基于gcndt
‑
macbert神经网络框架的话语关系识别方法及系统
技术领域
1.本发明涉及话语关系识别的技术领域,具体地,涉及一种基于gcndt
‑
macbert神经网络框架的话语关系识别方法及系统。
背景技术:
2.话语关系:话语关系描述了两个相邻的文本单元(例如,从句、句子和较长的句子组)如何在逻辑上相互连接。篇章分析是自然语言处理(natural language processing)基础任务之一,可以帮助其他下游自然语言处理任务更好地工作,话语关系识别是作为篇章分析的重要组成部分,近年来受到越来越多的研究人员的关注。着重于确定两个相邻的语篇单元(例如,从句、句子和句子组)在语义上如何相互连接。显然,识别话语关系可以帮助许多下游的nlp应用程序,例如自动摘要,信息提取和问题解答。原则上,两个子句之间的话语连接对于认识它们之间的关系很重要。对于隐式的话语关系识别,由于缺少精确的连接词,因此更具挑战性,通常取决于对全文的理解。与英语相比,它是一种表述性语言(形式内聚),而中文是一种类意化语言(语义内聚),倾向于从句连接词。
3.语篇分析是自然语言处理中的一项基本任务,是机器翻译、问答、文本生成和文本摘要等后续任务的关键步骤。浅语篇解析,如penn discourse treebank 2.0(pdtb 2.0)和conll2015共享任务,侧重于识别被命名为语篇单元的两个文本区间(即子句或句子)之间的关系。在pdtb和conll共享任务的不同子任务中,两句之间的隐性关系分类被认为是最困难的问题,因为两句之间并没有话语标记或连接词(例如,然而和因为)。
4.话语关系数据集:目前主流的几个中文话语关系数据集分别是suda
‑
cdtb、conll
‑
cdtb和shared task,它们分别是由苏州大学和ldc语言联盟所策划并标注。conll
‑
cdtb:conll 2016shared task是由signll(acl's special interest group on natural language learning)于2016年发起的一项比赛,旨在扩大研究人员对话语关系识别任务的关注度和提高话语关系识别任务的识别精度。它包含中文和英文两个数据集,英文数据集是由pdtb2.0构成,而中文数据集conll
‑
cdtb是cdtb0.5进行扩充而得到的。suda
‑
cdtb:苏州大学提出了一种连接驱动的依赖树(cdt,connective
‑
driven dependency tree)方案来表示中文话语修辞结构,其中元素话语单元是叶节点,连接词是非叶节点,这主要是由宾夕法尼亚大学推动的话语树库与修辞结构理论。特别是,连接词被用来直接表示树结构的层次结构和话语的修辞关系,而话语单位的核则是整体性参照依赖性理论来确定的。在cdt方案的指导下,他们手动注释了500个文档的中文话语树库(cdtb,chinese discourse treebank)。
5.预训练模型的发展:机器学习在隐式话语关系分类中得到了广泛的应用。传统的研究主要集中在语言特征的生成与选择上,最近,上下文化的单词表示学习,如elmo、bert和roberta,已经被证明可以显著改善许多下游任务。从word2vec和glove再到elmo和gpt,到现如今最通用的bert,预训练模型走过了很长一段路,也给自然语言处理领域带来了巨
大的活力和突破。现实生活中有大量的缺乏人工标注的文本数据,而预训练模型的特点正好可以利用这些数据并结合无监督的任务进行预训练,然后通过在超大规模的文本数据库上进行预训练之后,模型可以非常好的学习到通用的语言表示;并且预训练模型有更好的泛化能力、加速下游任务的模型收敛速度、防止模型在小规模的数据集上过拟合等优点。
6.谷歌的研究人员受到启发,使用transformer的encoder,bert就此诞生。bert使用mlm(masked language model)任务和nsp(next
‑
sentence prediction)任务进行预训练。在进行mlm任务时,bert提出:对于文本中的词,有15%的概率需要进行掩蔽;而在需要掩蔽的词中,在80%的概率下,使用[mask]进行掩蔽,在10%的概率下,使用任意的词对原来的词进行替换,在剩下10%的概率下会使用原本的词。
[0007]
