一种基于中红外光谱和svm的鹿角帽种类识别方法
技术领域
1.本发明属于鹿角帽识别技术领域,特别是涉及一种基于中红外光谱和svm的鹿角帽种类识别方法。
背景技术:
2.鹿角帽是梅花鹿或马鹿采茸后,在雄鹿头上留下的平台状角盘,逐渐骨化,换角时,角炳和角盘分离断裂,脱落下来的角,其有较高的药用价值,可以用来治疗疮痛肿毒,瘀血作痛,虚痨内伤等症,对各种腺体炎症效果明显。随着国内对鹿药材的开发,鹿角帽开始在市场火热起来。虽然梅花鹿鹿角帽和马鹿鹿角帽都是国家规定的鹿药材,但梅花鹿鹿角帽在价格和药用价值上都高于马鹿鹿角帽且二者外形和内部分子结构差不多,导致市场上鹿角帽种类不符成为了常见问题之一,如何找到一种高效,在线,低成本的鹿角帽种类识别方法是重中之重。
3.目前,国内外学者主要是对鹿茸进行检测识别研究,尽管很多学者对鹿茸的检测识别研究已经有了较好的成果,可对药用鹿角帽检测识别还非常少。红外光谱技术具体有高效,快速,低成本,无损等等点,在农林产品检测及识别方面有着良好的前景。现在对鹿角帽检测识别研究有较强的局限性,测试样本需和标准图谱一模一样才能被认定为正品鹿角帽,否则又要进行其它检测对比且不能对鹿角帽种类进行区分。为此,本发明基于中红外光谱技术的优点与广泛应用结合数学建模寻找到了一种高效、快速且准确的鹿角帽品种识别方法。
技术实现要素:
4.本发明的目的在于提供一种基于中红外光谱和svm的鹿角帽种类识别方法,通过中红外光谱技术以及支持向量机svm、随机森林算法rf和极限学习机elm建立模型的方法,解决了现有技术中梅花鹿鹿角帽和马鹿鹿角帽无法进行高效、准确和无损的识别,进而无法为解决鹿角帽种类和质量检测问题提供了新的思路和方法的问题。
5.为解决上述技术问题,本发明是通过以下技术方案实现的:
6.本发明为一种基于中红外光谱和svm的鹿角帽种类识别方法,包括以下步骤:
7.步骤1:对待测的梅花鹿鹿角帽和马鹿鹿角帽分别进行破碎处理,经200目筛筛分后得到梅花鹿鹿角帽和马鹿鹿角帽的粉末,再将鹿角帽粉末和溴化钾放到60℃恒温干燥箱内烘8
‑
12h;
8.步骤2:精密称取烘干后的梅花鹿鹿角帽粉末1.8mg和溴化钾190mg,混合研磨均匀,研磨后的粉末置于红外压片模具中压制成片,得到梅花鹿鹿角帽压片,同样方式得到马鹿鹿角帽压片,分别将梅花鹿鹿角帽压片和马鹿鹿角帽压片放置于中红外光谱仪上,分别采集对应压片的漫反射光谱;
9.步骤3:采用the unscrambler x 10.4软件对采集的原始光谱进行多重数据处理,得到预处理后的光谱,再将预处理后的光谱与对应的原始光谱进行对比;所述多重数据处
理包括有多元散射校正msc;
10.采用全段光谱数据波段和只从光谱数据中取出差异较大的所有波段进行后面的数据分析对比,从而选出最优的波段;
11.步骤4:采用k
‑
s检验法,以训练集和测试集样品数为5:2的比例,将总样品数划分为若干训练集和若干测试集,其中训练集和测试集中的梅花鹿鹿角帽和马鹿鹿角帽的样品比例均为1:1;
12.步骤5:采用归一化与主成分分析降维的方法,对光谱数据进行高维数据压缩和主要特征分量的提取,主要包括如下步骤:
13.步骤51:采用matlab2014b中的mapminmax函数把msc光谱数据进行归一化处理,并将数据映射范围设置为0~1;
14.步骤52:使用python 3.7软件对归一化后的msc鹿角帽光谱数据进行主成分分析,并分别绘制全段msc光谱和选出有明显差异波段msc光谱中的前两个主成分的散点图;
15.步骤6:以支持向量机svm、随机森林rf和极限学习机elm三个方法建模,分别将主成分分析后全段smc光谱和选出有明显差异波段后主成分分析的msc光谱作为输入变量,建立svm、elm和rf梅花鹿鹿角帽和马鹿鹿角帽的识别模型。
16.进一步地,所述步骤2中的漫反射光谱采集软件的波数范围为4000
‑
400cm
‑
1,分辨率为4cm
‑
1,扫描次数为16次,每个样本重复扫描3次,取平均光谱;
