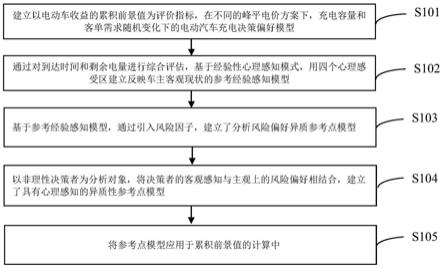
1.本发明涉及一种面向文献的表格信息抽取方法,属于数据处理以及计算机视觉领域。
背景技术:
::2.网络的无处不在和文献的免费访问使人类越来越容易获得越来越多的学术文献,可利用的实验数据的数量在迅速增加,几乎在所有研究领域中都在使用人工收集处理可用数据,这种方式效率低下。因此,为了使将来的研究能够充分的利用前人的数据和成果,并更进一步创新,需要一种用于自动提取和处理数据的系统。3.无论科学学科如何,研究和实验的结果通常都以表格的形式报告。表是一种报告大量数据集的直观和有效的方法。然而,虽然文献中的实验结果一般使用表格的形式在呈现,但在不同学科或者期刊之间的表格结构,存在任何形式的标准化。因此,用于提取这些表格数据的软件工具需要高度适应性,以便能够从不同类型表格中正确提取数据。4.目标检测技术已经应用于生活的各个方面。通过目标检测技术可以实现对不同类别的物体进行定位。“tsung‑yilin,priyagoyal,rossb.girshick,kaiminghe,andpiotrdollar.一种焦点损失用于目标检测′ieeetpami,42(2):318–327,2020”主要运用框回归神经网络和分类网络对位置的图片进行预测。“m.ruffoloande.oro.pdf‑trex:一种从pdf提取识别表格内容的方法inproc.oficdar2009,pages906–910,2009.提出一种启发式的表格信息抽取方法,通过对表格元素的位置拟合,实现了面向文本的表格信息萃取。当前的表格信息萃取召回率极低,会将文本中的噪声当成表格读取。因此,需要设计基于关键词语和可扩展词性的文本挖掘方法,以实现表格数据的精准抽取。技术实现要素:5.针对学术文献中表格边线不确定的特点,本发明提出了一种面向文献的表格信息抽取方法,适用于自动化提取表格信息,特别适用于学术文献信息抽取。6.本发明为解决其技术问题采用如下技术方案:7.一种面向文献的表格信息抽取方法,包括以下步骤:8.步骤1:利用规则获取所有可能含表格的候选页面;9.步骤2:将步骤1中获取的页面转化为图片文件;10.步骤3:采用深度学习方法,获取步骤2中图片文件的特征;11.步骤4:根据步骤3中获取的图片文件的特征,对图片进行特征融合;获取融合后的特征。12.步骤5:根据步骤4中获取的特征融合后的特征,对表格的位置进行初步定位;13.步骤6:针对步骤5获得的表格定位信息,根据表格元素的长宽关系,将横板表格旋转为竖版表格;14.步骤7:根据步骤6中获得的竖版表格,读取单元格字符流。15.步骤3的具体过程如下:16.首先用凯明正态分布初始化神经网络中的权重,然后将图片矢量化,最终将矢量化后的图片作为输入参数传入残差神经网络,获取特征图。17.步骤7的具体过程如下:18.对于已经旋转为竖版表格,计算每个元素的中线和边线的坐标,如果中线和19.边线的横竖坐标相同,则定位成单元格,并读取该位置的元素,将其转化为csv文件。20.本发明的有益效果如下:21.1)能自动对表格位置进行准确的定位。22.2)能够精确的从表格中读取表格的字符流。附图说明23.图1是本发明实例图。24.图2是表格定位的效果图。25.图3为表格定位的准确率示意图。26.图4是读取表格字符流效果图。具体实施方式:27.为了使本领域研究人员更好地理解本技术中的技术问题和技术方案,并实现申请所能达到的技术效果,下面结合附图和具体实施方式对本发明作进一步详细说明。28.本发明提出的一种面向文献的表格信息抽取方法,包括下述步骤,流程如图1所示:29.步骤1:利用多种规则,获取所有可能含表格的候选页面;30.地质文献数据集是关于地质文献的集合pd={pd1,pd2,...,pdn},其中,n代表地质文献数据集中地质文献的数量;31.对于单个文献pdj∈pd,存在页面集合pa={pa1,pa2,....pan},对任意页面paj,存在句子集合wa={wa1,wa2,....wan},如果正则表达式table[/d ]∈wa,则paj为候选页面,获取候选页面的多元属性组pdfi={doci,page,i,highti,widthi)其中doci为pdf候选页面文件,pagei为候选页面。,highti为pdf文件的高度,widthi为pdf文件的宽度。[0032]步骤2:将步骤1中获取的页面转化为图片文件;[0033]对于多元属性组pdfi对pdf文件进行截屏,截屏之后的生成的多元属性组picpdfi=(pngi,picage,i,pichighti,picwidthi)其中pngi为pdf候选页面文件的图片文件,picpagej为候选页面图片文件的页数。,pichighti为pdf候选页面文件的图片文件,,picwidthi为候选页面文件的图片文件宽度。由于pdf文件的坐标和图片文件的坐标表示方式不同,需要计算图标和pdf坐标的关系.