继bert之后,大量的预训练模型涌现,roberta和macbert引起了较大的关注。roberta较bert主要有两点改进:1、bert静态遮掩改为动态遮掩;2、使用更大规模的语料。
[0008]
macbert较bert主要有三点改进:1、使用全词掩蔽(wwm,whole word masking),n
‑
gram掩蔽策略来选择候选词进行掩蔽,从单字符到四字符的掩蔽百分比为40%、30%、20%、10%。2、使用同义词替代[mask]:bert有个很大的问题,也就是在进行mlm任务的时候会把输入的句子中的若干词用[mask]掩蔽起来,但是[mask]这个词在微调阶段并未出现,这会造成预训练任务与下游微调任务不一致;因此macbert提出使用同义词替代[mask],当没有同义词时才会选择随机词进行替换;3、使用albert模型提出的句子顺序预测任务(sentence
‑
order prediction)替换bert模型原本的nsp任务;sop任务通过切换两个连续句子的原顺序创建负样本。
[0009]
公开号为cn111382569a的中国发明专利文献公开了一种对话语料中实体的识别方法、装置和计算机设备,包括:获取待识别实体的语料文本;将所述语料文本进行分词,得到分词结果,所述分词结果中包含多个字;获取所述分词结果中的每个字对应的字向量,将所述每个字对应的字向量进行组合得到所述语料文本对应的文本矩阵;将所述文本矩阵作为实体识别模型的输入,获取所述实体识别模型输出的所述语料文本中的实体。
[0010]
针对上述中的相关技术,发明人认为上述方法是得到文本中的实体,文本内上下文信息和语法关系的利用率较小,较难学习文本的内在语义,导致模型效果差。
技术实现要素:
[0011]
针对现有技术中的缺陷,本发明的目的是提供一种基于gcndt
‑
macbert神经网络框架的话语关系识别方法及系统。
[0012]
根据本发明提供的一种基于gcndt
‑
macbert神经网络框架的话语关系识别方法,其特征在于,包括如下步骤:
[0013]
步骤s1:对数据进行预处理,得到文本的词序列和句法依存树;
[0014]
步骤s2:建立预训练模型,根据所述预训练模型对文本进行分字得到文本的字序列,将文本的字序列输入预训练模型,得到包含上下文信息的字向量序列;
[0015]
步骤s3:根据所述步骤s1得到的词序列对所述步骤s2的字向量序列进行融合,获得词向量序列;
[0016]
步骤s4:建立图卷积神经网络模块,将所述步骤s1的句法依存树转化为以词为节点的图结构,然后利用图卷积神经网络模块得到更多信息的词向量序列;
[0017]
步骤s5:建立cnn
‑
highway模块,包含卷积神经网络和highway,将词向量序列输入卷积神经网络,利用所述卷积神经网络对词向量序列进行向量特征融合并映射为固定长度的向量,通过highway提取词向量序列的更多信息;
[0018]
步骤s6:采用多层感知机,将步骤s5得到的词向量序列输入多层感知机,并使用softmax函数得出分类结果,根据分类结果知道文本之间的逻辑关系。
[0019]
优选的,所述步骤s1中通过自然语言处理工具包对文本进行处理,得到文本的词序列和句法依存树。
[0020]
优选的,所述步骤s2包括如下步骤:
[0021]
步骤s2.1:所述预训练模型包括分词器和词表,通过预训练模型的分词器对多个文本分别进行分字得到字序列,产生与字向量序列长度相同的位置序列和片段序列,然后将多个文本的各自的字序列、位置序列和片段序列分别按照顺序进行拼接;
[0022]
步骤s2.2:所述预训练模型包括多个嵌入层,将所述步骤s2.1中的字序列、位置序列和片段序列分别输入对应的嵌入层并得到对应的嵌入向量序列,请将多个嵌入向量序列相加得到最终的输入向量序列;
[0023]
步骤s2.3:预训练模型包括transformer encoder神经网络,将输入向量序列输入到预训练模型的transformer encoder神经网络中,通过计算得到包含上下文信息的字向量序列。
[0024]
优选的,所述步骤s3包括如下步骤:
[0025]
步骤s3.1:在得到步骤s2.3的字向量序列后,根据多个文本的原始序列长度将字向量序列分割为多个独立的字向量序列;
[0026]
步骤s3.2:根据步骤s1中通过自然语言处理工具包生成的词序列,将步骤s3.1的多个独立的字向量序列分别融合为词向量,得到词向量序列。
[0027]
