1.本发明属于行为识别技术领域,具体涉及基于人体骨架的科目三安全员作弊行为检测方法及系统。
背景技术:
2.随着人们生活水平的不断提高,便捷的交通出行是人们的一大需求,而出行的安全更是重中之重。机动车驾驶技能越来越受到人们的关注,每年都会有数以万计的学员考取驾驶证,通过驾驶专业技能的培训并最终考核达标后方能驾驶车辆上路,从而尽量避免汽车在行驶的过程中发生交通事故,事故的发生不仅仅会对车辆本身造成一定影响,对人们的安全和经济都产生非常严重的威胁。
3.我国现阶段的机动车驾驶人驾驶技能考试采用的是计算机评判和考试员人工评判相结合的评判方式。目前仅实现了部分考试项目的数据采集和自动考核评分,还有部分考试项目仍需要监考人员随车监考。
4.有鉴于此,有必要提出一种科目三考试车辆上安全员行为识别方法,以实现真正意义上的驾驶考试公正、公平、公开,进一步提高学员的考试质量。
5.以往的监管系统大多依赖于人力,在起初技术不发达阶段,单纯的依靠安全相关人员的监管,受限于监管人员的个人素养和数量问题,漏洞频出。而当前阶段,在安全生产领域已经大量推广普及监控系统,但其中鲜有能够提供对人员进行智能化识别的功能,更无法做到对监控范围内的人员的动作行为进行实时监管,需要由管理人员时刻注意着监控画面,因而仍然存在着较大的漏洞。
技术实现要素:
6.为解决上述技术问题,本发明提出基于人体骨架的科目三安全员作弊行为检测方法及系统。本发明采用以下技术方案:基于人体骨架的科目三安全员作弊行为检测方法,针对机动车驾驶人科目三考试车内的视频影像,执行以下步骤,判断科目三车内的安全员是否存在预设各类型的违规作弊行为:步骤a:基于机动车驾驶人科目三考试车内的视频影像,利用预训练的以帧图片为输入,以该帧图片中各人对应的人体矩形框、矩形框坐标信息和矩形框置信度为输出的人体目标识别模型,获得帧图片中各人分别对应的人体矩形框、矩形框坐标信息和各矩形框置信度,进而获得安全员对应的人体矩形框;步骤b:基于人体目标识别模型输出的安全员对应的人体矩形框,利用预训练的以人体矩形框为输入,该人体矩形框中人体的各预设关键点为输出的关键点识别模型,获得安全员人体的各预设关键点;步骤c:基于关键点识别模型输出的安全员人体的各预设关键点,进行安全员行为识别,进而判断科目三车内的安全员是否存在预设各类型的违规作弊行为。
7.作为本发明的一种优选技术方案,所述步骤a中,针对帧图片中各人分别对应的人体矩形框、矩形框坐标信息和矩形框置信度,基于预设置信度阈值,获得各高于预设置信度阈值的人体矩形框,进而基于各人体矩形框坐标信息,将各矩形框左上角横坐标最小对应的矩形框作为安全员对应的人体矩形框。
8.作为本发明的一种优选技术方案,所述步骤a中,所述人体目标识别模型采用yolo-v5网络模型,其中采用focus结构和csp结构作为yolo-v5网络的backbone,采用fpn pan结构作为yolo-v5网络的neck,采用bbox_head作为yolo-v5网络的yolohead。
9.作为本发明的一种优选技术方案,所述步骤a中,所述预训练的人体目标识别模型通过coco数据集和历史机动车驾驶人科目三考试车内的图片数据集,基于人体矩形框作为数据集标签进行预训练,再基于包含安全员违规作弊行为科目三车内图片数据集作为正样本集,不包含安全员违规作弊行为科目三车内图片数据集作为负样本集进行针对性训练获得;所述步骤b中,所述预训练的关键点识别模型通过coco数据集和历史机动车驾驶人科目三考试车内的图片数据集,基于人体各预设关键点作为数据集标签进行预训练,再基于包含安全员违规作弊行为科目三车内图片数据集作为正样本集,不包含安全员违规作弊行为科目三车内图片数据集作为负样本集进行针对性训练获得;针对各数据集采用数据翻转与数据裁剪进行数据扩充,并将各数据归一化为(-0.5, 0.5)。