17.光谱采集过程中,室内温度设置为25度,湿度设置为35%。
18.进一步地,所述步骤3中的多重数据处理还包括有标准正态变量变换snv、平滑sg、一阶导数和二阶导数。
19.进一步地,所述步骤5中主成分的个数选择方法为方法一和方法二的结合;
20.其中,所述方法一为主成分的个数累积贡献率至少要大于等于85%,所述方法二为主成分特征值大于等于1。
21.进一步地,所述步骤6中的支持向量机svm的具体方法为:首先训练集采用k
‑
cv交叉验证同时支持向量机svm需要确定最佳惩罚因子c、核函数参数g及最优核函数;
22.采用网络搜索法,所述最佳惩罚因子c设置为2
‑
15~215,所述核函数参数g的范围设置为2
‑
15~215,步长为0.1,使用径向基核函数作为最优核函数。
23.进一步地,所述步骤6中的随机森林rf的具体方法为:采用遗传算法寻找最优棵树及其它影响参数,遗传算法中待优化的变量个数设置为2,个体数目设置为20,最大遗传代数设置为200,变量的二进制位数设置为10,代沟设置为0.95,交叉变异概率设置为0.7,变异概率设置为0.01。
24.进一步地,所述步骤6中的极限学习机elm中的隐藏节点数量设置为40
‑
100,比较得出最优的隐藏节点数量。
25.本发明具有以下有益效果:
26.1、本发明利用中红外光谱技术以及支持向量机svm、随机森林算法rf和极限学习机elm建立模型的方法,实现了梅花鹿鹿角帽和马鹿鹿角帽的高效、准确和无损的鹿角帽品种识别,为解决鹿角帽种类和质量检测问题提供了新的思路和方法。
27.当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
28.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
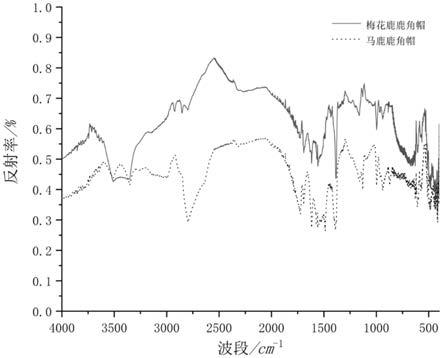
29.图1为msc鹿角帽的平均光谱图。
30.图2为归一化后的平均msc光谱数据图。
31.表1为前10个主成分特征值和累积贡献率。
32.图3为全段光谱测试集前2个主成分得分散点图。
33.图4为差异光谱测试集前2个主成分得分散点图。
34.图5为全段光谱网格搜索参数寻优适应度曲线。
35.图6为全段光谱测试集拟合结果。
36.图7为差异光谱网格搜索参数寻优适应度曲线
37.图8为差异光谱测试集拟合结果。
38.图9为全段光谱迭代误差变化曲线。
39.图10为全段光谱训练集拟合结果。
40.图11为全段光谱测试集拟合结果。
41.图12为差异光谱迭代误差变化曲线。
42.图13为差异光谱训练集拟合结果。
43.图14为差异光谱测试集拟合结果。
44.表2为elm算法预测结果对比。
45.图15为全段光谱训练集拟合结果。
46.图16为全段光谱测试集拟合结果。
47.图17为差异光谱训练集拟合结果。
48.图18为差异光谱测试集拟合结果。
具体实施方式
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
50.请参阅图1
‑
18和表1
‑
2,本发明为一种基于中红外光谱和svm的鹿角帽种类识别方法,包括以下步骤:
51.步骤1:对待测的梅花鹿鹿角帽和马鹿鹿角帽分别进行破碎处理,经200目筛筛分后得到梅花鹿鹿角帽和马鹿鹿角帽的粉末,再将鹿角帽粉末和溴化钾放到60℃恒温干燥箱内烘8
‑
12h;采集梅花鹿鹿角帽与马鹿鹿角帽各42个样品,共84个样品;
52.步骤2:精密称取烘干后的梅花鹿鹿角帽粉末1.8mg和溴化钾190mg,混合研磨均匀,研磨后的粉末置于红外压片模具中压制成片,得到梅花鹿鹿角帽压片,同样方式得到马鹿鹿角帽压片,分别将梅花鹿鹿角帽压片和马鹿鹿角帽压片放置于中红外光谱仪上,分别
采集对应压片的漫反射光谱;
