1.本发明涉及缺陷检测领域,更具体地,涉及一种柔印标签的在线缺陷检测方 法。
背景技术:
2.柔性印刷是指使用柔性版通过网纹辊传递油墨的印刷方式。印刷时网纹辊将 一定厚度的油墨层均匀地涂布在印版图文部分,然后在压印滚简压力的作用下, 将图文部分的油墨层转移到承印物的表面,形成清晰的图文。柔版印刷以其印刷 质量好、适用性广、生产率高、可控性好等优点被广泛应用于日用品的包装、标 签和装潢。无毒油墨柔版印刷已成为标签印刷的主流选择,尤其是在面料和服装 行业。
3.柔印印刷过程由于机器故障,油墨故障,环境污染物干扰,不可避免地产生 缺陷,如不被及时发现将会导致批量产品出错,造成原材料批量浪费和人工浪费。 柔印标签上的语言涉及世界各地语言(超过5000多种文字),且印刷内容多,平 均每张单超过200多个字符。采用人工检测抽检方式,效率低,并且容易漏检, 仍旧存在批量印刷错误风险。因此引入柔印在线检测系统对柔性印刷至关重要。
4.区别于使用pdf模板的柔印首件检测,柔印印刷过程由于衬底的材质厚薄, 疏密成度不一导致印刷受力不均,无缺陷样品的内容也会发生不同程度的形变, 如印粗、扭曲等,所以在线检测过程中没有标准的模板,因此若使用标准模板检 测方法容易引发大批量误检。柔印印刷速度非常快,单张柔印标签生产时间仅需 30ms,对自动检测系统的检测速度要求极高。若使用ncc局部匹配等耗时较长的 方法校正样品,难以满足检测速度需求。对于双面印刷的柔印标签,材质较薄的 衬底会导致透底现象产生,大大增加了标签内容和结构的复杂度,导致检测难度 增加。
5.现有技术中已公开了一种基于电子样稿的柔印首件检测方法,该方法采用
ꢀ“
粗-精”匹配方法避免了单独使用全局匹配算法在匹配弱纹理或者重复纹理的 区域时表现不佳的问题;粗匹配融合superpoint与gnn方法,由于注意力机制 参照人比对两幅图像的思想,聚合自注意力与交叉注意力,使得匹配精度远超暴 力匹配和快速最近邻搜索算法;精匹配完成了局部区域内容的微调,实现电子样 稿与柔印首件两者的完全匹配,进而实现像素级的检测精度;将电子样稿分割结 果作为约束条件的聚类算法,将柔印首件分割问题转换为与电子样稿二值图差异 最小的优化问题,并采用遗传算法加速求解优化算法的时间,实现了首件图像的 有效分割,提高了算法的速率与精度。然而,该专利没有涉及任何有关柔印过程 中因版材伸缩、弯曲引发柔印内容偏移而可能导致错检的问题。
技术实现要素:
6.本发明提供一种柔印标签的在线缺陷检测方法,该方法可解决柔印过程中因 版材伸缩、弯曲引发柔印内容偏移而可能导致错检的问题。
7.为了达到上述技术效果,本发明的技术方案如下:
8.一种柔印标签的在线缺陷检测方法,包括以下步骤:
9.s1:空间变换网络stn匹配对齐:通过空间变换网络获取样本与柔印模板 之间的匹配参数,完成对训练样本以及测试样本的匹配对齐;
10.s2:无监督缺陷检测:构建核心集,并且通过改进的k近邻算法得到测试 样品的异常得分;
11.s3:弱监督缺陷检测:使用无监督缺陷检测的图像级分类结果作为标签,通 过完成对热图的分割,实现柔印在线检测。
12.进一步地,所述步骤s1中,通过端到端的空间变换网络能快速地实现训练 样本、测试样本对模板的匹配对齐,空间变换网络由localisation net,gridgenerator,sampler三部分组成,在训练过程中,将测试样本向模板进行校正, 将损失函数设为l1 loss和ssim loss,在测试过程中,测试样本输入网络后即可 实现端到端的校正。
13.进一步地,所述步骤s2中,通过构造核心集的方法来避免直接做差,综合 多个无缺陷样本的特征,提高检测鲁棒性,使用空间变换网络匹配校正后的无缺 陷样本构成训练集,通过预训练的resnet网络提取训练集特征,然后通过贪婪算 法对训练集特征关键点进行筛选,对特征集实现降维;使用faiss构建量化器 quantizer计算特征间的欧氏距离即相似度,构建indexivfflat类型的索引,将簇 心设为2400,对降维后的特征集进行kmeans聚类,最后将聚类中心加入到索引 中并保存索引。