10.作为本发明的一种优选技术方案,所述步骤b中,所述关键点识别模型采用lite hrnet网络模型结合top-bottom方式进行关键点识别,其中采用优化的lite-hrnet-18作为lite hrnet网络的backbone和neck,采用top down simple head作为lite hrnet网络的keypoint_head。
11.作为本发明的一种优选技术方案,所述lite hrnet网络模型中采用hardswish激活函数,将sigmoid激活函数替换为0.5* (x/(1 torch.abs(x))) 0.5。
12.作为本发明的一种优选技术方案,所述步骤b中,所述各预设关键点包括人体鼻子、左肩、右肩、左肘、右肘、左腕、右腕、左胯、右胯、左膝、右膝、左脚、右脚。
13.作为本发明的一种优选技术方案,所述步骤c中,基于关键点识别模型输出的安全员人体的各预设关键点,提取安全员的左肩、右肩、左肘、右肘、左腕、右腕六个关键点,执行以下步骤,进行安全员行为识别,进而判断科目三车内的安全员是否存在预设各类型的违规作弊行为:步骤c1:针对安全员右肩、右肘、右腕的三个关键点,基于右肩关键点到右肘关键点构成的线段和右腕关键点到右肘关键点构成的线段,以右肘关键点为顶点两线段构成的夹角,当该夹角处于预设范围角度,并且右腕关键点在车窗区域内,则判定安全员存在违规作弊行为;步骤c2:针对安全员左肩、左肘以及左腕的三个关键点,基于左肩关键点到左肘关键点构成的线段和左腕关键点到左肘关键点构成的线段,以左肘关键点为顶点两线段构成的夹角,当该夹角处于预设范围角度,并且左腕关键点在档位区域或手刹区域,判定安全员存在违规作弊行为;步骤c3:针对方向盘区域,若左腕或右腕关键点在方向盘区域内,判定安全员存在
违规作弊行为。
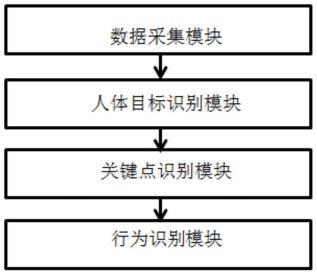
14.一种基于人体骨架的科目三安全员作弊行为检测系统,应用于所述基于人体骨架的科目三安全员作弊行为检测方法,其特征在于:包括数据采集模块、人体目标识别模块、关键点识别模块、行为识别模块;数据采集模块用于采集机动车驾驶人科目三考试车内的视频影像;人体目标识别模块基于采集的科目三车内的视频影像,对视频影像中帧图片进行识别,获得帧图片中安全员对应的人体矩形框;关键点识别模块基于人体目标识别模型输出的安全员对应的人体矩形框,对安全员对应的人体矩形框进行识别,获得安全员人体的各预设关键点;行为识别模块基于关键点识别模型输出的安全员人体的各预设关键点,进行安全员行为识别,进而判断科目三车内的安全员是否存在预设各类型的违规作弊行为。
15.一种基于人体骨架的科目三安全员作弊行为检测终端,包括存储器和处理器,所述存储器和所述处理器之间互相通信连接,所述存储器中存储有计算机指令,所述处理器通过执行所述计算机指令,从而执行权利要求1-8任一项所述基于人体骨架的科目三安全员作弊行为检测方法。
16.本发明的有益效果是:本发明提出了基于人体骨架的科目三安全员作弊行为检测方法及系统,结合了目标识别、人体关键点提取、行为识别等技术,并在此技术上进行优化提升,人体关键点提取的数据处理方法,以及网络结构中的将relu激活函数替换为更强的hardwish激活函数,同时把sigmoid换成了一个近似实现的函数,以解决推理不对齐的问题;在损失函数上,对mse输出的结果进行了排序,并筛选其中难例部分进行重点回归,在后处理部分,通过二维处理判断来解决三维的问题。为安全监管人员提供了一种具有实时性的安全员作弊行为检测的方式;并且本发明无须使用人体深度信息摄像头来获取人体关键点信息,通过深度学习的方式,仅通过传统rgb视频影像即可获得可信的人体关键点信息并进行不安全行为的识别,能够简单快速的于现有的监控设备相结合;本发明拥有多种检测识别,在应对安全生产场所复杂多变的环境时,仍然具有较高的识别精度和较快的识别速度。