53.步骤3:光谱信息易受高频随机噪声、基线漂移、样本本身和光散射等影响,需对原始光谱进行预处理,减少这些因素干扰,本发明采用the unscrambler x 10.4软件对采集的原始光谱进行多重数据处理,得到预处理后的光谱,再将预处理后的光谱与对应的原始光谱进行对比;所述多重数据处理包括有多元散射校正msc、标准正态变量变换snv、平滑sg、一阶导数和二阶导数;经过各种预处理后的光谱进行对比,可看出来经过多元散射校正msc处理的光谱差异性更为明显,如图1所示。由图1可以看出梅花鹿鹿角帽和马鹿鹿角帽在波段740
‑
840,1260
‑
1360,1420
‑
1540,1900
‑
3320,3700
‑
4000中有明显的不同;
54.在光谱数据中特征峰是判断光谱区别的主要因素,这里采用全段光谱数据波段和只从光谱数据中取出差异较大的所有波段进行后面的数据分析对比,从而选出最优的波段;
55.步骤4:k
‑
s检验是一种基于累计分布函数,快速检测训练集与测试集划分的方法,采用k
‑
s检验法,以训练集和测试集样品数为5:2的比例,将84份样品划分为60个训练集和24个测试集,其中训练集和测试集中的梅花鹿鹿角帽和马鹿鹿角帽的样品比例均为1:1;训练集中梅花鹿和马鹿鹿角帽各30份,测试集中梅花鹿和马鹿鹿角帽各12份;
56.步骤5:中红外光谱波段范围为4000
‑
400cm
‑1,其有波段多、数据量大、冗余性强的特点,采用归一化与主成分分析降维的方法,对光谱数据进行高维数据压缩和主要特征分量的提取,主要包括如下步骤:
57.步骤51:采用matlab2014b中的mapminmax函数把msc光谱数据进行归一化处理,并将数据映射范围设置为0~1,如图2所示;
58.步骤52:使用python 3.7软件对归一化后的msc鹿角帽光谱数据进行主成分分析,分别展示全段光谱与选出有明显差异波段光谱的前10个主成分特征值和累积贡献率如表1所示,在全段msc光谱中pca1的贡献率最大,为55.62909%,pca2的贡献率为20.63217%,前3个pc的累积贡献率为84.15974%,直到前8个pc的累积贡献率为97.16765%,之后的各pc贡献率都小于1%且累积贡献率提高速度逐步变小。在选出有明显差异波段msc光谱中pca1的贡献率最大,为59.52195%,pca2的贡献率为29.89027%,前3个pc的累积贡献率为92.68794%,直到前6个pc的累积贡献率为97.92108%,之后的各pc贡献率都小于1%且累积贡献率提高速度逐步变小;
59.并分别绘制全段msc光谱和选出有明显差异波段msc光谱中的前两个主成分的散点图,如图3
‑
4所示;
60.步骤6:以支持向量机svm、随机森林rf和极限学习机elm三个方法建模,分别将主成分分析后全段smc光谱和选出有明显差异波段后主成分分析的msc光谱作为输入变量,建立svm、elm和rf梅花鹿鹿角帽和马鹿鹿角帽的识别模型。
61.优选地,所述步骤2中的漫反射光谱采集软件的波数范围为4000
‑
400cm
‑
1,分辨率为4cm
‑
1,扫描次数为16次,每个样本重复扫描3次,取平均光谱;
62.光谱采集过程中,室内温度设置为25度,湿度设置为35%。
63.优选地,所述步骤5中主成分的个数选择方法为方法一和方法二的结合;
64.其中,所述方法一为主成分的个数累积贡献率至少要大于等于85%,所述方法二为主成分特征值大于等于1;在全段光谱数据上,选择前8个主成分构成主成分降维后的光
谱数据,又在选出有明显差异波段的光谱数据上,选择前6个主成分构成主成分降维后的光谱数据。
65.优选地,支持向量机svm是最好的有监督学习算法之一,该算法基于内核对线性和非线性问题的极限进行建模,可以解决支持分类和回归问题,它对于“过拟合”也非常可行,尤其是在小样本中。所述步骤6中的支持向量机svm的具体方法为:首先训练集采用k
‑
cv交叉验证同时支持向量机svm需要确定最佳惩罚因子c、核函数参数g及最优核函数;
66.采用网络搜索法,所述最佳惩罚因子c设置为2