优选的,所述步骤s4还包括:根据步骤s1中生成的句法依存树获得以词为节点的邻接矩阵,然后使用图卷积神经网络模块融合词向量序列的语法特征。
[0028]
优选的,所述步骤s5通过cnn
‑
highway模块进行向量特征融合并将其映射到固定长度的向量;将词向量序列输入卷积神经网络,设置多个带有卷积核的卷积层,利用卷积核融合文本中的信息,再通过卷积神经网络中的池化层将向量序列映射为固定长度的向量,最后使用highway提取更多信息。
[0029]
根据本发明提供的一种基于gcndt
‑
macbert神经网络框架的话语关系识别系统,包括如下模块:
[0030]
模块m1:对数据进行预处理,得到文本的词序列和句法依存树;
[0031]
模块m2:建立预训练模型,根据所述预训练模型对文本进行分字得到文本的字序列,将文本的字序列输入预训练模型,得到包含上下文信息的字向量序列;
[0032]
模块m3:根据所述模块m1得到的词序列对所述模块m2的字向量序列进行融合,获得词向量序列;
[0033]
模块m4:建立图卷积神经网络模块,将所述模块m1的句法依存树转化为以词为节点的图结构,然后利用图卷积神经网络模块得到更多信息的词向量序列;
[0034]
模块m5:建立cnn
‑
highway模块,包含卷积神经网络和highway,将词向量序列输入卷积神经网络,利用所述卷积神经网络对词向量序列进行向量特征融合并映射为固定长度
的向量,通过highway提取词向量序列的更多信息;
[0035]
模块m6:采用多层感知机,将模块m5得到的词向量序列输入多层感知机,并使用softmax函数得出分类结果,根据分类结果知道文本之间的逻辑关系。
[0036]
优选的,所述模块m1中通过自然语言处理工具包对文本进行处理,得到文本的词序列和句法依存树。
[0037]
优选的,所述模块m2包括如下步骤:
[0038]
模块m2.1:所述预训练模型包括分词器和词表,通过预训练模型的分词器对多个文本分别进行分字得到字序列,产生与字向量序列长度相同的位置序列和片段序列,然后将多个文本的各自的字序列、位置序列和片段序列分别按照顺序进行拼接;
[0039]
模块m2.2:所述预训练模型包括多个嵌入层,将所述模块m2.1中的字序列、位置序列和片段序列分别输入对应的嵌入层并得到对应的嵌入向量序列,请将多个嵌入向量序列相加得到最终的输入向量序列;
[0040]
模块m2.3:预训练模型包括transformer encoder神经网络,将输入向量序列输入到预训练模型的transformer encoder神经网络中,通过计算得到包含上下文信息的字向量序列。
[0041]
优选的,所述模块m3包括如下步骤:
[0042]
模块m3.1:在得到模块m2.3的字向量序列后,根据多个文本的原始序列长度将字向量序列分割为多个独立的字向量序列;
[0043]
模块m3.2:根据模块m1中通过自然语言处理工具包生成的词序列,将模块m3.1的多个独立的字向量序列分别融合为词向量,得到词向量序列。
[0044]
与现有技术相比,本发明具有如下的有益效果:
[0045]
1、本发明充分利用文本的上下文信息,使用最新的预训练模型进行提取上下文特征;
[0046]
2、本发明通过融合中文字向量得到了中文词向量,弥补了预训练模型在中文中只能有以为单位来表示的缺陷;
[0047]
3、本发明使用corenlp自然语言处理工具包提取句法依存树,然后使用图卷积神经网络提取语法特征;
[0048]
4、本发明充分利用了文本内的上下文信息和语法关系,使用预训练模型和图卷积网络可以极大的促进模型学习文本的内在语义;
[0049]
5、本发明使用macbert,roberta等预训练模型得到上下文的表示向量,然后将字向量(英文文本不需要这一步)融合得到词向量,并通过图卷积网络学习文本的语法特征。
附图说明
[0050]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
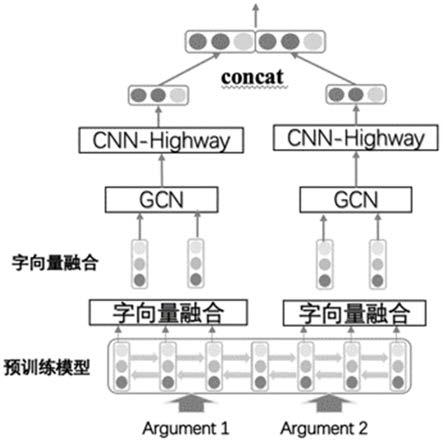
[0051]
图1为本发明中基于gcndt
‑
macbert神经网络框架的话语关系识别系统的整体架构图;
[0052]
图2为本发明中的利用corenlp自然语言处理工具包生成的句法依存树。
具体实施方式
