确定由医学成像数据表示的身体区域
1.相关申请的交叉引用本技术要求保护来自2021年8月5日提交的欧洲专利申请第21189986.9号的优先权的权益,其内容通过引用并入本文中。
技术领域
2.本框架涉及用于确定由存储在图像文件中的医学成像数据表示的身体区域的方法和装置。
背景技术:
3.诸如磁共振成像(mri)、计算机断层摄影(ct)等医学成像是医学诊断的宝贵工具。在临床决策制定中,患者疾病随时间的进展对于诊断而言即便不比该疾病的当前状态更有用,也是与该疾病的当前状态同样有用的。为了帮助评估患者疾病的进展,医学专业人员常常希望将患者的当前医学图像与患者的适当先前医学图像或医学图像系列进行比较。
4.然而,常常存在患者的大量先前医学图像。例如,对于任何给定患者,可能存在在多个先前时间点处采取的多个先前研究。此外,在每个研究内,可能存在多个医学图像系列,每个系列具有不同的特性。手动地评估先前医学图像的适当性以用于与当前医学图像进行比较或者以其他方式评估它们与当前医学图像的相关性对于医学专业人员来说可能是耗时且繁重的。此外,医学图像常常被存储在远离医学专业人员终端的存储装置中,并且检索患者的所有先在医学图像(其常常在大小方面是大的)对于医学专业人员进行评估来说是网络资源密集的。
5.自动地选择适合于与给定医学图像(例如,当前医学图像)进行比较或以其他方式与该给定医学图像相关的医学图像(例如,先前医学图像)将是有用的。替代地或附加地(例如,为了便于选择相关的医学图像或出于其他原因),自动地确定由医学图像表示的身体区域将是有用的。然而,分析表示该图像的医学成像数据以确定由此表示的身体区域将涉及医学成像数据的提取和处理,该医学成像数据典型地是大的并且将是资源密集的。
技术实现要素:
6.根据一个方面,提供了一种确定由存储在第一图像文件中的医学成像数据表示的身体区域的计算机实现方法,第一图像文件进一步存储一个或多个属性,每个属性具有包括指示该医学成像数据的内容的文本串的属性值,该方法包括:(a)获得第一图像文件的文本串中的一个或多个;以及(b)将文本串中的所获得的一个或多个输入到经训练的机器学习模型中,该机器学习模型已经被训练成基于一个或多个这种文本串的输入来输出身体区域,以及从经训练的机器学习模型获得输出,由此确定由该医学成像数据表示的身体区域。
附图说明
7.图1是图示了根据一示例的方法的流程图;
图2是图示了根据一示例的包括医学成像数据的图像文件的示意图;图3是图示了根据一示例的包括医学成像数据的医学数字成像和通信(dicom)文件的示意图;图4是图示了根据一示例的组件之间的流程的示意图;图5是图示了根据一示例的图形用户界面(gui)的示意图;图6是图示了根据一示例的方法的流程图;图7是图示了根据一示例的组件之间的流程的示意图;图8是图示了根据一示例的方法的流程图;图9是图示了根据一示例的组件之间的流程的示意图;图10是图示了根据一示例的系统的示意图;以及图11是图示了根据一示例的计算机的示意图。
具体实施方式
8.参考图1,图示了确定由存储在第一图像文件中的医学成像数据表示的身体区域的计算机实现方法。
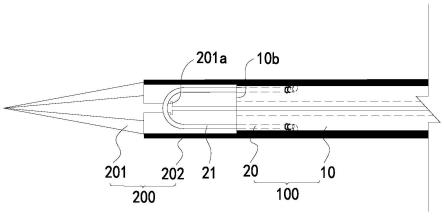
9.图2中图示了示例第一图像文件。第一图像文件200存储医学成像数据204,并且进一步存储一个或多个属性202,每个属性202具有包括指示医学成像数据204的内容的文本串的属性值206。
10.医学成像数据204是表示医学图像(或在某些示例中多于一个医学图像)的数据。例如,医学成像数据204可以包括像素或体素值的阵列或列表。例如,当由合适的图像查看软件处理时,医学成像数据导致了其所表示的医学图像(或多个医学图像)的渲染。一个或多个属性值与医学成像数据分离并且不同于医学成像数据,并且取而代之包括指示医学成像数据204的内容的文本串。在一些示例中,这种属性值可以被称为图像文件200的元数据。在一些示例中,图像文件200中的存储属性202和属性值206的部分可以被称为图像文件200的头(header),并且属性202和属性值206可以被称为图像文件200的头数据。
11.图像文件200的具体示例是医学数字成像和通信(dicom)文件300。图3中图示了示例dicom文件,如下面更详细地描述的。概括地,dicom文件300将医学成像数据316存储为指定数据元素312中的像素数据,并且进一步将一个或多个属性310存储为一个或多个其他数据元素310,每个属性310具有包括指示医学成像数据316的内容的文本串的属性值314。示例这种dicom属性310是“研究描述”,其属性值314是文本串,该文本串描述了该医学成像数据是其一部分的研究(例如,“neruo^head”,其中该医学成像数据属于患者的头部区域),并且由此指示医学成像数据316的内容。还存在这种dicom属性的其他示例,诸如“系列描述”、“所检查的身体部位”以及其他。
12.返回到图1,概括地说,该方法包括:(a)在步骤102中,获得第一图像文件200、300的文本串206、314中的一个或多个;以及(b)在步骤104中,将文本串中的所获得的一个或多个206、314输入到经训练的机器学习模型(参见例如图4的经训练的神经网络406)中,机器学习模型406已经被训练成基于一个或多个这种文本串的输入来输出身体区域,以及从经训练的机器学习模型406获得
输出,由此确定由医学成像数据204、316表示的身体区域408。
13.通过将第一图像文件200、300的一个或多个文本串206、314输入到被训练成基于输入这种文本串来确定身体区域的机器学习模型406(例如,神经网络)中来确定由医学成像数据204、316表示的身体区域408可以提供对由医学成像数据表示的身体区域408的高效和/或灵活的确定。
14.例如,与例如通过提取和分析医学成像数据本身(其在比特方面相对大)来确定身体区域相比,基于该文件的文本串(其在比特方面相对小)来确定身体区域可以是较不资源密集的,并且因此更加高效。在其中该图像文件通过网络与处理设备远离地存储的情况下,基于(相对小的)文本串来确定身体区域允许(相对大的)医学成像数据不需要通过网络被传输以便确定由此表示的身体区域,因此使得高效利用了网络资源。
15.作为另一个示例,例如与通过将硬编码规则应用于文本串来确定身体区域相比,通过将文本串输入到经训练的机器学习模型(例如,经训练的神经网络)中来确定身体区域可以提供对身体区域的高效、灵活和/或鲁棒的确定。例如,硬编码规则需要文本串与规则的确切匹配以便提供身体区域(并且因此关于针对其可以确定匹配的文本串是不灵活的,和/或在需要针对可以使用的所有可能文本串被编码的规则集的穷举性质方面是低效的)。另一方面,经训练的机器学习模型(例如,经训练的神经网络)从它在其上被训练的训练数据集进行泛化,并且因此既获得起来相对高效,又能够确定适当的身体区域,即使针对与训练数据集中的那些文本串不同的文本串也是如此,并且因此是相对灵活/鲁棒的。
16.因此,可以提供对由医学成像数据表示的身体区域的有效和/或灵活的自动确定。
17.在一些示例中,在给定时间处并且对于给定患者,放射科医师可以对患者执行医学成像研究。不同的研究可以在不同的时间处执行。特定研究可能针对患者的特定身体部位,并且使用特定成像模式(例如,mr)。在一些情况下,不同的研究可能是患者的不同身体部位的研究和/或具有不同的成像模态(即,由不同的设备捕获)。给定研究可以包括一个或多个医学图像系列。例如,在研究内的给定系列内,可能已经使用相同的成像参数(例如,患者取向、诸如回波时间等的mr特定成像参数)捕获了医学图像。研究内的每个系列可能具有不同的成像参数。在一些示例中,图像文件200存储表示特定系列内和特定研究内的图像的医学成像数据204。存储了表示作为相同研究的一部分的医学图像的医学成像数据204的图像文件200可以例如具有相同的唯一研究id,并且存储了表示作为相同系列的一部分的医学图像的医学成像数据204的图像文件200可以例如具有相同的唯一系列id。在任何情况下,给定研究可以具有至少一个这种图像文件200的至少一个系列。
18.在一些示例中,对由第一图像文件200的第一医学成像数据表示的身体区域的确定可以进而便于将第二个这种文件的第二医学成像数据自动选择为与第一医学成像数据相关(例如,适合于与第一医学成像数据进行比较)。例如,确定由当前研究的文件的医学成像数据表示的身体区域可以用于选择患者的相同身体区域的先前研究的医学成像数据。下面将参考图4和图5对此进行更详细的描述。
19.如上所提到的,在一些示例中,第一图像文件200、300可以是dicom文件300(即,以dicom文件格式的图像文件,例如根据dicom标准“nema ps3/iso 12052,医学数字成像和通信(dicom)标准、国家电气制造商协会,美国弗吉尼亚州罗斯林”)。再次参考图3,更详细地,dicom文件300包括头302和数据集308。头302包括128字节前导码304(如果不被使用的话,
其所有字节被设置为零)和包含字符串“dicm”的4字节前缀306。数据集308包含数据元素310、312。每个数据元素310、312包括标记并且由其标识。每个标记采用格式(xxxx,xxxx),其中每个“x”是十六进制数。dicom文件300可以在“研究id”数据元素(未示出)(即,由dicom标记(0020,0010)标识)中存储该文件是其一部分的研究的唯一标识符,并且可以在“系列id”数据元素(未示出)(即,由dicom标记(0020,000e)标识)中存储该文件是其一部分的系列的唯一标识符。
20.dicom文件300将医学成像数据316(在这种情况下是像素数据316)存储在dicom文件300的“像素数据”数据元素312(即,由dicom标记(7fe0,0010)标识)中。dicom文件300进一步存储一个或多个属性310(由一个或多个其他数据元素310提供),每个属性具有包括指示医学成像数据316的内容的文本串的属性值314。例如,一个这种属性可以是“研究描述”(即,由dicom标记(0008,1030)标识),其属性值314是文本串,该文本串描述了该医学成像数据是其一部分的研究(例如,“neruo^head”,其中该医学成像数据是患者的头部区域,或“pelvis^prostate”,其中该医学成像数据是患者的骨盆区域),并且由此指示医学成像数据316的内容。在一些示例中,尽管属性310和属性值314可能不被包括在头302中,照此而是被包括在数据集308中,但是属性310和属性值314(不包括存储医学成像数据316本身的数据元素312)有时可以被称为dicom文件300的头数据,因为这些是与医学成像数据316相关的数据,而不是医学成像数据316本身。
21.可以使用具有包括指示医学成像数据的内容的文本串的属性值的其他示例dicom属性。例如,另一个这种示例dicom属性是“系列描述”(即,由dicom标记(0008,103e)标识),其描述了医学成像数据是其一部分的系列(例如,“ax t1整个骨盆”,其指示该医学成像数据属于整个骨盆,是以轴向取向并且使用t1类型mri被捕获的)。例如,另一个这种dicom属性示例是“所检查的身体部位”(即,所标识的dicom标记(0018,0015)),其指示所检查的身体部位(例如,“pelvis”,其指示该医学成像数据属于骨盆)。应当领会的是,存在并且可以使用其他这种合适的dicom属性。在一些示例中,也可以使用dicom属性“请求手术的原因”(即,由dicom标记(0040,1002)标识)。
22.此外,应当领会的是,在一些示例中,可以使用除了dicom文件之外的这种图像文件。例如,图像文件可以是便携式网络图形(png)文件,该文件在其组块(chunk)中的一个中存储医学成像数据,并且在其组块中的另一个中存储包括一个或多个属性的元数据,每个属性具有包括指示医学成像数据的内容的文本串的属性值。
23.在一些示例中,一个这种文本串可以被输入到经训练的机器学习模型(例如,经训练的神经网络)中。然而,在其他示例中,来自第一图像文件的多个属性的多个属性值的多个这种文本串可以被一起输入到经训练的机器学习模型(例如,经训练的神经网络)中,以便确定由第一文件的医学成像数据表示的身体部位。例如,这可以提供对身体区域的更准确和/或鲁棒的确定。例如,经训练的机器学习模型(例如,经训练的神经网络)确定身体区域的准确度可以通过增加该确定所基于的输入数据(来自第一文件的这种文本串的数量)来改进。作为另一个示例,如果文本串中的一个碰巧是不可靠的和/或缺失的(例如,如已经发现的,可能是针对例如“所检查的身体部位”的情况,因为它不是由放射科医师常规地或可靠地填写的),则多个文本串的输入可以减轻这种情况,并且仍然允许对要确定的身体区域的可靠确定。
24.图4图示了根据一示例的上面参考图1至3描述的方法的组件之间的流程。参考图4,如所提到的,第一图像文件402的文本串404中的一个或多个被输入到经训练的机器学习406中,并且经训练的机器学习模型406输出身体区域408。文本串404、图像文件402、经训练的机器学习模型406和/或身体区域408可以与上面参考图1至3描述的那些相同或相似,和/或可以如上面参考图1至3描述的那样被使用。
25.在一些示例中,如所图示,可以从第一图像文件402中提取一个或多个文本字符串404。具体地,可以从第一图像文件402提取一个或多个文本串404,而不提取其医学成像数据。例如,采用dicom文件300作为示例,可以解析该图像文件以定位一个或多个预定义的标记,该标记标识了具有要提取的属性值的属性(例如,针对“研究描述”属性的dicom标记(0008,1030)、以及针对“系列描述”的dicom标记(0008,103e))。一旦标记被定位,就可以从图像文件402中提取由该一个或多个标记标识的一个或多个属性的属性值(即,文本串404)。所提取的文本串404可以例如与图像文件402或其医学成像数据的标识符相关联地存储。在一些示例中,图像文件402的文本串404可能已经从图像文件402中被提取或者以其他方式在该方法被执行之前被获得,并且例如与图像文件402或其医学成像数据的标识符相关联地存储。在任一种情况下,一个或多个文本串404被获得并且被输入到经训练的机器学习模型406中。
26.在一些示例中,可以使用仅一个文本字符串。然而,在一些示例中,图像文件402的多个文本串404可以被获得并且被输入到经训练的机器学习模型406中。例如,dicom文件402的所有属性“研究描述”、“系列描述”和“所检查的身体部位”的属性值的文本串可以被获得,并且被输入到经训练的机器学习模型406中,使得经训练的机器学习模型406基于所有这些输入文本串来输出由该文件的医学成像数据表示的身体区域。例如,文本串可以被级联并且被一起输入到经训练的机器学习模型406中。在任何情况下,来自经训练的机器学习模型406的输出408被获得,由此确定由医学成像数据表示的身体区域408。
27.如所提到的,机器学习模型406已经被训练成基于一个或多个这种文本串的输入来输出身体区域。也就是说,该机器学习模型被训练成:基于图像文件的一个或多个属性的一个或多个属性值的指示医学成像数据的内容的一个或多个文本串的输入,来输出由该图像文件的医学成像数据表示的身体区域。
28.在一些示例中,经训练的机器学习模型406可以是经训练的神经网络406。实际上,在下文描述的示例中,将参考经训练的神经网络406。然而,应当领会的是,在其他示例中,可以使用被训练成基于一个或多个文本串的输入来输出身体区域的其他类型的机器学习模型。例如,在其他示例中,经训练的机器学习模型可以采取经训练的随机森林算法等的形式。例如,随机森林算法可以包括在训练数据上训练的决策树的全体,该训练数据包括利用其相关联的身体区域被加标签的训练文本串(例如,如由专家所确定的),即,配置决策树的全体,以便与训练文本串的被加标签的身体区域相比,最小化该身体区域的预测中的误差。然而,如在下文中提到的,参考经训练的神经网络406的示例。使用经训练的神经网络406可以具有某些优点,如下文更详细讨论的那样。
