基于滑动窗口transformer的两阶段法ct图像分割方法
技术领域
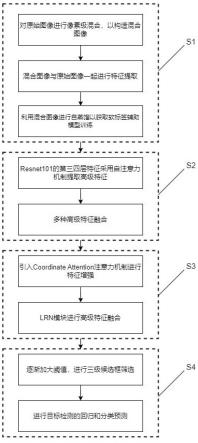
1.本发明涉及,具体涉及一种基于滑动窗口transformer的两阶段法ct图像分割方法。
背景技术:
2.transformer是当前流行的深度学习模型,最早应用在nlp(自然语言处理)领域(如:机器翻译,文本生成等),并且已经成为自然语言处理事务的标准。经过不断发展,transformer模型也被应用在计算机视觉领域(如:an image is worth 16x16 words:transformers for image recognition at scale等),并取得不错的成绩。在医学图像领域中,越来越的先进技术把医学图像中的组织病灶或感兴趣的区域分割出来,供专业的医生查看来分析病情或提出治疗方案。但是ct图像为3d图像,像素点过多,全部放入神经网络中训练会使训练过程过于缓慢。虽然swin中使用到了滑动窗口,但也只关注了局部的特征,没有考虑到图像的全局特征。
技术实现要素:
3.本发明为了克服以上技术的不足,提供了一种提高模型分割效率的基于滑动窗口transformer的两阶段法ct图像分割方法。
4.本发明克服其技术问题所采用的技术方案是:
5.一种基于滑动窗口transformer的两阶段法ct图像分割方法,包括如下步骤:
6.a)使用python中的glob模块读取所有训练集和测试集的ct图像的存储路径,将存储路径存入列表中,使用simpleitk模块按照列表中每个图像的存储路径读取ct图像的信息,将图区的ct图像进行预处理操作;
7.b)建立图像分割网络,将经过中心剪裁的测试集的ct图像输入到图像分割网络中,得到输出output;
8.c)计算得到损失函数ciou_loss;
9.d)利用损失函数训练图像分割网络;
10.e)将预处理操作后的训练集的ct图像输入到训练后的图像分割网络中,输出得到最终的分割结果。
11.进一步的,步骤a)中的预处理操作包括如下步骤:
12.a-1)根据人体腹部ct值的范围为-160-240hu将ct图像的像素值范围选择到-160-240;
13.a-2)将像素值范围为-160-240的ct图像进行归一化处理;
14.a-3)将归一化后的ct图像使用线性差值的方法进行图像重采样,各向异性分别率重采样为1*1;
15.a-4)将重采样后的ct图像按照图像中心剪裁,图像及图像的mask均剪裁为h*w,h为图像的高,w为图像的宽,将剪裁后的图像数据存储到npz文件中;
mergering层后,图像缩小为h/16*w/16*4c,将缩小后的图像输入到步骤a-6)中的block中得到图像output_left3;
29.b-5)将图像output_left3输入到缩小路径单元的第四缩小模块中,经过patch mergering层后,图像缩小为h/32*w/32*8c,将缩小后的图像输入到步骤a-6)中的block中得到图像output_left4;
30.b-6)将图像output_left4输入到扩大路径单元的第四扩大模块中,经过patch expanding层后,图像扩大为h/16*w/16*4c,将扩大后的图像与图像output_left3叠加操作后输入到步骤a-6)中的block中得到图像output_right3;
31.b-7)将图像output_right3输入到扩大路径单元的第三扩大模块中,经过patch expanding层后,图像扩大为h/8*w/8*2c,将扩大后的图像与图像output_left2叠加操作后得到图像output_right2;
32.b-8)将图像output_right2输入到扩大路径单元的第二扩大模块中,经过patch expanding层后,图像扩大为h/4*w/4*c,将扩大后的图像与图像output_left1叠加操作后输入到步骤a-6)中的block中得到图像output_right1;
33.b-9)将图像output_right1输入到扩大路径单元的第一扩大模块中,经过patch expanding层后,图像扩大为h-*w-*1,其中h-为图像的高,w-为图像的宽,该图像为输出output。
34.进一步的,步骤c)包括如下步骤:
35.c-1)通过公式ciou_loss=1-ciou计算得到model1的损失函数ciou_loss,式中为矩形区域x和输出output的并集,union为矩形区域x和输出output的交集,distance_2为矩形区域x的图像的中心点和输出output的图像的中心点之间的欧式距离,distance_c为矩形区域x与输出output交叉的图像区域,
[0036][0037]
c-2)使用sigmoid函数将输出output中的值处理到[0.1]的范围内,将处理后的输出output命名为output sig,设置阈值为0.5,将output sig中大于等于阈值的点作为分割目标,将分割目标取值为1,将output sig中小于阈值的点作为背景,将背景取值为0,将由0和1构成的图像命名为output mask,output mask中0和1交界的地方为分割目标的边界;
[0038]
c-3)通过公式l
total
=αl
dice
βl
ac
计算得到model2的损失函数l
total
,式中α为β均为权重值,α β=1,式中si为剪裁后的图像的mask中第i个像素点,i={1,2,...,n-},n-为剪裁后的图像的mask中像素点总数,gj为output mask中第j个
像素点,j={1,2,...,n},n为output mask中像素点总数,l
ac
=∫
ω
δ
ε
(x)(《n(x),v(x)》 g
∞
)dx,式中ω为output的积分区域,δ
ε
(x)为光滑的狄拉克函数,ε为参数,ε>0,s为output mask中值为1的点的区域,为output mask分割目标的边界,为output mask分割目标的边界外边的点x到的欧式距离,为output mask分割目标的边界内部的点x到的欧式距离,为φ(x)的梯度值,为矩形区域x的梯度值,gi为图像边缘指示器,b为常数,b>0,为欧几里得梯度算子,*为卷积算子,g
σ
为高斯核函数,i为矩形区域x。
[0039]
进一步的,步骤d)包括如下步骤:
[0040]
d-1)使用dataset类加载保存到npz的文件中图像数据image及bounding box对应的数据bbox;
[0041]
d-2)利用model1的损失函数ciou_loss通过adam优化器训练图像分割网络中的model1的参数,adam优化器的学习率的改变方式采用余弦退火学习率cosineannealinglr、最大学习率设置为0.3、最小设置为0.001、动量因子momentum设置为0.9、权重衰减weight_decay设置为0.05,训练时使用迭代器dataloader将dataset封装为一个迭代器,dataloader的参数为:batch_size设置为32,shuffle设置为true,num_workers设置为8;
[0042]
d-3)将npz的文件中图像数据image及mask切片封装到dataset,利用model2的损失函数l
total
通过sgd优化器训练图像分割网络中的model2的参数,sgd优化器的动量因子momentum设置为0.9、权重衰减weight_decay设置为0.0001,训练时使用迭代器dataloader迭代数据,dataloader的参数设置为batch_size设置为32,shuffle设置为true,num_workers设置为8。
[0043]
本发明的有益效果是:来本发明通过一种新型的两阶段式的图像分割方法,来提高模型分割的效率,并且这种方法还能去除离分割目标过远的异常分割区域,此外,本发明中,使用了基于轮廓模型的的损失函数l
ac
,这种方法结合了图像的全局特征,即l
ac
结合了图像的各向异性和非对称的特征,并且减少图像分割的有异常值和分割曲线容易发生泄漏问题。
具体实施方式
[0044]
下面对本发明做进一步说明。
[0045]
一种基于滑动窗口transformer的两阶段法ct图像分割方法,包括如下步骤:a)使用python中的glob模块读取所有训练集和测试集的ct图像的存储路径,将存储路径存入列表中,使用simpleitk模块按照列表中每个图像的存储路径读取ct图像的信息,将图区的ct图像进行预处理操作。
[0046]
b)建立图像分割网络,将经过中心剪裁的测试集的ct图像输入到图像分割网络中,得到输出output。
[0047]
c)计算得到损失函数ciou_loss。
[0048]
d)利用损失函数训练图像分割网络。