[0053]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
[0054]
本发明实施例公开了一种基于gcndt
‑
macbert神经网络框架的话语关系识别方法及系统,如图1和图2所示,包括如下步骤:步骤s1:对数据(每个样本为两条文本和对应的类别)进行预处理,得到文本的词序列和句法依存树。通过自然语言处理工具包对文本进行处理,得到文本的词序列和句法依存树。通过stanford corenlp自然语言处理工具包对文本进行处理,得到词序列及句法依存树。使用corenlp自然语言处理工具包对文本数据进行预处理,得到两个argument文本各自的词序列和句法依存树结构。
[0055]
实验是在两个数据集上进行的,分别是suda
‑
cdtb和conll
‑
cdtb数据集,两个数据集的原始文本来源如表1所示,suda
‑
cdtb和conll
‑
cdtb数据集的样本类型统计结果如表2和表3所示。使用corenlp自然语言处理工具包对每个样本的两个argument文本内容分别进行解析,得到文本的词序列和句法依存树结构。
[0056]
表1数据集样本总量及所属领域
[0057][0058]
表2suda
‑
cdtb数据集样本类型及数量统计
[0059][0060]
表3conll
‑
cdtb数据集样本类型及数量统计
[0061][0062]
步骤s2:建立预训练模型,根据预训练模型(macbert等)对文本进行分字得到文本的字序列,将文本的字序列输入预训练模型,得到包含上下文信息的字向量序列。使用预训练模型(macbert、roberta等)的分词器对两个argument文本进行处理并得到文本的字序列,然后将两个argument文本的字序列拼接,再输入到预训练模型中,得到包含上下文信息的字向量序列。
[0063]
步骤s2包括如下步骤:步骤s2.1:预训练模型包括分词器和词表,通过预训练模型的分词器对两个文本分别进行分字得到字序列,产生与字向量序列长度相同的位置序列和片段序列,然后将两个文本的各自的字序列、位置序列和片段序列分别按照顺序进行拼接。
[0064]
通过预训练模型的分词器对两个argument的文本分别进行分字得到字序列(英文文本的分词结果为词序列),然后将两个argument的各自的序列分别按照如下公式的顺序进行拼接。分别产生和两个argument字向量序列长度相同的位置序列和片段序列,argument1的位置序列从0开始以1为步长递增,argument2的位置序列接着argument1的最后一个元素开始同样以1为步长递增,对于片段序列,argument 1的片段序列都设置为0,argument2的片段序列都设置为1;然后将两个argument的各自的三条序列分别按照如下公式的顺序进行拼接。
[0065][0066][0067][0068]
arg1表示argument1的字向量序列;cls表示预训练模型添加的头标签;sep表示预训练模型添加的分割标签;eos表示预训练模型添加的头标签;表示argument1中的字向量;arg2表示argument2的字向量序列;表示argument2中的字向量;下标m表示argument1
中的字的数量;下标n表示argument2中的字的数量;e0~e
m n 3
表示合并后的新的字向量。
[0069]
步骤s2.2:预训练模型包括多个嵌入层,将步骤s2.1中的字序列、位置序列和片段序列分别输入对应的嵌入层并得到对应的嵌入向量序列,将多个嵌入向量序列相加得到最终的输入向量序列。预训练模型有三个嵌入层,分别为word embedding、position embedding、segment embedding,将步骤s2.1的三个序列分别输入对应的嵌入层并得到对应的嵌入向量序列(字向量序列、位置向量序列、片段向量序列),并将三条嵌入向量序列相加(对应位置相加)得到最终的输入向量序列。字向量序列由word embedding产生,位置向量序列由position embedding产生,片段向量序列由segment embedding产生。
[0070]
步骤s2.3:预训练模型包括transformer encoder神经网络,将输入向量序列输入到预训练模型的transformer encoder神经网络中,通过计算得到包含上下文信息的字向量序列。将输入向量序列输入到预训练模型的transformer encoder神经网络模块中,通过多层模块的计算得到包含上下文信息的字向量序列[h0,h1,