29.在一些示例中,神经网络406可以是深度神经网络(即,具有一个或多个隐藏层)。在一些示例中,可以使用有监督学习来训练神经网络。例如,可以使用包括多个训练文本串(实际上可以有100或1000个训练文本串)的训练数据集来训练神经网络406,每个训练文本
串来自图像文件的属性的属性值并且指示进一步被存储在图像文件中的医学成像数据的内容。例如,训练文本串可以是从dicom图像文件的适当属性(例如,“研究描述”、“系列描述”、“所检查的身体部位”等)的属性值中提取的文本串。在一些示例中,类似于如上所描述,每个训练文本串可以表示图像文件的不同适当属性的多个个体的这种文本串的级联。在任何情况下,每个训练文本串可以利用该训练文本串所对应的身体区域来加标签。例如,在一些示例中,训练文本串可以利用由该训练文本串所源自的文件的医学成像数据所表示的实际身体区域来加标签,该实际身体区域例如由专家从业者来确定。在一些示例中(如下面参考图5更详细地描述的),训练文本串可以利用被确定为如例如专家所确定的那样对应于该文本串本身或者由该文本串本身表示的身体区域来加标签。在任一种情况下,每个文本串的身体区域标签可以在神经网络的训练中用作监督信号。
30.在一些实例中,经训练的神经网络406可以被配置成以身体区域分类的形式来输出身体区域408,该身体区域分类是经训练的神经网络406的分类器部分针对输入的一个或多个文本串从多个身体区域分类当中选择的。例如,每个分类可以是表示身体区域的标准化单词,诸如“abdomen(腹部)”、“pelvis(骨盆)”、“chest(胸部)”等。在这种示例中,每个训练文本串可以利用其所属的分类来加标签,并且这可以用作用于训练神经网络的监督信号。例如,该训练可以包括深度学习。例如,该训练可以包括更新神经网络中的神经元的层之间的连接的权重,以便最小化由分类器针对训练文本串中的每一个所预测的分类与由训练文本串的相应标签所定义的训练文本串中的每一个的实际分类之间的误差。
31.在一些实例中,经训练的神经网络406可以被配置成以一个或多个数值的形式来输出身体区域408,该一个或多个数值表示经训练的神经网络406的回归器部分已经针对输入的一个或多个文本串404所计算的人类身体区域。例如,一个或多个数值可以是“身体标尺”的数值,即针对人类身体定义的标尺或刻度,其中0.0的值表示人类脚趾的尖端,并且1.0的值表示人类头部的最顶部部分(例如),其中0和1之间的值表示脚趾尖端与头部顶部之间的人类身体的相应区域。在一些示例中,可以使用两个这样的数值来表示人类身体的身体区域。例如,这两个值可以指示在其之间定义了身体区域的位置。例如,可以向膀胱指派身体标尺值[0.5,0.55]。在这种示例中,每个训练文本串可以利用表示其所对应的身体区域的一个(或多个,例如两个)数值来加标签,并且这可以用作用于训练神经网络406的监督信号。例如,该训练可以包括深度学习。例如,该训练可以包括更新神经网络中的神经元的层之间的连接的权重,以便最小化由回归器针对训练文本串中的每一个所预测的一个(或多个)数值与由训练文本串的相应标签所定义的训练文本串中的每一个的实际一个(或多个)数值之间的误差。
[0032]
将身体区域输出为一个或多个数值可以允许对由文件的医学成像数据表示的身体区域的精确和/或灵活的确定。例如,数值是连续的,并且因此例如与使用预定义类别的有限集合相比,能够更精确地并且以更多的灵活性来定义身体区域。这可以进而允许对身体区域的灵活和/或精确的比较,例如当选择与第一医学成像数据相关的第二医学成像数据时,如下面参考图6更详细地描述的。
[0033]
在一些示例中,经训练的神经网络406可以是经训练的基于字符的神经网络406,其被配置成将文本串中的所获得的一个或多个404的个体字符作为输入。在这些示例中,将文本串中的所获得的一个或多个404输入到经训练的神经网络406中可以包括将文本串中
的所获得的一个或多个的个体字符输入到经训练的神经网络406中。例如,神经网络406可以包括编码器,该编码器被配置成将输入文本串的每个字符编码成向量。例如,这可以使用字符嵌入来完成,诸如针对包括字母表、数字1到9和特殊字符的字符词汇表进行独热(1-hot)编码。这些向量可以由神经网络406用作确定身体区域的基础。可以使用不同的架构。
[0034]
例如,在一些示例中,神经网络406可以包括基于字符的递归神经网络(rnn),诸如长短期记忆(lstm)rnn,诸如双向ltsm。文本串的每个字符的向量可以被顺序地输入到rnn中,在此之后,rnn将具有某个内部状态(例如,表示其神经元在文本串的最后一个字符的向量被输入时的值的向量)。该内部状态然后可以被传递到神经网络406的回归器或分类器,该回归器或分类器然后可以将该内部状态映射到身体区域408上。
[0035]
作为另一个示例,神经网络406可以包括基于字符的卷积神经网络(cnn)。在这些示例中,文本串的相继字符的向量可以并排组装以创建矩阵。然后,可以对该矩阵应用卷积和池化操作,以确定表示文本串中存在的特征的压缩特征向量。该特征向量然后可以被传递到神经网络406的回归器或分类器,该回归器或分类器然后可以将该特征向量映射到身体区域上。可以通过其准确地映射身体区域的特征本身可以在神经网络406的训练期间被学习。
[0036]
在一些示例中,可以使用其他神经网络,例如基于单词的神经网络。然而,包括基于字符的神经网络的神经网络406可以提供如下身体区域确定:该确定对于不是训练数据的一部分的缩写或错误拼写或其他单词是鲁棒的。例如,“abdomen”可以缩写为“abd”,但是由于前几个字母是相同的,因此基于字符的神经网络可以针对在向量空间中处于相似位置的这两个单词生成向量(并且因此适当的身体区域可以被确定),而基于单词的神经网络可能会将“abd”确定为在词汇表之外。这反过来可以帮助提供准确的确定,这是由于词汇表之外的单词可能会降低准确度。
[0037]
如所提到的,每个训练文本串可以利用该训练文本串所对应的身体区域来加标签,并且在一些示例中,训练文本串可以利用被确定为如专家所确定的那样对应于该文本串或者由该文本串表示的身体区域来加标签。如参考图5所描述,在这种情况下,可以使用图形用户界面(gui)502来生成训练数据集(包括训练文本串以及其标签)。gui 502可以被配置成向用户呈现训练文本串508中的一个或多个以及被划分成可选身体区域511的人类身体510的表示。gui可以被配置成:针对一个或多个所呈现的训练文本串508中的每一个,接收选择了来自表示510的身体区域511的用户输入,并且利用指示所选身体区域511的标签509来对训练文本串508加标签。以这种方式,可以生成包括利用身体区域标签被加标签的训练文本串的训练数据集。
[0038]
例如,参考图5中的具体示例,gui 502包括进度条504,进度条504向用户指示当前正在显示的gui的特定窗格。还示出了特定窗格的标题506,在这种情况下,该标题506是“标注关键词”。在该示例中,训练文本串508是从存储了医学成像数据的图像文件的属性的属性值中提取的关键词。在所图示的示例中,关键词包括“aaa”、“ab”、“abdpel”、“abdroutine”、“aquired”、“aif”、“angiogram”和“ascities”。用户被呈现了特定关键词(在这种情况下是粗体的“aaa”),并且被要求选择其所对应的身体表示510的所显示的身体区域511之一。例如,作为专家并且知道医学成像情境中的“aaa”是“abdominal aortic aneurysm(腹主动脉瘤)”的缩写的用户选择所显示的身体表示511的腹部部分,并且因此文
本串“aaa”利用身体区域标签“abdomen”来加标签。可以针对其他所呈现的关键词进行类似选择:“ab”——“abdomen”、“abdpel”——“abdomen”、“abdroutine”——“abdomen”、“aif”——“head”、“angiogram
’”
——“chest”和“ascities”—“abdomen”。要注意的是,“acquired”文本串没有利用身体区域被加标签,因为它不与任何特定身体区域相关联,并且因此将不会形成训练数据集的一部分。gui 502还包括可选按钮512,即“子宫”、“前列腺”、“未知”和“无”。“子宫”和“前列腺”按钮是为了分别提供“prostate(前列腺)”和“uterus(子宫)”的身体部位标签。“未知”按钮用于如果用户不知道身体区域标签但是例如怀疑它能够被指派身体区域标签,并且“无”按钮用于如果用户知道没有身体区域可被分配给该文本串(例如,如上面的“acquired”的情况)。
[0039]
gui 502可以允许以简单且高效的方式来生成包括具有身体区域标签的多个(例如,100个)训练文本串的训练数据集。标签是使用人类身体的表示(例如,风格化图片)来获得的,该表示对于用户(包括医学专业人员并且不一定是编程专家)来说是可视且简单的以便与其交互。用户与gui的这种简单且高效的交互可以进而允许高效地生成训练数据集(即,要加标签的文本串)。
[0040]
在上面描述的示例中,神经网络406被训练成基于输入文本串来输出身体区域408。在一些示例中,神经网络406可以被进一步训练成基于一个或多个文本串的输入来输出输出身体区域408的偏侧性。偏侧性可以指代由医学成像数据表示的身体区域位于身体的哪一侧(即,“左”或“右”)。例如,在适当时,输出偏侧性可以是“左”或“右”。在这些示例中,图1的方法的步骤104可以进一步包括:基于经训练的神经网络406的所获得的输出来确定由医学成像数据表示的身体区域的偏侧性。作为一个示例,这可以通过提供被训练成基于一个或多个文本串的输入来输出偏侧性的神经网络406的专用偏侧性部分来实现。例如,这可以使用包括训练文本串的训练数据集来训练,每个训练文本串是利用该文本串所对应的身体区域的偏侧性来加标签的。作为另一个示例,这可以通过如下方式来进行:扩展神经网络406将输入文本串映射到其上的身体区域分类的集合,以包括每个身体区域分类的“左”和“右”版本。例如,这可以使用包括训练文本串的训练数据集来训练,每个训练文本串是利用该训练文本串所对应的身体区域和偏侧性分类来加标签的。确定身体区域的偏侧性可以允许确定更精确的身体区域,这可以进而允许对相关第二医学成像数据的更准确的选择,如下面更详细地描述的。
[0041]
如所提到的,在一些示例中,由第一医学成像数据表示的所确定的身体区域可以用于选择与第一医学成像数据相关(例如,适合于与第一医学成像数据进行比较)的第二医学成像数据。例如,可以针对给定患者的当前研究的第一医学成像数据确定身体区域,并且这可以用于选择适合于与当前研究(例如,相同或相似的身体区域)进行比较的针对给定患者的一个或多个先前研究的第二医学成像数据的一个或多个集合(例如,被包含在一个或多个图像文件中)。现在参考图6,图示了选择与第一医学成像数据相关的第二医学成像数据的方法。
[0042]
该方法包括:在步骤602中,将由存储在第一图像文件402中的第一医学成像数据表示的第一身体区域408与由存储在相应多个第二图像文件中的第二医学成像数据的相应多个集合表示的多个第二身体区域中的每一个进行比较。该方法包括:在步骤604中,基于身体区域的比较,将第二医学成像数据的集合中的一个或多个选择为与第一医学成像数据
相关。
[0043]
第二图像文件中的每一个可以属于与第一图像文件402相同的类型。即,每个第二图像文件进一步存储一个或多个属性,每个属性具有包括指示存储在第二图像文件中的第二医学成像数据的内容的文本串的属性值。第一身体区域408可能已经通过将上面参考图1描述的方法的步骤102和104应用于第一图像文件402的一个或多个文本串而被确定。替代地或附加地,第二身体区域中的至少一个(并且在一些情况下是全部)可以通过将上面参考图1描述的方法的步骤102和104应用于第二图像文件中的相应的至少一个(并且在一些情况下是全部)的一个或多个文本串来确定。
[0044]
图7图示了根据一示例的上面参考图6描述的方法的组件之间的流程。参考图7,在该示例中,类似于如上参考图4所描述,来自第一图像文件402的一个或多个文本串404被输入到经训练的神经网络406中,并且经训练的神经网络406输出第一身体区域408。第一身体区域408可以与第一图像文件402的标识符(未示出)相关联地存储。
[0045]
此外,在该示例中,从存储在存储设备714中的相应多个第二图像文件(例如,属于与第一图像文件402相同的患者)中提取多个一个或多个文本串716。例如,该多个第二图像文件中的每一个可以来自患者的不同先前研究。第二图像文件的多个一个或多个文本串716中的每一个被依次输入到经训练的神经网络720中,以获得相应多个第二身体区域720。第二身体区域中的每一个可以与相关联的第二图像文件的标识符(未示出)相关联地存储。照此,例如,可以确定在多个先前研究中的每一个的图像文件中示出的身体区域。然后,可以通过比较器710将第一身体区域408与多个第二身体区域720中的每一个进行比较,并且可以基于该比较来做出对第二医学成像数据的集合中的一个或多个的选择712。
[0046]
在一些示例中,该选择可以仅基于该比较。在其他示例中,该选择可以基于如下面更详细地描述的另外标准。在一些示例中,该选择可以是对身体区域与其相关联地存储的第二图像文件的标识符的选择。所选的标识符可以用于询问存储设备714并且从存储设备714(例如,在线或近线dicom存档设备)检索(例如,预取)相关联的第二图像文件。
[0047]
在一些示例中,可以从存储设备714检索包括第二医学成像数据的一个或多个所选集合之一的那些研究(例如,仅那些研究)的医学成像数据或图像文件。可以例如通过匹配包含所选第二医学成像数据的文件的“研究id”属性来确定这些文件。在一些示例中,如下面更详细地描述的,可以从存储设备714检索包括第二医学成像数据的所选集合中的一个或多个的那些系列(例如,仅那些系列)的医学成像数据或图像文件。可以例如通过匹配包含所选第二医学成像数据的文件的“系列id”属性来确定这些文件。
[0048]
在任何情况下,第二医学图像数据的检索到的集合中的一个或多个的渲染可以被显示在显示设备(参见例如图10的1003)上。
[0049]
在一些示例中,第一医学成像数据可以表示患者的当前医学图像(或医学图像系列),并且第二医学成像数据的多个集合可以表示患者的先前医学图像(或医学图像系列)。例如,第一图像文件可以对应于患者的当前研究,并且第二图像文件中的每一个可以对应于患者的相应的不同先前研究。医学专业人员可能希望将当前研究的一个或多个图像与患者的先前研究中的相关研究的那些图像进行比较,例如,以评估疾病在这两个研究之间的进展。实现高效比较的有用标准是当前和先前研究(即,其当前和先前医学图像)属于相同或相似的身体部位(例如,头部、腹部、足部)。通过基于针对第一医学图像数据和第二医学
成像数据确定的身体区域的比较来自动地选择第二医学成像数据,该方法允许医学专业人员将例如当前研究的医学图像仅与相关先前医学图像(例如,相同或相似身体区域的先前研究的那些医学图像)进行比较,这与用户必须与所有先前医学图像进行比较相比是高效的。
[0050]
