1.本发明涉及人工智能和单目标追踪领域,特别涉及一种基于动态全局信息建模和孪生网络的单目标跟踪算法,可用于提高单目标追踪的准确度和实时性。
背景技术:
2.视觉目标追踪是计算机视觉领域重要的分支。它的目的是在人为给出目标第一帧位置的情况下,自动地,精确地和快速地定位后续帧中目标的位置。该任务的主要挑战是物体遮挡、目标模糊、快速移动、形变、光照变化。在保证追踪器达到实时性的前提下,目标跟踪技术在很多领域得到了应用,比如视频监控,人机交互,无人驾驶。
3.目前的主流目标追踪算法算法,比如siamrpn算法在网络中加入了区域建议结构,它由模板分支和检测分支组成,实现离线端到端训练。它采用anchor
‑
based策略,尽管能较为准确地预测出物体的位置,但是因为区域建议结构的存在,跟踪器对锚框的数目,尺度,长宽比都非常敏感,对这些参数调节非常困难,且耗费人力;siamfc 算法基于anchor
‑
free策略,它不依赖过多的先验知识,并自适应回归目标的位置。然而它也存在问题:它忽视了不同尺度和长宽比目标对感受野的需求区别,以及没有对全局上下文信息建模,这会造成在复杂的场景下,如物体形状多变、快速移动、遮挡时追踪失败。
技术实现要素:
4.本发明针对现有的主流单目标跟踪算法存在的调参困难、感受野固定、缺乏全局信息建模等缺点,设计了一种基于动态全局信息建模和孪生网络的单目标跟踪算法,以提升在困难场景下目标追踪的成功率和准确率。
5.实现本发明的技术方案如下:
6.一种基于动态全局信息建模和孪生网络的单目标跟踪算法,其特征在于,包括以下步骤:
7.步骤s1:获取训练集和测试集,并对训练集预处理;
8.步骤s2:网络搭建,设计损失函数并训练;
9.步骤s3:根据步骤s1和s2得到的网络,用测试集测试准确率、成功率、期望平均重叠率等参数来验证算法效果;
10.所述步骤s1进一步包括:
11.步骤s11:将训练集原图片以目标物体为中心分别切割成127
×
127和255
×
255的新图片各一张。新图片中超出原图片的部分用通道均值像素补足;
12.步骤s12:把s11生成的训练集图片信息,包括图片路径、目标物体左上角坐标、目标物体右下角坐标转换成json格式保存。训练阶段就能根据保存的图片路径读取图片,同时获取目标物体的大小和位置信息;
13.所述步骤s2进一步包括:
14.步骤s21:孪生子网络搭建,采用经过修改的网络模型resnet50网络作为特征提取
骨架网络,该模型先经过7
×
7的卷积,然后经过3
×
3的最大值池化层,最后经过3个大卷积组,这3个卷积组分别包含了3、4、6个bottleneck模块,每个bottleneck内依次包含1
×
1、3
×
3、1
×
1的卷积;
15.步骤s22:分类
‑
回归和交并比(iou)预测子网络搭建;
16.所述步骤s22进一步包括:
17.步骤s221:动态全局信息建模模块构建,该模块由split,fuse和select这3个部分组成;在split部分,输入特征x分别并行地经过1
×
3、3
×
3和3
×
1卷积,得到特征u
a
、u
b
和u
c
,3个分支的卷积核的尺寸不同,特征u
a
、u
b
和u
c
按权值进行融合。这么做的目的是让追踪器更灵活,能根据目标的尺寸和长宽比动态选择感受野;在fuse部分,对同一帧图中任意距离的两个像素点信息建模,得到向量s,向量s的通道数从256减少至32,得到向量z。这部分的主要功能是对经过建模输出的全局信息转变后赋值给不同的通道,用公式表示为:
[0018][0019]
其中δ代表非线性激活函数,代表批量正则化。其中w∈r
32
×
256
。向量z经过softmax算子得到特征u
a
、u
b
和u
c
的软注意力向量v
a
、v
b
和v
c
;在select部分,软注意力向量v
a
、v
b
和v
c
分别和特征矩阵u
a
、u
b
和u
c
相乘后取和,得到特征v;
[0020]
步骤s222:分类
‑
回归分支构建,2个分支的结构是一样的,由4个大小3
×
3的卷积核组成;
[0021]
步骤s223:交并比预测模块构建,该模块作用是预测真实框和预测框之间的交并比(iou)。用公示表示如下:
[0022][0023]
其中b
*
代表真实框,b代表预测框;
[0024]
步骤s224:分类预测模块构建,该模块输出特征图p