附图说明
17.图1为本发明系统框图;图2为本发明实施例lite hrnet网络模型原理流程图;图3为本发明实施例人体各关键点示意图;图3中:0——鼻子, 1——左肩,2——右肩,3——左肘,4——右肘,5——左腕,6——右腕,7——左胯,8——右胯,9——左膝,10——右膝,11——左脚,12——右脚。
具体实施方式
18.下面结合附图对本发明进行进一步说明。下面的实施例可使本专业技术人员更全面地理解本发明,但不以任何方式限制本发明。
19.本实施例提供了一种基于人体骨架的科目三安全员作弊行为检测方法及系统,可以应用于科目三中对安全员进行实时监控,进而判断安全员是否存在预设各类型的帮助考
生作弊的行为。
20.基于人体骨架的科目三安全员作弊行为检测方法,针对机动车驾驶人科目三考试车内的视频影像,执行以下步骤,判断科目三车内的安全员是否存在预设各类型违规作弊行为:步骤a:基于机动车驾驶人科目三考试车内的视频影像,利用预训练的以帧图片为输入,以该帧图片中各人对应的人体矩形框、矩形框坐标信息和矩形框置信度为输出的人体目标识别模型,获得帧图片中各人分别对应的人体矩形框、矩形框坐标信息和各矩形框置信度,进而获得安全员对应的人体矩形框;可以通过视频采集设备获取实时视频影像,进而利用人体目标识别模型实时提取安全员对应的人体矩形框。
21.所述步骤a中,针对帧图片中各人分别对应的人体矩形框、矩形框坐标信息和矩形框置信度,矩形框置信度即为基于该目标识别模型预测的矩形框置信度,目标识别模型是多目标识别,非单目标识别,所以输出的时候,会存在多个目标框,进而基于预设置信度阈值,获得各高于预设置信度阈值的人体矩形框,进而基于各人体矩形框坐标信息,将各矩形框左上角横坐标最小对应的矩形框作为安全员对应的人体矩形框。目标识别模型基于图片中各个像素点对应预设各类型特征的结果实现。
22.所述人体目标识别模型采用yolo-v5网络模型,其中采用focus结构和csp结构作为yolo-v5网络的backbone主干网络,采用fpn pan结构作为yolo-v5网络的neck,采用bbox_head作为yolo-v5网络的yolohead。backbone为主干网络;focus结构为focus structure,focus模块在yolo-v5中是图片进入backbone前对图片进行切片操作; csp为cross stage partial network,是跨阶段局部网络;fpn为特征金字塔网络,是用来提取不同尺度特征图的,提供给后面的网络执行预测任务;pan为perceptual adversarial network感知对抗网络;yolohead为yolo网络的头部;bbox_head是在neck(颈部网络)提供的特征层上进行预测,bbox_head主要对目标框bbox进行检测头部简称。
23.所述人体目标识别模型通过coco数据集和历史机动车驾驶人科目三考试车内的图片数据集,依照coco数据集格式合并为一个数据集,按照9:1的比例,将上述两个数据集进行统一处理融合后的数据集划分为训练集和测试集,基于人体矩形框作为数据集标签进行预训练,即可对各人体矩形框和各矩形框坐标等进行标注;本方案中,所述yolo-v5在预训练完成之后需要针对作弊行为数据集进行针对性训练,提高对于驾考场景中安全员作弊行为的人体目标识别精度,因此再基于包含安全员违规作弊行为科目三车内图片数据集作为正样本集,不包含安全员违规作弊行为科目三车内图片数据集作为负样本集进行针对性训练获得,同样基于人体矩形框作为数据集标签,将各样本集依照coco数据集格式合并为一个数据集,依照9:1的比例,将上述两个数据集进行统一处理融合后的数据集划分为训练集和测试集。针对各数据集采用数据翻转与数据裁剪进行数据扩充,并将各数据归一化为(-0.5, 0.5)。对于上述两个数据集,由于其标注信息存在大量类别,本发明仅提取标注信息中的person类bbox信息,建立具有高鲁棒性的人体目标识别模型。
