1.本发明涉及人工智能领域,尤其涉及一种基于对抗式特征增广的长尾数据个性化联邦学习方法、系统、装置和存储介质。
背景技术:
2.近年来,深度学习技术在人工智能领域中发挥了重要作用,它的成功很大程度上依赖于大量的训练数据。利用深度模型进行建模时,通常的做法是在服务器端收集大量的数据进行训练模型。但是在现实生活中,企业之间都存在数据孤岛的问题,企业之间的数据并不互通。与此同时,随着数据安全隐私意识的提高,在服务器端进行中心化建模的方式越来越困难。联邦学习的提出是为了在保证数据隐私安全及合规合法的基础上进行跨组织联合建模,提升人工智能模型的效果,目前已广泛用于人工智能研究方向。
3.联邦学习的提出是为了在保证数据隐私安全及合规合法的基础上进行跨组织联合建模,提升人工智能模型的效果,目前已广泛用于人工智能研究方向。横向联邦学习中的一个挑战是不同组织(我们称为客户端)之间的数据分布是不同的,即数据异构问题。在服务器端聚合的全局模型并不能保证在不同的客户端数据上具有很好的泛化性。因此,个性化联邦学习算法针对于不同的客户端的数据分布,全局模型在客户端侧数据进行训练的时候即能保证泛化性,又能快速适应本地数据分布。同时,在实际场景中,参与联邦训练的潜在全局数据分布(假设不同组织的数据集合在一起的情况)呈现长尾数据分布的情况。这会导致本地数据不平衡程度各不相同。全局模型在客户端侧进行训练时,只关注样本数量多的多数类信息,而不能捕捉样本数量少的少数类信息。因此,在联邦学习中需要解决数据异构和长尾分布问题。
4.现有解决数据异构问题的个性化联邦学习算法中,最简单的方法是由wang等人提出直接利用全局模型在客户端侧数据进行微调。但是由于客户端侧训练数据量不足,通常会存在模型过拟合的问题。为了得到鲁棒的本地个性化模型,一些个性化联邦学习算法采取了元学习训练范式,flanagan等人提出的per-fedavg利用元学习训练得到一个具有快速适应的全局模型,此全局模型可以在不同的数据分布上具有很好的泛化能力。还有一些方法通过正则来约束全局模型和本地模型的差异,设计特有的个性化优化目标得到鲁棒的本地模型。li,t.等人提出的fedprox引入了修正项(proximal term),在更新本地模型时控制与初始全局模型的距离。t.dinh,c.等人提出的pfedme对每个客户端使用l2范数的正则化损失函数,该方法允许客户端沿不同的方向更新本地模型,同时不会偏离全局模型参考点。还有一种利用聚类思想得到本地个性化的方法,huang等人提出的fedamp均是在服务器端给不同本地模型进行赋权求和得到多个不同的全局模型,每个客户端选择距离自己与自己数据分布最接近的全局模型进行本地个性化训练。
5.然而,上述方法只考虑了联邦学习中平衡数据分布下的异构数据的问题,在真实的应用场景中,全局数据分布往往呈现长尾分布的情况。在这种情况下,上述个性化联邦学
习算法由于没有考虑本地数据不平衡的情况,模型仅仅能够捕捉到样本数量较多的类别的信息,而不能有效学习样本数量较少的类别信息。整个个性化模型的性能会有很大的下降。现有很多方法被提出解决数据不平衡的问题,主要可以分为类平衡、信息增广和两阶段训练的三类方法。类平衡方法的目标是通过平衡训练数据集或在训练期间应用不同的权重来提高样本量较少的类的泛化能力。最直接的重采样方法是shen,l等人提出class-aware sampling方法,其中每个类中的样本在每个小批量中以相等的概率被选择。cui,y等人提出的类平衡损失函数(cb loss)也是基于通过简单公式计算每个类的有效数量的类加权损失。针对于信息增广的方式,chu,p.等人提出的ofa利用类激活图将特征分为类特有特征和类共有特征,通过融合大类丰富的类共有特征和小类的类共有特征扩充小类信息训练模型。zang,y.等人提出的fasa是利用高斯分布融合特征生成小类特征训练模型。而对于两阶段训练的方式,kang,b等人提出将深度神经网络学习的过程解耦为表示学习和分类,并验证了在不平衡数据集上学到的特征提取器仍然具有好的性能,仅通过微调分类器即可获得强大的少数累识别能力。
