一种基于bert unilm并融合音形特征的纠错模型
技术领域
1.本发明涉及nlp领域中文句子中字词纠错方法,具体涉及一种基于bert unilm并融合音形特征的纠错模型。
背景技术:
2.中文纠错技术是实现中文语句自动检查、自动纠错的一项重要技术,其目的是提高语言正确性的同时减少人工校验的成本。在通用领域中,中文文本纠错问题是从互联网起始就一直在寻求解决方案的问题。在搜索引擎中,一个好的纠错系统能够对用户的查询词进行纠错提示或者直接展示正确的答案。在asr系统中,面临的问题是发音相似导致系统难以识别出正确的内容,所以也需要纠错模块的介入。目前主流的纠错方案一般包括错误检测、候选召回、候选排序这三部分,基于规则的方法有ngram模型检测纠错,近年来随着nlp(自然语言处理)技术的不断深入,基于深度神经网络的方法取得了较好的效果,这些方法主要分成两类:第一种是先使用一个序列标注模型(lstm/transformer crf)去检测中文语句中存在的字错误,然后桥接候选召回和候选排序;第二种是基于神经机器翻译的纠错方法,即将错误句子放做源语言,正确句子当作目标语言,预想利用模型将错误的句子翻译成正确的句子,利用seq2seq模型完成端到端的纠错过程。
3.上述中第一类方法属于非端到端的纠错,纠错的效果很大程度上取决于混淆集的构建,纠错过程比较复杂;第二类方法数据端到端的纠错方法,模型训练好以后使用简单,但是seq2seq类的autoregressive(自回归)的生成模型其在解码的时候要求只能接收来自单侧的信息,而bert预训练模型是自编码模型其在预训练的时候得到的信息是双向的,所以理论上来说原生的bert模型是不太适合文本生成类任务的,无法利用其在大规模语料上预训练学习到的信息来提升文本生成的效果。
技术实现要素:
4.本发明所要解决的技术问题是提供一种基于bert unilm并融合音形特征的纠错模型,针对中文文本纠错中的音近字和形近字的检错和纠错精度差,生成模型无法使用bert预训练模型问题;其是针对第二类方法进行改进,改造bert预训练模型使其适用于生成类任务,从而提升纠错效果;本发明中提取中文句子中每个字的音和形特征,然后将特征都映射为一个固定维度的向量,进一步通过highway层做特征的融合和过滤,并且使用rnn提取深层次的特征,将结果经过非线性变换后加到bert预训练模型中layernormlization(层归一化)中的参数上做条件文本生成;采用bert unilm方案来使用预训练模型生成正确的文本,其基本思想是在bert的自注意力矩阵中mask掉当前预测词及其之后的信息,从而间接的达到自回归的要求。
5.本发明基于bert unilm并融合音形特征的纠错模型是通过以下技术方案来实现的:包括以下步骤:
6.s1、特征提取;
7.s2、特征与layernormalization融合;
8.s3、bert unilm训练。
9.作为优选的技术方案,在s1中,特征提取具体包括以下步骤:
10.s11、使用pypinyin工具和中文四角编码数据库提取中文句子中每个字的拼音和四角编码,其中拼音和中文句子是对齐的因为每个中文都有一个拼音与之对应,数字等没有拼音的字符用unk表示;四角编码是汉语字典常用的检字方法之一,用最多5个阿拉伯数字来对汉字进行归类;
11.s12、本发明中将每个拼音映射为一个固定维度为h的向量,将长度为5的四角编码数字串也同样映射为维度为h的向量,那么对于一个长度为l的中文句子,其拼音特征矩阵为l
×
h的矩阵hw,字形特征同样为l
×
h的矩阵hc;
12.s13、将上一步得到的矩阵hw和hc拼接成一个l
×
2h的矩阵,将这个矩阵送入highway层做特征的融合和过滤,highway层的公式如下:
13.z=t
⊙
g(wh[hw;hc] bh) (1-t)
⊙
[hw;hc]
[0014]
t=θ(w
t
[hw;hc] b
t
);
[0015]
s14、将上一步得到的结果,通过lstm(long short-term memory)网络进一步提取深层特征,lstm的公式如下:
[0016]i(t)
=σ(w(i)x
(t)
u(i)h
(t-1)
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(input gate)
[0017]f(t)
=σ(w
(f)
x
(t)
u
(f)h(t-1)
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(forget gate)
[0018]o(t)
=σ(w
(o)
x
(t)
u