cls
,主要作用是预测特征点映射回原图的区域是目标的概率;
[0025]
步骤s225:回归预测模块构建,该模块输出特征图p
reg
,主要作用是预测目标框的位置;
[0026]
步骤s23:网络训练,输入一对大小分别为127
×
127和255
×
255的模板图和搜索图到共享权重的resnet50模型,输出特征矩阵a1和a2,大小分别是15
×
15和31
×
31,通道数均为256;a1和a2经过动态全局信息建模模块后做交叉卷积,得到分类分支输入a
cls
和回归分支输入a
reg
,大小都是25
×
25,通道数为256。a
reg
经回归分支的卷积组后得到特征图p
iou
和p
reg
,p
iou
大小25
×
25,通道数为1,它预测真实框和预测框之间的交并比,p
reg
大小25
×
25,通道数为4,它指示预测框的位置。a
cls
经过分类分支卷积组后得到特征图p
cls
,它的大小25
×
25,通道数为1,它预测特征点映射回原图的区域是目标的概率;
[0027]
步骤s24:通过计算损失函数,将其作为参考通过反向传播算法训练神经网络,优化相应的权重偏置等参数,让卷积神经网络更好地实现追踪,最终实现训练样本的完美拟合。损失函数由3部分组成:
[0028]
[0029][0030][0031]
其中i{
·
}是个指示函数,如果条件满足则它的值为1,否则为0。代表特征图上点(i,j)的状态:
[0032][0033]
对于分类任务和预测交并比任务,我们采用二值交叉熵损失函数,和和代表真实标签。内部是离散的值,代表特征图上点(i,j)的状态而是连续值,代表预测真实框和预测框之间的交并比。
[0034]
最终,我们把这3项损失结合,得到总损失函数如下:
[0035][0036]
在训练模型过程中,分别设置λ1=1和λ2=1.2。
[0037]
所述步骤s3进一步包括:
[0038]
步骤s31:获取测试视频,将视频解析成图片帧,所有图片按照时间先后命名(如第一帧图片命名为00001.jpg),并放在同一个文件夹下;
[0039]
步骤s32:第一帧图片作为模板图输入网络;
[0040]
步骤s33:后续帧图片作为搜索图输入网络,并预测目标在每一帧图片中的位置;
[0041]
步骤s34:通过每一帧目标位置的预测,得到追踪的成功率和准确率,其中成功率需要计算预测框和真实目标框的重叠率,准确率需要计算预测框和真实目标框的中心偏移距离。
[0042]
上述技术方案中,具体实现过程如下:
[0043]
(1)网络搭建。本发明采用经过修改的卷积神经网络模型resnet50网络作为特征提取网络骨架,它先经过7
×
7的卷积,然后经过3
×
3的最大值池化层,最后经过3个大卷积组,这3个卷积组分别包含了3、4、6个bottleneck模块,每个bottleneck内依次包含1
×
1、3
×
3、1
×
1的卷积。输入一对大小分别是127
×
127和255
×
255的图片到共享权值的网络骨架,输出的2张特征图进入分类
‑
回归和交并比(iou)预测子网络,经过该子网络动态感受野融合和全局信息建模,最终输出分类图、回归图和iou预测图;
[0044]
(2)网络构成。特征提取网络选用经过修改的卷积神经网络模型resnet50,分类
‑
回归和交并比(iou)预测子网络包括了动态全局信息建模模块、分类
‑
回归分支、分类预测模块、回归预测模块和交并比预测模块;
[0045]
(3)网络训练。输入n对大小分别为127
×
127和255
×
255的模板图和搜索图到共享权重的resnet50模型,得到特征图,随后将2张特征图输入分类
‑
回归和交并比(iou)预测子网络,最终得到分类图、回归图和iou预测图。为达到更短的训练时间和更好的训练效果的目标,在训练网络之前,先加载resnet50针对imagenet数据集的预训练参数。
[0046]
(4)通过计算损失函数,将其作为参考通过反向传播算法训练卷积神经网络,优化
相应的权重偏置等参数,让卷积神经网络更好地提取特征,最终实现训练样本的完美拟合。
[0047]
(5)在测试阶段,使用了主流的目标追踪测试集,如vot2019,otb100,got
‑
10k。使用不同的测试集,并且保证测试所用的图片没有出现在训练集中。在多个主流算法上进行验证,获取成功率和准确率等信息。