6.然而,上述结合数据异构问题和数据长尾分布问题的方法中,均没有同时考虑这两个问题。为了解决联邦学习中的数据长尾分布问题,duan,m等人提出的astraea和wang,l等人提出的ratio loss同时考虑了数据异构问题和数据长尾分布问题,但是它们的优化目标是为了得到一个性能好的全局模型,而不是鲁棒的客户端的本地个性化模型。
技术实现要素:
7.有鉴于此,本发明的目的在于提出一种基于对抗式特征增广的长尾数据个性化联邦学习方法,能够解决上述的问题。
8.本发明的一方面提供一种基于对抗式特征增广的长尾数据个性化联邦学习方法,包括:
9.在服务器端将整个全局模型分成全局特征提取器g和全局分类器f并将其发给若干个客户端;
10.通过随机采样平衡若干个客户端本地样本数据分布,利用伯努利分布构建若干对源大类样本ys和目标小类样本y
t
标签对;
11.获取源大类样本特征hs和目标小类样本特征并得到采样平衡样本特征集d
bal
和生成平衡样本特征集
12.利用所述采样平衡样本特征集d
bal
和生成平衡样本特征集训练所述全局分类器f,结合全局特征提取器g,得到本地个性化模型。
13.其中,将所述全局特征提取器g参数化为u,将所述全局分类器f参数化为v;样本x的特征由所述全局特征提取器g生成,即h=g(x;u);样本x的预测结果由所述全局分类器f给出,即f(h;v)。
14.其中,所述源大类样本ys为采样前样本数量ns较多的类,所述目标小类样本y
t
为采样前样本数量n
t
较少的类,第k个所述客户端拥有的训练样本总量为nk,所述伯努利分布的计算公式如下:
[0015][0016]
其中,所述获取源大类样本特征hs和目标小类样本特征的步骤具体如下:
[0017]
利用所述全局特征提取器g获取所述源大类样本ys的所述源大类样本特征hs;
[0018]
利用对抗样本得到所述目标小类样本特征
[0019]
其中,所述对利用对抗样本得到所述目标小类样本特征的具体步骤包括:
[0020]
通过梯度下降算法不断优化所述源大类样本特征hs,在反向传播时得到梯度梯度的计算公式如下:
[0021][0022]
将梯度正则化得到最终的特征扰动δ,特征扰动δ的计算公式如下:
[0023][0024]
将特征扰动δ添加到所述源大类样本特征hs上,得到所述目标小类样本特征所述目标小类样本特征的计算公式如下:
[0025][0026]
对所述目标小类样本特征进行优化,具体优化公式如下:
[0027][0028]
其中,所述采样平衡样本特征集d
bal
为随机采样的源大类样本特征hd的集合,所述生成平衡样本特征集为对抗生成的目标小类样本特征的集合。
[0029]
其中,所述得到本地个性化模型的具体步骤包括:
[0030]
设计客户端k的本地分类器vk在所述生成平衡样本特征集上的损失函数损失函数的计算公式如下:
[0031][0032]
设计客户端k的本地分类器vk在所述采样平衡样本特征集d
bal
上的损失函数损失函数的计算公式如下:
[0033]
[0034]
利用超参数λ调整损失函数和得到最终损失函数最终损失函数的计算公式如下:
[0035][0036]
本发明的另一方面提供一种基于对抗式特征增广的长尾数据个性化联邦学习系统,包括:
[0037]
分割模块,用于在服务器端将整个全局模型分成全局特征提取器g和全局分类器f并将其发给若干个客户端;
[0038]
构建模块,用于通过随机采样平衡若干个客户端本地样本数据分布,利用伯努利分布构建若干对源大类样本ys和目标小类样本y
t
标签对;
[0039]
获取模块,用于获取源大类样本特征hs和目标小类样本特征并得到采样平衡样本特征集d
bal
和生成平衡样本特征集
[0040]
训练模块,用于利用所述采样平衡样本特征集d
bal
和生成平衡样本特征集训练所述全局分类器f,结合全局特征提取器g,得到本地个性化模型。
[0041]
本发明的又一方面提供一种基于对抗式特征增广的长尾数据个性化联邦学习装置,包括存储器和处理器:
[0042]
所述存储器,用于存储计算机程序;
[0043]