14.进一步地,所述步骤s2中,通过预训练的resnet网络提取测试样本的特征, 加载保存好的索引,通过索引搜索最近的簇,然后在簇内应用k近邻算法,寻 找到邻近点;通过k近邻算法来衡量异常得分,并将异常分数图resize到输入尺 寸大小,从而实现无监督异常检测。
15.进一步地,所述步骤s3中,通过u-net架构提取样本特征,引入压缩和激 励网络senet,通道和空间注意力模块抑制复杂背景的干扰,增强有用特征的表 示;由于二元交叉熵函数不仅收敛快,而且在整批累积每像素的损失,因此使用 二元交叉熵值作为损失函数,损失函数的输入为分类器的输出结果以及无监督缺 陷检测的图像级分类结果,以热图像素的平均值和标准差组合构成分割的阈值, 完成对热图的分割。
16.进一步地,所述localizion net用于获取位置参数,localizion net通过四个 convbnrelu block以及两个conv2d层提取图片特征,获得32*32的特征图u, 然后将特征图reshape为1*1024后输入线性层,最后得到1*6的位置参数θ并将 其reshape为2*3;
17.grid generator利用θ对特征图u进行相应的空间变换,得到输出特征图将 位置参数θ输入grid generator获取特征图u,的映射关系,设u的坐标为设u的坐标为的像素位置为则映射关系为:
[0018][0019]
也就是说,对于的每一个位置,对其进行空间变换即仿射变换寻找其对应与 u的空间位置;
[0020]
经过以上的两步操作后,上每一个像素点都会通过空间变换对应到u的某 个像素位置,但是由于feature score对于feature position的偏导数无法计算,因而我 们需
要构造一种position到score的映射;该映射具有可导的性质,从而满足反向 传播的条件。
[0021]
进一步地,空间变换网络使用的损失函数为l1 loss和ssim loss,设输入图 像为x,nn为空间变换网络模型匹配,校正后的输出图像为nn(x),y为模板图像, 则l1 loss为:
[0022][0023]
其中n为测试样本数,nn(x)为经过空间变换网络模型的样本,结构相似性指 数用于度量两幅图像间的结构相似性和被广泛采用的l2 loss不同,ssim和人类 的视觉系统hvs类似,对局部结构变化的感知敏感,ssim的公式如下:
[0024][0025]
其中μ
x
,μy分别为图像x和y的均值,和分别为图像x和y的方差,σ
xy
为 图像x和y的协方差,c1和c2为常数,因此ssimloss为:
[0026]
ssimloss=1-ssim(x,y)。
[0027]
进一步地,在经过空间变换网络后,柔印标签与模板图片实现对齐,由于柔 印标签的结构复杂,衬底较薄的标签双面印刷时会产生透底现象,透底图案使得 标签的图案结构复杂度大大增加,且图案结构粗细不一,因此使用单个模板与测 试样本做差的检测方法会导致较高的误检率,所以通过构造核心集的方法来避免 直接做差;
[0028]
使用多张经过校正对齐的无缺陷样本构建训练集,使用预先在imagenet上 训练的resnet网络提取训练集特征,resnet网络的第一层虽然包含大量的测试样 本的纹理特征,但同时也包含了大量的冗余信息,导致后续贪婪算法降采样的效 率降低和缺陷检测的检测时间大大增加,因此本发明使用resnet模型最后两层提 取的特征作为特征集,再通过贪婪算法对特征集关键点进行筛选,从而达到降维 的效果,将核心集降采样率设为0.01,即相对于直接提取的特征集,核心集大小 下降为原来的1%;
[0029]
使用faiss构建量化器quantizer计算特征间的欧氏距离即相似度,构建 indexivfflat类型的索引,将簇心设为2400,对降维后的特征集进行kmeans聚 类,通过查询最近的聚类中心,然后比较聚类中所有向量得到相似的向量,最后 将聚类中心加入到索引中并保存索引;
[0030]
