一种pet/ct影像识别方法及装置
技术领域
1.本技术涉及计算机辅助医学技术领域,尤其涉及一种pet/ct影像识别方法及装置。
背景技术:
2.肺癌是当今世界上对人类危害最为严重的疾病之一,对于肺癌的可靠诊断和早期预防是当下十分重要的研究课题。肺结节作为肺癌最为重要的早期症状,对肺结节的良恶性分类成为了早期预防肺癌的重要措施。因此,如何对肺结节进行可靠分类成为肺癌早期诊断了的研究热点。
3.医学影像技术作为以非入侵方式捕获并呈现机体形态结构和功能状态改变的影像手段,不同于传统医学图像只提供结构成像或功能成像,pet/ct作为一种融合显像,可同时显像肺结节形态及功能状态的改变,对于肺癌的早期诊断提供了有力的依据。
4.目前面向肺结节的计算机辅助诊断技术(computer aided diagnosis,cad)已经取得了不错的效果。但现存方法主要针对ct影像,主要通过肺结节的人工标注、特征提取,并构建分类网络进行识别。然而,前期标注工作不仅依赖人工,而且由于每位人工标注的主观性不同,可能导致不同程度的误差。同时,由于目标组织与周围组织的结构、密度相似,其本身的异质性导致了分类模型的高灵敏度和低特异度。
技术实现要素:
5.本技术提供了一种pet/ct影像识别方法及装置,以解决由于目标组织与周围组织的结构、密度相似,其本身的异质性导致了分类模型的高灵敏度和低特异度的问题。
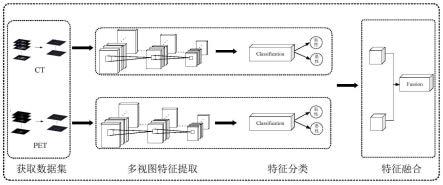
6.第一方面,本技术提供一种pet/ct影像识别方法,包括:通过pet/ct原始影像进行目标实质提取,得到ct数据集和pet数据集;将ct数据集和pet数据集分别输入到双视图深度学习分类器进行特征提取和特征分类,得到ct特征分类和pet特征分类;所述双视图深度学习分类器使用mvpd-net模型;基于投票的识别机制,对所述ct特征分类和pet特征分类进行融合,得到最终识别结果。
7.可选的,所述通过pet/ct原始影像进行处理,得到ct数据集和pet数据集的步骤包括:获取去噪后的ct图像;对去噪后的ct图像进行重采样处理,得到重采样后的ct图像;对重采样后的ct图像进行基于k-means聚类算法的阈值分割,得到k-means的分割阈值;对重采样后的ct图像进行基于otsu算法的阈值分割,得到otsu的分割阈值;取k-means的分割阈值和otsu的分割阈值的均值作为目标实质分割阈值;利用所述目标实质分割阈值对ct原始影像进行形态学变换,得到ct目标实质掩膜mask;利用所述ct目标实质掩膜mask对ct原始影像进行目标实质提取,得到ct数据集;将所述ct目标实质掩膜mask按照ct分辨率与pet分辨率的比值进行尺寸缩放,得到pet目标实质掩膜mask;利用所述pet目标实质掩膜mask对pet原始影像进行目标实质提取,得到pet数据集。
8.可选的,所述获取去噪后的ct图像的步骤包括:对ct原始影像进行数据清洗,得到
清洗后的ct图像;所述数据清洗为将存在信息缺失、结果不明确和过期的数据进行筛选去除;对所述清洗后的ct图像进行数据降噪,得到去噪后的ct图像;所述数据降噪为基于滤波窗口为3
×
3的中值滤波方法对清洗后的ct图像进行去噪。
9.可选的,所述对去噪后的ct图像进行重采样处理,得到重采样后的ct图像的步骤包括:利用转换公式将去噪后的ct图像的像素值转换为ct值,得到重采样后的ct图像;
10.所述转换公式为
11.hu=pixel_val
×
rescale_slope rescale_intercept
12.其中,pixel_val为去噪后的ct图像的像素值,rescale_slope和rescale_intercept为斜率和截距。
13.可选的,所述对重采样后的ct图像进行基于k-means聚类算法的阈值分割,得到k-means的分割阈值的步骤包括:对重采样后的ct图像随机选取k为2个数据作为初始聚类中心;计算剩余数据距离初始聚类中心的欧氏距离,按照最近原则分类,生成簇;计算每个簇中心的平均值作为新的聚类中心;如果聚类中心发生改变,或者,迭代次数达到阈值,则得到聚类结果,并对聚类结果求均值作为k-means的分割阈值。
14.可选的,所述对重采样后的ct图像进行基于otsu算法的阈值分割,得到otsu的分割阈值的步骤包括:对重采样后的ct图像计算灰度图像的全局期望;遍历灰度值,将灰度图像分为前景与背景;计算前景和背景的期望与概率;当阈值的间类方差为最大时,得到阈值作为otsu的分割阈值。