…
,h
m n 2
,h
m n 3
];h0~h
m n 3
表示e0~e
m n 3
输入到预训练模型融合了上下位信息得到的信息字向量序列。
[0071]
步骤s3:根据步骤s1得到的词序列对步骤s2的字向量序列进行融合,获得词向量序列。对字向量序列进行融合,获得词向量序列。根据步骤s1中通过corenlp自然语言处理工具包生成的词序列,将步骤s2得到的两个argument的字向量序列分别进行融合,获得两个argument的词向量序列。
[0072]
步骤s3包括如下步骤:步骤s3.1:在得到步骤s2.3的字向量序列后,根据多个文本的原始序列长度将字向量序列分割为多个独立的字向量序列。在得到s2.3的字向量序列后,根据两个argument的原始序列长度将字向量序列分割为两个独立的字向量序列,分别称为argument1的字向量序列和argument2的字向量序列;
[0073][0074][0075]
表示切分后的argument1字向量;表示切分后的argument2字向量;h
m 1
表示切分前的字向量;m表示argument1的字的数量;n表示argument2的字的数量。
[0076]
步骤s3.2:根据步骤s1中通过自然语言处理工具包生成的词序列,将步骤s3.1的多个独立的字向量序列分别融合为词向量,得到词向量序列。根据步骤s1中通过corenlp自然语言处理工具包生成的词序列,将步骤s3.1的多个独立的字向量序列分别融合为词向量,得到词向量序列。
[0077]
步骤s4:建立图卷积神经网络模块,将步骤s1的句法依存树转化为以词为节点的图结构,然后利用图卷积神经网络模块得到更多信息的词向量序列。根据步骤s1中生成的句法依存树获得以词为节点的邻接矩阵,然后使用图卷积神经网络模块融合词向量序列的语法特征。步骤s1中通过corenlp自然语言处理工具包生成的句法依存树是以词为节点形成的树结构,先将根据句法依存树获得以词为节点的邻接矩阵;然后使用图卷积神经网络模块融合词向量序列的语法特征。
[0078]
步骤s4包括如下步骤:步骤s4.1:根据步骤s1中通过自然语言处理工具包生成的句法依存树是以词为节点形成的树结构,树结构是一种特殊的图结构,树结构本质上也是无向图的结构,所以先根据句法依存树获得以词为节点的邻接矩阵。
[0079]
步骤s4.2:然后将词向量序列和邻接矩阵一同输入到图卷积神经网络模块中,通
过图神经网络模块得到包含语法关系特征的词向量序列。
[0080]
h
l 1
=f(h
l
,a)
[0081]
h0=x为第一层的输入;x表示词向量序列,表示x的维度是n
’×
d,是向量维度的符号,n’为图的节点个数,d为每个节点特征向量的维度,a为邻接矩阵,f为卷积函数,h
l
表示第l层的输入。
[0082]
步骤s5:建立cnn
‑
highway模块,包含卷积神经网络和highway,将词向量序列输入卷积神经网络,利用卷积神经网络对词向量序列进行向量特征融合并映射为固定长度的向量,通过highway提取词向量序列的更多信息,信息/特征是一种抽象的概念,highway本质上就是使向量所表示和包含的信息能更多。通过cnn
‑
highway模块进行向量特征融合并将其映射到固定长度的向量;将词向量序列输入卷积神经网络,设置多个带有卷积核的卷积层,利用卷积核融合文本中的信息,再通过卷积神经网络中的池化层将词向量序列映射为固定长度的向量,最后使用highway提取更多信息。cnn
‑
highway模块包含cnn(卷积神经网络)和highway两个子模块。
[0083]
cnn
‑
highway模块,利用卷积神经网络和最大池化层对词向量序列进行向量特征融合并映射为固定长度的向量,然后通过highway模块提取更多特征。通过cnn
‑
highway模块对词向量序列进行向量特征融合并将其映射到固定长度的向量,首先输入卷积神经网络(cnn),利用卷积核融合文本中的n
‑
gram信息,在通过最大池化层将词向量序列映射为固定长度的向量,最后使用highway模块提取更多特征。
[0084]
步骤s5包括以下具体步骤:步骤s5.1:利用卷积神经网络(cnn)融合词向量序列;设置多个卷积核大小不同的卷积层,首先将词向量序列输入卷积神经网络(cnn)利用卷积操作融合文本中的n
‑