在测试阶段,由于需要使用最邻近算法,所以必须确保测试集特征与训练集 特征的尺寸相同,因此使用预训练的resnet网络的第二第三层提取的测试样本特 征,导入保存好的索引,通过索引搜索最近的簇,然后在簇内应用k近邻算法, 根据距离度量,在核心集中找出与测试样本特征m
test
最近邻的k个点,距离度 量公式为
[0031][0032]
其中m表示核心集的特征,d表示两点之间的距离,通过k近邻算法来衡量 异常得分;
[0033]
采用re-weighting的计算方法来计算image-level的异常得分,相比于以往的 直接取最大值的判断异常方法更加鲁棒:
[0034][0035]s*
=‖m
test,*-m
*
‖2[0036][0037]
其中m
test,*
,m
*
异常候选,为了得到re-weighting后的异常分数值s,增加了 s
*
的权重来解释相邻补丁的行为:如果内存库特征最接近异常候选m
test,*
,m
*
,由 于其本身距离相邻样本相对较远,这已经是一种罕见的事件,因此增加异常分数, 最后将异常分数图resize到输入尺寸大小,完成异常检测。
[0038]
进一步地,在完成无监督缺陷检测后,能够判断测试样本是否为缺陷样本; 由于无监督缺陷检测的分割结果不精准,使用弱监督缺陷检测对测试样本进行分 割;以无监督缺陷检测的分类结果作为弱监督检测的标签;弱监督检测阶段主要 包括特征提取网络,通道和空间注意力网络,分类器和分割几个部分;
[0039]
为了增强对细微缺陷的检测能力,特征提取网络使用u-net架构提取测试样 本的特征;由于柔印标签样本结构比较复杂,所以在u-net架构中添加压缩和激 励网络,抑制复杂背景对检测的干扰,增强有用特征的表示;将提取的特征分别 通过全局平均池化层、通道和空间注意力模块,然后将得到的特征相乘得到特征 图,分别将平均池化和最大池化后的特征向量输入共享全连接层,然后将得到的 两个特征向量相加后输入sigmoid激活层,得到特征通道权重空间注意力模块将 经过最大池化和平均池化的特征向量堆叠起来,通过卷积将堆叠的特征向量变通 道数为1的特征向量,然后经过sigmoid激活层,得到特征空间权重;
[0040]
特征图输入全连接层实现分类,因为二元交叉熵函数收敛快,而且在整批累 积每像素的损失,所以将二元交叉熵作为损失函数:
[0041][0042]
其中yi为无监督缺陷检测生成的标签,p(yi)为预测概率;
[0043]
模型生成热图中的较高值对应像素属于概率较高的缺陷,通过设置阈值对热 图进行二值化,阈值公式如下:
[0044]
t=μ
±
c*σ
[0045]
其中t为阈值,μ为热图均值,c为常数,σ为热图标准差,最后分割结果由 下式给出:
[0046][0047]
其中m为热图,为二值图,为对应的像素点。
[0048]
与现有技术相比,本发明技术方案的有益效果是:
[0049]
本发明使用stn端到端网络来校正图案,避免了传统的局部匹配时间长的问 题,校正后训练样本和测试样本的结构位置都大体上保持一致,所以对于细微缺 陷的检测能力也有所提高;由于样本生产过程中的材质厚薄度和受力不一,在经 过校正后仍不可避免
的有细微差异。同时由于较薄的双面印刷的样品会有透底现 象,模板与测试样品的透底图案位置偏差较大,通过做差容易导致误检。所以通 过提取多个无缺陷样本的方法建立核心集,对比单一模板的做差方法,大大提高 了检测结果的鲁棒性,减少了误检率和透底的影响;使用无监督缺陷检测的结果 作为弱监督缺陷检测的标签。相比于人工打标签,速度和准确率都有明显的提高, 并且弱监督缺陷检测的分割结果比无监督缺陷检测更加精准。
附图说明
[0050]
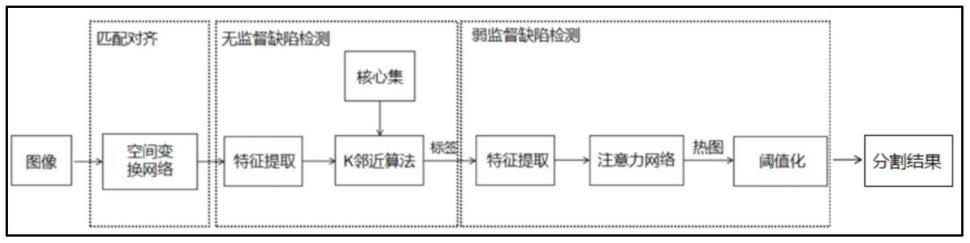
图1为本发明流程框图;
[0051]
图2为stn校正流程框图;
[0052]
图3为匹配对齐前后图片;
[0053]
图4为缺失样本无监督检测结果;
[0054]
图5为弱监督检测流程图;
[0055]
图6为通道注意力网络结构图。
具体实施方式