此外,在一些示例中,第二医学成像数据的多个集合被存储在远程存储设备714(也参见例如图10的1006)中,该远程存储设备714可以通过网络(参见例如图10的1004)连接到用户的终端(参见例如图10的1002)。在这些情况下,第二医学成像数据的所选的一个或多个集合(或包括第二医学成像数据的所选集合的研究的第二医学成像数据集合)可以从远程存储设备714、1006被检索(例如,从dicom存档设备1006被预取),而不检索第二医学成像数据的多个集合中的其他集合。由于可以基于图像文件的属性的文本串来确定身体区域,因此那些文件的第二医学成像数据一旦被选择为相关,它们就仅需要从远程存储装置714、1006被检索,并且未被选择为相关或要检索的第二医学成像数据根本不需要被检索。照此,可以高效地部署网络资源。
[0051]
在一些示例中,身体区域的比较可以包括确定第一医学成像数据的身体区域分类(例如,“abdomen”、“chest”)是否与第二医学成像数据的身体区域分类相同。在一些示例中,如果存在匹配(例如,两者具有相同的身体区域分类“abdomen”),则第二医学成像数据可以被选择为与第一医学成像数据相关。
[0052]
在一些示例中,身体区域的比较可以包括比较定义了第一和第二医学成像数据的身体区域的数值。例如,这可以包括确定第一医学成像数据的身体区域数值是否与第二医学成像数据的身体区域数值相同或相似或重叠。例如,如果第一医学成像数据的数值是0.5,则具有数值0.45的第二医学成像数据集合可以被选择为相似的(例如,相差小于预定义的量)。作为另一个示例,如果第一医学成像数据的数值是[0.5,0.55],则可以选择具有数值[0.5,0.55]的第二医学成像数据集合,因为它是相同的,并且可以选择具有数值[0.4,0.55]的第二医学成像数据集合,因为它是重叠的。
[0053]
如所提到的,将第二医学成像数据的一个或多个集合(例如,给定患者的先前研究)选择为与第一医学成像数据(例如,给定患者的当前研究)相关可以基于比较其身体区域。然而,在一些示例中,该选择可以基于另外的因素或标准,如下面更详细地描述的。
[0054]
除了示出了相同身体部位的当前和先前研究之外,实现对其图像的高效比较的另一个有用标准是当前和先前研究属于相同或相似的模态(即,用于捕获其图像的医学成像的模式或类型,例如ct、mri、x射线)。
[0055]
因此,在一些示例中,该方法可以包括:针对第二医学成像数据(例如,属于先前研究)的多个集合中的每一个,确定第一医学成像数据(例如,属于当前研究)的第一成像模态与第二医学成像数据(例如,属于先前研究)的第二成像模态之间的成像模态相关性得分。在这些示例中,将第二医学成像数据的一个或多个集合选择为与第一医学成像数据相关可以进一步基于所确定的成像模态相关性得分。例如,具有较高成像模态相关性得分的第二医学成像数据集合中的一个(例如,属于给定患者的先前研究中的一个)可以优先于具有较低成像模态相关性得分的第二医学成像数据集合中的另一个(例如,属于给定患者的先前研究中的另一个)被选择用于第一医学成像数据(例如,属于患者的当前研究)。在一些示例中,可以选择具有与第一医学成像数据相同的身体区域并且具有最高成像模态相关性得分
的第二医学成像数据的集合。在一些示例中,可以预先选择具有与第一医学图像数据相同或相似的身体区域的第二医学成像数据的集合,例如根据上面参考图6描述的方法,并且然后可以基于成像模态相关性得分来从预先选择的集合当中选择第二医学成像数据的一个或多个集合。
[0056]
在一些示例中,用于捕获文件的医学成像数据的成像模态可以从其中存储了医学成像数据的图像文件的成像模态属性的属性值来确定。例如,成像模态可以直接从dicom文件的“模态”属性(例如,由dicom标记(0008,0060)标识)的属性值来获得。dicom“模态”属性值标识了获取了医学成像数据的设备的类型。在dicom标准中,可以表示不同成像模式的值是预先定义的。例如:所定义的是,“ct”表示“计算机断层摄影”,并且“mr”表示“磁共振”等。此外,在一些示例中,可以通过与设备一起使用以生成图像文件的软件来将成像模态属性值自动设置为适当的值。因此,可以直接从文件的“模态”属性可靠地获得成像模态。
[0057]
两个模态之间的成像模态相关性得分可以是表示使用一个模态捕获的医学成像数据与使用另一个模态捕获的医学成像数据相关(即,适合于与另一个模态进行比较或者对于与另一个模态进行比较是有用的)的程度的值。在一些示例中,可以使用成像模态转移矩阵来确定成像模态相关性得分。例如,矩阵的每个元素可以对应于一个特定成像模态与另一个特定成像模态之间的一个成像模态相关性得分。也就是说,矩阵的元素s
ij
可以是具有成像模态i的第一(例如,当前)医学成像数据与具有成像模态j的第二(例如,先前)医学成像数据之间的成像模态相关性得分。例如,i = mr和j = mr之间的成像模态相关性得分(即,s
mrmr
)可以是0.6,而i = mr和j = ct之间的成像模态相关性得分(即,s
mrct
)可以是0.22。在这种情况下,例如,如果使用mr捕获了第一医学成像数据,则如果第二医学成像数据集合中的两个都具有与第一医学成像数据相同的身体区域,但是一个集合是使用mr被捕获的,而另一个集合是使用ct被捕获的,则可以优先选择使用mr被捕获的集合。
[0058]
在一些示例中,成像模态相关性得分(即,转移矩阵的每个元素s
ij
)可以表示:在给定与特定第一成像模态i相关联的第一医学成像数据的情况下,用户(例如,医学专业人员)将选择具有特定第二成像模态j的第二医学成像数据以用于与第一医学成像数据进行比较的概率。例如,该概率可以基于与医学成像数据的被记入日志的用户交互的统计分析来确定。例如,数据日志可以记录由给定医学专业人员在给定环节中已经针对给定患者检索的医学成像文件。可以对这些日志应用统计处理来确定该概率。例如,当查阅其模态是mr的当前医学成像文件时,如果确定医学专业人员继续查阅其成像模态是mr的患者的先前医学成像文件60%的时间,但是继续查阅其成像模态是ct的患者的先前医学成像文件22%的时间,则s
mrmr
可以被确定为0.6,并且s
mrct
可以被确定为0.22。这可以针对成像模态的所有组合进行,以填充转移矩阵。基于与医学成像数据的实际用户交互的统计分析的成像模态相关性得分(即,转移矩阵的每个元素s
ij
)可以帮助确保适当模态的第二医学成像数据被选择。
[0059]
在上面描述的示例中,可以例如基于身体区域和/或成像模态来选择与给定患者的当前研究的医学成像数据相关(例如,适合于与给定患者的当前研究的医学成像数据进行比较)的给定患者的先前研究的医学成像数据。如所提到的,在给定的研究内,可能存在医学图像的多个系列。例如,在给定研究内(具体地在给定模态内,例如mr)的不同系列可以包括已经使用不同成像参数(例如,对于mr:回波时间、翻转角度、回波串长度、患者取向等)捕获的医学成像数据。使得医学专业人员能够有效比较当前和先前医学图像的另一个有用
标准可以是当捕获当前和先前医学图像时使用的医学成像参数是相同或相似的。因此,在一些示例中,第二医学成像数据的选择可以替代地或附加地基于成像参数的比较。例如,可以基于用于捕获先前和当前系列的图像的医学成像参数的比较将给定患者的先前研究内的先前系列的第二医学成像数据选择为与当前系列的第一医学成像数据相关(例如,适合于与当前系列的第一医学成像数据进行比较)。
[0060]
参考图8,图示了基于成像参数来选择相关医学成像数据的方法。
[0061]
在这些示例中,第一和第二图像文件中的每一个存储一个或多个属性,每个属性具有指示用于捕获图像文件的医学成像数据的成像参数的属性值。
[0062]
例如,类似于如上所描述,每个图像文件可以是dicom文件,并且具有指示用于捕获其医学成像数据的成像参数的属性值的一个或多个第一属性包括以下各项中的一个或多个:dicom属性“图像取向患者”(由dicom标记(0020,0037)标识),并且其值指定了医学成像数据的第一行和第一列相对于患者的取向余弦,示例值是“[1,0,0,0,1,0]”;“系列描述”(由dicom标记(0020,0037)标识),并且其值包括该系列的描述,示例值是“ax t1整个骨盆”,指示轴向取向);“回波时间”(由dicom标记(0018,0081)标识),并且其值指定了mr成像中激发脉冲的中间与所产生的回波的峰值之间的时间(以毫秒为单位),示例值是“4.2”;“重复时间”(由dicom标记(0018,0080)标识,并且其值指定了mr成像中脉冲序列的开始和后续脉冲序列的开始之间的时间(以毫秒为单位),示例值为“8”;“翻转角度”(由dicom标记(0018,1314)标识),并且其值指定了mr成像中磁向量从原型场的磁向量被翻转的稳态角度(以度为单位),示例值是“90”;回波串长度'(由dicom属性标记(0018,0091)标识),并且其值指定了每个图像每次激发所获取的k空间(表示mr图像中的空间频率的数字阵列)中的行数,示例值是“1”;“扫描序列”(由dicom标记(0018,0020)标识),并且其值指示所捕获的mr数据的类型,示例值是“se”,指示自旋回波类型mr);“序列名称”(由dicom标记(0018,0024)标识),并且其值指定了mr成像中扫描序列和序列变体的组合的用户定义的名称,示例值是“spcir_242”);以及“协议名称”(由dicom标记(0018,1030)标识),并且其值指定了ct协议的名称,示例值是“t2w_tse sense”)。应当领会的是,在一些示例中,可以使用其他这种属性,并且实际上可以使用其他类型的图像文件。
[0063]
在图8中所图示的示例中,该方法包括:在步骤802中,获得第一医学成像数据的第一向量(参见例如图9的908),该第一向量是基于指示用于捕获第一图像文件(参见例如图9的902)的第一医学成像数据的成像参数的属性值(参见例如图9的904)中的一个或多个而生成的。该方法包括:在步骤804中,获得针对第二医学成像数据的相应多个集合的多个第二向量(参见例如图9的920),其中,对于第二医学成像数据的每个集合,第二向量920是基于指示用于捕获第二图像文件的第二医学成像数据集合的成像参数的属性值(参见例如图9的916)中的一个或多个而生成的。
[0064]
该方法包括:在步骤806中,针对多个第二向量920中的每一个,确定指示第一向量908与第二向量920之间的相似性的相似性度量;以及在步骤808中,基于所确定的相似性度量将第二医学成像数据的集合中的一个或多个(参见例如图9的912)选择为与第一医学成像数据相关。例如,在一些示例中,可以选择第二医学成像数据的多个集合当中具有最高相似性度量的第二医学成像数据集合。在一些示例中,可以选择第二医学成像数据的多个集合当中具有最高的两个或更多个相似性度量的第二医学成像数据的两个或更多个集合。
[0065]
在一些示例中,第二医学成像数据的一个或多个集合的选择(例如,如上面参考图1至图7所描述)可以进一步基于所确定的相似性度量,即,除了上面参考图1至图7所描述的身体区域和/或成像模态相关性得分的比较之外。例如,在一些示例中,先前研究的第二医学成像数据(例如,包含第二医学成像数据的多个系列)可以基于如上面参考图1至图7所描述的身体区域和/或成像模态的比较而在患者的先前研究当中被预先选择为与当前医学成像数据相关;以及该预先选择的研究内的多个系列当中的特定系列的第二医学成像数据可以基于如参考图8描述的所确定的相似性度量被选择为与当前医学成像数据相关。在这种情况下,第二医学成像数据的一个或多个集合(例如,表示给定系列的一个或多个医学图像)可以基于身体区域、成像模态相关性得分和所确定的相似性度量的比较而被选择为与第一医学成像数据相关。
[0066]
然而,在某些其他示例中,参考图8描述的方法可以独立于上面参考图1至图7描述的方法来应用。例如,第二医学成像数据的一个或多个集合的选择可以基于所确定的相似性度量,并且不需要附加地基于上面参考图1至图7描述的身体区域和/或成像模态相关性得分的比较。例如,适当的先前研究可能已经通过其他手段被确定,并且图8的方法可以被应用于该先前研究的图像文件,以将先前研究内的特定系列的第二医学成像数据选择为与当前医学成像数据相关。
[0067]
在任一种情况下,参考图8描述的方法可以允许自动地选择使用与第一医学成像数据(例如,表示当前医学图像)相同或相似的成像参数捕获的第二医学成像数据的一个或多个集合(例如,表示先前医学图像的某些系列)。这可以提供适合于与当前医学图像进行比较的先前医学图像的高效选择,例如与打开和评估患者的所有先前医学图像相比。此外,基于图像文件的属性值(其在大小方面是相对小)的选择允许在不必提取或分析医学成像数据本身(其在大小方面是相对大的)的情况下进行选择,并且因此可以允许高效的选择。此外,基于根据属性值生成的向量的选择可以允许灵活的选择。例如,与尝试直接匹配成像参数相比,特征空间中的向量的比较可以在参数之间的非精确匹配方面更加鲁棒和/或灵活。
[0068]
图9图示了根据一示例的参考图8描述的方法的组件之间的流程。第一图像文件902存储第一医学成像数据以及具有指示用于捕获第一医学成像数据的成像参数的第一属性值的属性。这些第一属性值904从第一图像文件902中被提取,并且被提供给向量化器906,并且向量化器输出第一向量908。多个第二图像文件被存储在存储装置914中。在一些示例中,该多个第二图像文件中的每一个可以来自研究内的相应不同系列。一个或多个第二属性值916(每个第二属性值指示用于捕获存储在其中包括它们的相应第二文件中的第二医学成像数据的成像参数)的多个集合从相应多个第二图像文件中被提取。第二属性值916的这些集合进而被提供给向量化器906,向量化器906输出相应多个第二向量920(一个或多个第二属性值的输入集合中的每一个的向量)。第一向量908和/或第二向量920可以与第一/第二图像文件(或其标识符)相关联地存储,针对该第一/第二图像文件,第一向量908和/或第二向量920被生成。第一向量908以及多个第二向量920中的每一个被输入到比较器910,比较器910确定第一向量与第二向量中的每一个之间的相似性度量。比较器910可以基于所确定的相似性度量来输出对第二医学成像数据集合(或其标识符)中的一个或多个的选择912(例如,可以选择具有最高相似性度量的一个或多个)。然后,可以从存储装置914检
索第二医学成像数据的所选的一个或多个集合。在一些示例中,如上所提到的,可以从存储装置914检索包含所选的第二集合中的一个集合的系列的第二医学成像数据(例如,仅该系列的第二医学成像数据)。换句话说,在一些示例中,可以从存储装置914检索被包括在包括了第二医学成像数据的所选集合中的一个或多个的系列中的第二医学成像数据集合(例如,仅该第二医学成像数据集合)。
[0069]
在一些示例中,如已经提到的,第二医学成像数据的多个集合可以被存储在远程存储装置(参见例如图10的1006)中。在这些示例中,该方法可以包括:从远程存储装置检索第二医学成像数据的所选的一个或多个集合(或包括第二医学成像数据的所选集合的系列的医学成像数据集合),而不检索第二医学成像数据的多个集合中的其他集合。这可以提供对网络资源的高效利用。
[0070]
在一些示例中,该方法可以包括生成显示数据以使显示设备(参见例如1003)显示第一医学成像数据的渲染以及第二医学成像数据的所选的(或以其他方式检索的)集合中的一个或多个的渲染。这可以为医学专业人员提供在视觉上评估患者的第一(例如,当前)与第二(例如,先前)医学成像数据之间的差异。由于第二(先前)医学成像数据已经被选择为适合于与第一(当前)医学成像数据进行比较,所以用户可以更好地聚焦于由于由此表示的疾病的进展所致的差异,而不是由于诸如模态和成像参数之类的非疾病相关因素所致的差异。
[0071]