对于候选页面图片文件多元属性组集合picpdf={picpdf1,picpdf2,......,picpdfn},以及候选页面集合pdf={pdf1,pdf2,......,pdfn}设缩放比例为k,截距为b,对于高度计算公式如式(1)所示:[0034]∑i<nk*highti ∑i<nb=∑i<npichightiꢀꢀꢀꢀ(1)[0035]其中:i表示当前的页面值,n为页面的个数。[0036]步骤3:采用深度学习技术,获取步骤2中图片文件的特征。[0037]对于步骤2中所叙述的图片多元属性组picpdfi,用计算机知识对多元属性组中的图片文件中的表格进行定位,首先用凯明正态分布初始化神经网络中的全连接层的参数,然后将图片矢量化,最终作为输入参数传入残差神经网络,获取特征图。[0038]具体的操作流程如下[0039]首先利用凯明正态分布对模型进行初始化,模型服从0均值的正态分布n,公式如式(2)所示:[0040]n~(0,std)ꢀꢀ(2)[0041][0042]其中a为激活函数的负半轴的斜率,在这里用relu函数,所以为0,fan_in为输入的维度。[0043]对于第i个残差块,输入为xi,输入为xi 1两层之间的公式如式(4)所示:[0044]xi 1=relu(h(xi) f(xi,wi))ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(4)[0045]h(xi)=wl′xꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(5)[0046]其中f(xi,wi)表示残差部分,由于卷积网络中xi 1会和xi的维度不同,wl′x为1x1的卷积操作,使特征图的两端的维度相同。relu函数为激活函数对于第l层的残差块xl与第i层的关系如式(6)所示:[0047][0048]其中:f(xj,wj)表示第l层和第i层之间的残差块;[0049]经过50层的残差层最终得到特征图spi。[0050]步骤4:根据步骤3中获取的图片文件的特征,对图片进行特征融合。[0051]由于在步骤2所述的特征图中的表格有大有小,需要对表格进行特征融合,从而捕获在不同尺寸的目标的特征。[0052]具体实施做法如下,对步骤3中所描述的特征分别spi利用步长为2,4,8,16,32的卷积核提取图片在不同尺寸的特征c={c1,c2,......,cn},对不同尺寸的特征图进行自上而下的特征融合,公式如式(7)所示:[0053]pi=h(ci) h(pi 1)(i<n‑1)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(7)[0054]pn=h(ci)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(8)[0055]f=∑i<npiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(9)[0056]其中h(ci)表示进行1x1卷积核升维之后的向量,h(pi 1)表示升维后的特征,pi表示第i层的特征,pn表示最顶层的特征,n为参与特征融合的特征图层数,最后将这些特征累加,成为图片总体的特征f。[0057]步骤5:根据步骤4中获取的图片文件的特征,对表格的位置进行初步定位;对于步骤4中所述的特征融合过后的特征图集合p,对于每个p,利用框回归网络j(x)生成回归框集合a={a1,a2,......,an},对于第i个框ai,xi,yi为框左上顶点的坐标,wi,hi为框的长宽,对于该特征图pi实际的左上角坐标实际的左上角坐标实际的长宽利用focaloss(焦点损失)来计算损失,从而解决背景和目标样本失衡的问题,公式如式(10)所示:[0058](xi,yi,wi,hi)=j(f)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(10)[0059]flx(ztx)=‑(1‑ztx)γlog(ztx)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(11)[0060][0061]flx(zty)=‑(1‑zty)γlog(zty)ꢀꢀ(13)[0062][0063]flw(ztw)=‑(1‑ztw)γlog(ztw)ꢀꢀ(15)[0064][0065]flh(zth)=‑(1‑zth)γlog(zth)ꢀꢀ(17)[0066][0067]其中j(f)为边框回归网络生成的框属性。对于左上顶点的横坐标ztx,利用focaloss计算真实值和预测值的损失,其中flx(ztx)为左上顶点横坐标的focaloss,ztx为左上顶点的横坐标的真实值和预测值xi的交叉熵。flx(zty)为左上顶点纵坐标的focaloss,zty为左上顶点的纵坐标真实值和预测值yi的交叉熵。flw(ztw)为预测框宽度的focaloss,ztw为预测框宽度的真实值和预测值wi的交叉熵,flh(zth)为预测框高度的focaloss,zth为预测框高度的真实值和预测值hi的交叉熵,γ为调制系数,为了减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。