1.本发明涉及路况预测领域,特别涉及一种新能源汽车大数据路况预测系统。
背景技术:
2.由于汽车数量的急剧增高,不少城市的道路基础设施趋于饱和,无法满足人们的出行需求。对于城市发展而言,交通拥堵更会阻碍经济的发展,同时造成能源浪费和环境污染为解决交通拥堵,提高人们的出行体验。
3.为解决城市交通拥堵问题,给人们提供优质的出行体验,提出了基于车联网大数据分析的实时路况检测系统。使用gps技术对行驶的车辆进行数据采集,通过数据清洗和数据修复得到样本集合,利用改进模糊c均值聚类算法对样本数据进行分析,得出各路段的平均车速,进而得到相应路段的交通状态。该系统能够准确得获取道路上行驶车辆的交通数据,识别出当前路段的交通状态。
技术实现要素:
4.本发明的目的是设计一种新能源汽车大数据路况预测系统,在使用的时候得到相应路段的交通状态。
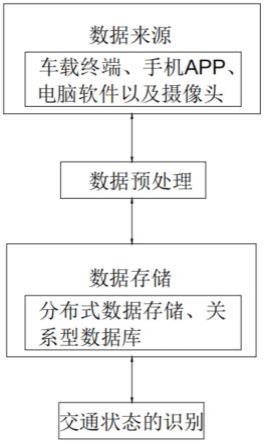
5.为了达到上述发明目的,本发明采用的技术方案为:一种新能源汽车大数据路况预测系统,其特征在于,包括数据来源、数据预处理、数据存储以及交通状态的识别,所述数据来源包括车载终端、手机app、电脑软件以及摄像头,所述数据预处理,采集到数据后,需要对数据进行预处理,所述数据存储包括分布式数据存储与关系型数据库,所述交通状态的识别通过数据挖掘算法,将这些隐藏的信息显示出来并供用户使用。
6.作为改进,所述预处理操作主要有数据清洗和数据修复,在进行数据清洗前,对gps模块采集到的数据进行标准化处理。
7.作为改进,所述数据清洗将数据标准化处理,需要对采集到的数据进行数据清洗,对采集到数据中的异常数据进行甄别并处理,对“异常数据”的识别。
8.作为改进,所述数据修复是指进行数据清洗后,根据数据“异常”的类型,进行相应的预测,并进行数据补充。
9.作为改进,所述异常数据主要分为异常车辆行驶数据和无用的干扰信息两类,异常数据的判断采用阈值判断法,阈值判断法是根据某个系统或属性的最值,来判断数据是否异常。
10.作为改进,所述分布式数据存储面向海量数据的存储访问与共享需求,实现分布式存储节点上多用户的访问共享。
11.作为改进,所述关系型数据库是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
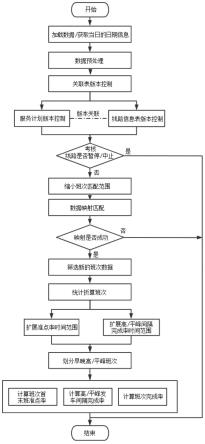
12.作为改进,所述交通状态的识别的数据挖掘算法为基于改进模糊c均值聚类算法,提取行驶车辆的瞬时车速。
13.作为改进,所述改进模糊c均值聚类算法的操作过程如下:
14.(1)利用canopy算法得出聚类中心v
(0)
和聚类个数c;
15.(2)合理设定模糊加权指数m和迭代终止阈值ε,并将常数k与迭代次数r设成0;
16.(3)计算隶属度矩阵u
(r)
和聚类中心v
(r l)
;
17.(4)比较‖v
(r 1)-v
(r)
‖与迭代终止阈值ε的大小,若‖v
(r 1)-v
(r)
‖小于迭代终止阈值e,则输出隶属度矩阵uk和聚类中心vk,否则,将r数值增1,重新从步骤(3)开始计算;
18.(5)计算u
xrk
的数值,若u
xrk
≥u
xrk-1
,则达到了迭代精度,输出隶属度矩阵u
k-1
和聚类中心u
k-1
,否则,将k的数值加1,重新设定模糊加权指数m
k,
返回步骤(2)重新计算,得到路段上车辆的平均速度;
19.(6)通过得到的道路平均速度可以作为判断道路交通状态的依据之一,道路交通状态可以分为:畅通缓行、拥堵和严重拥堵,这几种状态具有不同的道路平均数据区间,当计算得到的平均速度位于某种状态的速度区间时,得出当前某段路的交通状态。