所述处理器,用于当执行所述计算机程序时,执行如上述的方法。
[0044]
本发明的再一方面提供一种基于对抗式特征增广的长尾数据个性化联邦学习存储介质,包括:所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,执行如上述的方法。
[0045]
本发明的有益效果:
[0046]
1、本发明将全局模型分成全局特征提取器和全局分类器,这样的全局特征提取器受到数据分布的影响较小,避免横向联邦学习中全局长尾数据分布下的数据异构影响。
[0047]
2、本发明利用伯努利分布将源大类样本信息迁移到目标小类样本上,利用源大类样本信息补充目标小类样本信息,丰富目标小类样本信息,避免横向联邦学习中全局长尾数据分布下的数据异构影响。
[0048]
3、本发明中客户端利用全局特征提取器得到源大类特征,避免了本地特征提取器带来的本地数据分布的噪音导致的提取特征过拟合,在得到源大类特征之后,利用对抗样本的思想生成目标小类特征平衡本地特征集,利用对抗样本生成样本补充信息,解决了横向联邦学习中全局长尾数据分布带来的数据异构的问题。
[0049]
4、本发明分别对于采样平衡样本特征集和生成平衡样本特征集设计各自的损失函数,引入超参数控制本地模型的训练方向,能够提升了个性化联邦学习下的每个客户端本地模型性能。
附图说明
[0050]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本
发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0051]
图1是本发明实施例中的整体流程图;
[0052]
图2是本发明实施例中的系统模块图;
[0053]
图3是本发明实施例中的装置示意图;
具体实施方式
[0054]
为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。因此,以下对在附图中提供的本发明的实施方式的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施方式。
[0055]
在本发明的描述中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
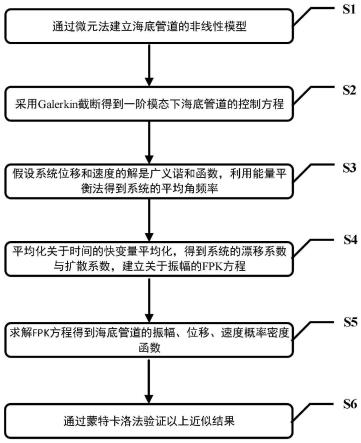
[0056]
如图1所示,本发明实施例提供一种基于对抗式特征增广的长尾数据个性化联邦学习方法,包括:
[0057]
s1准备数据集,搭建联邦学习框架,初始化学习网络;
[0058]
s101准备若干长尾分类数据集,并切分训练数据集给若干个客户端;
[0059]
在本实施例中,所使用的三个长尾分类数据集均是图像分类数据集,分别为fashion-mnist数据集、cifar-10数据集和cifar-100数据集。具体的,fashion-mnist是一个时尚服饰略缩图数据集,包括60000张训练图像和10000张测试图像,每张图像为28*28像素灰度图;cifar-10是用于识别物体的小型数据集,一共包含10个类别的rgb彩色数据图片,图片的尺寸为32*32像素,包括50000张训练图片和10000张测试图片;cifar-100是用于识别物体的大型数据集,一共包含100个类别的rgb彩色数据图片,图片的尺寸为32*32像素,包括50000张训练图片和10000张测试图片。所有长尾分类数据集的不平衡因子均为100,即全局样本量最多的类别除以全局样本量最少的类别的数值。采用带有超参数α的狄利克雷分布来控制客户端数据异构程度,α越接近0数据异构程度更严重,在本实施例中,模拟了α=0.5和α=0.2两种数据异构程度。将若干长尾分类数据集中数据平均切分给若干个客户端,每个客户端分到的数据量相同。
[0060]
s102搭建联邦学习框架并初始化深度学习网络;
[0061]