[0068]当预测的时候,通过边框回归网络就能预测出框的大小。表格的定位效果如图2所示,表格的定位的成功率如图3所示。[0069]步骤6:针对步骤5获得的表格位置,根据表格元素的长宽关系,将横板表格旋转;[0070]在文献中,表格的方向往往是不同,如果不处理方向就会导致表格错位。对于步骤5中所定位到的表格(xi,yi,wi,hi)对其进行坐标转化,得到(pxlti,pylti,pxrfi,pyrfi)其中pxlti,pylti为pdf中左上角点的坐标,pxrfi,pyrfi为pdf中右下角点的坐标。转化公式如(23),(24)所示:[0071]pxlti=kxi bꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(19)[0072]phi=khi bꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(20)[0073]pwi=kwi bꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(21)[0074]pvlti=kyi bꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(22)[0075]pxrfi=pxlti phiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(23)[0076]pyrfi=pylti pwiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(24)[0077]其中k,b为步骤2中计算得到的缩放比例和截距,pwi,phi为pdf中表格的宽高,读取从坐标大于pxlti,pylti到pxrfi,pyrfi的元素,判断每个元素字符流的长度和每个元素长宽,当字符流长度大于3的时候,判断元素的长和宽的关系,如果长小于宽,则判断为利用pdfminer工具包将pdf页面旋转。[0078]步骤7:根据步骤6中获得的竖版表格,读取单元格字符流。[0079]对于已经旋转为竖版表格,计算每个元素的中线和边线的坐标,如果中线和边线的横竖坐标相同,则定位成单元格,并读取该位置的元素,将其转化为csv(逗号分隔值)文件。步骤5‑7的样例如图4所示。当前第1页12当前第1页12
背景技术:
::2.网络的无处不在和文献的免费访问使人类越来越容易获得越来越多的学术文献,可利用的实验数据的数量在迅速增加,几乎在所有研究领域中都在使用人工收集处理可用数据,这种方式效率低下。因此,为了使将来的研究能够充分的利用前人的数据和成果,并更进一步创新,需要一种用于自动提取和处理数据的系统。3.无论科学学科如何,研究和实验的结果通常都以表格的形式报告。表是一种报告大量数据集的直观和有效的方法。然而,虽然文献中的实验结果一般使用表格的形式在呈现,但在不同学科或者期刊之间的表格结构,存在任何形式的标准化。因此,用于提取这些表格数据的软件工具需要高度适应性,以便能够从不同类型表格中正确提取数据。4.目标检测技术已经应用于生活的各个方面。通过目标检测技术可以实现对不同类别的物体进行定位。“tsung‑yilin,priyagoyal,rossb.girshick,kaiminghe,andpiotrdollar.一种焦点损失用于目标检测′ieeetpami,42(2):318–327,2020”主要运用框回归神经网络和分类网络对位置的图片进行预测。“m.ruffoloande.oro.pdf‑trex:一种从pdf提取识别表格内容的方法inproc.oficdar2009,pages906–910,2009.提出一种启发式的表格信息抽取方法,通过对表格元素的位置拟合,实现了面向文本的表格信息萃取。当前的表格信息萃取召回率极低,会将文本中的噪声当成表格读取。因此,需要设计基于关键词语和可扩展词性的文本挖掘方法,以实现表格数据的精准抽取。技术实现要素:5.针对学术文献中表格边线不确定的特点,本发明提出了一种面向文献的表格信息抽取方法,适用于自动化提取表格信息,特别适用于学术文献信息抽取。6.本发明为解决其技术问题采用如下技术方案:7.一种面向文献的表格信息抽取方法,包括以下步骤:8.步骤1:利用规则获取所有可能含表格的候选页面;9.步骤2:将步骤1中获取的页面转化为图片文件;10.步骤3:采用深度学习方法,获取步骤2中图片文件的特征;11.步骤4:根据步骤3中获取的图片文件的特征,对图片进行特征融合;获取融合后的特征。12.步骤5:根据步骤4中获取的特征融合后的特征,对表格的位置进行初步定位;13.步骤6:针对步骤5获得的表格定位信息,根据表格元素的长宽关系,将横板表格旋转为竖版表格;14.步骤7:根据步骤6中获得的竖版表格,读取单元格字符流。15.步骤3的具体过程如下:16.