在一些示例中,该方法可以包括生成第一向量908和/或第二向量920中的一个或多个(例如全部)。
[0072]
在其中第一属性值904或第二属性值916中的一个或多个包括文本串的示例中,分别生成第一向量908或第二向量920可以包括将文本串编码成向量表示。例如,文本串可以包括单词,这些单词可以使用单词嵌入被编码成向量表示。例如,单词嵌入将字典中的单词映射到向量空间,其中字典中的单词以及针对每个单词的向量可以通过将单词嵌入模型应用于训练文本的语料库来生成。已知的单词嵌入模型的示例是“word2vec”,它使用神经网络以从训练文本的语料库中学习单词嵌入。在一些示例中,可以使用预先训练的单词嵌入,该单词嵌入例如已经在大量通用文本语料库上被预先训练。在一些示例中,训练文本可以包括医学文本,诸如放射学报告、医学文献和/或训练图像文件的属性值的文本串。这可以允许学习特定于医学领域的单词和缩写的语义含义(在训练文本的情境内)。在其中文本串包括多个单词的情况下,来自每个单词的单词嵌入的向量可以被组合以生成第一向量(或第一向量的一部分),例如通过对文本串的每个单词的单词嵌入的向量进行级联或取其平均值。可以使用其他方法。
[0073]
在其中第一属性值904或第二属性值906中的一个或多个包括数值的示例中,分别生成第一向量908或第二向量920可以包括将数值格式化成向量表示。例如,属性值中的一个或多个可以是数值。例如,如上所描述,示例dicom属性“回波时间”的示例值是“4.2”。在这种示例中,在适当时,属性值可以用作第一或第二向量的元素。在一些示例中,在适当时,属性值可以在将它包括作为第一或第二向量的元素之前被归一化。例如,回波时间属性值在作为向量的元素被包括之前可以被除以10000。作为另一个示例,属性值中的一个或多个可以包括多个数值,例如值系列。在这种示例中,数值系列可以被格式化成每元素具有一个数值的列向量。例如,如上所描述,示例dicom属性“图像取向患者”的示例属性值是“[1,0,
0,0,1,0]”。这可以被格式化成列向量,并且在适当时用作第一或第二向量(或其一部分)。
[0074]
在一些示例中,生成第一向量908或第二向量920包括:针对多个第一属性值904或第二属性值916中的每一个,分别基于第一属性值或第二属性值来生成第三向量,并且组合第三向量以分别生成第一向量908或第二向量920。例如,多个属性值可以是“系列描述”、“回波时间”和“图像取向患者”。在这种情况下,可以如上所描述的那样针对这三个属性值中的每一个生成第三向量,例如分别为v
sd
、v
et
、v
iop
。然后,这三个第三向量中的每一个可以在适当时被级联以生成第一向量908或第二向量920,例如[v
sd
,v
et
,v
iop
]。
[0075]
在一些示例中,确定相似性度量可以包括:针对每个第二向量920,确定第一向量908与第二向量920之间的余弦相似性。如所已知的,余弦相似性是两个向量之间的点积,并且表示两个向量之间的相似性。例如,余弦相似性1指示相同或高度相似的向量(并且因此其对应于相同或高度相似的成像参数),而余弦相似性0指示正交向量(并且因此其对应于截然相反或高度不相似的成像参数)。在一些示例中,具有与第一医学成像数据的第一向量908具有高余弦相似性的第二向量920的第二医学成像数据的集合优先于具有低余弦相似性的第二向量920的第二医学成像数据的集合被选择。在一些示例中,可以使用其他相似性度量,诸如第一向量908与第二向量920之间的欧几里德距离。在这些示例中,比较器910可以包括计算单元(未示出),该计算单元计算第一与第二向量之间的余弦相似性(或其他这种相似性度量)。
[0076]
在一些示例中,比较器910可以包括神经网络(未示出),该神经网络被训练成基于两个向量的输入来输出指示两个向量之间的相似性的值。在一些示例中,确定相似性度量可以包括:针对第二向量920中的每一个,将第一向量908和第二向量920输入到经训练的神经网络中;以及从经训练的神经网络获得输出,由此确定指示第一向量与第二向量之间的相似性的值。例如,神经网络可以是在初始层与最终层之间包括神经元的一个或多个隐藏层的深度神经网络。初始层可以被配置成将固定大小的第一向量和第二向量作为输入。神经网络可以包括回归器(未示出),该回归器被配置成将来自神经网络的最终层的向量表示映射到指示两个输入向量之间的相似性的值(例如,在0与1之间)。
[0077]
在一些示例中,可以基于训练数据集来训练神经网络,该训练数据集包括多对这种向量(例如,多对向量,其中该对向量中的每个向量分别具有与第一向量908和第二向量908相同的格式),每一对利用训练相似性值被加标签,该训练相似性值在神经网络的训练期间提供监督信号。在实践中,训练数据集可以包括100个或1000个这种被加标签的训练对。例如,该训练可以包括深度学习。例如,该训练可以包括更新神经网络中的神经元的层之间的连接的权重,以便最小化由回归器针对向量的训练对中的每一个预测的相似性值与由训练对的相应标签所定义的训练对中的每一个的实际相似性值之间的误差。
[0078]
在一些示例中,针对向量的训练对中的每一个,训练相似性值标签可以表示:在给定具有在训练对的一个向量中表示的特定第一属性值的第一医学成像数据的情况下,用户将选择具有在该对的另一个向量中表示的特定第二属性值的第二医学成像数据以用于与第一医学成像数据进行比较的概率。例如,该概率可以基于与医学成像数据的被记入日志的用户交互的统计分析来确定。例如,数据日志可以记录由给定医学专业人员在给定环节中针对给定患者检索的医学成像文件。可以对这些日志应用统计处理来确定该概率。例如,对于其成像参数是x的当前医学成像文件,可以确定医学专业人员继续查阅其成像参数是y
的先前医学成像文件的时间百分比(例如,60%)以及医学专业人员继续查阅其成像参数是z的先前医学成像文件的时间百分比(例如,20%)。在这种情况下,可以生成两个训练对,一个具有表示x和y的向量并且具有0.6的训练相似性值标签,并且另一个具有表示x和z的向量并且具有0.2的训练相似性值标签。这可以针对成像参数的大量组合来进行,以生成训练数据集。基于与医学成像数据的实际用户交互的统计分析的训练数据集可以帮助确保使用适当成像参数捕获的第二医学成像数据被选择。
[0079]
参考图10,图示了示例系统1000,在其中可以在一些示例中实现根据上面参考图1至9描述的示例中的任何一个或组合的方法。系统1000包括计算机1002、显示设备1003、网络1004和存储装置1006。计算机1002可以被配置成执行根据上面参考图1至9描述的示例中的任何一个或组合的方法。显示设备1003可以用于显示上面描述的医学成像数据的渲染(未示出),和/或上面参考图5描述的gui 502。计算机1002被配置成通过网络1004与存储装置1006通信。例如,网络804可以包括局域网或广域网,诸如互联网。在该示例中,存储装置1006表示档案,例如dicom档案设备,并且被配置成根据上面描述的示例中的任一个来存储成像文件。例如,存储装置1007可以实现上面参考图7描述的存储装置714和/或上面参考图9描述的存储装置914。例如,存储装置914可以存储第一图像文件402、902和/或第二图像文件。存储装置1006在如下意义上远离计算机1002:它可经由网络1004来访问,而不是可在计算机802本地访问。在这种实现环境中,例如由于有限的带宽资源,减少或限制通过网络1004传输的数据量可能是有用的。医学成像数据在大小方面可以特别大,因此在可能的情况下减少医学成像数据通过网络1004的传输是有用的。不是提取患者的所有第二(例如,先前)医学成像数据以供用户与第一(例如,当前)医学成像数据进行比较,而是根据本公开的示例,如上所提到的,计算机1002可以基于其中存储了医学成像数据的文件的属性的属性值来选择与第一(例如,当前)医学成像数据相关的第二(例如,先前)医学成像数据(例如,属于相同或相似身体区域和/或使用相同或相似模态的研究;和/或属于使用相同或相似成像参数的系列)的一个或多个集合,并且因此可以仅提取与该比较相关的第二(例如,先前)医学成像数据的那些集合。因此,可以减少通过网络1004传输的数据总量,并且更高效地部署网络资源。
[0080]
参考图11,图示了根据一示例的装置1100。该装置可以是计算机1100。装置1100可以被使用以代替上面参考图10描述的计算机1002。装置1100可以被配置成执行根据上面参考图1至10描述的示例中的任何一个或组合的方法。装置1100可以被配置成例如根据上面参考图1至10描述的示例中的任一个通过网络1004与远程存储装置1006通信。
[0081]
如所图示,装置1100包括处理器1102、存储器设备1104、输入接口1006和输出接口1108。存储器设备1104可以存储指令,所述指令在由处理器1102执行时使得装置1100执行根据上面参考图1至10描述的示例中的任何一个或组合的方法。可以在一个或多个非暂时性计算机可读介质上提供所述指令。所述指令可以以计算机程序的形式。输入接口1106可以例如被配置成从上面参考图5描述的gui 502接收用户输入。例如,输入接口1106可以连接到诸如键盘和/或鼠标(未示出)之类的输入装置,用户/放射科医师可以经由该输入装置提供输入和/或选择。处理器1102可以被配置成经由输入接口1106来接收输入和/或选择。输入接口1106可以替代地或附加地被配置成根据上面参考图1至10描述的示例中的任何一个来接收图像文件、医学成像数据、文本串、属性值、向量和/或训练数据集。输出接口1108
可以被配置成根据上面参考图1至图10描述的示例中的任何一个来输出所确定的身体区域、一个或多个第二医学成像数据的所选集合、和/或显示数据。输出接口1108可以与远程存储装置1006通信,并且向远程存储装置1006传输信号,以使得检索所选的第二医学图像数据(其文件,或者所选的医学成像数据是其一部分的研究或系列的文件或数据)。替代地或附加地,例如,输出接口1108可以连接到显示设备,诸如图10的显示设备1003,并且将显示数据输出到显示设备。例如,可以使得显示设备根据上面参考图1至10描述的示例中的任何一个或组合来经由输出显示数据显示医学成像数据的渲染和/或gui 502。处理器1102可以被配置成经由输出接口1108来输出显示数据。
[0082]
如上所提到的,在某些示例中,参考图8和9描述的方法可以独立于参考图1至7描述的方法来使用。例如,第二医学成像数据的一个或多个集合的选择可以基于所确定的相似性度量,并且不需要附加地基于上面参考图1至图7描述的身体区域和/或成像模态相关性得分的比较。以下经编号的条款中描述了这些特定示例的各方面:a1.一种用于确定相关医学成像数据集的计算机实现方法,所述方法包括:获得第一医学成像数据的第一向量,第一向量已经基于进一步包括第一医学成像数据的第一图像文件的属性的一个或多个第一属性值而被生成,每个第一属性值指示用于捕获第一医学成像数据的成像参数;获得第二医学成像数据的相应多个集合的多个第二向量,其中针对第二医学成像数据的每个集合,第二向量已经基于包括第二医学成像数据的第二图像文件的属性的一个或多个第二属性值而被生成,所述一个或多个第二属性值指示用于捕获第二医学成像数据的成像参数;针对所述多个第二向量中的每一个,确定指示第一向量与第二向量之间的相似性的相似性度量;以及基于所确定的相似性度量,将第二医学成像数据的所述集合中的一个或多个选择为与第一医学成像数据相关。
[0083]
a2.根据条款a1所述的计算机实现方法,其中第二医学成像数据的所述多个集合被存储在远程存储装置中,并且所述方法包括:从远程存储装置检索第二医学成像数据的所选的一个或多个集合、或包括第二医学成像数据的所选的一个或多个集合的系列的第二医学成像数据集合,而不检索第二医学成像数据的所述多个集合中的其他集合。
[0084]
a3.根据条款a1或条款a2所述的计算机实现方法,其中所述方法包括:生成显示数据,以使得显示设备显示第一医学成像数据的渲染以及第二医学成像数据的所选的或所检索的集合中的一个或多个的渲染。
[0085]
a4.根据条款a1至条款a3中任一项所述的计算机实现方法,其中所述方法包括:生成第一向量和/或第二向量中的一个或多个。
[0086]
a5.根据条款a4的计算机实现方法,其中在第一属性值或第二属性值中的一个或多个包括文本串的情况下,分别生成第一向量或第二向量包括将文本串编码成向量表示。
[0087]
a6.根据条款a4或条款a5所述的计算机实现方法,其中在第一属性值或第二属性值中的一个或多个包括数值的情况下,分别生成第一或第二向量包括将数值格式化成向量表示。
[0088]
a7.根据条款a4至条款a6中任一项所述的计算机实现方法,其中生成第一向量或第二向量包括:分别针对多个第一属性值或第二属性值中的每一个,分别基于第一属性值或第二属性值来生成第三向量;以及组合第三向量以分别生成第一向量或第二向量。
[0089]
a8.根据条款a1至条款a7中任一项所述的计算机实现方法,其中针对所述多个第二向量中的每一个,确定相似性度量包括确定第一向量与第二向量之间的余弦相似性。
[0090]
a9.根据条款a1至条款a8中任一项所述的计算机实现方法,其中针对所述多个第二向量中的每一个,确定相似性度量包括:将第一向量和第二向量输入到经训练的神经网络中,所述神经网络已经被训练成基于两个这种向量的输入来输出指示所述两个向量之间的相似性的值;以及从所述经训练的神经网络获得输出,由此确定指示第一向量与第二向量之间的相似性的值。
[0091]
a10.根据条款a9所述的计算机实现方法,其中所述神经网络已经基于训练数据集被训练,所述训练数据集包括多对这种向量,每一对利用训练相似性值被加标签,所述训练相似性值在所述神经网络的训练期间提供监督信号。
[0092]
a11.根据条款a10的计算机实现方法,其中针对所述向量对中的每一个,相似性值标签表示:在给定具有在所述对的一个向量中表示的特定第一属性值的第一医学成像数据的情况下,用户将选择具有在所述对的另一个向量中表示的特定第二属性值的第二医学成像数据以用于与第一医学成像数据进行比较的概率,所述概率是基于与医学成像数据集的被记入日志的用户交互的统计分析来确定的。
[0093]
a12.根据条款a1至条款a11中任一项所述的计算机实现方法,其中将第二医学成像数据的所述集合中的一个或多个选择为与第一医学成像数据相关进一步基于以下各项中的一个或多个:由第一医学成像数据表示的第一身体区域与由第二医学成像数据的多个集合表示的多个第二身体区域中的每一个的比较;以及在第一医学成像数据的第一成像模态与第二医学成像数据的第二成像模态之间确定的成像模态相关性得分。
[0094]
a13.根据条款a1至条款a12中任一项的计算机实现方法,其中所述或每个图像文件是dicom文件,并且具有指示用于捕获其医学成像数据集的成像参数的属性值的一个或多个属性包括以下各项中的一个或多个:dicom属性“图像取向患者”、“系列描述”、“回波时间”、“重复时间”、“翻转角度”、“回波串长度”、“扫描序列”、“序列名称”和“协议名称”。
[0095]
a14.一种被配置成执行根据条款a1至条款a13中任一项所述的方法的装置。
[0096]
a15.一种计算机程序,所述计算机程序在由计算机执行时使得所述计算机执行条款a1至条款a13中任一项所述的方法。
[0097]
上述实施例应理解为本发明的说明性实施例。要理解的是,关于任何一个示例所描述的任何特征可以单独使用,或者与所描述的其他特征结合使用,并且也可以与示例中的任何其他示例的一个或多个特征结合使用,或者与示例中的任何其他示例的任何组合结合使用。此外,在不脱离由所附权利要求限定的本发明的范围的情况下,也可以采用上面没有描述的等同物和修改。