24.根据上述所得人体目标识别模型,对实时采集的视频的帧图片信息识别,将视频输入的帧图片重置为320
×
320像素分辨率的图片,保留图片原始的位置信息和缩放比例,对于空白部分进行空白填充,获得各人体所处矩形包围框及坐标信息和预测置信度。
25.步骤b:基于人体目标识别模型输出的安全员对应的人体矩形框,利用预训练的以
人体矩形框为输入,即人体矩形框图片为输入,该人体矩形框中人的各预设关键点为输出的关键点识别模型,获得安全员人体的各预设关键点,即可获得各关键点位置信息。
26.所述步骤b中,所述步骤b中,所述关键点识别模型采用lite hrnet网络模型结合top-bottom方式进行关键点识别,其中采用优化的lite-hrnet-18作为lite hrnet网络的backbone和neck,采用top down simple head作为lite hrnet网络的keypoint_head。top down simple head为自上而下的简单头部;lite hrnet为a lightweight high-resolution network;keypoint_head是主要对关键点进行检测头部的简称。
27.所述lite hrnet网络模型中使用hardswish激活函数,并将sigmoid激活函数替换为0.5* (x/(1 torch.abs(x))) 0.5。
28.所述的步骤b中人体网络结构优化包括如下:首先,人体关键点识别中考虑到之前的人体目标识别模型,在关键点识别中应用top-bottom进行人体关键点识别。top-bottom是先检测人,再裁剪出来对每个人去检测关键点;而bottom-up则相反,直接检测出所有的关键点,再依次组合成一个人。这里和目标检测中的one-stage和two-stage其实有点神似,一般来说,top-bottom方式精度高,但是速度慢一点,而bottom-up速度快,但是精度差一点。由于我们使用轻量化网络,为了保证精度不减,所以使用top-bottom,即先检测人再检测关键点,基于步骤a中已经检测出人,现在在检测出人的基础上检测出关键点。所用人体骨骼关键点检测网络模型采用轻量级网络优化的lite-hrnet-18为 backbone 和neck ,top down simple head为keypoint_head所构建。
29.其次,对于为lite hrnet网络的backbone和neck,将shufflenet中的高效shuffle模块应用到hrnet(高分辨率网络),在本实施例中,将shuffle模块应用到lite-hrnet-18中,即在lite-hrnet-18网络的第一个卷积层后加入shuffle模块,并且将shuffle模块中的pointwise (1x1)卷积均替换为条件通道加权的轻量级单元,对lite-hrnet-18进行优化,使得lite-hrnet-18与流行的轻量级网络相比展现了更强的性能。针对shuffle模块运行过程是网络通道打乱顺序,经过1*1卷积,接着经过3*3深度可分离卷积层,再经过一个1*1卷积,最后将此1*1卷积的输出通道和最开始打乱顺序的通道拼接起来。针对条件通道加权单元即从所有通道和多个分辨率中学习权重,这些权重在hrnet的并行分支中很容易获得。它使用权重作为跨通道和跨分辨率交换信息的桥梁,补偿pointwise (1x1)卷积所起的作用,以此得到lite-hrnet,在保证准确率的同时进一步减少压缩模型减少计算量。通道加权的复杂度与通道数量成线性关系,并且低于pointwise (1x1)卷积的二次时间复杂度。进而lite-hrnet-18可以展示了优于现下流行的轻量级网络。