在本实施例中,在fashion-mnist数据集使用三层cnn模型进行训练,在cifar-10数据集和cifar-100数据集采用resnet32架构作为骨干模型。对于cnn模型,选择第二个卷积层之后的特征做特征增广;对于resnet32,选择经过第二块(block)之后的特征做特征增广。所有实验均利用pytorch框架实现,在两个nvidia geforce rtx 3080 gpu上运行完成。总共模拟设计20个客户端数据分布,每次随机选择其中的10个客户端模型进行联邦聚合,每批大小设置为128,学习率设置为0.005,优化器选用sgd,全局训练轮数设为500,本地更
新轮数设为1。
[0062]
s2在服务器端将整个全局模型分成全局特征提取器g和全局分类器f并将其发给若干个客户端;
[0063]
在本实施例中,基于现有联邦学习和长尾学习方法的研究,在数据异构和数据长尾分布的情况下,全局模型的特征提取器受到数据分布的影响较小。因此,将全局模型分成两个部分,第一部分是全局特征提取器g,将其参数化为u。第二部分是全局分类器f,将其参数化为v。此时,样本x的特征由全局特征提取器g生成,即由h=g(x;u)生成;样本x的预测结果由全局分类器f给出,即由f(h;v)给出。将全局特征提取器和全局分类器分发给各个被选定的客户端,其中全局特征提取器的参数保持固定不变,其中,每个客户端都分到一个全局特征提取器g和一个全局分类器f。
[0064]
s3通过随机采样平衡若干个客户端本地样本数据分布,利用伯努利分布构建若干对源大类样本ys和目标小类样本y
t
标签对;
[0065]
在本实施例中,针对于若干个客户端本地不平衡的样本数据分布,通过随机采样平衡本地样本数据集。对于任意两个不同的类别,定义采样前样本数量ns较多的类为源大类样本ys,采样前样本数量n
t
较少的类为目标小类样本y
t
。因为源大类样本ys的信息更加丰富,所以需要将源大类样本ys信息迁移到目标小类样本y
t
上,在本发明中通过伯努利分布实现信息迁移。针对于目标小类样本y
t
,在选定其对应的源大类样本ys的时候遵循伯努利分布:
[0066][0067]
其中,nk为客户端k拥有的训练样本总量。
[0068]
s4获取源大类样本特征hs和目标小类样本特征并得到采样平衡样本特征集d
bal
和生成平衡样本特征集
[0069]
其中,所述获取源大类样本特征hs和目标小类样本特征的步骤具体如下:
[0070]
s401利用所述全局特征提取器g获取所述源大类样本ys的所述源大类样本特征hs;
[0071]
在本实施例中,选择利用全局特征提取器g而不利用本地特征提取器在本地做特征增广的原因有两个:其一是因为全局特征提取器g是由各个本地特征提取器聚合而来,全局特征提取器g包含更多的数据信息来做信息迁移;其二是因为本地特征提取器带有本地数据分布的噪音,利用本地特征提取器生成的特征更加容易过拟合。因此,定义选取的样本标签对(ys,y
t
),通过全局特征提取器g得到源大类样本特征:hs=g(xs;u),其中(xs,ys)是随机选定的源大类中的样本特征。
[0072]
s402利用对抗样本得到所述目标小类样本特征
[0073]
其中,所述对利用对抗样本得到所述目标小类样本特征的具体步骤包括:
[0074]
s4021通过梯度下降算法不断优化所述源大类样本特征hs,在反向传播时得到梯度
[0075]
在本实施例中,利用对抗学习中生成对抗样本的思想,不断给源大类样本特征hs添加特定的扰动,使得模型认为添加了特定扰动的源大类样本特征hs是目标小类样本特征。因此,将源大类样本特征hs的标签标记为目标小类样本y
t
,通过梯度下降算法不断优化源大类样本特征hs。在反向传播时,得到的梯度如下
[0076][0077]
s4022将梯度正则化得到最终的特征扰动δ;
[0078]
在本实施例中,可以视为将源大类样本特征hs转化为目标小类样本特征的重要度。进一步将梯度进行正则化,得到最终的特征扰动δ:
[0079][0080]
s4023将特征扰动δ添加到所述源大类样本特征hs上,得到所述目标小类样本特征所述目标小类样本特征的计算公式如下:
[0081][0082]
s4024对所述目标小类样本特征进行优化。