首先用凯明正态分布初始化神经网络中的权重,然后将图片矢量化,最终将矢量化后的图片作为输入参数传入残差神经网络,获取特征图。17.步骤7的具体过程如下:18.对于已经旋转为竖版表格,计算每个元素的中线和边线的坐标,如果中线和19.边线的横竖坐标相同,则定位成单元格,并读取该位置的元素,将其转化为csv文件。20.本发明的有益效果如下:21.1)能自动对表格位置进行准确的定位。22.2)能够精确的从表格中读取表格的字符流。附图说明23.图1是本发明实例图。24.图2是表格定位的效果图。25.图3为表格定位的准确率示意图。26.图4是读取表格字符流效果图。具体实施方式:27.为了使本领域研究人员更好地理解本技术中的技术问题和技术方案,并实现申请所能达到的技术效果,下面结合附图和具体实施方式对本发明作进一步详细说明。28.本发明提出的一种面向文献的表格信息抽取方法,包括下述步骤,流程如图1所示:29.步骤1:利用多种规则,获取所有可能含表格的候选页面;30.地质文献数据集是关于地质文献的集合pd={pd1,pd2,...,pdn},其中,n代表地质文献数据集中地质文献的数量;31.对于单个文献pdj∈pd,存在页面集合pa={pa1,pa2,....pan},对任意页面paj,存在句子集合wa={wa1,wa2,....wan},如果正则表达式table[/d ]∈wa,则paj为候选页面,获取候选页面的多元属性组pdfi={doci,page,i,highti,widthi)其中doci为pdf候选页面文件,pagei为候选页面。,highti为pdf文件的高度,widthi为pdf文件的宽度。[0032]步骤2:将步骤1中获取的页面转化为图片文件;[0033]对于多元属性组pdfi对pdf文件进行截屏,截屏之后的生成的多元属性组picpdfi=(pngi,picage,i,pichighti,picwidthi)其中pngi为pdf候选页面文件的图片文件,picpagej为候选页面图片文件的页数。,pichighti为pdf候选页面文件的图片文件,,picwidthi为候选页面文件的图片文件宽度。由于pdf文件的坐标和图片文件的坐标表示方式不同,需要计算图标和pdf坐标的关系.对于候选页面图片文件多元属性组集合picpdf={picpdf1,picpdf2,......,picpdfn},以及候选页面集合pdf={pdf1,pdf2,......,pdfn}设缩放比例为k,截距为b,对于高度计算公式如式(1)所示:[0034]∑i<nk*highti ∑i<nb=∑i<npichightiꢀꢀꢀꢀ(1)[0035]其中:i表示当前的页面值,n为页面的个数。[0036]步骤3:采用深度学习技术,获取步骤2中图片文件的特征。[0037]对于步骤2中所叙述的图片多元属性组picpdfi,用计算机知识对多元属性组中的图片文件中的表格进行定位,首先用凯明正态分布初始化神经网络中的全连接层的参数,然后将图片矢量化,最终作为输入参数传入残差神经网络,获取特征图。[0038]具体的操作流程如下[0039]首先利用凯明正态分布对模型进行初始化,模型服从0均值的正态分布n,公式如式(2)所示:[0040]n~(0,std)ꢀꢀ(2)[0041][0042]其中a为激活函数的负半轴的斜率,在这里用relu函数,所以为0,fan_in为输入的维度。[0043]对于第i个残差块,输入为xi,输入为xi 1两层之间的公式如式(4)所示:[0044]xi 1=relu(h(xi) f(xi,wi))ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(4)[0045]h(xi)=wl′xꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(5)[0046]其中f(xi,wi)表示残差部分,由于卷积网络中xi 1会和xi的维度不同,wl′x为1x1的卷积操作,使特征图的两端的维度相同。relu函数为激活函数对于第l层的残差块xl与第i层的关系如式(6)所示:[0047][0048]其中:f(xj,wj)表示第l层和第i层之间的残差块;[0049]经过50层的残差层最终得到特征图spi。[0050]步骤4:根据步骤3中获取的图片文件的特征,对图片进行特征融合。[0051]由于在步骤2所述的特征图中的表格有大有小,需要对表格进行特征融合,从而捕获在不同尺寸的目标的特征。[0052]具体实施做法如下,对步骤3中所描述的特征分别spi利用步长为2,4,8,16,32的卷积核提取图片在不同尺寸的特征c={c1,c2,......,cn},对不同尺寸的特征图进行自上而下的特征融合,公式如式(7)所示:[0053]pi=h(ci) h(pi 1)(i<n‑1)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(7)[0054]pn=h(ci)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(8)[0055]f=∑i<npiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(9)[0056]其中h(ci)表示进行1x1卷积核升维之后的向量,h(pi 1)表示升维后的特征,pi表示第i层的特征,pn表示最顶层的特征,n为参与特征融合的特征图层数,最后将这些特征累加,成为图片总体的特征f。