‑
15~215,所述核函数参数g的范围设置为2
‑
15~215,步长为0.1,使用径向基核函数作为最优核函数;
67.svm建模对比,基于全段smc光谱,和选出有明显差异波段后主成分分析的msc光谱不同模型训练集,测试集识别效果与确定的c,g如图5
‑
8所示。由图5
‑
8知全段smc光谱和选出有明显差异波段后主成分分析的msc光谱所建模型训练集和预测集识别率均为100%,说明svm对鹿角帽种类识别具有良好效果。
68.优选地,随机森林rf是一种很灵活实用的方法,具有极好的准确率,能够评估各个特征在分类问题上的重要性,对于缺省值问题也能够获得很好得结果,在bf模型中,设置树的棵树影响着最终结果的好坏。所述步骤6中的随机森林rf的具体方法为:采用遗传算法寻找最优棵树及其它影响参数,遗传算法中待优化的变量个数设置为2,个体数目设置为20,最大遗传代数设置为200,变量的二进制位数设置为10,代沟设置为0.95,交叉变异概率设置为0.7,变异概率设置为0.01;
69.建立随机森林模型,用遗传算法寻找树的目数,基于全段smc光谱树的目数为500和选出有明显差异波段后主成分分析的msc光谱树的目数为600,建模结果如图9
‑
14所示。由图9
‑
14可知,在全段smc光谱建模中训练集识别率为100%,测试集识别率为95.8333%,有1份梅花鹿鹿角帽识别错误。在选出有明显差异波段后主成分分析的msc光谱建模中,训练集识别率为100%,测试集识别率为87.5%,有3份梅花鹿鹿角帽识别错误,说明所建立模型出现了过拟合的情况,整体来说全段smc光谱建模识别率高于选出有明显差异波段后主成分分析的msc光谱建模识别率。
70.优选地,极限学习机elm是一种新型的快速学习算法,学习可以不需要调整隐层节点,也就是说elm网络隐藏层节点的权重随机生成或者人工定义,学习过程仅需计算输出权重,具有训练参数少、学习速度快、泛化能力强的优点。elm模型中隐藏节点设置数量与训练集和测试集正确率有直接关系,同时隐藏节点数量的增加又会使算法耗时时间延长,所以根据相关文献对隐藏节点数量的选择为隐层节点数大于训练数据集数量后,正确率增加不明显,且有波动,所述步骤6中的极限学习机elm中的隐藏节点数量设置为40
‑
100,比较得出最优的隐藏节点数量;
71.在elm模型中,选择sigmoidal函数作为激活函数,设置隐藏节点数量为40
‑
100,步长为1进行比较,得表2(为避免数据过于密集,此处仅展示隐藏节点数量从40起以步长为10的建模结果)和图15
‑
18。由表2知当全段smc光谱建模隐藏节点数量为60,训练集识别率为100%,测试集识别率为95%,有一份梅花鹿鹿角帽识别错误;当选出有明显差异波段后主成分分析的msc光谱建模隐藏节点数量为50,训练集识别率为100%,测试集识别率为95.833%,有一份梅花鹿鹿角帽识别错误。总体来说elm算法在2种建模情况下都有稳定的识别效果。
72.从rf建模效果可以看出,光谱数据特征的提取上采用全段光谱建模的预测集识别率为100%明显高于差异光谱建模的测试集识别率87.5%。从elm模型中也能看出全段光谱建模预测集识别率为100%略高于差异光谱建模的预测集识别率95.8333%。由此可得全段光谱建模效果总体优于差异光谱建模效果。从建模方法上对比,svm模型平均识别率为100%,rf模型平均识别率为93.75%,elm模型平均识别率为97.91665%。可以得出svm不论是在全段光谱还是差异光谱都有很好的识别效果,非常适用于小样本中红外光谱数据的分析。中红外全段光谱数据结合svm建模识别效果最佳,为解决鹿角帽种类和质量检测问题提供了新的思路和方法。
73.在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
74.以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。