30.另外,针对网络的激活函数,用一个轻量级模型的工程化优化的更强的激活函数lite-hrnet主干网络使用hardswish直接替换激活函数relu。hardswish和hardmish二者的性能是接近的,但hardswish稳定性更胜一筹。所以在网络的主干网络中,选择激活函数hardswish直接替换激活函数relu。lite-hrnet网络最后输出时候的激活函数通常使用sigmoid激活函数,为了提高了训练速度,同时把sigmoid换成了一个近似实现:0.5 * (x/(1 torch.abs(x))) 0.5,x是网络上一层的输出,即激活函数上一层网络的输出;torch.abs()直接调用的一个函数求绝对值,提高了训练速度,而且还顺便解决了推理工具结果不对齐的问题。进而优化后的lite-hrnet有更低的计算量和更高的性能。
31.并且,对于该模型的损失函数,本方案基于heatmap(热力图)进行模型loss的计
算。在关键点检测任务上,常规的使用的方法是关键点坐标回归,具体实现是将网络全连接层之前的最后一层输出的一维向量,假设现在有13个关键点,那么,这个一维向量的长度就是13*(x, y, s)共39个向量,其中x,y是关键点横纵坐标,s表示此点是否可见,可见为1,不可见为0;再通过全连接层进行关键点的分类,我们知道单纯这个一维向量难以将关键点在空间中的信息进行捕捉。因此本文中采用heatmap进行关键点检测,具体实现是通过如下方式:(1)根据我们的关键点标签生成heatmap图,使用二维高斯分布,就是将原来的一个关键点现在变成一小片区域。(2)在实际训练过程中的倒数第二层的卷积层回归的是(b, c, h, w),其中,b代表batch,c代表chanel,h、w代表长宽。这里面的通道数c对应的是关键点的个数,比如关键点的个数是13,那么c就是13。(3)在训练过程进行loss计算的时候,因为我们有13(关键点个数)个通道,那么在计算loss的时候就是将对应通道的关键点序号进行l2范数计算,因为标签在生成过程中生成的是heatmap也就是一小片区域,具体计算loss(损失)时,实际上计算的是predict(预测)与labe(标签)区域点之间的距离。
32.在具体计算loss的时候,mseloss计算的是预测出的点与gt点(真实点)之间的距离,但是这有一个弊端,随着网络的不断训练,对于那些不可见的点会逐渐弱化,为了避免这一现象,根据训练损失来明确地在线选择难例关键点,并仅从所选关键点反向传播梯度,该方法就是对mse输出的结果进行了排序,并基于排序筛选其中预设各难例部分进行重点回归。均方误差(mean square error,mse)是回归损失函数中最常用的误差,它是预测值f(x)与目标值y之间差值平方和的均值,mse的函数曲线光滑、连续,处处可导,便于使用梯度下降算法更新网络参数,是一种常用的损失函数。而且,随着误差的减小,梯度也在减小,这有利于收敛,即使使用固定的学习速率,也能较快的收敛到最小值。即本网络模型基于梯度下降结合反向传播进行网络训练,梯度下降基于梯度更新网络参数,最小化目标函数,从而训练网络,反向传播则是用于计算梯度的,基于误差(目标函数)层层反传。本实施例中损失函数如下所示:其中,y是实际标注的标签值,为网络输出,取决于使用的网络结构。