[0048]
与现有技术相比,本发明具有如下技术效果:
[0049]
(1)本发明采用修改后的resnet
‑
50作为网络骨架以获取更加丰富的信息。无先验box的设计,避免了繁杂的超参数设置,也让追踪器更加灵活,网络结构简单,但是取得不错的效果。
[0050]
(2)本发明采用的的动态全局信息建模模块提供x维度和y维度不同尺寸和比例的卷积核,让我们的追踪器能根据不同的目标自适应的选择卷积核来满足不同的感受野需求。同时内嵌的全局信息建模模块能捕获目标的长距离依赖,完成全局信息建模。
[0051]
(3)本发明引入的和回归分支共享权重的iou预测分支,降低离目标远的预测框的权重,间接增加分类了分支的鲁棒性。
[0052]
(4)如图4、图5、图6所示,我们的追踪器在包括vot2019,otb100,got
‑
10k在内的测试数据集上均超过现有的主流算法,如siamfc,siamrpn等,且能跑到65fps,保证实时性。
附图说明
[0053]
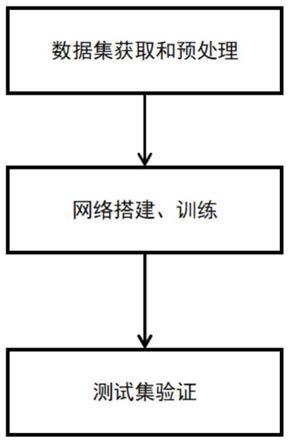
图1为本发明一方法实施例训练流程图;
[0054]
图2为本发明一方法实施例整体网络结构图;
[0055]
图3为本发明一方法实施例动态全局信息建模结构图;
[0056]
图4为本发明一方法实施例在测试集vot2019上测得的期望平均重叠率(eao)和其他算法的对比图;
[0057]
图5为本发明一方法实施例在测试集otb100上测得的准确率、成功率和其他算法的对比图;
[0058]
图6为本发明一方法实施例在测试集got
‑
10k上测得的成功率和其他算法的对比图;
具体实施方式
[0059]
为使本发明的目的、技术方案和优点更加清楚,以下结合具体的实例,并参照附图,对本发明作进一步的描述。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提,还可以做出若干变形和改进。这些都属于本发明的保护范围。
[0060]
本发明是一种基于动态全局信息建模和孪生网络的单目标跟踪算法,搭建孪生网络作为主干网络,投入经过预处理的数据集进行训练,然后根据输出的响应图确定目标物体在视频序列中的位置。本发明同时结合了动态全局信息建模算法,它能根据物体的尺寸和长宽比动态地调整网络感受野,同时它能对全局特征图中任意两点信息建模,在小幅度提升网络复杂度的情况下,大大提升追踪的准确性,同时也保证了实时性。
[0061]
如图1所示,本发明包括3大步骤,步骤s1:获取训练集和测试集,并对训练集预处理;步骤s2:网络搭建,设计损失函数并训练;步骤s3:根据步骤s1和s2得到的网络,用测试集验证算法效果;下面是追踪算法具体过程进行详细阐述如下:
[0062]
步骤s1:获取训练集和测试集,并对训练集预处理;
[0063]
步骤s2:网络搭建,设计损失函数并训练;
[0064]
步骤s3:根据步骤s1和s2得到的网络,用测试集测试准确率、成功率、期望平均重叠率等参数来验证算法效果;
[0065]
所述步骤s1进一步包括:
[0066]
步骤s11:将训练集原图片以目标物体为中心分别切割成127
×
127和255
×
255的新图片各一张。新图片中超出原图片的部分用通道均值像素补足;
[0067]
步骤s12:把s11生成的训练集图片信息,包括图片路径、目标物体左上角坐标、目标物体右下角坐标转换成json格式保存。训练阶段就能根据保存的图片路径读取图片,同时获取目标物体的大小和位置信息;
[0068]
所述步骤s2进一步包括:
[0069]
步骤s21:孪生子网络搭建,采用经过修改的网络模型resnet50网络作为特征提取骨架网络,该模型先经过7
×
7的卷积,然后经过3
×
3的最大值池化层,最后经过3个大卷积组,这3个卷积组分别包含了3、4、6个bottleneck模块,每个bottleneck内依次包含1
×
1、3
×
3、1
×
1的卷积;
[0070]
步骤s22:分类
‑
回归和交并比(iou)预测子网络搭建;
[0071]
所述步骤s22进一步包括:
[0072]
步骤s221:动态全局信息建模模块构建,该模块由split,fuse和select这3个部分组成;在split部分,输入特征x分别并行地经过1
×
3、3
×
3和3
×
1卷积,得到特征u
