实施例的系统、方法和/或设备可以通过实施可以减少或消除不必要的模块间存储器访问的工作流来减少或防止通信瓶颈,例如,通过将用于k
‑
mer计数的输入数据集分割成多个分区,并且将分区和/或分区上的操作本地化到可以以很大程度的并行性来操作的多个存储器模块中。在一些实施例中,并且取决于实施方式细节,根据本公开的示例实施例的系统、方法和/或设备可以通过实施可以包括级间c/a总线和/或级间数据总线的分层总线来减少或防止通信瓶颈,从而减少或最小化模块间通信。
103.带宽利用率
104.图15a示出了根据本公开的示例实施例的存储器设备的地址映射的实施例。图15a所示的映射可以从最高有效位(msb)位置处的2比特通道地址开始,随后是4比特级地址、4比特设备地址、4比特存储体(bank)地址、16比特行地址、10比特列地址、3比特突发地址和最低有效位(lsb)位置处的2比特宽度。图15a所示的映射可以合并存储器设备内的数据,在一些实施例中,这可以利用数据本地性。然而,诸如k
‑
mer计数的应用可能涉及大量的细粒度(例如,1比特或2比特)随机存储器访问,这可能具有很少或没有本地性。因此,取决于实施方式细节,存储器带宽可能未得到充分利用。
105.根据本公开的示例实施例的一些实施例可以实施分布式数据映射方案,以跨存储器设备、级、存储器模块等分布数据。
106.图15b示出了根据本公开的示例实施例的存储器设备的地址映射的另一实施例。图15b所示的映射可以从msb位置处的2比特通道地址开始,然后是16比特行地址、4比特存储体地址、4比特级地址、4比特设备地址、10比特列地址、3比特突发地址和lsb位置处的2比特宽度。图15b中所示的映射可以对存储器设备的地址比特进行重新排序,以将在不同的存储器设备(例如,dram芯片)中的分布数据进行优先级排序。取决于实施方式细节,这可以提高存储器带宽利用率,例如,通过减少或消除存储器设备、级、存储器模块等内的数据的集中。
107.工作负荷平衡
108.在一些实施例中,诸如图9所示的工作负荷监视器938的工作负荷监视器可以基于监视一个或多个计算资源的工作负荷来实施任务调度方案。例如,任务调度方案可以平衡近存储器计算模块924中的处理元件932之间的工作负荷。
109.在一些实施例中,任务调度方案可以利用输入缓冲器942作为到来的任务的队列。工作负荷监视器938可以监视一个或多个处理元件932和输入缓冲器942的状态。如果处理元件932中的一个完成了任务,则工作负荷监视器938可以从输入缓冲器942中选择输入数据单元,并将其作为任务分派给处理元件932,以使其保持忙碌。因此,在一些实施例中,工作负荷监视器938可以通过以细粒度向处理元件932动态分派任务来实施任务调度方案。取决于实施方式细节,这可以提高一个或多个计算资源的利用率。
110.冗余存储器访问
111.图16a示出了根据本公开的示例实施例的布隆过滤器的第一次存储器访问方法的示例实施例。图16a所示的实施例可以使用四个哈希函数(n=4)。因此,可以为每个k
‑
mer检查四个布隆过滤器条目。在k
‑
mer计数操作期间,可以检查合并的布隆过滤器中与当前k
‑
mer相关的所有布隆过滤器条目,以验证它们是1。如果所有对应的布隆过滤器条目都是1,
则哈希表可以被更新。否则,不能执行写入操作。然而,在一些实施例中,合并的布隆过滤器的顺序存储器访问可能导致如下所述的浪费的存储器带宽。
112.在图16a所示的实施例中,合并的布隆过滤器的存储器访问可以针对每个任务顺序地发布(对于每个k
‑
mer,这可以由不同的处理元件来执行)。图16a中的顶部序列示出了布隆过滤器访问的序列,其中对相同任务(k
‑
mer和处理元件)的请求用相同类型的阴影表示。图16a中的底部序列示出了针对每个读取请求返回给处理元件的数据,其中特定任务返回的数据用与任务相同类型的阴影表示。因此,对于每个k
‑
mer的四次存储器访问可以顺序地发出,并且数据也可以顺序地返回。
113.为第一任务返回的第一布隆过滤器条目(没有阴影表示)可以是零。然而,如果第一条目是零,则接下来的三个条目(由粗轮廓表示)可能是不相关的(例如,“不关心”术语)。因此,接下来的三次访问可能是不必要的,并且可能浪费存储器带宽。