33.所述关键点识别模型通过coco数据集和历史机动车驾驶人科目三考试车内的图片数据集,即驾考中心数据集,基于人体各预设关键点作为数据集标签进行预训练,即对于上述两个数据集,提取标注信息中的人体关键点信息,并统一处理为coco person_keypoints格式,合并为一个数据集;按照9:1的比例,将上述两个数据集进行统一处理融合后的数据集划分为训练集、测试集;本方案中,所述lite-hrnet在预训练完成之后需要针对安全员作弊行为数据集进行针对性训练,提高对于科目三驾考场景中具有安全员作弊行为的人体关键点识别精度;因此再基于包含安全员违规作弊行为科目三车内图片数据集作为正样本集,不包含安全员违规作弊行为科目三车内图片数据集作为负样本集进行针对性训练获得;针对各数据集采用数据翻转与数据裁剪进行数据扩充,并将各数据归一化为(-0.5, 0.5)。对于top-down方法的姿态估计,由于目标检测的关系,姿态估计的对象大都会在图像的中央,用(-0.5, 0.5)的归一化会比(0, 1)的归一化更快收敛。
34.如图2所示,根据所得关键点识别模型,对实时采集的视频以图片流的形式经过人体目标识别模型处理获得的帧图片以图片流的形式,连同获得人体所处矩形包围框信息作
为输入,通过已经完成预先训练的lite hrnet网络模型进行预测,进行人体关键点识别,获得安全员人体的各预设关键点,即可获得各关键点位置坐标信息。
35.本实施例中除了使用清洗后的coco数据集,也从历史机动车驾驶人科目三考试车内的视频然后生成图片和标注,图片数据集进行预训练,再基于包含安全员违规作弊行为科目三车内图片数据集作为正样本集,不包含安全员违规作弊行为科目三车内图片数据集作为负样本集进行针对性训练获得。因为原始coco、历史机动车驾驶员考试科目之类的图片,还是缺少一些作弊的特殊的姿态的,这就会造成数据不平衡(类似人脸关键的中的张嘴闭眼),于是除了扩充一些数据标注,还可以考虑代码中加入数据平衡手段,如分层k-fold、欠采样减少分类中多数类样本的样本数量实现样本均衡、过采样增加分类中少数样本的数量来现样本均衡等等;并且,本实施例中,针对各数据集采用数据翻转与数据裁剪进行数据扩充,常见数据翻转为简单的镜像翻转,由于本方案是进行目标检测,所以本方案中目标检测中要把目标框的横坐标同样翻转,对关键点横坐标翻转之后,还要修改对应关键点的顺序,比如左手腕的图片水平镜像翻转后,它就不再是左手腕而变成右手腕了;另外数据裁剪采用随机裁剪crop增大目标范围;进而增加训练的数据量,提高训练样本质量,提高模型的泛化能力与鲁棒性。本方案的所有数据集包含的数据量根据需求自行设定,针对人体目标识别模型的数据集进行同样的数据扩充操作。如图3所示,所述各预设关键点包括人体鼻子、左肩、右肩、左肘、右肘、左腕、右腕、左胯、右胯、左膝、右膝、左脚、右脚。在关键点识别过程中,不存在的点的坐标值赋为0,这样便得到各预设关键点的坐标。
36.步骤c:基于关键点识别模型输出的安全员人体的各预设关键点,进行安全员行为识别,进而判断科目三车内的安全员是否存在预设各类型的违规作弊行为,本方案中的夹角角度可以基于关键点识别模块获得安全员人体的各预设关键点位置信息获得;或者基于肘部关键点作为原点建立新的坐标系,进而获得本方案中的夹角角度。
37.所述步骤c中,基于关键点识别模型输出的安全员人体的各预设关键点,提取安全员的左肩、右肩、左肘、右肘、左腕、右腕、六个关键点,执行以下步骤,进行安全员行为识别,进而判断科目三车内的安全员是否存在预设各类型的违规作弊行为:步骤c1:针对安全员右肩、右肘、右腕的三个关键点,基于右肩关键点到右肘关键点构成的线段和右腕关键点到右肘关键点构成的线段,以右肘关键点为顶点两线段构成的夹角,当该夹角处于预设范围角度,并且右腕关键点在车窗区域内,便判断安全员手伸出窗外,则判定安全员存在违规行为;具体为:基于右肩关键点到右肘关键点构成的线段和右腕关键点到右肘关键点构成的线段,以右肘关键点为顶点两线段构成的夹角,当该夹角大于45