[0049]
e)将预处理操作后的训练集的ct图像输入到训练后的图像分割网络中,输出得到最终的分割结果。
[0050]
实施例1:
[0051]
步骤a)中的预处理操作包括如下步骤:
[0052]
a-1)因为人体组织对x射线的吸收程度不同,所以不同部位形成的ct值不同。本发明主要是分割腹部器官,腹部器官ct值常用的范围为-160~240hu。因此将ct图像的像素值范围选择到-160-240。
[0053]
a-2)将像素值范围为-160-240的ct图像进行归一化处理。
[0054]
a-3)将归一化后的ct图像使用线性差值的方法进行图像重采样,以降低图像分辨率的大小,来提高网络的训练速度,各向异性分别率重采样为1*1。
[0055]
a-4)将重采样后的ct图像按照图像中心剪裁,图像及图像的mask均剪裁为h*w,h为图像的高,w为图像的宽,将剪裁后的图像数据存储到npz文件中。
[0056]
a-5)分别将剪裁后的每个ct图像的mask的上、下、左、右的最靠边的像素的横坐标位置及纵坐标位置记录下来,将最上方像素的纵坐标和最左方像素的横坐标构成bounding box的左上角的点,将最下方像素的纵坐标和最右方像素的横坐标构成bounding box的右下角的点,由左上角的点和右下角的点的对角线确定包含分割目标的矩形区域x,该矩形区域x为h*w*1,1为维度大小,将矩形区域数据x保存到扩展名为npz的文件中,得到model1训练集的数据。
[0057]
a-6)生成目标检测的数据和标签以后,需要训练目标检测的网络结构。检测需要预测图像的类别和位置,在医学图像分割中,知道需要识别的器官是哪个,所以我们只需要寻找目标的位置。在标准的transformer结构中,计算时计算了当前像素跟其他所有像素之间的关系,所以时间复杂度是二次方,这种方法不适用于像素较高的图像中,时间开销太大。所以通过滑动窗口的方式,来降低时间复杂度。本发明中使用yolov5作为backbone,并在上边做一些改进,将基于滑动窗口的transformer模块修改yolov5中的一些模块,具体修改的位置为:将yolov5网络中的卷积块和csp bottleneck blosks替换为block(即滑动窗口的transformer模块),所述block由block1和block2串联构成,所述block1依次由第一正则化层、多头注意力机制层、残差连接层、第二正则化层及两层的多层感知机构成,矩形区域x输入到第一正则化层后输出得到特征图x
i 1
,将特征图x
i 1
输入到多头注意力机制层中输出得到特征图x
i 2
,将特征图x
i 2
及矩形区域x输入到残差连接层后再输入到第二正则化
层,输出得到特征图x
i 3
,将特征图x
i 3
输入到多层感知机中,输出得到特征图y,所述block2依次由第一正则化层、基于滑动窗口的多头注意力机制层、残差连接层、第二正则化层及两层的多层感知机构成,将特征图y输入到block2的第一正则化层后输出得到特征图y
i 1
,将特征图y
i 1
输入到基于滑动窗口的多头注意力机制层中输出得到特征图y
i 2
,将特征图y
i 2
及特征图y输入到残差连接层后再输入到第二正则化层,输出得到特征图y
i 3
,将特征图y
i 3
输入到多层感知机中,输出得到特征图z。基于滑动窗口的多头注意力机制块来自swin transformer:hierarchical vision transformer using shifted windows.论文中的第4页,英文名为shifted window based self-attention,此论文2021年发表international conference on computer vision上。
[0058]
a-7)将yolov5网络中的neck部分选择panet,将特征图z输入到yolov5网络中的backbone中,输出得到最终的预测bounding box的集合。
[0059]
a-8)利用nms算法对预测bounding box的集合进行过滤,得到过滤后的一个bounding box,nms算法的阈值为0.65。
[0060]
a-9)将步骤a-4)中剪裁后的剪裁后的ct图像的切片及ct图像对应的mask切片保存在同一个扩展名为npz的文件中,得到model2训练集的数据。
[0061]
实施例2:
[0062]