(o)h(t-1)
)
ꢀꢀꢀꢀꢀ
(output/exposure gate)
[0019][0020][0021][0022]
作为优选的技术方案,在s2中,特征与layernormalization融合具体包括以下步骤:
[0023]
layernormalization可以缓解internal covariate shift(内部协变量偏移)问题,可以将数据分布拉到激活函数的非饱和区,具有权重或者数据伸缩不变性的特带你,起到缓解梯度消失/爆炸、加速训练和正则化的效果;layernormalization的公式如下:
[0024][0025][0026][0027]
在图像生成中条件bn(batchnormalization)是将已有的normalization方法中的g和b变成输入条件的函数,从而可以通过条件来控制生成的行为;而在bert模型中,主要的normalization方法是layernormalization,所以很自然就能想到将对应的g和b变成输入条件的函数,来控制bert的生成行为,对于已经预训练好的模型来说,已经有现成的无条件的g和b了,他们都是固定长度的向量;所以我们可以通过两个不同的变换矩阵,将输入条件
变换到跟g和b一样的维度,然后将两个变换结果分别加到g和b上;为了防止扰乱原来的预训练权重,两个变换矩阵可以全零初始化,这样在初始状态依然保持跟原来的预训练模型一致。
[0028]
作为优选的技术方案,在s3中,bert unilm训练具体包括以下步骤:
[0029]
s31、原生的bert预训练模型,因为其双向自编码机制的限制,在预训练的时候随机mask句子中的字或者词语,然后用被mask的字或者词语两侧的信息来预测mask位置的字词,所以其本身是不太适合文本生成类的任务;seq2seq类生成模型,一般是单向的(正向)的语言模型,其关键点是要防止看到“未来信息”,如下式,预测x1的时候,是没有任何的外部输入的,而预测x2的时候只能输入x1,预测x3的时候只能输入x1和x2以此类推;
[0030]
p(x1,x2,x3,...,xn)=p(x1)p(x2|x1)p(x3|x1,x2)...p(xn|x1,...,x
n-1
);
[0031]
s32、之前介绍的rnn、lstm模型是天然适合做语言模型的,因为他本身就是递归运算,如果用cnn(卷积)来做的话,则需要对卷积核进行mask,即需要对卷积核对应右边的部分置零,如果是bert这种transformer类架构的模型,
[0032]
则需要一个特殊的下三角矩阵形式的attention矩阵;transformer中
[0033]
attention矩阵的数学形式如下:
[0034][0035]
这里q,k,v分别代表query、key、value的向量序列,其中我们可以认为key和value是一一对应的,而qk
t
则是将query、key的向量两两做内积,然后用softmax归一化,就得到一个attention矩阵,它描述的是query和key之间任意两个元素的关联强度;目前最常用的attention方式是self-attention,即q,k,v都是同一个向量序列经过线性变换而来的,而transformer则是self-attention跟point-wise全连接层(相当于kernel size为1的一维卷积)的组合;所以,transformer就是基于attention的向量序列到序列的变换;
[0036]
s33、为了将bert预训练模型与seq2seq相结合,需要一个特别的mask矩阵,将bert中的attention矩阵变成下三角矩阵,这个方法叫做unilm;
[0037]
s34、训练阶段用到的损失函数为,多分类的交叉熵(categorical crossentropy),其公式为:
[0038][0039]
其中n为训练样本数,k为字表中字的数量;需要注意的是,在计算损失函数的时候我们mask掉输入句子的那部分loss,只关注期望输出的正确句子的loss。
[0040]
本发明的有益效果是:
[0041]
1、本发明中将中文的音和形特征映射到一个固定长度的向量,并且与预训练模型相结合,可以有效的提升模型对于中文句子中音近字和形近字的检错和纠错效果。
[0042]
2、本发明中对于目前的预训练模型的研究,有两个方向:一是加大模型的规模提升参数量和训练数据来提升模型在下游任务中的表现;二是模型轻量化,牺牲较小的精度来精简模型,使其满足落地的需求;本发明中的模型可以将bert替换为albert或者roberta-tiny等轻量级的预训练模型,以满足人工智能场景化落地,同时并不会大幅度降低纠错效果。