[0083]
在本实施例中,为了保证生成目标小类样本特征可以以很高的成功率让模型预测为目标小类样本特征,仅保留预测结果超过某个阈值的生成目标小类样本特征,在本发明中,选择预测结果超过0.5的生成目标小类样本特征,对于预测结果没有超过0.5的生成目标小类样本特征,直接选择放弃。生成目标小类样本特征的优化目标如下:
[0084][0085]
在本实施例中,在完成整个对抗样本生成的操作之后,可以得到两个特征集:一个是经过随机采样得到的源大类样本特征hs的采样平衡样本特征集d
bal
,另一个是经过对抗样本生成的目标小类样本特征的生成平衡样本特征集
[0086]
s5利用所述采样平衡样本特征集d
bal
和生成平衡样本特征集训练所述全局分类器f,结合全局特征提取器g,得到本地个性化模型。
[0087]
其中,所述得到本地个性化模型的具体步骤包括:
[0088]
s501设计客户端k的本地分类器vk在所述生成平衡样本特征集上的损失函数
[0089]
在本实施例中,利用生成平衡样本特征集设计客户端k的本地分类器vk在生成平衡特征集上的损失函数
[0090]
[0091]
通过此损失函数不断优化本地分类器vk,对于本地数量较少的样本类别,将本地大类丰富的样本特征信息迁移到本地小类样本上,解决了本地分类器vk过拟合的问题,提高了本地模型对于本地小类样本的性能。
[0092]
s502设计客户端k的本地分类器vk在所述采样平衡样本特征集d
bal
上的损失函数
[0093]
在本实施例中,考虑到添加了扰动的源大类样本特征对抗生成目标小类样本特征后,没有添加扰动前的源大类样本特征hs可能会被错分为目标小类样本特征,因此在原采样平衡样本数据集d
bal
上设定了另一个损失函数
[0094][0095]
s503利用超参数λ调整损失函数和得到最终损失函数
[0096]
在本实施中,结合上述损失函数和得到最终的损失函数为:
[0097][0098]
其中,λ是作为平衡因子的超参数,用于调整训练原始样本特征集和生成样本特征集的力度。通过对抗式增广小类特征平衡每个客户端的数据分布,提出新的损失函数优化本地模型,充分将本地大类丰富的样本特征信息迁移到本地小类样本上,最终对于本地所有类的分类准确度都有了提高。有效解决了联邦异构不平衡数据分布的问题,进一步提升了横向联邦学习下的每个客户端本地模型性能。
[0099]
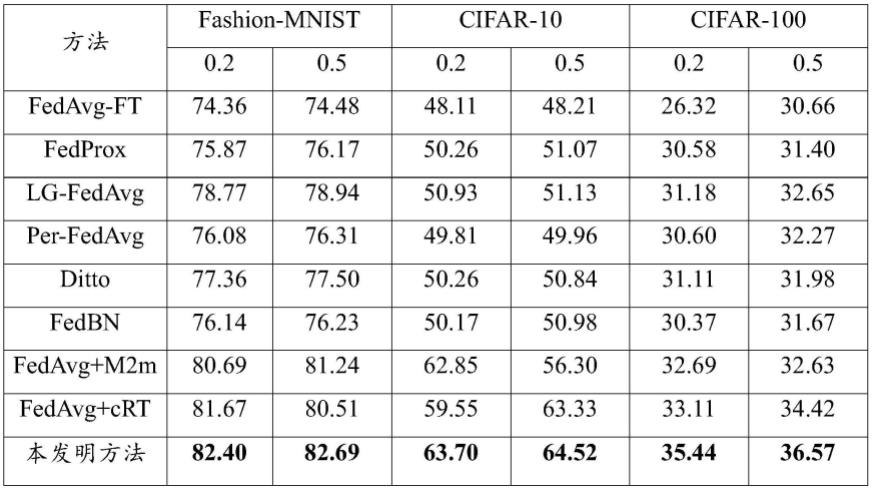
表1为本发明与其他几种联邦学习方法在fashion-mnist,cifar-10和cifar-100数据集上不平衡程度为100,数据异构程度为0.5、0.2的精度(%)比对结果。表中加粗结果为各指标的最优结果。
[0100]
表1
[0101]
[0102]
在表1中:
[0103]
fedavg-ft对应wang,k等人提出的方法(federated evaluation of on-device personalization.arxiv(2019));
[0104]
fedprox对应li,t.等人提出的方法(federated optimization in heterogeneous networks.arxiv.);
[0105]
lg-fedavg对应hanzely,f.等人提出的方法(federated learning of a mixture of global and local models.arxiv(2020));
[0106]
per-fedavg对应fallah,a.等人提出的方法(personalized federated learning with theoretical guarantees:a model-agnostic meta-learning approach.in:advances in neural information processing systems.pp.3557{3568(2020)});
[0107]