[0057]步骤5:根据步骤4中获取的图片文件的特征,对表格的位置进行初步定位;对于步骤4中所述的特征融合过后的特征图集合p,对于每个p,利用框回归网络j(x)生成回归框集合a={a1,a2,......,an},对于第i个框ai,xi,yi为框左上顶点的坐标,wi,hi为框的长宽,对于该特征图pi实际的左上角坐标实际的左上角坐标实际的长宽利用focaloss(焦点损失)来计算损失,从而解决背景和目标样本失衡的问题,公式如式(10)所示:[0058](xi,yi,wi,hi)=j(f)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(10)[0059]flx(ztx)=‑(1‑ztx)γlog(ztx)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(11)[0060][0061]flx(zty)=‑(1‑zty)γlog(zty)ꢀꢀ(13)[0062][0063]flw(ztw)=‑(1‑ztw)γlog(ztw)ꢀꢀ(15)[0064][0065]flh(zth)=‑(1‑zth)γlog(zth)ꢀꢀ(17)[0066][0067]其中j(f)为边框回归网络生成的框属性。对于左上顶点的横坐标ztx,利用focaloss计算真实值和预测值的损失,其中flx(ztx)为左上顶点横坐标的focaloss,ztx为左上顶点的横坐标的真实值和预测值xi的交叉熵。flx(zty)为左上顶点纵坐标的focaloss,zty为左上顶点的纵坐标真实值和预测值yi的交叉熵。flw(ztw)为预测框宽度的focaloss,ztw为预测框宽度的真实值和预测值wi的交叉熵,flh(zth)为预测框高度的focaloss,zth为预测框高度的真实值和预测值hi的交叉熵,γ为调制系数,为了减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。[0068]当预测的时候,通过边框回归网络就能预测出框的大小。表格的定位效果如图2所示,表格的定位的成功率如图3所示。[0069]步骤6:针对步骤5获得的表格位置,根据表格元素的长宽关系,将横板表格旋转;[0070]在文献中,表格的方向往往是不同,如果不处理方向就会导致表格错位。对于步骤5中所定位到的表格(xi,yi,wi,hi)对其进行坐标转化,得到(pxlti,pylti,pxrfi,pyrfi)其中pxlti,pylti为pdf中左上角点的坐标,pxrfi,pyrfi为pdf中右下角点的坐标。转化公式如(23),(24)所示:[0071]pxlti=kxi bꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(19)[0072]phi=khi bꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(20)[0073]pwi=kwi bꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(21)[0074]pvlti=kyi bꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(22)[0075]pxrfi=pxlti phiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(23)[0076]pyrfi=pylti pwiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ(24)[0077]其中k,b为步骤2中计算得到的缩放比例和截距,pwi,phi为pdf中表格的宽高,读取从坐标大于pxlti,pylti到pxrfi,pyrfi的元素,判断每个元素字符流的长度和每个元素长宽,当字符流长度大于3的时候,判断元素的长和宽的关系,如果长小于宽,则判断为利用pdfminer工具包将pdf页面旋转。[0078]步骤7:根据步骤6中获得的竖版表格,读取单元格字符流。[0079]对于已经旋转为竖版表格,计算每个元素的中线和边线的坐标,如果中线和边线的横竖坐标相同,则定位成单元格,并读取该位置的元素,将其转化为csv(逗号分隔值)文件。步骤5‑7的样例如图4所示。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。