a
、u
b
和u
c
,3个分支的卷积核的尺寸不同,特征u
a
、u
b
和u
c
按权值进行融合。这么做的目的是让追踪器更灵活,能根据目标的尺寸和长宽比动态选择感受野;在fuse部分,对同一帧图中任意距离的两个像素点信息建模,得到向量s,向量s的通道数从256减少至32,得到向量z。这部分的主要功能是对经过建模输出的全局信息转变后赋值给不同的通道,用公式表示为:
[0073][0074]
其中δ代表非线性激活函数,代表批量正则化。其中w∈r
32
×
256
。向量z经过softmax算子得到特征u
a
、u
b
和u
c
的软注意力向量v
a
、v
b
和v
c
;在select部分,软注意力向量v
a
、v
b
和v
c
分别和特征矩阵u
a
、u
b
和u
c
相乘后取和,得到特征v;
[0075]
步骤s222:分类
‑
回归分支构建,2个分支的结构是一样的,由4个大小3
×
3的卷积核组成;
[0076]
步骤s223:交并比预测模块构建,该模块作用是预测真实框和预测框之间的交并比(iou)。用公示表示如下:
[0077][0078]
其中b
*
代表真实框,b代表预测框;
[0079]
步骤s224:分类预测模块构建,该模块输出特征图p
cls
,主要作用是预测特征点映射回原图的区域是目标的概率;
[0080]
步骤s225:回归预测模块构建,该模块输出特征图p
reg
,主要作用是预测目标框的位置;
[0081]
步骤s23:网络训练,输入一对大小分别为127
×
127和255
×
255的模板图和搜索图
到共享权重的resnet50模型,输出特征矩阵a1和a2,大小分别是15
×
15和31
×
31,通道数均为256;a1和a2经过动态全局信息建模模块后做交叉卷积,得到分类分支输入a
cls
和回归分支输入a
reg
,大小都是25
×
25,通道数为256。a
reg
经回归分支的卷积组后得到特征图p
iou
和p
reg
,p
iou
大小25
×
25,通道数为1,它预测真实框和预测框之间的交并比,p
reg
大小25
×
25,通道数为4,它指示预测框的位置。a
cls
经过分类分支卷积组后得到特征图p
cls
,它的大小25
×
25,通道数为1,它预测特征点映射回原图的区域是目标的概率;
[0082]
步骤s24:通过计算损失函数,将其作为参考通过反向传播算法训练神经网络,优化相应的权重偏置等参数,让卷积神经网络更好地实现追踪,最终实现训练样本的完美拟合。损失函数由3部分组成:
[0083][0084][0085][0086]
其中i{
·
}是个指示函数,如果条件满足则它的值为1,否则为0。代表特征图上点(i,j)的状态:
[0087][0088]
对于分类任务和预测交并比任务,我们采用二值交叉熵损失函数,和和代表真实标签。内部是离散的值,代表特征图上点(i,j)的状态而是连续值,代表预测真实框和预测框之间的交并比。
[0089]
最终,我们把这3项损失结合,得到总损失函数如下:
[0090][0091]
在训练模型过程中,分别设置λ1=1和λ2=1.2。
[0092]
所述步骤s3进一步包括:
[0093]
步骤s31:获取测试视频,将视频解析成图片帧,所有图片按照时间先后命名(如第一帧图片命名为00001.jpg),并放在同一个文件夹下;
[0094]
步骤s32:第一帧图片作为模板图输入网络;
[0095]
步骤s33:后续帧图片作为搜索图输入网络,并预测目标在每一帧图片中的位置;
[0096]
步骤s34:通过每一帧目标位置的预测,得到追踪的成功率和准确率,其中成功率需要计算预测框和真实目标框的重叠率,准确率需要计算预测框和真实目标框的中心偏移距离。
[0097]
综上实例可见,本发明采用修改后的resnet
‑
50作为网络骨架以获取更加丰富的信息。无先验box的设计,避免了繁杂的超参数设置,也让追踪器更加灵活。同时动态全局信息建模模块提供x维度和y维度不同尺寸和比例的卷积核,让我们的追踪器能根据不同的目标自适应的选择卷积核来满足不同的感受野需求。同时内嵌的全局信息建模模块能捕获目
标的长距离依赖,完成全局信息建模。
[0098]
以上对本发明的具体实施例进行了说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。