15.可选的,所述利用所述目标实质分割阈值对ct原始影像进行形态学变换,得到ct目标实质掩膜mask的步骤包括:利用所述目标实质分割阈值对ct原始影像进行二值化处理,得到第一图像;对第一图像进行核为3
×
3和8
×
8的腐蚀、膨胀操作,得到第二图像;对第二图像进行核为25
×
25的闭操作,得到ct目标实质掩膜mask。
16.可选的,所述mvpd-net模型包括:
17.特征提取子网络包括:ct特征提取器和pet特征提取器,用于分别对ct数据集和pet数据集进行特征提取;所述ct特征提取器和pet特征提取器均由3d卷积层和3d池化层进行组合构建;所述ct特征提取器的3d卷积层包括卷积核为7
×7×
7,卷积核个数为64;所述ct特征提取器的3d池化层为1
×3×
3;所述ct特征提取器通过5个特征提取块的堆叠进行高维特征提取;所述pet特征提取器的3d卷积层包括卷积核为3
×3×
4,卷积核个数为64;所述pet特征提取器的3d池化层为1
×3×
3;所述pet特征提取器通过4个特征提取块的堆叠进行高维特征提取;
18.特征分类子网络,用于对于特征提取器得到的ct特征和pet特征,进行特征分类;所述特征分类子网络包括:进行特征向量扁平化;通过2层全连接层进行特征分类;基于softmax激活函数得到分类结果。
19.可选的,所述投票的识别机制包括:
20.yv=max(y
(v)
)
21.其中,y
(v)
代表不同视图通道的识别结果,yv代表不同视图通道投票后的结果。
22.第二方面,本技术还提供一种pet/ct影像识别装置,包括:控制器,用于执行第一方面所述的pet/ct影像识别方法。
23.本技术提供了一种pet/ct影像识别方法及装置,所述影像识别方法包括:通过
pet/ct原始影像进行目标实质提取,得到ct数据集和pet数据集;将ct数据集和pet数据集分别输入到双视图深度学习分类器进行特征提取和特征分类,得到ct特征分类和pet特征分类;所述双视图深度学习分类器使用mvpd-net模型;基于投票的识别机制,对所述ct特征分类和pet特征分类进行融合,得到最终识别结果。本技术提出mvpd-net模型,是基于多视图3d卷积神经网络的pet/ct影像的分类模型,可以更可靠的进行pet/ct影像识别,也更加具备可解释性。取k-means的分割阈值和otsu的分割阈值的均值作为目标实质分割阈值进行目标实质提取,解决了由于目标组织与周围组织的结构、密度相似,其本身的异质性导致了分类模型的高灵敏度和低特异度的问题。
附图说明
24.为了更清楚地说明本技术的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
25.图1为本技术所述的一种pet/ct影像识别方法的流程示意图;
26.图2为本技术所述通过pet/ct原始影像进行处理,得到ct数据集和pet数据集的流程示意图;
27.图3为本技术所述对重采样后的ct图像进行基于k-means聚类算法的阈值分割,得到k-means的分割阈值的流程示意图;
28.图4为本技术所述对重采样后的ct图像进行基于otsu算法的阈值分割,得到otsu的分割阈值的流程示意图;
29.图5为本技术所述利用所述目标实质分割阈值对ct原始影像进行形态学变换,得到ct目标实质掩膜mask的流程示意图;
30.图6为本技术所述mvpd-net模型的结构框架图。
具体实施方式
31.下面将详细地对实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下实施例中描述的实施方式并不代表与本技术相一致的所有实施方式。仅是与权利要求书中所详述的、本技术的一些方面相一致的系统和方法的示例。
32.pet全称为正电子发射型计算机断层显像(positron emission computed tomography),是核医学领域比较先进的临床检查影像技术。ct(computed tomography,电子计算机断层扫描)是利用精确准直的x线束、γ射线、超声波等,与灵敏度极高的探测器一同围绕人体的某一部位作一个接一个的断面扫描,具有扫描时间快,图像清晰等特点,可用于多种疾病的检查。pet/ct是将pet与ct融为一体,由pet提供病灶详尽的功能与代谢等分子信息,而ct提供病灶的精确解剖定位,一次显像可获得全身各方位的断层图像,具有灵敏、准确、特异及定位精确等特点。
33.借助计算机辅助诊断技术(computer aided diagnosis,cad),对ct影像数据进行自动分析,进而提高处理效率。在一些实施例中,针对ct影像,通过人工标注、特征提取,并构建分类网络进行识别。然而,前期标注工作不仅依赖人工,而且由于每位人工标注的主观
