技术特征:
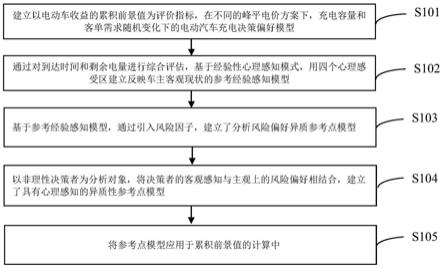
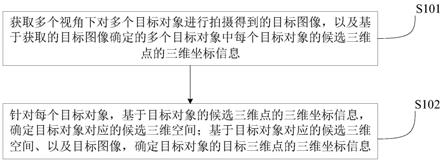
1.一种文本处理方法,其特征在于,包括:基于第一语言文本确定第一语言文本模块,并基于第二语言文本确定第二语言文本模块,其中,所述第一语言文本和所述第二语言文本为双语同族专利文本,或者,所述第一语言文本和所述第二语言文本为同一篇论文的双语文本,所述第一语言文本模块与所述第二语言文本模块在文本结构层面呈对应关系;分别对所述第一语言文本模块和所述第二语言文本模块进行句词拆分操作,以生成多个第一语言文本单元和多个第二语言文本单元;基于所述多个第一语言文本单元和所述多个第二语言文本单元确定所述第一语言文本模块和所述第二语言文本模块对应的平行句对。2.根据权利要求1所述的文本处理方法,其特征在于,所述句词拆分操作用于将所述第一语言文本模块和所述第二语言文本模块中的每个语言文本模块所包括的文本段落拆分为多个分句,并将每个分句拆分为多个分词;和/或,所述基于第一语言文本确定第一语言文本模块,并基于第二语言文本确定第二语言文本模块,包括:分别对所述第一语言文本和所述第二语言文本进行文本结构拆分操作,以生成第一语言文本模块和第二语言文本模块,所述文本结构拆分操作指的是对所述第一语言文本和所述第二语言文本进行文本结构层面的拆分操作。3.根据权利要求1或2所述的文本处理方法,其特征在于,所述基于所述多个第一语言文本单元和所述多个第二语言文本单元确定所述第一语言文本模块和所述第二语言文本模块对应的平行句对,包括:针对所述多个第一语言文本单元中的每个第一语言文本单元,基于所述多个第二语言文本单元确定所述第一语言文本单元对应的第一候选单元集合,其中,所述第一候选单元集合包括至少一个第二语言文本单元;确定所述第一候选单元集合中包括的第二语言文本单元和所述第一语言文本单元对应的多个候选词对;确定所述多个候选词对各自对应的分数信息;基于所述多个候选词对各自对应的分数信息确定所述第一候选单元集合中包括的第二语言文本单元对应的统计分数信息;计算所述第一候选单元集合中包括的第二语言文本单元对应的统计分数信息;基于所述统计分数信息确定所述第一语言文本单元对应的第二候选单元集合;基于所述多个第一语言文本单元各自对应的第二候选单元集合确定所述平行句对;其中,所述候选词对包括第一语言词和与所述第一语言词对应的第二语言词,所述确定所述多个候选词对各自对应的分数信息,包括:针对所述多个候选词对中的每个候选词对,基于所述候选词对的出现频率信息、包含有所述第二语言词的第二语言文本单元在所述第一候选单元集合中的比值信息、所述第二语言文本单元的候选加权信息、所述第二语言文本单元和所述第一语言文本单元的长度比值信息,确定所述候选词对对应的分数信息;其中,所述基于所述多个候选词对各自对应的分数信息确定所述统计分数信息,包括:
对所述多个候选词对各自对应的分数信息进行累加操作,以确定所述统计分数信息。4.一种模型训练方法,其特征在于,包括:确定初始处理模型;基于平行句对训练所述初始处理模型,以生成文本处理模型,其中,所述文本处理模型用于基于第一语言的待处理文本生成与所述待处理文本对应的第二语言的目标文本,所述平行句对基于上述权利要求1至3任一项所述的文本处理方法确定。5.一种文本处理方法,其特征在于,包括:获取第一语言的待处理文本;将所述第一语言的待处理文本输入文本处理模型,以生成第二语言的目标文本,其中,所述文本处理模型基于上述权利要求4所述的模型训练方法训练得到。6.一种文本处理装置,其特征在于,包括:第一确定模块,用于基于第一语言文本确定第一语言文本模块,并基于第二语言文本确定第二语言文本模块,其中,所述第一语言文本和所述第二语言文本为双语同族专利文本,或者,所述第一语言文本和所述第二语言文本为同一篇论文的双语文本,所述第一语言文本模块与所述第二语言文本模块在文本结构层面呈对应关系;拆分模块,用于分别对所述第一语言文本模块和所述第二语言文本模块进行句词拆分操作,以生成多个第一语言文本单元和多个第二语言文本单元;第二确定模块,用于基于所述多个第一语言文本单元和所述多个第二语言文本单元确定所述第一语言文本模块和所述第二语言文本模块对应的平行句对。7.一种模型训练装置,其特征在于,包括:初始处理模型确定模块,用于确定初始处理模型;训练模块,用于基于平行句对训练所述初始处理模型,以生成文本处理模型,其中,所述文本处理模型用于基于第一语言的待处理文本生成与所述待处理文本对应的第二语言的目标文本,所述平行句对基于上述权利要求1至3任一项所述的文本处理方法确定。8.一种文本处理装置,其特征在于,包括:获取模块,用于获取第一语言的待处理文本;处理模块,用于将所述第一语言的待处理文本输入文本处理模型,以生成第二语言的目标文本,其中,所述文本处理模型基于上述权利要求4所述的模型训练方法训练得到。9.一种计算机可读存储介质,其特征在于,所述存储介质存储有指令,当所述指令由电子设备的处理器执行时,使得所述电子设备能够执行上述权利要求1至5任一项所述的方法。10.一种电子设备,其特征在于,所述电子设备包括:处理器;用于存储计算机可执行指令的存储器;所述处理器,用于执行所述计算机可执行指令,以实现上述权利要求1至5任一项所述的方法。
技术总结
本公开提供了一种文本处理方法及装置、模型训练方法及装置,涉及数据处理技术领域。该文本处理方法包括:基于第一语言文本确定第一语言文本模块,并基于第二语言文本确定第二语言文本模块;分别对第一语言文本模块和第二语言文本模块进行句词拆分操作,以生成多个第一语言文本单元和多个第二语言文本单元;基于多个第一语言文本单元和多个第二语言文本单元确定第一语言文本模块和第二语言文本模块对应的平行句对。本公开充分利用了文本的结构特征,并借助了句词拆分操作将相应的文本模块转换为包括碎片化的分句分词的文本单元,因此,本公开能够充分顾及句子间的潜在语义信息,进而能够有效提升平行句对的构建效果。而能够有效提升平行句对的构建效果。而能够有效提升平行句对的构建效果。
技术研发人员:王超超 王为磊 屠昶旸
受保护的技术使用者:智慧芽信息科技(苏州)有限公司
技术研发日:2021.03.29
技术公布日:2021/11/4
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。