pfedme对应t.dinh等人提出的方法(personalized federated learning with moreauenvelopes.in:advances in neural information processing systems.pp.21394-21405(2020));
[0108]
ditto对应li,t.等人提出的(fair and robust federated learning through personalization.in:international conference on machine learning.pp.6357-6368(2021));
[0109]
fedbn对应li,x.等人提出的(federated learning on non-iid features via local batch normalization.in international conference on learning representations,1
–
27);
[0110]
fedavg m2m对应kim,j.等人提出的(m2m:imbalanced classification via major-to-minor translation.in ieee/cvf conference on computer vision and pattern recognition,13896
–
13905);
[0111]
fedavg crt对应kang,b.等人提出的(decoupling representation and classifier for long-tailed recognition.in international conference on learning representations,1
–
16);
[0112]
如图2所示,本发明还提供一种基于对抗式特征增广的长尾数据个性化联邦学习系统,包括:
[0113]
分割模块601,用于在服务器端将整个全局模型分成全局特征提取器g和全局分类器f并将其发给若干个客户端;
[0114]
构建模块602,用于通过随机采样平衡若干个客户端本地样本数据分布,利用伯努利分布构建若干对源大类样本ys和目标小类样本y
t
标签对;
[0115]
获取模块603,用于获取源大类样本特征hs和目标小类样本特征并得到采样平衡样本特征集d
bal
和生成平衡样本特征集
[0116]
训练模块604,用于利用所述采样平衡样本特征集d
bal
和生成平衡样本特征集训练所述全局分类器f,结合全局特征提取器g,得到本地个性化模型。
[0117]
如图3所示,本发明还提供一种基于对抗式特征增广的长尾数据个性化联邦学习装置,包括:存储器701和处理器702;
[0118]
所述存储器701,用于存储计算机程序;
[0119]
所述处理器702,用于当执行所述计算机程序时,实现如上述的方法。
[0120]
本发明还提供一种基于对抗式特征增广的长尾数据个性化联邦学习存储介质,包括:
[0121]
所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,实现如上述的方法。
[0122]
本领域内的技术人员应明白,本发明的实施例可提供为方法、平台、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0123]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0124]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0125]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0126]
以上所述仅为本发明的部分实施例,并非因此限制本发明的保护范围,凡是根据本发明说明书及附图内容所作的等效装置或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。