1.相关申请的交叉引用本技术要求保护来自2021年8月5日提交的欧洲专利申请第21189986.9号的优先权的权益,其内容通过引用并入本文中。
技术领域
2.本框架涉及用于确定由存储在图像文件中的医学成像数据表示的身体区域的方法和装置。
背景技术:
3.诸如磁共振成像(mri)、计算机断层摄影(ct)等医学成像是医学诊断的宝贵工具。在临床决策制定中,患者疾病随时间的进展对于诊断而言即便不比该疾病的当前状态更有用,也是与该疾病的当前状态同样有用的。为了帮助评估患者疾病的进展,医学专业人员常常希望将患者的当前医学图像与患者的适当先前医学图像或医学图像系列进行比较。
4.然而,常常存在患者的大量先前医学图像。例如,对于任何给定患者,可能存在在多个先前时间点处采取的多个先前研究。此外,在每个研究内,可能存在多个医学图像系列,每个系列具有不同的特性。手动地评估先前医学图像的适当性以用于与当前医学图像进行比较或者以其他方式评估它们与当前医学图像的相关性对于医学专业人员来说可能是耗时且繁重的。此外,医学图像常常被存储在远离医学专业人员终端的存储装置中,并且检索患者的所有先在医学图像(其常常在大小方面是大的)对于医学专业人员进行评估来说是网络资源密集的。
5.自动地选择适合于与给定医学图像(例如,当前医学图像)进行比较或以其他方式与该给定医学图像相关的医学图像(例如,先前医学图像)将是有用的。替代地或附加地(例如,为了便于选择相关的医学图像或出于其他原因),自动地确定由医学图像表示的身体区域将是有用的。然而,分析表示该图像的医学成像数据以确定由此表示的身体区域将涉及医学成像数据的提取和处理,该医学成像数据典型地是大的并且将是资源密集的。
技术实现要素:
6.根据一个方面,提供了一种确定由存储在第一图像文件中的医学成像数据表示的身体区域的计算机实现方法,第一图像文件进一步存储一个或多个属性,每个属性具有包括指示该医学成像数据的内容的文本串的属性值,该方法包括:(a)获得第一图像文件的文本串中的一个或多个;以及(b)将文本串中的所获得的一个或多个输入到经训练的机器学习模型中,该机器学习模型已经被训练成基于一个或多个这种文本串的输入来输出身体区域,以及从经训练的机器学习模型获得输出,由此确定由该医学成像数据表示的身体区域。
附图说明
7.图1是图示了根据一示例的方法的流程图;
图2是图示了根据一示例的包括医学成像数据的图像文件的示意图;图3是图示了根据一示例的包括医学成像数据的医学数字成像和通信(dicom)文件的示意图;图4是图示了根据一示例的组件之间的流程的示意图;图5是图示了根据一示例的图形用户界面(gui)的示意图;图6是图示了根据一示例的方法的流程图;图7是图示了根据一示例的组件之间的流程的示意图;图8是图示了根据一示例的方法的流程图;图9是图示了根据一示例的组件之间的流程的示意图;图10是图示了根据一示例的系统的示意图;以及图11是图示了根据一示例的计算机的示意图。
具体实施方式
8.参考图1,图示了确定由存储在第一图像文件中的医学成像数据表示的身体区域的计算机实现方法。
9.图2中图示了示例第一图像文件。第一图像文件200存储医学成像数据204,并且进一步存储一个或多个属性202,每个属性202具有包括指示医学成像数据204的内容的文本串的属性值206。
10.医学成像数据204是表示医学图像(或在某些示例中多于一个医学图像)的数据。例如,医学成像数据204可以包括像素或体素值的阵列或列表。例如,当由合适的图像查看软件处理时,医学成像数据导致了其所表示的医学图像(或多个医学图像)的渲染。一个或多个属性值与医学成像数据分离并且不同于医学成像数据,并且取而代之包括指示医学成像数据204的内容的文本串。在一些示例中,这种属性值可以被称为图像文件200的元数据。在一些示例中,图像文件200中的存储属性202和属性值206的部分可以被称为图像文件200的头(header),并且属性202和属性值206可以被称为图像文件200的头数据。
11.图像文件200的具体示例是医学数字成像和通信(dicom)文件300。图3中图示了示例dicom文件,如下面更详细地描述的。概括地,dicom文件300将医学成像数据316存储为指定数据元素312中的像素数据,并且进一步将一个或多个属性310存储为一个或多个其他数据元素310,每个属性310具有包括指示医学成像数据316的内容的文本串的属性值314。示例这种dicom属性310是“研究描述”,其属性值314是文本串,该文本串描述了该医学成像数据是其一部分的研究(例如,“neruo^head”,其中该医学成像数据属于患者的头部区域),并且由此指示医学成像数据316的内容。还存在这种dicom属性的其他示例,诸如“系列描述”、“所检查的身体部位”以及其他。
12.返回到图1,概括地说,该方法包括:(a)在步骤102中,获得第一图像文件200、300的文本串206、314中的一个或多个;以及(b)在步骤104中,将文本串中的所获得的一个或多个206、314输入到经训练的机器学习模型(参见例如图4的经训练的神经网络406)中,机器学习模型406已经被训练成基于一个或多个这种文本串的输入来输出身体区域,以及从经训练的机器学习模型406获得
输出,由此确定由医学成像数据204、316表示的身体区域408。
13.通过将第一图像文件200、300的一个或多个文本串206、314输入到被训练成基于输入这种文本串来确定身体区域的机器学习模型406(例如,神经网络)中来确定由医学成像数据204、316表示的身体区域408可以提供对由医学成像数据表示的身体区域408的高效和/或灵活的确定。
14.例如,与例如通过提取和分析医学成像数据本身(其在比特方面相对大)来确定身体区域相比,基于该文件的文本串(其在比特方面相对小)来确定身体区域可以是较不资源密集的,并且因此更加高效。在其中该图像文件通过网络与处理设备远离地存储的情况下,基于(相对小的)文本串来确定身体区域允许(相对大的)医学成像数据不需要通过网络被传输以便确定由此表示的身体区域,因此使得高效利用了网络资源。
15.作为另一个示例,例如与通过将硬编码规则应用于文本串来确定身体区域相比,通过将文本串输入到经训练的机器学习模型(例如,经训练的神经网络)中来确定身体区域可以提供对身体区域的高效、灵活和/或鲁棒的确定。例如,硬编码规则需要文本串与规则的确切匹配以便提供身体区域(并且因此关于针对其可以确定匹配的文本串是不灵活的,和/或在需要针对可以使用的所有可能文本串被编码的规则集的穷举性质方面是低效的)。另一方面,经训练的机器学习模型(例如,经训练的神经网络)从它在其上被训练的训练数据集进行泛化,并且因此既获得起来相对高效,又能够确定适当的身体区域,即使针对与训练数据集中的那些文本串不同的文本串也是如此,并且因此是相对灵活/鲁棒的。
16.因此,可以提供对由医学成像数据表示的身体区域的有效和/或灵活的自动确定。
17.在一些示例中,在给定时间处并且对于给定患者,放射科医师可以对患者执行医学成像研究。不同的研究可以在不同的时间处执行。特定研究可能针对患者的特定身体部位,并且使用特定成像模式(例如,mr)。在一些情况下,不同的研究可能是患者的不同身体部位的研究和/或具有不同的成像模态(即,由不同的设备捕获)。给定研究可以包括一个或多个医学图像系列。例如,在研究内的给定系列内,可能已经使用相同的成像参数(例如,患者取向、诸如回波时间等的mr特定成像参数)捕获了医学图像。研究内的每个系列可能具有不同的成像参数。在一些示例中,图像文件200存储表示特定系列内和特定研究内的图像的医学成像数据204。存储了表示作为相同研究的一部分的医学图像的医学成像数据204的图像文件200可以例如具有相同的唯一研究id,并且存储了表示作为相同系列的一部分的医学图像的医学成像数据204的图像文件200可以例如具有相同的唯一系列id。在任何情况下,给定研究可以具有至少一个这种图像文件200的至少一个系列。
18.在一些示例中,对由第一图像文件200的第一医学成像数据表示的身体区域的确定可以进而便于将第二个这种文件的第二医学成像数据自动选择为与第一医学成像数据相关(例如,适合于与第一医学成像数据进行比较)。例如,确定由当前研究的文件的医学成像数据表示的身体区域可以用于选择患者的相同身体区域的先前研究的医学成像数据。下面将参考图4和图5对此进行更详细的描述。
19.如上所提到的,在一些示例中,第一图像文件200、300可以是dicom文件300(即,以dicom文件格式的图像文件,例如根据dicom标准“nema ps3/iso 12052,医学数字成像和通信(dicom)标准、国家电气制造商协会,美国弗吉尼亚州罗斯林”)。再次参考图3,更详细地,dicom文件300包括头302和数据集308。头302包括128字节前导码304(如果不被使用的话,
其所有字节被设置为零)和包含字符串“dicm”的4字节前缀306。数据集308包含数据元素310、312。每个数据元素310、312包括标记并且由其标识。每个标记采用格式(xxxx,xxxx),其中每个“x”是十六进制数。dicom文件300可以在“研究id”数据元素(未示出)(即,由dicom标记(0020,0010)标识)中存储该文件是其一部分的研究的唯一标识符,并且可以在“系列id”数据元素(未示出)(即,由dicom标记(0020,000e)标识)中存储该文件是其一部分的系列的唯一标识符。
20.dicom文件300将医学成像数据316(在这种情况下是像素数据316)存储在dicom文件300的“像素数据”数据元素312(即,由dicom标记(7fe0,0010)标识)中。dicom文件300进一步存储一个或多个属性310(由一个或多个其他数据元素310提供),每个属性具有包括指示医学成像数据316的内容的文本串的属性值314。例如,一个这种属性可以是“研究描述”(即,由dicom标记(0008,1030)标识),其属性值314是文本串,该文本串描述了该医学成像数据是其一部分的研究(例如,“neruo^head”,其中该医学成像数据是患者的头部区域,或“pelvis^prostate”,其中该医学成像数据是患者的骨盆区域),并且由此指示医学成像数据316的内容。在一些示例中,尽管属性310和属性值314可能不被包括在头302中,照此而是被包括在数据集308中,但是属性310和属性值314(不包括存储医学成像数据316本身的数据元素312)有时可以被称为dicom文件300的头数据,因为这些是与医学成像数据316相关的数据,而不是医学成像数据316本身。
21.可以使用具有包括指示医学成像数据的内容的文本串的属性值的其他示例dicom属性。例如,另一个这种示例dicom属性是“系列描述”(即,由dicom标记(0008,103e)标识),其描述了医学成像数据是其一部分的系列(例如,“ax t1整个骨盆”,其指示该医学成像数据属于整个骨盆,是以轴向取向并且使用t1类型mri被捕获的)。例如,另一个这种dicom属性示例是“所检查的身体部位”(即,所标识的dicom标记(0018,0015)),其指示所检查的身体部位(例如,“pelvis”,其指示该医学成像数据属于骨盆)。应当领会的是,存在并且可以使用其他这种合适的dicom属性。在一些示例中,也可以使用dicom属性“请求手术的原因”(即,由dicom标记(0040,1002)标识)。
22.此外,应当领会的是,在一些示例中,可以使用除了dicom文件之外的这种图像文件。例如,图像文件可以是便携式网络图形(png)文件,该文件在其组块(chunk)中的一个中存储医学成像数据,并且在其组块中的另一个中存储包括一个或多个属性的元数据,每个属性具有包括指示医学成像数据的内容的文本串的属性值。
23.在一些示例中,一个这种文本串可以被输入到经训练的机器学习模型(例如,经训练的神经网络)中。然而,在其他示例中,来自第一图像文件的多个属性的多个属性值的多个这种文本串可以被一起输入到经训练的机器学习模型(例如,经训练的神经网络)中,以便确定由第一文件的医学成像数据表示的身体部位。例如,这可以提供对身体区域的更准确和/或鲁棒的确定。例如,经训练的机器学习模型(例如,经训练的神经网络)确定身体区域的准确度可以通过增加该确定所基于的输入数据(来自第一文件的这种文本串的数量)来改进。作为另一个示例,如果文本串中的一个碰巧是不可靠的和/或缺失的(例如,如已经发现的,可能是针对例如“所检查的身体部位”的情况,因为它不是由放射科医师常规地或可靠地填写的),则多个文本串的输入可以减轻这种情况,并且仍然允许对要确定的身体区域的可靠确定。
24.图4图示了根据一示例的上面参考图1至3描述的方法的组件之间的流程。参考图4,如所提到的,第一图像文件402的文本串404中的一个或多个被输入到经训练的机器学习406中,并且经训练的机器学习模型406输出身体区域408。文本串404、图像文件402、经训练的机器学习模型406和/或身体区域408可以与上面参考图1至3描述的那些相同或相似,和/或可以如上面参考图1至3描述的那样被使用。
25.在一些示例中,如所图示,可以从第一图像文件402中提取一个或多个文本字符串404。具体地,可以从第一图像文件402提取一个或多个文本串404,而不提取其医学成像数据。例如,采用dicom文件300作为示例,可以解析该图像文件以定位一个或多个预定义的标记,该标记标识了具有要提取的属性值的属性(例如,针对“研究描述”属性的dicom标记(0008,1030)、以及针对“系列描述”的dicom标记(0008,103e))。一旦标记被定位,就可以从图像文件402中提取由该一个或多个标记标识的一个或多个属性的属性值(即,文本串404)。所提取的文本串404可以例如与图像文件402或其医学成像数据的标识符相关联地存储。在一些示例中,图像文件402的文本串404可能已经从图像文件402中被提取或者以其他方式在该方法被执行之前被获得,并且例如与图像文件402或其医学成像数据的标识符相关联地存储。在任一种情况下,一个或多个文本串404被获得并且被输入到经训练的机器学习模型406中。
26.在一些示例中,可以使用仅一个文本字符串。然而,在一些示例中,图像文件402的多个文本串404可以被获得并且被输入到经训练的机器学习模型406中。例如,dicom文件402的所有属性“研究描述”、“系列描述”和“所检查的身体部位”的属性值的文本串可以被获得,并且被输入到经训练的机器学习模型406中,使得经训练的机器学习模型406基于所有这些输入文本串来输出由该文件的医学成像数据表示的身体区域。例如,文本串可以被级联并且被一起输入到经训练的机器学习模型406中。在任何情况下,来自经训练的机器学习模型406的输出408被获得,由此确定由医学成像数据表示的身体区域408。
27.如所提到的,机器学习模型406已经被训练成基于一个或多个这种文本串的输入来输出身体区域。也就是说,该机器学习模型被训练成:基于图像文件的一个或多个属性的一个或多个属性值的指示医学成像数据的内容的一个或多个文本串的输入,来输出由该图像文件的医学成像数据表示的身体区域。
28.在一些示例中,经训练的机器学习模型406可以是经训练的神经网络406。实际上,在下文描述的示例中,将参考经训练的神经网络406。然而,应当领会的是,在其他示例中,可以使用被训练成基于一个或多个文本串的输入来输出身体区域的其他类型的机器学习模型。例如,在其他示例中,经训练的机器学习模型可以采取经训练的随机森林算法等的形式。例如,随机森林算法可以包括在训练数据上训练的决策树的全体,该训练数据包括利用其相关联的身体区域被加标签的训练文本串(例如,如由专家所确定的),即,配置决策树的全体,以便与训练文本串的被加标签的身体区域相比,最小化该身体区域的预测中的误差。然而,如在下文中提到的,参考经训练的神经网络406的示例。使用经训练的神经网络406可以具有某些优点,如下文更详细讨论的那样。