性不同,可能导致不同程度的误差。同时,由于目标组织与周围组织的结构、密度相似,其本身的异质性导致了分类模型的高灵敏度和低特异度。
34.为了解决上述问题,本技术提供一种pet/ct影像识别方法,如图1所示,包括:
35.s100:通过pet/ct原始影像进行目标实质提取,得到ct数据集和pet数据集。
36.传统的标注只关注对病灶位置的提取,例如:对肺结节的位置提取,但是由于肺结节与周围组织的结构、密度相似,其本身的异质性导致了分类模型的高灵敏度和低特异度。为了克服上述的缺点,采用目标实质提取,目标实质提取是指从整个pet/ct图像中去除无关区域,将完整的目标区域提取出来,例如:肺实质提取就是将整个肺部区域完整的提取出来,精准分割肺实质可以有效的提高模型对肺结节的判断准确度。
37.在一种示意性的实施方式中,如图2所示,所述通过pet/ct原始影像进行处理,得到ct数据集和pet数据集的步骤包括:
38.s110:获取去噪后的ct图像,包括:
39.对ct原始影像进行数据清洗,得到清洗后的ct图像;所述数据清洗为将存在信息缺失、结果不明确和过期的数据进行筛选去除。ct原始影像数据中存在一些信息缺失、结果不明确和过期的数据,需要将这些数据筛选去除,使清洗后的ct图像均为有效的数据。示例的,经数据收集,共获得实验数据3145条,清洗后共得到1881条有效数据。
40.对所述清洗后的ct图像进行数据降噪,得到去噪后的ct图像;所述数据降噪为基于滤波窗口为3
×
3的中值滤波方法对清洗后的ct图像进行去噪。由于在计算机断层扫描人体进行成像过程中会受到多种因素干扰,导致ct图像出现噪声,比如操作不规范、图像重建算法限制等,使用基于滤波窗口为3
×
3的中值滤波方法对清洗后的ct图像进行去噪,可以使得到的ct图像更加清晰。
41.s120:对去噪后的ct图像进行重采样处理,得到重采样后的ct图像,包括:
42.利用转换公式(1)将去噪后的ct图像的像素值转换为ct值,称亨氏单位(hounsfield unit,hu),得到重采样后的ct图像。
43.所述转换公式(1)为
44.hu=pixel_val
×
rescale_slope rescale_intercept
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
45.其中,pixel_val为去噪后的ct图像的像素值,rescale_slope和rescale_intercept为斜率和截距。
46.s130:对重采样后的ct图像进行基于k-means聚类算法的阈值分割,得到k-means的分割阈值。
47.k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为k组,则随机选取k个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。
48.在一种示意性的实施方式中,如图3所示,所述对重采样后的ct图像进行基于k-means聚类算法的阈值分割,得到k-means的分割阈值的步骤包括:
49.s131:对重采样后的ct图像随机选取k为2个数据作为初始聚类中心。因为otsu算法是二值化算法,选取k为2个数据,是为了与otsu算法配合。
50.s132:计算剩余数据距离初始聚类中心的欧氏距离,按照最近原则分类,生成簇。
51.s133:计算每个簇中心的平均值作为新的聚类中心。
52.s134:如果聚类中心发生改变,或者,迭代次数达到阈值,则得到聚类结果,并对聚类结果求均值作为k-means的分割阈值。
53.如果聚类中心没有发生改变,并且,迭代次数没有达到阈值,则跳到步骤s132重复执行,直到满足条件。
54.使用k-means聚类算法,算法思想简单,收敛速度快,聚类效果较优,算法的可解释度比较强。
55.s140:对重采样后的ct图像进行基于otsu算法的阈值分割,得到otsu的分割阈值。
56.otsu算法(大律法或最大类间方差法)是一种图像二值化算法。其算法假设图像中存在一个阈值t,判断图像中每个像素与t的大小关系,可以将所有像素分为背景c0和前景c1两类,且当选取到最佳t阈值时,背景部分与前景部分的差别最大,而otsu算法利用最大类间方差来衡量这一差别,由于otsu算法采用了最大类间方法的思想,因此该算法也被称为otsu最大类间方差法。
57.在一种示意性的实施方式中,如图4所示,所述对重采样后的ct图像进行基于otsu算法的阈值分割,得到otsu的分割阈值的步骤包括:
