技术特征:
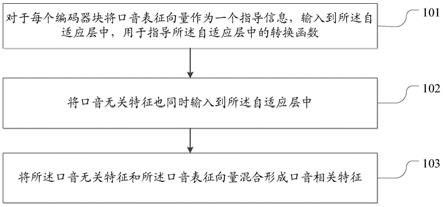
1.一种针对多口音语音识别的方法,其中,对于单语音识别系统,在编码阶段添加自适应层用于学习与口音有关的特征信息,包括:对于每个编码器块将口音表征向量作为一个指导信息,输入到所述自适应层中,用于指导所述自适应层中的转换函数,其中,一个编码器有多个串联的编码器块;将口音无关特征也同时输入到所述自适应层中;将所述口音无关特征和所述口音表征向量混合形成口音相关特征。2.根据权利要求1所述的方法,还包括基于多个基的自适应方法,包括:将所述口音表征向量经过一个预测概率的神经网络,输出对应不同基的概率;同时将口音无关特征输入每一个基里得到基相关的特征;将所述基相关的特征与所述概率合并起来得到口音相关特征。3.根据权利要求2所述的方法,其中,所述基于多个基的自适应方法包括:其中,将每个基的输出b
k
(h
i
)与相应的插值系数α
k
连接起来,缩放f
k
(
·
)和移位g
k
(
·
)的转换函数用于将输入h
i
转换为与口音相关的空间,其中,k=1,2,...,n,其中,n是自适应层基数,转换函数包括仅缩放操作和仅移位操作。4.根据权利要求3所述的方法,其中,为了从口音表征向量z估计插值系数α∈rn,使用了插值参数预测器p(
·
)模型,公式如下:其中,插值系数α=(α1,...,αn)是多个基的概率,插值参数预测器p(
·
)由几个dnn层组成。5.根据权利要求2所述的方法,还包括:应用多任务学习方案来利用辅助任务的损失规范语音识别系统和预测器模型的训练,其中,来自预测器的辅助损耗被引入语音识别系统损耗l
jca
,然后整个系统的最终损耗l
mtl
计算为:其中,α
(ref)
是插值参数预测器输出p(z)的目标标签,α是插值参数预测器输出,γ
mtl
是控制参数的超参数插值参数预测器损失的贡献;通过从预训练的aid模型提取的口音表征向量的聚类获得目标标签α
(ref)
。6.根据权利要求1所述的方法,还包括:直接利用所述口音表征向量生成转换函数,将缩放因子f(z)和移位因子g(z)应用于输入特征以进行重音调整:
其中,a
g
是门控适配器层,
⊙
表示元素级乘积,f(z)和g(z)由具有tanh(
·
)活化作用的单个致密层分别生成。7.一种针对多口音语音识别的装置,其中,对于单语音识别系统,在编码阶段添加自适应层用于学习与口音有关的特征信息,包括:指导程序模块,配置为对于每个编码器块将口音表征向量作为一个指导信息,输入到所述自适应层中,用于指导所述自适应层中的转换函数,其中,一个编码器有多个串联的编码器块;无关输入程序模块,配置为将口音无关特征也同时输入到所述自适应层中;混合程序模块,配置为将所述口音无关特征和所述口音表征向量混合形成口音相关特征。8.一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1至6任一项所述方法的步骤。9.一种存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现权利要求1至6任一项所述方法的步骤。
技术总结
本发明公开针对多口音语音识别的方法和装置,其中,一种针对多口音语音识别的方法,其中,对于单语音识别系统,在编码阶段添加自适应层用于学习与口音有关的特征信息,包括:对于每个编码器块将口音表征向量作为一个指导信息,输入到所述自适应层中,用于指导所述自适应层中的转换函数,其中,一个编码器有多个串联的编码器块;将口音无关特征也同时输入到所述自适应层中;以及将所述口音无关特征和所述口音表征向量混合形成口音相关特征。本申请实施例进一步探讨了适应层的注入位置、口音基数和不同类型的口音基数,以实现更好的口音适应。应。应。
技术研发人员:钱彦旻 龚勋 卢怡宙 周之恺
受保护的技术使用者:思必驰科技股份有限公司
技术研发日:2021.05.28
技术公布日:2021/11/2
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。