附图说明
[0043]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0044]
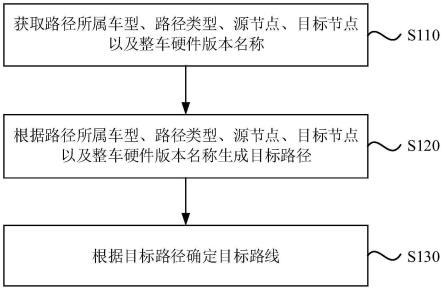
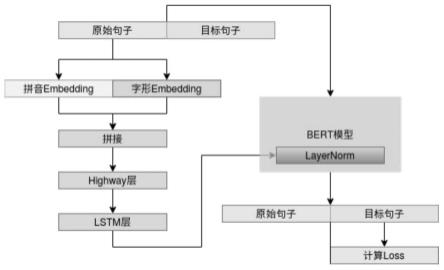
图1为本发明的训练阶段示意图;
[0045]
图2为本发明的推理预测阶段示意图。
具体实施方式
[0046]
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
[0047]
本发明的一种基于bert unilm并融合音形特征的纠错模型,包括以下步骤:
[0048]
s1、特征提取;
[0049]
s2、特征与layernormalization融合;
[0050]
s3、bert unilm训练。
[0051]
本实施例中,在s1中,特征提取具体包括以下步骤:
[0052]
s11、使用pypinyin工具和中文四角编码数据库提取中文句子中每个字的拼音和四角编码,其中拼音和中文句子是对齐的因为每个中文都有一个拼音与之对应,数字等没有拼音的字符用unk表示;四角编码是汉语字典常用的检字方法之一,用最多5个阿拉伯数字来对汉字进行归类,也就是说每个中文对应的四角编码为5个数字,数字等没有没有四角编码的字符用unk表示;
[0053]
s12、本发明中将每个拼音映射为一个固定维度为h的向量,将长度为5的四角编码数字串也同样映射为维度为h的向量,那么对于一个长度为l的中文句子,其拼音特征矩阵为l
×
h的矩阵hw,字形特征同样为l
×
h的矩阵hc。
[0054]
s13、将上一步得到的矩阵hw和hc拼接成一个l
×
2h的矩阵,将这个矩阵送入highway层做特征的融合和过滤,highway层的公式如下:
[0055]
z=t
⊙
g(wh[hw;hc] bh) (1-t)
⊙
[hw;hc]
[0056]
t=θ(w
t
[hw;hc] b
t
)
[0057]
g表示激活函数,wh,w
t
表示一个2h
×
2h的矩阵,bh,b
t
表示维度为2h的向量,θ表示激活函数sigmoid。
[0058]
s14、将上一步得到的结果,通过lstm(long short-term memory)网络进一步提取深层特征,lstm的公式如下:
[0059]i(t)
=σ(w(i)x
(t)
u(i)h
(t-1)
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(input gate)
[0060]f(t)
=σ(w
(f)
x
(t)
u
(f)h(t-1)
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(forget gate)
[0061]o(t)
=σ(w
(o)
x
(t)
u
(o)h(t-1)
)
ꢀꢀꢀ
(output/exposure gate)
[0062][0063][0064]
[0065]
本实施例中,在s2中,特征与layernormalization融合具体包括以下步骤:
[0066]
layernormalization可以缓解internal covariate shift(内部协变量偏移)问题,可以将数据分布拉到激活函数的非饱和区,具有权重或者数据伸缩不变性的特带你,起到缓解梯度消失/爆炸、加速训练和正则化的效果。layernormalization的公式如下:
[0067][0068][0069][0070]
在图像生成中条件bn(batchnormalization)是将已有的normalization方法中的g和b变成输入条件的函数,从而可以通过条件来控制生成的行为。而在bert模型中,主要的normalization方法是layernormalization,所以很自然就能想到将对应的g和b变成输入条件的函数,来控制bert的生成行为,对于已经预训练好的模型来说,已经有现成的无条件的g和b了,他们都是固定长度的向量。所以我们可以通过两个不同的变换矩阵,将输入条件变换到跟g和b一样的维度,然后将两个变换结果分别加到g和b上。为了防止扰乱原来的预训练权重,两个变换矩阵可以全零初始化,这样在初始状态依然保持跟原来的预训练模型一致。
[0071]
本实施例中,在s3中,bert unilm训练具体包括以下步骤:
[0072]