gram信息,再通过最大池化层将词向量序列映射为固定长度的向量,公式如下:
[0085][0086]
表示经过卷积核为c的卷积函数和池化层操作后的向量,下标c表示卷积核的大小,relu表示非线性函数,conv
c
表示卷积核大小为c的卷积函数,表示第i个词向量,表示第i c个词向量。
[0087]
步骤s5.2:最后使用highway模块提取更多特征,公式如下:
[0088][0089][0090][0091]
o1=g1⊙
u1′
(1
‑
g1)
⊙
u1[0092]
表示经过卷积核为z的卷积函数和池化层操作后的向量,flatten将向量序列合并为向量,w
h
、w
g
表示模块内的参数,上标t表示矩阵转置,sigmod、relu表示非线性函数,o1表示最终的固定长度的argument向量,符号
⊙
表示内积运算。
[0093]
步骤s6:采用多层感知机,将步骤s5得到的词向量序列输入多层感知机,并使用softmax函数得出分类结果,根据分类结果得到文本之间的逻辑关系。
[0094]
多层感知机是深度学习领域的一个基础模块,可以直接使用将两个argument的表征向量拼接起来输入到多层感知机中,最终长度为4的向量,使用softmax函数进行归一化作为每个类别的得分,得分最高的类别便是模型预测的结果。根据所分得的类别可以知道这两条文本之间的逻辑关系,为下游任务提供帮助。输出的是定义好的类型,例如,因果,转折等;项目的任务就是得到这个类别。
[0095]
步骤s6包括以下具体步骤:步骤s6.1:通过步骤s5可以得到两个argument的固定长度的表征向量,然后将两个向量拼接起来输入到多层感知机中,最终长度为4的向量。表征向量为固定长度的向量。
[0096]
步骤s6.2:然后使用softmax函数进行归一化作为每个类别的得分,得分最高的类别便是模型预测的结果。每个数据集自身定义类别。
[0097]
本发明的深度学习模型—gcndt
‑
macbert神经网络框架,除此之外,我们还加入了不包含gcn的gcndt
‑
macbert模型(即macbert)作为比较,与以往的模型一起分别在conll
‑
cdtb和suda
‑
cdtb数据集上进行实验,通过acc指标和f1指标两个指标来比较不同模型的性能差异。
[0098]
acc表示准确率,准确率是针对我们预测结果而言的,在二元分类的统计分析中,它表示的是预测为正的样本中有多少是真正的正样本。
[0099]
f1是测试准确性的度量。它是根据测试的准确率和召回率计算得出的,在二元分类的统计分析中,其中精确率是真阳性结果的数量除以所有阳性结果的数量,包括未正确识别的结果,召回率是真阳性结果的数量除以应该被确定为阳性的所有样本的数量;f1同样也可以扩展到多分类的问题中。
[0100]
表4总结了gcndt
‑
macbert和所有baseline方法的结果,其中最优结果已经以黑体字突出显示。显而易见,本发明提出的gcndt
‑
macbert在每个数据集上的所有指标上均表现出最优性能。gcndt
‑
macbert通过预训练模型更好地学习到文本的上下文信息,并且通过句法依存树的结构和图卷积神经网络模块提取到了文本的语法信息;与次优的ttn相比,gcndt
‑
macbert在conll
‑
cdtb和suda
‑
cdtb数据集上的acc分别提高5.4%和13.96%。
[0101]
表4各模型在数据库上的表现
[0102]
[0103]
本发明提供了基于transformer和gcn神经网络的gcndt
‑
macbert神经网络框架的话语关系识别模型,本发明使用macbert,roberta等预训练模型得到上下文的表示向量,然后将字向量(英文文本不需要这一步)融合得到词向量,并通过图卷积网络学习文本的语法特征。本发明使用corenlp自然语言处理工具包提取句法依存树,然后使用图卷积神经网络提取特征语法特征。本文是要得到两个文本之间的关系类别,本发明涉及句间文本分类和话语关系领域,充分利用了文本内的上下文信息和语法关系,使用预训练模型和图卷积网络可以极大的促进模型学习文本的内在语义。
[0104]
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0105]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。