114.一些实施例可以实施分散的存储器访问和/或任务切换方案。例如,一个任务的存储器访问可以与一个或多个其他任务的存储器访问交错。取决于实施方式细节,这可以减少或消除不可用的数据访问。附加地或可替代地,任务可以在存储器访问之间切换,例如,用可用数据的访问来填充存储器访问时隙。取决于实施方式细节,这可以提高存储器带宽利用率。
115.图16b示出了根据本公开的示例实施例的布隆过滤器的第二存储器访问方法的示例实施例。在图16b所示的实施例中,不同任务(k
‑
mer和布隆过滤器)的存储器访问可以是分散的和/或以时间间隔发布的。例如,特定任务的后续存储器访问只能在所有先前访问都返回1的情况下发出。因此,如图16b所示,在前两个任务的第一访问之后,可以不发出后续存储器访问,因为前两个任务的每一个的第一访问返回0。然而,因为第三任务的第一存储器访问可以返回1,所以第三任务的第二存储器访问(bf
‑
1)可以在时间间隔之后发出。在一些实施例中,并且取决于实施方式细节,这可以减少或消除冗余存储器访问和/或更有效地利用可用的存储器带宽。
116.尽管冗余存储器访问可以随着分散的存储器访问而减少或消除,但是在一些实施例中,存储器带宽仍然可能被浪费,例如,由于缺少存储器访问来填充任务的存储器访问之间的时间间隔。因此,一些实施例可以在存储器访问之间切换任务,如图16b所示。例如,在为第一k
‑
mer的第一任务发布存储器访问之后,处理元件可以切换到属于第二k
‑
mer的第二任务,同时等待第一任务的返回数据。因此,分散的存储器访问之间引起的时间间隔可以用属于不同任务和/或处理元件的存储器访问来填充。在一些实施例中,并且取决于实施方式细节,这可以进一步提高存储器带宽利用率。在一些实施例中,分散的存储器访问和任务切换的组合可以产生协同效应,其可以减少或消除冗余的存储器访问和/或有效地利用存储器带宽。
117.图17示出了根据本公开的示例实施例的处理数据集的方法的实施例。图17所示的实施例可以从操作1702处开始。在操作1704处,方法可以将数据集的第一部分分布到第一存储器模块。在操作1706处,方法可以将数据集的第二部分分布到第二存储器模块。在操作1708处,方法可以基于数据集的第一部分在第一存储器模块处构建第一本地数据结构。在操作1710处,方法可以基于数据集的第二部分在第二存储器模块处构建第二本地数据结构。在操作1712处,方法可以合并第一本地数据结构和第二本地数据结构。方法可以在操作
1714处结束。
118.图17中示出的实施例以及本文描述的所有其他实施例是示例操作和/或组件。在一些实施例中,可以省略一些操作和/或组件,和/或可以包括其他操作和/或组件。此外,在一些实施例中,操作和/或组件的时间和/或空间顺序可以变化。虽然一些组件和/或操作可以被示为单独的组件,但是在一些实施例中,分离地示出的一些组件和/或操作可以被集成到单个组件和/或操作中,和/或示为单个组件和/或操作的一些组件和/或操作可以用多个组件和/或操作来实施。
119.上面公开的实施例已经在各种实施方式细节的上下文中进行了描述,但是本公开的原理不限于这些或任何其他具体细节。例如,一些功能已经被描述为由某些组件实施,但是在其他实施例中,功能可以分布在不同位置的不同系统和组件之间,并且具有各种用户界面。某些实施例已经被描述为具有特定的过程、操作等,但是这些术语也包括其中特定的过程、操作等可以用多个过程、操作等来实施,或者其中多个过程、操作等可以被集成到单个过程、步骤等中的实施例。对组件或元素的引用可以仅指组件或元素的一部分。例如,对集成电路的引用可以指集成电路的全部或仅一部分,对块的引用可以指整个块或一个或多个子块。在本公开和权利要求中使用诸如“第一”和“第二”的术语可能仅仅是为了区分它们所修饰的事物,并且可能不指示任何空间或时间顺序,除非从上下文中明显看出。在一些实施例中,对事物的引用可以指事物的至少一部分,例如,“基于”可以指“至少部分基于”,“访问”可以指“至少部分访问”等。对第一元件的引用并不意味着第二元件的的存在。为了方便起见,可以提供各种组织辅助,诸如节标题等,但是根据这些辅助布置的主题和本公开的原理不限于这些组织辅助。
120.根据本专利公开的发明原理,上述各种细节和实施例可以被组合以产生附加的实施例。由于本专利公开的发明原理可以在不脱离本发明构思的情况下在布置和细节上进行修改,因此这种改变和修改被认为落入所附权利要求的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。