29.在一些示例中,神经网络406可以是深度神经网络(即,具有一个或多个隐藏层)。在一些示例中,可以使用有监督学习来训练神经网络。例如,可以使用包括多个训练文本串(实际上可以有100或1000个训练文本串)的训练数据集来训练神经网络406,每个训练文本
串来自图像文件的属性的属性值并且指示进一步被存储在图像文件中的医学成像数据的内容。例如,训练文本串可以是从dicom图像文件的适当属性(例如,“研究描述”、“系列描述”、“所检查的身体部位”等)的属性值中提取的文本串。在一些示例中,类似于如上所描述,每个训练文本串可以表示图像文件的不同适当属性的多个个体的这种文本串的级联。在任何情况下,每个训练文本串可以利用该训练文本串所对应的身体区域来加标签。例如,在一些示例中,训练文本串可以利用由该训练文本串所源自的文件的医学成像数据所表示的实际身体区域来加标签,该实际身体区域例如由专家从业者来确定。在一些示例中(如下面参考图5更详细地描述的),训练文本串可以利用被确定为如例如专家所确定的那样对应于该文本串本身或者由该文本串本身表示的身体区域来加标签。在任一种情况下,每个文本串的身体区域标签可以在神经网络的训练中用作监督信号。
30.在一些实例中,经训练的神经网络406可以被配置成以身体区域分类的形式来输出身体区域408,该身体区域分类是经训练的神经网络406的分类器部分针对输入的一个或多个文本串从多个身体区域分类当中选择的。例如,每个分类可以是表示身体区域的标准化单词,诸如“abdomen(腹部)”、“pelvis(骨盆)”、“chest(胸部)”等。在这种示例中,每个训练文本串可以利用其所属的分类来加标签,并且这可以用作用于训练神经网络的监督信号。例如,该训练可以包括深度学习。例如,该训练可以包括更新神经网络中的神经元的层之间的连接的权重,以便最小化由分类器针对训练文本串中的每一个所预测的分类与由训练文本串的相应标签所定义的训练文本串中的每一个的实际分类之间的误差。
31.在一些实例中,经训练的神经网络406可以被配置成以一个或多个数值的形式来输出身体区域408,该一个或多个数值表示经训练的神经网络406的回归器部分已经针对输入的一个或多个文本串404所计算的人类身体区域。例如,一个或多个数值可以是“身体标尺”的数值,即针对人类身体定义的标尺或刻度,其中0.0的值表示人类脚趾的尖端,并且1.0的值表示人类头部的最顶部部分(例如),其中0和1之间的值表示脚趾尖端与头部顶部之间的人类身体的相应区域。在一些示例中,可以使用两个这样的数值来表示人类身体的身体区域。例如,这两个值可以指示在其之间定义了身体区域的位置。例如,可以向膀胱指派身体标尺值[0.5,0.55]。在这种示例中,每个训练文本串可以利用表示其所对应的身体区域的一个(或多个,例如两个)数值来加标签,并且这可以用作用于训练神经网络406的监督信号。例如,该训练可以包括深度学习。例如,该训练可以包括更新神经网络中的神经元的层之间的连接的权重,以便最小化由回归器针对训练文本串中的每一个所预测的一个(或多个)数值与由训练文本串的相应标签所定义的训练文本串中的每一个的实际一个(或多个)数值之间的误差。
[0032]
将身体区域输出为一个或多个数值可以允许对由文件的医学成像数据表示的身体区域的精确和/或灵活的确定。例如,数值是连续的,并且因此例如与使用预定义类别的有限集合相比,能够更精确地并且以更多的灵活性来定义身体区域。这可以进而允许对身体区域的灵活和/或精确的比较,例如当选择与第一医学成像数据相关的第二医学成像数据时,如下面参考图6更详细地描述的。
[0033]
在一些示例中,经训练的神经网络406可以是经训练的基于字符的神经网络406,其被配置成将文本串中的所获得的一个或多个404的个体字符作为输入。在这些示例中,将文本串中的所获得的一个或多个404输入到经训练的神经网络406中可以包括将文本串中
的所获得的一个或多个的个体字符输入到经训练的神经网络406中。例如,神经网络406可以包括编码器,该编码器被配置成将输入文本串的每个字符编码成向量。例如,这可以使用字符嵌入来完成,诸如针对包括字母表、数字1到9和特殊字符的字符词汇表进行独热(1-hot)编码。这些向量可以由神经网络406用作确定身体区域的基础。可以使用不同的架构。
[0034]
例如,在一些示例中,神经网络406可以包括基于字符的递归神经网络(rnn),诸如长短期记忆(lstm)rnn,诸如双向ltsm。文本串的每个字符的向量可以被顺序地输入到rnn中,在此之后,rnn将具有某个内部状态(例如,表示其神经元在文本串的最后一个字符的向量被输入时的值的向量)。该内部状态然后可以被传递到神经网络406的回归器或分类器,该回归器或分类器然后可以将该内部状态映射到身体区域408上。
[0035]
作为另一个示例,神经网络406可以包括基于字符的卷积神经网络(cnn)。在这些示例中,文本串的相继字符的向量可以并排组装以创建矩阵。然后,可以对该矩阵应用卷积和池化操作,以确定表示文本串中存在的特征的压缩特征向量。该特征向量然后可以被传递到神经网络406的回归器或分类器,该回归器或分类器然后可以将该特征向量映射到身体区域上。可以通过其准确地映射身体区域的特征本身可以在神经网络406的训练期间被学习。
[0036]
在一些示例中,可以使用其他神经网络,例如基于单词的神经网络。然而,包括基于字符的神经网络的神经网络406可以提供如下身体区域确定:该确定对于不是训练数据的一部分的缩写或错误拼写或其他单词是鲁棒的。例如,“abdomen”可以缩写为“abd”,但是由于前几个字母是相同的,因此基于字符的神经网络可以针对在向量空间中处于相似位置的这两个单词生成向量(并且因此适当的身体区域可以被确定),而基于单词的神经网络可能会将“abd”确定为在词汇表之外。这反过来可以帮助提供准确的确定,这是由于词汇表之外的单词可能会降低准确度。
[0037]
如所提到的,每个训练文本串可以利用该训练文本串所对应的身体区域来加标签,并且在一些示例中,训练文本串可以利用被确定为如专家所确定的那样对应于该文本串或者由该文本串表示的身体区域来加标签。如参考图5所描述,在这种情况下,可以使用图形用户界面(gui)502来生成训练数据集(包括训练文本串以及其标签)。gui 502可以被配置成向用户呈现训练文本串508中的一个或多个以及被划分成可选身体区域511的人类身体510的表示。gui可以被配置成:针对一个或多个所呈现的训练文本串508中的每一个,接收选择了来自表示510的身体区域511的用户输入,并且利用指示所选身体区域511的标签509来对训练文本串508加标签。以这种方式,可以生成包括利用身体区域标签被加标签的训练文本串的训练数据集。
[0038]
例如,参考图5中的具体示例,gui 502包括进度条504,进度条504向用户指示当前正在显示的gui的特定窗格。还示出了特定窗格的标题506,在这种情况下,该标题506是“标注关键词”。在该示例中,训练文本串508是从存储了医学成像数据的图像文件的属性的属性值中提取的关键词。在所图示的示例中,关键词包括“aaa”、“ab”、“abdpel”、“abdroutine”、“aquired”、“aif”、“angiogram”和“ascities”。用户被呈现了特定关键词(在这种情况下是粗体的“aaa”),并且被要求选择其所对应的身体表示510的所显示的身体区域511之一。例如,作为专家并且知道医学成像情境中的“aaa”是“abdominal aortic aneurysm(腹主动脉瘤)”的缩写的用户选择所显示的身体表示511的腹部部分,并且因此文
本串“aaa”利用身体区域标签“abdomen”来加标签。可以针对其他所呈现的关键词进行类似选择:“ab”——“abdomen”、“abdpel”——“abdomen”、“abdroutine”——“abdomen”、“aif”——“head”、“angiogram
’”
——“chest”和“ascities”—“abdomen”。要注意的是,“acquired”文本串没有利用身体区域被加标签,因为它不与任何特定身体区域相关联,并且因此将不会形成训练数据集的一部分。gui 502还包括可选按钮512,即“子宫”、“前列腺”、“未知”和“无”。“子宫”和“前列腺”按钮是为了分别提供“prostate(前列腺)”和“uterus(子宫)”的身体部位标签。“未知”按钮用于如果用户不知道身体区域标签但是例如怀疑它能够被指派身体区域标签,并且“无”按钮用于如果用户知道没有身体区域可被分配给该文本串(例如,如上面的“acquired”的情况)。
[0039]
gui 502可以允许以简单且高效的方式来生成包括具有身体区域标签的多个(例如,100个)训练文本串的训练数据集。标签是使用人类身体的表示(例如,风格化图片)来获得的,该表示对于用户(包括医学专业人员并且不一定是编程专家)来说是可视且简单的以便与其交互。用户与gui的这种简单且高效的交互可以进而允许高效地生成训练数据集(即,要加标签的文本串)。
[0040]
在上面描述的示例中,神经网络406被训练成基于输入文本串来输出身体区域408。在一些示例中,神经网络406可以被进一步训练成基于一个或多个文本串的输入来输出输出身体区域408的偏侧性。偏侧性可以指代由医学成像数据表示的身体区域位于身体的哪一侧(即,“左”或“右”)。例如,在适当时,输出偏侧性可以是“左”或“右”。在这些示例中,图1的方法的步骤104可以进一步包括:基于经训练的神经网络406的所获得的输出来确定由医学成像数据表示的身体区域的偏侧性。作为一个示例,这可以通过提供被训练成基于一个或多个文本串的输入来输出偏侧性的神经网络406的专用偏侧性部分来实现。例如,这可以使用包括训练文本串的训练数据集来训练,每个训练文本串是利用该文本串所对应的身体区域的偏侧性来加标签的。作为另一个示例,这可以通过如下方式来进行:扩展神经网络406将输入文本串映射到其上的身体区域分类的集合,以包括每个身体区域分类的“左”和“右”版本。例如,这可以使用包括训练文本串的训练数据集来训练,每个训练文本串是利用该训练文本串所对应的身体区域和偏侧性分类来加标签的。确定身体区域的偏侧性可以允许确定更精确的身体区域,这可以进而允许对相关第二医学成像数据的更准确的选择,如下面更详细地描述的。
[0041]
如所提到的,在一些示例中,由第一医学成像数据表示的所确定的身体区域可以用于选择与第一医学成像数据相关(例如,适合于与第一医学成像数据进行比较)的第二医学成像数据。例如,可以针对给定患者的当前研究的第一医学成像数据确定身体区域,并且这可以用于选择适合于与当前研究(例如,相同或相似的身体区域)进行比较的针对给定患者的一个或多个先前研究的第二医学成像数据的一个或多个集合(例如,被包含在一个或多个图像文件中)。现在参考图6,图示了选择与第一医学成像数据相关的第二医学成像数据的方法。
[0042]
该方法包括:在步骤602中,将由存储在第一图像文件402中的第一医学成像数据表示的第一身体区域408与由存储在相应多个第二图像文件中的第二医学成像数据的相应多个集合表示的多个第二身体区域中的每一个进行比较。该方法包括:在步骤604中,基于身体区域的比较,将第二医学成像数据的集合中的一个或多个选择为与第一医学成像数据
相关。
[0043]
第二图像文件中的每一个可以属于与第一图像文件402相同的类型。即,每个第二图像文件进一步存储一个或多个属性,每个属性具有包括指示存储在第二图像文件中的第二医学成像数据的内容的文本串的属性值。第一身体区域408可能已经通过将上面参考图1描述的方法的步骤102和104应用于第一图像文件402的一个或多个文本串而被确定。替代地或附加地,第二身体区域中的至少一个(并且在一些情况下是全部)可以通过将上面参考图1描述的方法的步骤102和104应用于第二图像文件中的相应的至少一个(并且在一些情况下是全部)的一个或多个文本串来确定。
[0044]
图7图示了根据一示例的上面参考图6描述的方法的组件之间的流程。参考图7,在该示例中,类似于如上参考图4所描述,来自第一图像文件402的一个或多个文本串404被输入到经训练的神经网络406中,并且经训练的神经网络406输出第一身体区域408。第一身体区域408可以与第一图像文件402的标识符(未示出)相关联地存储。
[0045]
此外,在该示例中,从存储在存储设备714中的相应多个第二图像文件(例如,属于与第一图像文件402相同的患者)中提取多个一个或多个文本串716。例如,该多个第二图像文件中的每一个可以来自患者的不同先前研究。第二图像文件的多个一个或多个文本串716中的每一个被依次输入到经训练的神经网络720中,以获得相应多个第二身体区域720。第二身体区域中的每一个可以与相关联的第二图像文件的标识符(未示出)相关联地存储。照此,例如,可以确定在多个先前研究中的每一个的图像文件中示出的身体区域。然后,可以通过比较器710将第一身体区域408与多个第二身体区域720中的每一个进行比较,并且可以基于该比较来做出对第二医学成像数据的集合中的一个或多个的选择712。
[0046]
在一些示例中,该选择可以仅基于该比较。在其他示例中,该选择可以基于如下面更详细地描述的另外标准。在一些示例中,该选择可以是对身体区域与其相关联地存储的第二图像文件的标识符的选择。所选的标识符可以用于询问存储设备714并且从存储设备714(例如,在线或近线dicom存档设备)检索(例如,预取)相关联的第二图像文件。
[0047]
在一些示例中,可以从存储设备714检索包括第二医学成像数据的一个或多个所选集合之一的那些研究(例如,仅那些研究)的医学成像数据或图像文件。可以例如通过匹配包含所选第二医学成像数据的文件的“研究id”属性来确定这些文件。在一些示例中,如下面更详细地描述的,可以从存储设备714检索包括第二医学成像数据的所选集合中的一个或多个的那些系列(例如,仅那些系列)的医学成像数据或图像文件。可以例如通过匹配包含所选第二医学成像数据的文件的“系列id”属性来确定这些文件。
[0048]
在任何情况下,第二医学图像数据的检索到的集合中的一个或多个的渲染可以被显示在显示设备(参见例如图10的1003)上。
[0049]
在一些示例中,第一医学成像数据可以表示患者的当前医学图像(或医学图像系列),并且第二医学成像数据的多个集合可以表示患者的先前医学图像(或医学图像系列)。例如,第一图像文件可以对应于患者的当前研究,并且第二图像文件中的每一个可以对应于患者的相应的不同先前研究。医学专业人员可能希望将当前研究的一个或多个图像与患者的先前研究中的相关研究的那些图像进行比较,例如,以评估疾病在这两个研究之间的进展。实现高效比较的有用标准是当前和先前研究(即,其当前和先前医学图像)属于相同或相似的身体部位(例如,头部、腹部、足部)。通过基于针对第一医学图像数据和第二医学
成像数据确定的身体区域的比较来自动地选择第二医学成像数据,该方法允许医学专业人员将例如当前研究的医学图像仅与相关先前医学图像(例如,相同或相似身体区域的先前研究的那些医学图像)进行比较,这与用户必须与所有先前医学图像进行比较相比是高效的。
[0050]