s31、原生的bert预训练模型,因为其双向自编码机制的限制,在预训练的时候随机mask句子中的字或者词语,然后用被mask的字或者词语两侧的信息来预测mask位置的字词,所以其本身是不太适合文本生成类的任务。seq2seq类生成模型,一般是单向的(正向)的语言模型,其关键点是要防止看到“未来信息”,如下式,预测x1的时候,是没有任何的外部输入的,而预测x2的时候只能输入x1,预测x3的时候只能输入x1和x2以此类推。
[0073]
p(x1,x2,x3,...,xn)=p(x1)p(x2|x1)p(x3|x1,x2)...p(xn|x1,...,x
n-1
)
[0074]
s32、之前介绍的rnn、lstm模型是天然适合做语言模型的,因为他本身就是递归运算,如果用cnn(卷积)来做的话,则需要对卷积核进行mask,即需要对卷积核对应右边的部分置零,如果是bert这种transformer类架构的模型,
[0075]
则需要一个特殊的下三角矩阵形式的attention矩阵。transformer中attention矩阵的数学形式如下:
[0076][0077]
这里q,k,v分别代表query、key、value的向量序列,其中我们可以认为key和value是一一对应的,而qk
t
则是将query、key的向量两两做内积,然后用softmax归一化,就得到一个attention矩阵,它描述的是query和key之间任意两个元素的关联强度。目前最常用的attention方式是self-attention,即q,k,v都是同一个向量序列经过线性变换而来的,而transformer则是self-attention跟point-wise全连接层(相当于kernel size为1的一维卷积)的组合。所以,transformer就是基于attention的向量序列到序列的变换。
[0078]
s33、为了将bert预训练模型与seq2seq相结合,需要一个特别的mask矩阵,将bert
中的attention矩阵变成下三角矩阵,这个方法叫做unilm。unilm直接将seq2seq当成句子补全任务,假如输入的错误句子为“自然与言处理”,那么其对应的正确句子为“自然语言处理”,模型训练的时候将这两个句子拼接成一个:
[0079][0080]
经过这样的转化之后,最简单的方案就是训练一个语言模型,输入给模型“[cls]自然与言处理[sep]”来逐字预测“自然语言处理”,直到出现“[sep]”为止,即下面图:
[0081][0082]
不过上图只是最朴素的方案,它把“自然与言处理”这个错误的句子也加入了预测的范围,这样的话这个attention矩阵是单向的,即其对应的mask矩阵是一个标准的下三角矩阵,事实上这是不必要的,属于额外的约束,真正要预测的是“自然语言处理”这部分,所以把“自然与言处理”这部分的mask去掉,得到下图中的mask:
[0083]
[0084]
这样将输入部分的attention矩阵变成双向的,输出部分的attention矩阵是单向的,并且没有额外的约束。
[0085]
s34、训练阶段用到的损失函数为,多分类的交叉熵(categorical crossentropy),其公式为:
[0086][0087]
其中n为训练样本数,k为字表中字的数量。需要注意的是,在计算损失函数的时候我们mask掉输入句子的那部分loss,只关注期望输出的正确句子的loss。
[0088]
本发明中,训练和推理阶段的的过程是存在差异的,主要体现在以下三个方面:
[0089]
1、训练阶段,由于是平行文本,可以按照上部分中写的那样将错误句子和正确句子拼接起来输入给模型(如图1所示),而预测的时候我们是不知道正确的句子的,所以第一步预测的时候输入给模型的只是错误的句子;
[0090]
2、训练的时候,模型是一次性输出所有的正确句子的token,而推理的时候是递归进行的,即每次只预测一个token,然后将上一部预测的token与错误的句子拼接起来,再次输入给模型,预测下一个token,直到出现结束标志或满足了最大长度才停止(如图2所示)。
[0091]
在解码(预测推理)的时候,使用greedysearch(贪心搜索)解码。贪心算法在每一步直接取字表中条件概率最大的字,作为输出,即每一步都选择在当前状态下最好或者最优的选择,通过这种局部最优策略期望输出全局最优序列。
[0092]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何不经过创造性劳动想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书所限定的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。