20.本发明的有益效果是:在使用的时候得到相应路段的交通状态,利用gps技术和改进模糊c均值聚类算法,设计了基于车联网大数据分析的实时路况检测系统,从测试结果可以看出,本系统能够准确得获取道路上行驶车辆的交通数据,识别出当前路段的交通状态。地提高了道路通行以及交通疏导能力,缓解交通拥堵问题。
附图说明
21.图1为本发明一种新能源汽车大数据路况预测系统系统图。
具体实施方式
22.下面用具体实施例说明本发明,并不是对本发明的限制。
23.实施例一
24.一种新能源汽车大数据路况预测系统,包括数据来源、数据预处理、数据存储以及交通状态的识别,数据来源包括车载终端、手机app、电脑软件以及摄像头。
25.数据预处理,无论是采用gps技术、rfid技术,还是传感器来采集车辆行驶数据,均不可避免地会发生因高楼遮挡、雨雪天气、网络信号不稳定等原因造成的采集数据丢失.重复和错误等情况,从而导致对实时路况的解析发生偏差。采集到数据后,需要对数据进行预处理,预处理操作主要有数据清洗和数据修复。在进行数据清洗前,对gps模块采集到的数据进行标准化处理,使之拥有统一的格式,方便后续的清洗与修复操作。
26.数据清洗将数据标准化处理,需要对采集到的数据进行数据清洗。是指对采集到数据中的异常数据进行甄别并处理,对“异常数据”的识别,异常数据的识别情况将直接影响到数据质量,其不仅浪费存储空间,更会影响对实时路况信息的判断,从而影响用户体验。数据修复是指进行数据清洗后,根据数据“异常”的类型,进行相应的预测,并进行数据补充。
27.异常数据主要分为异常车辆行驶数据和无用的干扰信息两类,异常数据的判断采用阈值判断法。阈值判断法是根据某个系统或属性的最值,来判断数据是否异常,由于每条道路均有其限定的最高车速,因而该极值便可作为判断行驶车辆车速数据是否异常的标准。
28.数据存储包括分布式数据存储与关系型数据库,交通状态的识别通过数据挖掘算法,将这些隐藏的信息显示出来并供用户使用。分布式数据存储面向海量数据的存储访问与共享需求,提供基于多存储节点的高性能,高可靠和可伸缩性的数据存储和访问能力,实现分布式存储节点上多用户的访问共享,关系型数据库是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
29.交通状态的识别的数据挖掘算法为基于改进模糊c均值聚类算法,提取行驶车辆的瞬时车速。改进模糊c均值聚类算法的操作过程如下:
30.利用canopy算法得出聚类中心v
(0)
和聚类个数c;合理设定模糊加权指数m和迭代终止阈值ε,并将常数k与迭代次数r设成0;计算隶属度矩阵u
(r)
和聚类中心v
(r l)
;比较‖v
(r 1)-v
(r)
‖与迭代终止阈值ε的大小,若‖v
(r 1)-v
(r)
‖小于迭代终止阈值e,则输出隶属度矩阵uk和聚类中心vk,否则,将r数值增1,重新从计算隶属度矩阵u
(r)
和聚类中心v
(r l)
开始计算。
31.计算u
xrk
的数值,若u
xrk
≥u
xrk-1
,则达到了迭代精度,输出隶属度矩阵u
k-1
和聚类中心u
k-1
,否则,将k的数值加1,重新设定模糊加权指数m
k,
返回合理设定模糊加权指数m和迭代终止阈值ε,并将常数k与迭代次数r设成0重新计算,得到路段上车辆的平均速度。
32.通过得到的道路平均速度可以作为判断道路交通状态的依据之一,道路交通状态可以分为:畅通缓行、拥堵和严重拥堵,这几种状态具有不同的道路平均数据区间,当计算得到的平均速度位于某种状态的速度区间时,得出当前某段路的交通状态。
33.以上,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。