技术特征:
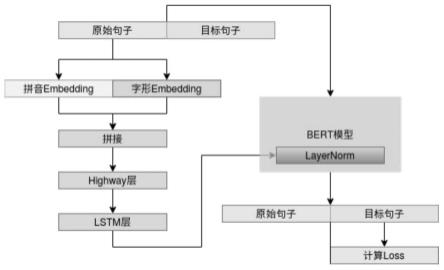
1.一种基于bert unilm并融合音形特征的纠错模型,其特征在于,包括以下步骤:s1、特征提取;s2、特征与layernormalization融合;s3、bert unilm训练。2.根据权利要求1所述的基于bert unilm并融合音形特征的纠错模型,其特征在于,在s1中,特征提取具体包括以下步骤:s11、使用pypinyin工具和中文四角编码数据库提取中文句子中每个字的拼音和四角编码,其中拼音和中文句子是对齐的,每个中文都有一个拼音与之对应,没有拼音的字符用unk表示;四角编码是汉语字典常用的检字方法之一,用最多5个阿拉伯数字来对汉字进行归类;s12、将每个拼音映射为一个固定维度为h的向量,将长度为5的四角编码数字串映射为维度为h的向量,那么对于一个长度为l的中文句子,其拼音特征矩阵为l
×
h的矩阵h
w
,字形特征同样为l
×
h的矩阵h
c
;s13、将上一步得到的矩阵h
w
和h
c
拼接成一个l
×
2h的矩阵,将这个矩阵送入highway层做特征的融合和过滤,highway层的公式如下:z=t
⊙
g(w
h
[h
w
;h
c
] b
h
) (1-t)
⊙
[h
ω
;h
c
]t=θ(w
t
[h
ω
;h
c
] b
t
);s14、将上一步得到的结果,通过lstm网络进一步提取深层特征,lstm的公式如下:i
(t)
=σ(w
(i)
x
(t)
u
(i)
h
(t-1)
)(input gate)f
(t)
=σ(w
(f)
x
(t)
u
(f)
h
(t-1)
)(forget gate)o
(t)
=σ(w
(o)
x
(t)
u
(o)
h
(t-1)
)(output/exposure gate)gate)gate)3.根据权利要求1所述的基于bert unilm并融合音形特征的纠错模型,其特征在于,在s2中,特征与layernormalization融合具体包括以下步骤:layernormalization用于缓解内部协变量偏移问题,将数据分布拉到激活函数的非饱和区,具有权重或者数据伸缩不变性的特点,起到缓解梯度消失/爆炸、加速训练和正则化的效果;layernormalization的公式如下:的效果;layernormalization的公式如下:的效果;layernormalization的公式如下:在图像生成中条件bn将已有的normalization方法中的g和b变成输入条件的函数,从而通过条件来控制生成的行为;两个变换矩阵全零初始化,这样在初始状态依然保持跟原
来的预训练模型一致。4.根据权利要求1所述的基于bert unilm并融合音形特征的纠错模型,其特征在于,在s3中,bert unilm训练具体包括以下步骤:s31、原生的bert预训练模型,因为其双向自编码机制的限制,在预训练的时候随机mask句子中的字或者词语,然后用被mask的字或者词语两侧的信息来预测mask位置的字词,所以其本身是不太适合文本生成类的任务;seq2seq类生成模型,一般是单向的语言模型,如下式,预测x1的时候,是没有任何的外部输入的,而预测x2的时候只能输入x1,预测x3的时候只能输入x1和x2以此类推;p(x1,x2,x3,...,x
n
)=p(x1)p(x2|x1)p(x3|x1,x2)...p(x
n
|x1,...,x
n-1
);s32、如果用cnn来做的话,则需要对卷积核进行mask,即需要对卷积核对应右边的部分置零,如果是bert这种transformer类架构的模型,则需要一个特殊的下三角矩阵形式的attention矩阵;transformer中attention矩阵的数学形式如下:这里q,k,v分别代表query、key、value的向量序列,其中key和value一一对应,而qk
t
则是将query、key的向量两两做内积,然后用softmax归一化,就得到一个attention矩阵,其描述的是query和key之间任意两个元素的关联强度;attention方式采用self-attention,即q,k,v都是同一个向量序列经过线性变换而来的,而transformer则是self-attention跟point-wise全连接层的组合;所以,transformer就是基于attention的向量序列到序列的变换;s33、为了将bert预训练模型与seq2seq相结合,需要一个特别的mask矩阵,将bert中的attention矩阵变成下三角矩阵,这个方法叫做unilm;s34、训练阶段用到的损失函数为,多分类的交叉熵(categorical crossentropy),其公式为:其中n为训练样本数,k为字表中字的数量。
技术总结
本发明公开了一种基于BERTUNILM并融合音形特征的纠错模型,包括特征提取、特征与LayerNormalization融合以及BERTUNILM训练。本发明能将拼音和字形的特征提取与融合;将提取到的音形特征融合到BERT的LayerNormalization(层归一化)层;BERTUNILM模型根据输入的含有字词错误的中文句子,自回归解码生成正确的句子。归解码生成正确的句子。归解码生成正确的句子。
技术研发人员:朱贺 樊治国
受保护的技术使用者:青岛高重信息科技有限公司
技术研发日:2022.10.20
技术公布日:2023/1/31
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。