°
且小于135
°
这样的预设范围角度,并且右腕关键点在车窗区域内,便判断安全员手伸出窗外,则判定安全员存在违规行为。
38.步骤c2:针对安全员左肩、左肘以及左腕的三个关键点,基于左肩关键点到左肘关键点构成的线段和左腕关键点到左肘关键点构成的线段,以左肘关键点为顶点两线段构成的夹角,当该夹角处于预设范围角度,并且左腕关键点在档位区域或手刹区域,判定安全员存在作弊行为;具体为:基于左肩关键点到左肘关键点构成的线段和左腕关键点到左肘关键点构成的线段,以左肘关键点为顶点两线段构成的夹角,当该夹角处于大于135
°
且小于等于180
°
这样的预设范围角度,并且左腕关键点在档位区域或手刹区域,判定安全员存在作弊行为。安全员手摸挡位或者手摸手刹,协助考生的作弊行为。
39.步骤c3:针对方向盘区域,若左腕或右腕关键点在方向盘区域内,判定安全员存在作弊行为。判定安全员摸方向盘,协助考生。
40.如图1所示,一种基于人体骨架的科目三安全员作弊行为检测系统,应用于所述基于人体骨架的科目三安全员作弊行为检测方法,包括数据采集模块、人体目标识别模块、关键点识别模块、行为识别模块;数据采集模块用于采集机动车驾驶人科目三考试车内的视频影像;人体目标识别模块基于采集的科目三车内的视频影像,对视频影像中帧图片进行识别,获得帧图片中安全员对应的人体矩形框;关键点识别模块基于人体目标识别模型输出的安全员对应的人体矩形框,对安全员对应的人体矩形框进行识别,获得安全员人体的各预设关键点;行为识别模块基于关键点识别模型输出的安全员人体的各预设关键点,进行安全员行为识别,进而判断科目三车内的安全员是否存在预设各类型的违规作弊行为。
41.一种基于人体骨架的科目三安全员作弊行为检测终端,包括存储器和处理器,所述存储器和所述处理器之间互相通信连接,所述存储器中存储有计算机指令,所述处理器通过执行所述计算机指令,从而执行所述基于人体骨架的科目三安全员作弊行为检测方法。
42.本发明设计了基于人体骨架的科目三安全员作弊行为检测方法及系统,结合了目标识别、人体关键点提取、行为识别等技术,并在此技术上进行优化提升,人体关键点提取的数据处理方法,以及网络结构中的将relu激活函数替换为更强的hardwish激活函数,同时把sigmoid换成了一个近似实现的函数,以解决推理不对齐的问题;在损失函数上,对mse输出的结果进行了排序,并筛选其中难例部分进行重点回归。在后处理部分,通过二维处理判断来解决三维的问题。为安全监管人员提供了一种具有实时性的安全员作弊行为检测的方式;并且本发明无须使用人体深度信息摄像头来获取人体关键点信息,通过深度学习的方式,仅通过传统rgb视频影像即可获得可信的人体关键点信息并进行不安全行为的识别,能够简单快速的于现有的监控设备相结合;本发明拥有多种检测识别,在应对安全生产场所复杂多变的环境时,仍然具有较高的识别精度和较快的识别速度。
43.以上仅为本发明的较佳实施例,但并不限制本发明的专利范围,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来而言,其依然可以对前述各具体实施方式所记载的技术方案进行修改,或者对其中部分技术特征进行等效替换。凡是利用本发明说明书及附图内容所做的等效结构,直接或间接运用在其他相关的技术领域,均同理在本发明专利保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