58.s141:对重采样后的ct图像计算灰度图像的全局期望;
59.s142:遍历灰度值,将灰度图像分为前景与背景;
60.s143:计算前景和背景的期望与概率;
61.s144:当阈值的间类方差为最大时,得到阈值作为otsu的分割阈值。
62.s150:取k-means的分割阈值和otsu的分割阈值的均值作为目标实质分割阈值。
63.单独使用otsu算法,对图像噪声敏感,只能针对单一目标分割;当目标和背景大小比例悬殊、类间方差函数可能呈现双峰或者多峰,这个时候效果不好。而单独使用k-means聚类算法,聚类结果往往收敛于局部最优而得不到全局最优解,对非凸形状的类簇识别效果差,易受噪声、边缘点、孤立点影响。为了克服上述的缺点,对获得的k-means的分割阈值和otsu的分割阈值进行平均处理,得到最终目标实质分割阈值,这样可以提高模型识别的准确率。
64.s160:利用所述目标实质分割阈值对ct原始影像进行形态学变换,得到ct目标实质掩膜mask,如图5所示,包括:
65.s161:利用所述目标实质分割阈值对ct原始影像进行二值化处理,得到第一图像。
66.s162:对第一图像进行核为3
×
3和8
×
8的腐蚀、膨胀操作,得到第二图像。进行核为3
×
3和8
×
8的腐蚀、膨胀操作,可去除肺实质内外的空洞部分。
67.s163:对第二图像进行核为25
×
25的闭操作,得到ct目标实质掩膜mask。考虑到结节在肺边界的粘连情况与结节纳入标准(结节直径小于3cm),采用核为25
×
25的闭操作,进行边界补齐可较好的解决大结节在肺边界的粘连情况。
68.s170:利用所述ct目标实质掩膜mask对ct原始影像进行目标实质提取,得到ct数据集。示例的,对1881条有效的ct原始影像进行目标实质提取,得到包括1881条数据的ct数据集。
69.s180:将所述ct目标实质掩膜mask按照ct分辨率与pet分辨率的比值进行尺寸缩
放,得到pet目标实质掩膜mask。示例的,ct分辨率为512
×
512,pet分辨率为128
×
128,则是将512
×
512的ct目标实质掩膜mask缩放到128
×
128,基于三次样插值,对512
×
512的ct目标实质掩膜mask进行resize,得到pet目标实质掩膜mask。
70.s190:利用所述pet目标实质掩膜mask对pet原始影像进行目标实质提取,得到pet数据集。示例的,对1881条有效的pet原始影像进行目标实质提取,得到包括1881条数据的pet数据集。
71.s200:将ct数据集和pet数据集分别输入到双视图深度学习分类器进行特征提取和特征分类,得到ct特征分类和pet特征分类;所述双视图深度学习分类器使用mvpd-net(multi-view pulmonary nodules net,多视图肺结节网络)模型。所述mvpd-net模型,是基于多视图3d卷积神经网络的pet/ct影像的分类模型。
72.一个卷积神经网络主要由以下5种结构组成:
73.输入层,输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵。从输入层开始卷积神经网络通过不同的神经网络结构将生一层的三维矩阵转化为下一层的三维矩阵,直到最后的全连接层。
74.卷积层,是一个卷积神经网络中最重要的部分。和传统全连接层不同,卷积层中每一个节点的输入只是上一层神经网络的一小块,即感受野,卷积核常用的大小有3
×
3或者5
×
5。卷积层试图将神经网络中的每一小块进行更加深入地分析从而得到抽象程序更高的特征。一般来说,通过卷积层处理过的节点矩阵会变得更深,所以经过卷积层之后的节点矩阵的深度会增加。
75.池化层(pooling),池化层神经网络不会改变三维矩阵的深度,但是它可以缩小矩阵的大小,减少模型运算量。池化层操作可以认为是将一张分辨率较高的图片转化为分辨率较高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数。从而达到减少整个神经网络中参数的目的。
76.全连接层,在经过多轮卷积层和池化层的处理之后,在卷积神经网络的最后一般会是由数个全连接层进行特征分类并给出最后的分类结果。经过几轮卷积层和池化层之后,可以认为图像中的信息已经被抽象成了信息含量更高的特征。可以将卷积层和池化层看成自动图像特征提取的过程。在特征提取完成之后,仍然需要使用全连接层来完成分类任务。
77.softmax激活函数,主要用于分类问题。通过softmax激活函数可以得到当前样例属于不同种类的概率分布情况。