此外,在一些示例中,第二医学成像数据的多个集合被存储在远程存储设备714(也参见例如图10的1006)中,该远程存储设备714可以通过网络(参见例如图10的1004)连接到用户的终端(参见例如图10的1002)。在这些情况下,第二医学成像数据的所选的一个或多个集合(或包括第二医学成像数据的所选集合的研究的第二医学成像数据集合)可以从远程存储设备714、1006被检索(例如,从dicom存档设备1006被预取),而不检索第二医学成像数据的多个集合中的其他集合。由于可以基于图像文件的属性的文本串来确定身体区域,因此那些文件的第二医学成像数据一旦被选择为相关,它们就仅需要从远程存储装置714、1006被检索,并且未被选择为相关或要检索的第二医学成像数据根本不需要被检索。照此,可以高效地部署网络资源。
[0051]
在一些示例中,身体区域的比较可以包括确定第一医学成像数据的身体区域分类(例如,“abdomen”、“chest”)是否与第二医学成像数据的身体区域分类相同。在一些示例中,如果存在匹配(例如,两者具有相同的身体区域分类“abdomen”),则第二医学成像数据可以被选择为与第一医学成像数据相关。
[0052]
在一些示例中,身体区域的比较可以包括比较定义了第一和第二医学成像数据的身体区域的数值。例如,这可以包括确定第一医学成像数据的身体区域数值是否与第二医学成像数据的身体区域数值相同或相似或重叠。例如,如果第一医学成像数据的数值是0.5,则具有数值0.45的第二医学成像数据集合可以被选择为相似的(例如,相差小于预定义的量)。作为另一个示例,如果第一医学成像数据的数值是[0.5,0.55],则可以选择具有数值[0.5,0.55]的第二医学成像数据集合,因为它是相同的,并且可以选择具有数值[0.4,0.55]的第二医学成像数据集合,因为它是重叠的。
[0053]
如所提到的,将第二医学成像数据的一个或多个集合(例如,给定患者的先前研究)选择为与第一医学成像数据(例如,给定患者的当前研究)相关可以基于比较其身体区域。然而,在一些示例中,该选择可以基于另外的因素或标准,如下面更详细地描述的。
[0054]
除了示出了相同身体部位的当前和先前研究之外,实现对其图像的高效比较的另一个有用标准是当前和先前研究属于相同或相似的模态(即,用于捕获其图像的医学成像的模式或类型,例如ct、mri、x射线)。
[0055]
因此,在一些示例中,该方法可以包括:针对第二医学成像数据(例如,属于先前研究)的多个集合中的每一个,确定第一医学成像数据(例如,属于当前研究)的第一成像模态与第二医学成像数据(例如,属于先前研究)的第二成像模态之间的成像模态相关性得分。在这些示例中,将第二医学成像数据的一个或多个集合选择为与第一医学成像数据相关可以进一步基于所确定的成像模态相关性得分。例如,具有较高成像模态相关性得分的第二医学成像数据集合中的一个(例如,属于给定患者的先前研究中的一个)可以优先于具有较低成像模态相关性得分的第二医学成像数据集合中的另一个(例如,属于给定患者的先前研究中的另一个)被选择用于第一医学成像数据(例如,属于患者的当前研究)。在一些示例中,可以选择具有与第一医学成像数据相同的身体区域并且具有最高成像模态相关性得分
的第二医学成像数据的集合。在一些示例中,可以预先选择具有与第一医学图像数据相同或相似的身体区域的第二医学成像数据的集合,例如根据上面参考图6描述的方法,并且然后可以基于成像模态相关性得分来从预先选择的集合当中选择第二医学成像数据的一个或多个集合。
[0056]
在一些示例中,用于捕获文件的医学成像数据的成像模态可以从其中存储了医学成像数据的图像文件的成像模态属性的属性值来确定。例如,成像模态可以直接从dicom文件的“模态”属性(例如,由dicom标记(0008,0060)标识)的属性值来获得。dicom“模态”属性值标识了获取了医学成像数据的设备的类型。在dicom标准中,可以表示不同成像模式的值是预先定义的。例如:所定义的是,“ct”表示“计算机断层摄影”,并且“mr”表示“磁共振”等。此外,在一些示例中,可以通过与设备一起使用以生成图像文件的软件来将成像模态属性值自动设置为适当的值。因此,可以直接从文件的“模态”属性可靠地获得成像模态。
[0057]
两个模态之间的成像模态相关性得分可以是表示使用一个模态捕获的医学成像数据与使用另一个模态捕获的医学成像数据相关(即,适合于与另一个模态进行比较或者对于与另一个模态进行比较是有用的)的程度的值。在一些示例中,可以使用成像模态转移矩阵来确定成像模态相关性得分。例如,矩阵的每个元素可以对应于一个特定成像模态与另一个特定成像模态之间的一个成像模态相关性得分。也就是说,矩阵的元素s
ij
可以是具有成像模态i的第一(例如,当前)医学成像数据与具有成像模态j的第二(例如,先前)医学成像数据之间的成像模态相关性得分。例如,i = mr和j = mr之间的成像模态相关性得分(即,s
mrmr
)可以是0.6,而i = mr和j = ct之间的成像模态相关性得分(即,s
mrct
)可以是0.22。在这种情况下,例如,如果使用mr捕获了第一医学成像数据,则如果第二医学成像数据集合中的两个都具有与第一医学成像数据相同的身体区域,但是一个集合是使用mr被捕获的,而另一个集合是使用ct被捕获的,则可以优先选择使用mr被捕获的集合。
[0058]
在一些示例中,成像模态相关性得分(即,转移矩阵的每个元素s
ij
)可以表示:在给定与特定第一成像模态i相关联的第一医学成像数据的情况下,用户(例如,医学专业人员)将选择具有特定第二成像模态j的第二医学成像数据以用于与第一医学成像数据进行比较的概率。例如,该概率可以基于与医学成像数据的被记入日志的用户交互的统计分析来确定。例如,数据日志可以记录由给定医学专业人员在给定环节中已经针对给定患者检索的医学成像文件。可以对这些日志应用统计处理来确定该概率。例如,当查阅其模态是mr的当前医学成像文件时,如果确定医学专业人员继续查阅其成像模态是mr的患者的先前医学成像文件60%的时间,但是继续查阅其成像模态是ct的患者的先前医学成像文件22%的时间,则s
mrmr
可以被确定为0.6,并且s
mrct
可以被确定为0.22。这可以针对成像模态的所有组合进行,以填充转移矩阵。基于与医学成像数据的实际用户交互的统计分析的成像模态相关性得分(即,转移矩阵的每个元素s
ij
)可以帮助确保适当模态的第二医学成像数据被选择。
[0059]
在上面描述的示例中,可以例如基于身体区域和/或成像模态来选择与给定患者的当前研究的医学成像数据相关(例如,适合于与给定患者的当前研究的医学成像数据进行比较)的给定患者的先前研究的医学成像数据。如所提到的,在给定的研究内,可能存在医学图像的多个系列。例如,在给定研究内(具体地在给定模态内,例如mr)的不同系列可以包括已经使用不同成像参数(例如,对于mr:回波时间、翻转角度、回波串长度、患者取向等)捕获的医学成像数据。使得医学专业人员能够有效比较当前和先前医学图像的另一个有用
标准可以是当捕获当前和先前医学图像时使用的医学成像参数是相同或相似的。因此,在一些示例中,第二医学成像数据的选择可以替代地或附加地基于成像参数的比较。例如,可以基于用于捕获先前和当前系列的图像的医学成像参数的比较将给定患者的先前研究内的先前系列的第二医学成像数据选择为与当前系列的第一医学成像数据相关(例如,适合于与当前系列的第一医学成像数据进行比较)。
[0060]
参考图8,图示了基于成像参数来选择相关医学成像数据的方法。
[0061]
在这些示例中,第一和第二图像文件中的每一个存储一个或多个属性,每个属性具有指示用于捕获图像文件的医学成像数据的成像参数的属性值。
[0062]
例如,类似于如上所描述,每个图像文件可以是dicom文件,并且具有指示用于捕获其医学成像数据的成像参数的属性值的一个或多个第一属性包括以下各项中的一个或多个:dicom属性“图像取向患者”(由dicom标记(0020,0037)标识),并且其值指定了医学成像数据的第一行和第一列相对于患者的取向余弦,示例值是“[1,0,0,0,1,0]”;“系列描述”(由dicom标记(0020,0037)标识),并且其值包括该系列的描述,示例值是“ax t1整个骨盆”,指示轴向取向);“回波时间”(由dicom标记(0018,0081)标识),并且其值指定了mr成像中激发脉冲的中间与所产生的回波的峰值之间的时间(以毫秒为单位),示例值是“4.2”;“重复时间”(由dicom标记(0018,0080)标识,并且其值指定了mr成像中脉冲序列的开始和后续脉冲序列的开始之间的时间(以毫秒为单位),示例值为“8”;“翻转角度”(由dicom标记(0018,1314)标识),并且其值指定了mr成像中磁向量从原型场的磁向量被翻转的稳态角度(以度为单位),示例值是“90”;回波串长度'(由dicom属性标记(0018,0091)标识),并且其值指定了每个图像每次激发所获取的k空间(表示mr图像中的空间频率的数字阵列)中的行数,示例值是“1”;“扫描序列”(由dicom标记(0018,0020)标识),并且其值指示所捕获的mr数据的类型,示例值是“se”,指示自旋回波类型mr);“序列名称”(由dicom标记(0018,0024)标识),并且其值指定了mr成像中扫描序列和序列变体的组合的用户定义的名称,示例值是“spcir_242”);以及“协议名称”(由dicom标记(0018,1030)标识),并且其值指定了ct协议的名称,示例值是“t2w_tse sense”)。应当领会的是,在一些示例中,可以使用其他这种属性,并且实际上可以使用其他类型的图像文件。
[0063]
在图8中所图示的示例中,该方法包括:在步骤802中,获得第一医学成像数据的第一向量(参见例如图9的908),该第一向量是基于指示用于捕获第一图像文件(参见例如图9的902)的第一医学成像数据的成像参数的属性值(参见例如图9的904)中的一个或多个而生成的。该方法包括:在步骤804中,获得针对第二医学成像数据的相应多个集合的多个第二向量(参见例如图9的920),其中,对于第二医学成像数据的每个集合,第二向量920是基于指示用于捕获第二图像文件的第二医学成像数据集合的成像参数的属性值(参见例如图9的916)中的一个或多个而生成的。
[0064]
该方法包括:在步骤806中,针对多个第二向量920中的每一个,确定指示第一向量908与第二向量920之间的相似性的相似性度量;以及在步骤808中,基于所确定的相似性度量将第二医学成像数据的集合中的一个或多个(参见例如图9的912)选择为与第一医学成像数据相关。例如,在一些示例中,可以选择第二医学成像数据的多个集合当中具有最高相似性度量的第二医学成像数据集合。在一些示例中,可以选择第二医学成像数据的多个集合当中具有最高的两个或更多个相似性度量的第二医学成像数据的两个或更多个集合。
[0065]
在一些示例中,第二医学成像数据的一个或多个集合的选择(例如,如上面参考图1至图7所描述)可以进一步基于所确定的相似性度量,即,除了上面参考图1至图7所描述的身体区域和/或成像模态相关性得分的比较之外。例如,在一些示例中,先前研究的第二医学成像数据(例如,包含第二医学成像数据的多个系列)可以基于如上面参考图1至图7所描述的身体区域和/或成像模态的比较而在患者的先前研究当中被预先选择为与当前医学成像数据相关;以及该预先选择的研究内的多个系列当中的特定系列的第二医学成像数据可以基于如参考图8描述的所确定的相似性度量被选择为与当前医学成像数据相关。在这种情况下,第二医学成像数据的一个或多个集合(例如,表示给定系列的一个或多个医学图像)可以基于身体区域、成像模态相关性得分和所确定的相似性度量的比较而被选择为与第一医学成像数据相关。
[0066]
然而,在某些其他示例中,参考图8描述的方法可以独立于上面参考图1至图7描述的方法来应用。例如,第二医学成像数据的一个或多个集合的选择可以基于所确定的相似性度量,并且不需要附加地基于上面参考图1至图7描述的身体区域和/或成像模态相关性得分的比较。例如,适当的先前研究可能已经通过其他手段被确定,并且图8的方法可以被应用于该先前研究的图像文件,以将先前研究内的特定系列的第二医学成像数据选择为与当前医学成像数据相关。
[0067]
在任一种情况下,参考图8描述的方法可以允许自动地选择使用与第一医学成像数据(例如,表示当前医学图像)相同或相似的成像参数捕获的第二医学成像数据的一个或多个集合(例如,表示先前医学图像的某些系列)。这可以提供适合于与当前医学图像进行比较的先前医学图像的高效选择,例如与打开和评估患者的所有先前医学图像相比。此外,基于图像文件的属性值(其在大小方面是相对小)的选择允许在不必提取或分析医学成像数据本身(其在大小方面是相对大的)的情况下进行选择,并且因此可以允许高效的选择。此外,基于根据属性值生成的向量的选择可以允许灵活的选择。例如,与尝试直接匹配成像参数相比,特征空间中的向量的比较可以在参数之间的非精确匹配方面更加鲁棒和/或灵活。
[0068]
图9图示了根据一示例的参考图8描述的方法的组件之间的流程。第一图像文件902存储第一医学成像数据以及具有指示用于捕获第一医学成像数据的成像参数的第一属性值的属性。这些第一属性值904从第一图像文件902中被提取,并且被提供给向量化器906,并且向量化器输出第一向量908。多个第二图像文件被存储在存储装置914中。在一些示例中,该多个第二图像文件中的每一个可以来自研究内的相应不同系列。一个或多个第二属性值916(每个第二属性值指示用于捕获存储在其中包括它们的相应第二文件中的第二医学成像数据的成像参数)的多个集合从相应多个第二图像文件中被提取。第二属性值916的这些集合进而被提供给向量化器906,向量化器906输出相应多个第二向量920(一个或多个第二属性值的输入集合中的每一个的向量)。第一向量908和/或第二向量920可以与第一/第二图像文件(或其标识符)相关联地存储,针对该第一/第二图像文件,第一向量908和/或第二向量920被生成。第一向量908以及多个第二向量920中的每一个被输入到比较器910,比较器910确定第一向量与第二向量中的每一个之间的相似性度量。比较器910可以基于所确定的相似性度量来输出对第二医学成像数据集合(或其标识符)中的一个或多个的选择912(例如,可以选择具有最高相似性度量的一个或多个)。然后,可以从存储装置914检
索第二医学成像数据的所选的一个或多个集合。在一些示例中,如上所提到的,可以从存储装置914检索包含所选的第二集合中的一个集合的系列的第二医学成像数据(例如,仅该系列的第二医学成像数据)。换句话说,在一些示例中,可以从存储装置914检索被包括在包括了第二医学成像数据的所选集合中的一个或多个的系列中的第二医学成像数据集合(例如,仅该第二医学成像数据集合)。
[0069]
在一些示例中,如已经提到的,第二医学成像数据的多个集合可以被存储在远程存储装置(参见例如图10的1006)中。在这些示例中,该方法可以包括:从远程存储装置检索第二医学成像数据的所选的一个或多个集合(或包括第二医学成像数据的所选集合的系列的医学成像数据集合),而不检索第二医学成像数据的多个集合中的其他集合。这可以提供对网络资源的高效利用。
[0070]
在一些示例中,该方法可以包括生成显示数据以使显示设备(参见例如1003)显示第一医学成像数据的渲染以及第二医学成像数据的所选的(或以其他方式检索的)集合中的一个或多个的渲染。这可以为医学专业人员提供在视觉上评估患者的第一(例如,当前)与第二(例如,先前)医学成像数据之间的差异。由于第二(先前)医学成像数据已经被选择为适合于与第一(当前)医学成像数据进行比较,所以用户可以更好地聚焦于由于由此表示的疾病的进展所致的差异,而不是由于诸如模态和成像参数之类的非疾病相关因素所致的差异。
[0071]
在一些示例中,该方法可以包括生成第一向量908和/或第二向量920中的一个或多个(例如全部)。
[0072]