优选的,步骤a-2)中采用z-score方法对ct图像进行归一化。
[0063]
实施例3:
[0064]
优选的,步骤a-4)中h取值为160,w取值为160。
[0065]
实施例4:
[0066]
优选的,步骤a-5)中扩展名为npz的文件中图像数据命名为image,bounding box对应的数据命名为bbox,步骤a-9)中扩展名为npz的文件中图像切片命名为image,mask切片命名为lable。
[0067]
实施例5:
[0068]
步骤b)包括如下步骤:
[0069]
b-1)图像分割网络由缩小路径单元及扩大路径单元构成,所述缩小路径单元依次包括第一缩小模块、第二缩小模块、第三缩小模块、第四缩小模块构成,所述扩大路径单元依次包括第四扩大模块、第三扩大模块、第二扩大模块、第一扩大模块构成。
[0070]
b-2)将测试集的ct图像的矩形区域x的图像h*w*1输入到缩小路径单元的第一缩小模块中,经过patch层和liear enbedding层后,图像缩小为h/4*w/4*c,c为维度,将该图像命名为output_left1。
[0071]
b-3)将图像output_left1输入到缩小路径单元的第二缩小模块中,经过patch mergering层后,图像缩小为h/8*w/8*2c,将缩小后的图像输入到步骤a-6)中的block中得到图像output_left2。liear enbedding,patch mergering来自swin transformer:hierarchical vision transformer using shifted windows.论文中的第3页和第4页,此论文2021年发表international conference on computer vision上。
[0072]
b-4)将图像output_left2输入到缩小路径单元的第三缩小模块中,经过patch mergering层后,图像缩小为h/16*w/16*4c,将缩小后的图像输入到步骤a-6)中的block中得到图像output_left3。
[0073]
b-5)将图像output_left3输入到缩小路径单元的第四缩小模块中,经过patch mergering层后,图像缩小为h/32*w/32*8c,将缩小后的图像输入到步骤a-6)中的block中得到图像output_left4。
[0074]
b-6)将图像output_left4输入到扩大路径单元的第四扩大模块中,经过patch expanding层后,图像扩大为h/16*w/16*4c,将扩大后的图像与图像output_left3叠加操作后输入到步骤a-6)中的block中得到图像output_right3。patch expanding是来自论文swin-unet:unet-like pure transformer for medical image segmentation中第的7页,2021年在arxiv上发布。其中使用的算法有liear enbedding,patch mergering,patch expanding。patch mergering的作用是负责降采样和增维,patch expanding的作用是专门设计来执行上采样和降维的。patch是将一个长为h1*w1的正方形中的像素叠在一起,h1和w1取各4,得到一个长度为16的序列,即得到一个h1/4*w1/4*16的图像。liear enbedding的作用是修改维数,将16修改为c。
[0075]
b-7)将图像output_right3输入到扩大路径单元的第三扩大模块中,经过patch expanding层后,图像扩大为h/8*w/8*2c,将扩大后的图像与图像output_left2叠加操作后得到图像output_right2。
[0076]
b-8)将图像output_right2输入到扩大路径单元的第二扩大模块中,经过patch expanding层后,图像扩大为h/4*w/4*c,将扩大后的图像与图像output_left1叠加操作后输入到步骤a-6)中的block中得到图像output_right1。
[0077]
b-9)将图像output_right1输入到扩大路径单元的第一扩大模块中,经过patch expanding层后,图像扩大为h-*w-*1,其中h-为图像的高,w-为图像的宽,该图像为输出output。