78.在一种示意性的实施方式中,如图6所示,所述mvpd-net模型包括:
79.特征提取子网络包括:ct特征提取器和pet特征提取器,用于分别对ct数据集和pet数据集进行特征提取;所述ct特征提取器和pet特征提取器均由3d卷积层和3d池化层进行组合构建;所述ct特征提取器的3d卷积层包括卷积核为7
×7×
7,卷积核个数为64;所述ct特征提取器的3d池化层为1
×3×
3;所述ct特征提取器通过5个特征提取块的堆叠(详见表1中ct-view列conv2,conv3,conv4,conv5,conv6)进行高维特征提取;所述pet特征提取器的3d卷积层包括卷积核为3
×3×
4,卷积核个数为64;所述pet特征提取器的3d池化层为1
×3×
3;所述pet特征提取器通过4个特征提取块的堆叠(详见表1中pet-view列conv2,conv3,conv4,conv5)进行高维特征提取。
80.特征分类子网络,用于对于特征提取器得到的ct特征和pet特征,进行特征分类;所述特征分类子网络包括:进行特征向量扁平化;通过2层全连接层进行特征分类;基于softmax激活函数得到分类结果。要识别出的特征是两种类型,例如:良性或者恶性,将特征分类为两种类型。
81.表1 mvpd-net参数设置
[0082][0083][0084]
s300:基于投票的识别机制,对所述ct特征分类和pet特征分类进行融合,得到最终识别结果。
[0085]
在一种示意性的实施方式中,所述投票的识别机制包括:
[0086]yv
=max(y
(v)
)
ꢀꢀꢀꢀꢀꢀ
(2)
[0087]
其中,y
(v)
代表不同视图通道的识别结果,yv代表不同视图通道投票后的结果。
[0088]
对pet和ct获得到的识别结果,进行投票,使用公式(2)以最大概率值作为模型的最终结果并输出。
[0089]
由于深度学习模型黑盒特点的限制,深度学习的可解释性始终作为众多研究的热点问题,尤其在医学图像处理领域,模型可解释性的缺乏限制了临床医生对此类方法的信任。鉴于此,本技术基于注意力机制及pet影像的进行模型的可解释性分析。具体而言,注意力机制可使模型更加关注具备分类特点的感受野,其中权重的高低与对应位置信息的重要程度正相关,也即高权重的输入单元对于输出结果有决定性作用。并基于此实现模型内部可解释性分析,同时考虑到pet影像为功能成像,其异常高亮区域为恶性结节多发区域。因此,结合注意力机制及pet影像,可从模型内部及其功能成像进行可解释性分析。
[0090]
基于上述实施例提供的一种pet/ct影像识别方法,本技术的部分实施例还提供一种pet/ct影像识别装置,包括:控制器,用于执行上述实施例提供的pet/ct影像识别方法。
[0091]
所述控制器可以是电脑、服务器、工控机、单片机、plc(programmable logic controller,可编程逻辑控制器)、dsp(digital signal processor,数字信号处理器)、fpga(field programmable gate array,场可编程逻辑门阵列)、asic(application-specific integrated circuit,专用集成电路)等具有存储和运算功能的设备,本技术实施例对此不做限制。
[0092]
本技术提供了一种pet/ct影像识别方法及装置,所述影像识别方法包括:通过pet/ct原始影像进行目标实质提取,得到ct数据集和pet数据集;将ct数据集和pet数据集分别输入到双视图深度学习分类器进行特征提取和特征分类,得到ct特征分类和pet特征分类;所述双视图深度学习分类器使用mvpd-net模型;基于投票的识别机制,对所述ct特征分类和pet特征分类进行融合,得到最终识别结果。本技术提出mvpd-net模型,是基于多视图3d卷积神经网络的pet/ct影像的分类模型,可以更可靠的进行pet/ct影像识别,也更加具备可解释性。取k-means的分割阈值和otsu的分割阈值的均值作为目标实质分割阈值进行目标实质提取,解决了由于目标组织与周围组织的结构、密度相似,其本身的异质性导致了分类模型的高灵敏度和低特异度的问题。
[0093]
本技术提供的实施例之间的相似部分相互参见即可,以上提供的具体实施方式只是本技术总的构思下的几个示例,并不构成本技术保护范围的限定。对于本领域的技术人员而言,在不付出创造性劳动的前提下依据本技术方案所扩展出的任何其他实施方式都属于本技术的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