在其中第一属性值904或第二属性值916中的一个或多个包括文本串的示例中,分别生成第一向量908或第二向量920可以包括将文本串编码成向量表示。例如,文本串可以包括单词,这些单词可以使用单词嵌入被编码成向量表示。例如,单词嵌入将字典中的单词映射到向量空间,其中字典中的单词以及针对每个单词的向量可以通过将单词嵌入模型应用于训练文本的语料库来生成。已知的单词嵌入模型的示例是“word2vec”,它使用神经网络以从训练文本的语料库中学习单词嵌入。在一些示例中,可以使用预先训练的单词嵌入,该单词嵌入例如已经在大量通用文本语料库上被预先训练。在一些示例中,训练文本可以包括医学文本,诸如放射学报告、医学文献和/或训练图像文件的属性值的文本串。这可以允许学习特定于医学领域的单词和缩写的语义含义(在训练文本的情境内)。在其中文本串包括多个单词的情况下,来自每个单词的单词嵌入的向量可以被组合以生成第一向量(或第一向量的一部分),例如通过对文本串的每个单词的单词嵌入的向量进行级联或取其平均值。可以使用其他方法。
[0073]
在其中第一属性值904或第二属性值906中的一个或多个包括数值的示例中,分别生成第一向量908或第二向量920可以包括将数值格式化成向量表示。例如,属性值中的一个或多个可以是数值。例如,如上所描述,示例dicom属性“回波时间”的示例值是“4.2”。在这种示例中,在适当时,属性值可以用作第一或第二向量的元素。在一些示例中,在适当时,属性值可以在将它包括作为第一或第二向量的元素之前被归一化。例如,回波时间属性值在作为向量的元素被包括之前可以被除以10000。作为另一个示例,属性值中的一个或多个可以包括多个数值,例如值系列。在这种示例中,数值系列可以被格式化成每元素具有一个数值的列向量。例如,如上所描述,示例dicom属性“图像取向患者”的示例属性值是“[1,0,
0,0,1,0]”。这可以被格式化成列向量,并且在适当时用作第一或第二向量(或其一部分)。
[0074]
在一些示例中,生成第一向量908或第二向量920包括:针对多个第一属性值904或第二属性值916中的每一个,分别基于第一属性值或第二属性值来生成第三向量,并且组合第三向量以分别生成第一向量908或第二向量920。例如,多个属性值可以是“系列描述”、“回波时间”和“图像取向患者”。在这种情况下,可以如上所描述的那样针对这三个属性值中的每一个生成第三向量,例如分别为v
sd
、v
et
、v
iop
。然后,这三个第三向量中的每一个可以在适当时被级联以生成第一向量908或第二向量920,例如[v
sd
,v
et
,v
iop
]。
[0075]
在一些示例中,确定相似性度量可以包括:针对每个第二向量920,确定第一向量908与第二向量920之间的余弦相似性。如所已知的,余弦相似性是两个向量之间的点积,并且表示两个向量之间的相似性。例如,余弦相似性1指示相同或高度相似的向量(并且因此其对应于相同或高度相似的成像参数),而余弦相似性0指示正交向量(并且因此其对应于截然相反或高度不相似的成像参数)。在一些示例中,具有与第一医学成像数据的第一向量908具有高余弦相似性的第二向量920的第二医学成像数据的集合优先于具有低余弦相似性的第二向量920的第二医学成像数据的集合被选择。在一些示例中,可以使用其他相似性度量,诸如第一向量908与第二向量920之间的欧几里德距离。在这些示例中,比较器910可以包括计算单元(未示出),该计算单元计算第一与第二向量之间的余弦相似性(或其他这种相似性度量)。
[0076]
在一些示例中,比较器910可以包括神经网络(未示出),该神经网络被训练成基于两个向量的输入来输出指示两个向量之间的相似性的值。在一些示例中,确定相似性度量可以包括:针对第二向量920中的每一个,将第一向量908和第二向量920输入到经训练的神经网络中;以及从经训练的神经网络获得输出,由此确定指示第一向量与第二向量之间的相似性的值。例如,神经网络可以是在初始层与最终层之间包括神经元的一个或多个隐藏层的深度神经网络。初始层可以被配置成将固定大小的第一向量和第二向量作为输入。神经网络可以包括回归器(未示出),该回归器被配置成将来自神经网络的最终层的向量表示映射到指示两个输入向量之间的相似性的值(例如,在0与1之间)。
[0077]
在一些示例中,可以基于训练数据集来训练神经网络,该训练数据集包括多对这种向量(例如,多对向量,其中该对向量中的每个向量分别具有与第一向量908和第二向量908相同的格式),每一对利用训练相似性值被加标签,该训练相似性值在神经网络的训练期间提供监督信号。在实践中,训练数据集可以包括100个或1000个这种被加标签的训练对。例如,该训练可以包括深度学习。例如,该训练可以包括更新神经网络中的神经元的层之间的连接的权重,以便最小化由回归器针对向量的训练对中的每一个预测的相似性值与由训练对的相应标签所定义的训练对中的每一个的实际相似性值之间的误差。
[0078]
在一些示例中,针对向量的训练对中的每一个,训练相似性值标签可以表示:在给定具有在训练对的一个向量中表示的特定第一属性值的第一医学成像数据的情况下,用户将选择具有在该对的另一个向量中表示的特定第二属性值的第二医学成像数据以用于与第一医学成像数据进行比较的概率。例如,该概率可以基于与医学成像数据的被记入日志的用户交互的统计分析来确定。例如,数据日志可以记录由给定医学专业人员在给定环节中针对给定患者检索的医学成像文件。可以对这些日志应用统计处理来确定该概率。例如,对于其成像参数是x的当前医学成像文件,可以确定医学专业人员继续查阅其成像参数是y
的先前医学成像文件的时间百分比(例如,60%)以及医学专业人员继续查阅其成像参数是z的先前医学成像文件的时间百分比(例如,20%)。在这种情况下,可以生成两个训练对,一个具有表示x和y的向量并且具有0.6的训练相似性值标签,并且另一个具有表示x和z的向量并且具有0.2的训练相似性值标签。这可以针对成像参数的大量组合来进行,以生成训练数据集。基于与医学成像数据的实际用户交互的统计分析的训练数据集可以帮助确保使用适当成像参数捕获的第二医学成像数据被选择。
[0079]
参考图10,图示了示例系统1000,在其中可以在一些示例中实现根据上面参考图1至9描述的示例中的任何一个或组合的方法。系统1000包括计算机1002、显示设备1003、网络1004和存储装置1006。计算机1002可以被配置成执行根据上面参考图1至9描述的示例中的任何一个或组合的方法。显示设备1003可以用于显示上面描述的医学成像数据的渲染(未示出),和/或上面参考图5描述的gui 502。计算机1002被配置成通过网络1004与存储装置1006通信。例如,网络804可以包括局域网或广域网,诸如互联网。在该示例中,存储装置1006表示档案,例如dicom档案设备,并且被配置成根据上面描述的示例中的任一个来存储成像文件。例如,存储装置1007可以实现上面参考图7描述的存储装置714和/或上面参考图9描述的存储装置914。例如,存储装置914可以存储第一图像文件402、902和/或第二图像文件。存储装置1006在如下意义上远离计算机1002:它可经由网络1004来访问,而不是可在计算机802本地访问。在这种实现环境中,例如由于有限的带宽资源,减少或限制通过网络1004传输的数据量可能是有用的。医学成像数据在大小方面可以特别大,因此在可能的情况下减少医学成像数据通过网络1004的传输是有用的。不是提取患者的所有第二(例如,先前)医学成像数据以供用户与第一(例如,当前)医学成像数据进行比较,而是根据本公开的示例,如上所提到的,计算机1002可以基于其中存储了医学成像数据的文件的属性的属性值来选择与第一(例如,当前)医学成像数据相关的第二(例如,先前)医学成像数据(例如,属于相同或相似身体区域和/或使用相同或相似模态的研究;和/或属于使用相同或相似成像参数的系列)的一个或多个集合,并且因此可以仅提取与该比较相关的第二(例如,先前)医学成像数据的那些集合。因此,可以减少通过网络1004传输的数据总量,并且更高效地部署网络资源。
[0080]
参考图11,图示了根据一示例的装置1100。该装置可以是计算机1100。装置1100可以被使用以代替上面参考图10描述的计算机1002。装置1100可以被配置成执行根据上面参考图1至10描述的示例中的任何一个或组合的方法。装置1100可以被配置成例如根据上面参考图1至10描述的示例中的任一个通过网络1004与远程存储装置1006通信。
[0081]
如所图示,装置1100包括处理器1102、存储器设备1104、输入接口1006和输出接口1108。存储器设备1104可以存储指令,所述指令在由处理器1102执行时使得装置1100执行根据上面参考图1至10描述的示例中的任何一个或组合的方法。可以在一个或多个非暂时性计算机可读介质上提供所述指令。所述指令可以以计算机程序的形式。输入接口1106可以例如被配置成从上面参考图5描述的gui 502接收用户输入。例如,输入接口1106可以连接到诸如键盘和/或鼠标(未示出)之类的输入装置,用户/放射科医师可以经由该输入装置提供输入和/或选择。处理器1102可以被配置成经由输入接口1106来接收输入和/或选择。输入接口1106可以替代地或附加地被配置成根据上面参考图1至10描述的示例中的任何一个来接收图像文件、医学成像数据、文本串、属性值、向量和/或训练数据集。输出接口1108
可以被配置成根据上面参考图1至图10描述的示例中的任何一个来输出所确定的身体区域、一个或多个第二医学成像数据的所选集合、和/或显示数据。输出接口1108可以与远程存储装置1006通信,并且向远程存储装置1006传输信号,以使得检索所选的第二医学图像数据(其文件,或者所选的医学成像数据是其一部分的研究或系列的文件或数据)。替代地或附加地,例如,输出接口1108可以连接到显示设备,诸如图10的显示设备1003,并且将显示数据输出到显示设备。例如,可以使得显示设备根据上面参考图1至10描述的示例中的任何一个或组合来经由输出显示数据显示医学成像数据的渲染和/或gui 502。处理器1102可以被配置成经由输出接口1108来输出显示数据。
[0082]
如上所提到的,在某些示例中,参考图8和9描述的方法可以独立于参考图1至7描述的方法来使用。例如,第二医学成像数据的一个或多个集合的选择可以基于所确定的相似性度量,并且不需要附加地基于上面参考图1至图7描述的身体区域和/或成像模态相关性得分的比较。以下经编号的条款中描述了这些特定示例的各方面:a1.一种用于确定相关医学成像数据集的计算机实现方法,所述方法包括:获得第一医学成像数据的第一向量,第一向量已经基于进一步包括第一医学成像数据的第一图像文件的属性的一个或多个第一属性值而被生成,每个第一属性值指示用于捕获第一医学成像数据的成像参数;获得第二医学成像数据的相应多个集合的多个第二向量,其中针对第二医学成像数据的每个集合,第二向量已经基于包括第二医学成像数据的第二图像文件的属性的一个或多个第二属性值而被生成,所述一个或多个第二属性值指示用于捕获第二医学成像数据的成像参数;针对所述多个第二向量中的每一个,确定指示第一向量与第二向量之间的相似性的相似性度量;以及基于所确定的相似性度量,将第二医学成像数据的所述集合中的一个或多个选择为与第一医学成像数据相关。
[0083]
a2.根据条款a1所述的计算机实现方法,其中第二医学成像数据的所述多个集合被存储在远程存储装置中,并且所述方法包括:从远程存储装置检索第二医学成像数据的所选的一个或多个集合、或包括第二医学成像数据的所选的一个或多个集合的系列的第二医学成像数据集合,而不检索第二医学成像数据的所述多个集合中的其他集合。
[0084]
a3.根据条款a1或条款a2所述的计算机实现方法,其中所述方法包括:生成显示数据,以使得显示设备显示第一医学成像数据的渲染以及第二医学成像数据的所选的或所检索的集合中的一个或多个的渲染。
[0085]
a4.根据条款a1至条款a3中任一项所述的计算机实现方法,其中所述方法包括:生成第一向量和/或第二向量中的一个或多个。
[0086]
a5.根据条款a4的计算机实现方法,其中在第一属性值或第二属性值中的一个或多个包括文本串的情况下,分别生成第一向量或第二向量包括将文本串编码成向量表示。
[0087]
a6.根据条款a4或条款a5所述的计算机实现方法,其中在第一属性值或第二属性值中的一个或多个包括数值的情况下,分别生成第一或第二向量包括将数值格式化成向量表示。
[0088]
a7.根据条款a4至条款a6中任一项所述的计算机实现方法,其中生成第一向量或第二向量包括:分别针对多个第一属性值或第二属性值中的每一个,分别基于第一属性值或第二属性值来生成第三向量;以及组合第三向量以分别生成第一向量或第二向量。
[0089]
a8.根据条款a1至条款a7中任一项所述的计算机实现方法,其中针对所述多个第二向量中的每一个,确定相似性度量包括确定第一向量与第二向量之间的余弦相似性。
[0090]
a9.根据条款a1至条款a8中任一项所述的计算机实现方法,其中针对所述多个第二向量中的每一个,确定相似性度量包括:将第一向量和第二向量输入到经训练的神经网络中,所述神经网络已经被训练成基于两个这种向量的输入来输出指示所述两个向量之间的相似性的值;以及从所述经训练的神经网络获得输出,由此确定指示第一向量与第二向量之间的相似性的值。
[0091]
a10.根据条款a9所述的计算机实现方法,其中所述神经网络已经基于训练数据集被训练,所述训练数据集包括多对这种向量,每一对利用训练相似性值被加标签,所述训练相似性值在所述神经网络的训练期间提供监督信号。
[0092]
a11.根据条款a10的计算机实现方法,其中针对所述向量对中的每一个,相似性值标签表示:在给定具有在所述对的一个向量中表示的特定第一属性值的第一医学成像数据的情况下,用户将选择具有在所述对的另一个向量中表示的特定第二属性值的第二医学成像数据以用于与第一医学成像数据进行比较的概率,所述概率是基于与医学成像数据集的被记入日志的用户交互的统计分析来确定的。
[0093]
a12.根据条款a1至条款a11中任一项所述的计算机实现方法,其中将第二医学成像数据的所述集合中的一个或多个选择为与第一医学成像数据相关进一步基于以下各项中的一个或多个:由第一医学成像数据表示的第一身体区域与由第二医学成像数据的多个集合表示的多个第二身体区域中的每一个的比较;以及在第一医学成像数据的第一成像模态与第二医学成像数据的第二成像模态之间确定的成像模态相关性得分。
[0094]
a13.根据条款a1至条款a12中任一项的计算机实现方法,其中所述或每个图像文件是dicom文件,并且具有指示用于捕获其医学成像数据集的成像参数的属性值的一个或多个属性包括以下各项中的一个或多个:dicom属性“图像取向患者”、“系列描述”、“回波时间”、“重复时间”、“翻转角度”、“回波串长度”、“扫描序列”、“序列名称”和“协议名称”。
[0095]
a14.一种被配置成执行根据条款a1至条款a13中任一项所述的方法的装置。
[0096]
a15.一种计算机程序,所述计算机程序在由计算机执行时使得所述计算机执行条款a1至条款a13中任一项所述的方法。
[0097]
上述实施例应理解为本发明的说明性实施例。要理解的是,关于任何一个示例所描述的任何特征可以单独使用,或者与所描述的其他特征结合使用,并且也可以与示例中的任何其他示例的一个或多个特征结合使用,或者与示例中的任何其他示例的任何组合结合使用。此外,在不脱离由所附权利要求限定的本发明的范围的情况下,也可以采用上面没有描述的等同物和修改。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。