[0078]
实施例6:
[0079]
步骤c)包括如下步骤:
[0080]
c-1)通过公式ciou_loss=1-ciou计算得到model1的损失函数ciou_loss,式中为矩形区域x和输出output的并集,union为矩形区域x和输出output的交集,distance_2为矩形区域x的图像的中心点和输出output的图像的中心点之间的欧式距离,distance_c为矩形区域x与输出output交叉的图像区域,
[0081][0082]
c-2)使用sigmoid函数将输出output中的值处理到[0.1]的范围内,将处理后的输出output命名为output sig,设置阈值为0.5,将output sig中大于等于阈值的点作为分割目标,将分割目标取值为1,将output sig中小于阈值的点作为背景,将背景取值为0,将由0和1构成的图像命名为output mask,output mask中0和1交界的地方为分割目标的边界;
[0083]
c-3)通过公式l
total
=αl
dice
βl
ac
计算得到model2的损失函数l
total
,式中α为β均为
权重值,α β=1,式中si为剪裁后的图像的mask中第i个像素点,i={1,2,...,n-},n-为剪裁后的图像的mask中像素点总数,gj为output mask中第j个像素点,j={1,2,...,n},n为output mask中像素点总数,l
ac
=∫
ω
δ
ε
(x)(《n(x),v(x)》 g
∞
)dx,式中ω为output的积分区域,δ
ε
(x)为光滑的狄拉克函数,ε为参数,ε>0,s为output mask中值为1的点的区域,为output mask分割目标的边界,为output mask分割目标的边界外边的点x到的欧式距离,为output mask分割目标的边界内部的点x到的欧式距离,矢量场n(x)对分割目标的边界进行法线处理,在水平集的表述中,它可以被定义为:为φ(x)的梯度值,为矩形区域x的梯度值,梯度的各向异性和不对称性特征由矢量场v(x)保障,gi为图像边缘指示器,b为常数,b>0,为欧几里得梯度算子,*为卷积算子,g
σ
为高斯核函数,i为矩形区域x。
[0084]
实施例7:
[0085]
步骤d)包括如下步骤:
[0086]
d-1)使用dataset类加载保存到npz的文件中图像数据image及bounding box对应的数据bbox。
[0087]
d-2)利用model1的损失函数ciou_loss通过adam优化器训练图像分割网络中的model1的参数,adam优化器的学习率的改变方式采用余弦退火学习率cosineannealinglr、最大学习率设置为0.3、最小设置为0.001、动量因子momentum设置为0.9、权重衰减weight_decay设置为0.05,其他的参数采用默认参数。训练时使用迭代器dataloader将dataset封装为一个迭代器,dataloader的参数为:batch_size设置为32,shuffle设置为true,num_workers设置为8。model1训练完成后,网络结构的参数最终保存网络的参数到ph文件中
[0088]
d-3)将npz的文件中图像数据image及mask切片封装到dataset,利用model2的损失函数l
total
通过sgd优化器训练图像分割网络中的model2的参数,sgd优化器的动量因子momentum设置为0.9、权重衰减weight_decay设置为0.0001,其他的参数使用默认的参数,训练时使用迭代器dataloader迭代数据,dataloader的参数设置为batch_size设置为32,shuffle设置为true,num_workers设置为8。最终保存网络的参数到ph文件中。优选的,训练时model1和model2都开启gpu,加速网络收敛速度。
[0089]
通过ph文件,加载训练后的网络结构的参数,将将预处理操作后的训练集的ct图像放入到model1中,经过训练后的图像分割网络的预测,得到输出output,该输出output即最终的分割结果。将分割结果的mask保存到nii.gz文件中。
[0090]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。