[0056]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0057]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实 际产品的尺寸;
[0058]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理 解的。
[0059]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0060]
实施例1
[0061]
如图1所示,一种柔印标签的在线缺陷检测方法,包括以下步骤:
[0062]
s1:空间变换网络stn匹配对齐:通过空间变换网络获取样本与柔印模板 之间的匹配参数,完成对训练样本以及测试样本的匹配对齐;
[0063]
s2:无监督缺陷检测:构建核心集,并且通过改进的k近邻算法得到测试 样品的异常得分;
[0064]
s3:弱监督缺陷检测:使用无监督缺陷检测的图像级分类结果作为标签,通 过完成对热图的分割,实现柔印在线检测。
[0065]
步骤s1中,通过端到端的空间变换网络能快速地实现训练样本、测试样本 对模板的匹配对齐,空间变换网络由localisation net,grid generator,sampler 三部分组成,在训练过程中,将测试样本向模板进行校正,将损失函数设为l1 loss 和ssim loss,在测试过程中,测试样本输入网络后即可实现端到端的校正如图 2所示,匹配对齐前后图片如图3所示。
[0066]
步骤s2中,通过构造核心集的方法来避免直接做差,综合多个无缺陷样本 的特征,提高检测鲁棒性,使用空间变换网络匹配校正后的无缺陷样本构成训练 集,通过预训练的resnet网络提取训练集特征,然后通过贪婪算法对训练集特征 关键点进行筛选,对特征集实现降维;使用faiss构建量化器quantizer计算特征 间的欧氏距离即相似度,构建indexivfflat类型的索引,将簇心设为2400,对 降维后的特征集进行kmeans聚类,最后将
indexivfflat类型的索引,将簇心设为2400,对降维后的特征集进行kmeans聚 类,通过查询最近的聚类中心,然后比较聚类中所有向量得到相似的向量,最后 将聚类中心加入到索引中并保存索引;
[0092]
在测试阶段,由于需要使用最邻近算法,所以必须确保测试集特征与训练集 特征的尺寸相同,因此使用预训练的resnet网络的第二第三层提取的测试样本特 征,导入保存好的索引,通过索引搜索最近的簇,然后在簇内应用k近邻算法, 根据距离度量,在核心集中找出与测试样本特征m
test
最近邻的k个点,距离度 量公式为
[0093][0094]
其中m表示核心集的特征,d表示两点之间的距离,通过k近邻算法来衡量 异常得分;
[0095]
采用re-weighting的计算方法来计算image-level的异常得分,相比于以往的 直接取最大值的判断异常方法更加鲁棒:
[0096][0097]s*
=‖m
test,*-m
*
‖2[0098][0099]
其中m
test,*
,m
*
异常候选,为了得到re-weighting后的异常分数值s,增加了 s
*
的权重来解释相邻补丁的行为:如果内存库特征最接近异常候选m
test,*
,m
*
,由 于其本身距离相邻样本相对较远,这已经是一种罕见的事件,因此增加异常分数, 最后将异常分数图resize到输入尺寸大小,完成异常检测。
[0100]
在完成无监督缺陷检测后,能够判断测试样本是否为缺陷样本;由于无监督 缺陷检测的分割结果不精准,使用弱监督缺陷检测对测试样本进行分割;以无监 督缺陷检测的分类结果作为弱监督检测的标签;弱监督检测阶段主要包括特征提 取网络,通道和空间注意力网络,分类器和分割几个部分;
[0101]
为了增强对细微缺陷的检测能力,特征提取网络使用u-net架构提取测试样 本的特征;由于柔印标签样本结构比较复杂,所以在u-net架构中添加压缩和激 励网络,抑制复杂背景对检测的干扰,增强有用特征的表示;将提取的特征分别 通过全局平均池化层、通道和空间注意力模块,然后将得到的特征相乘得到特征 图,通道注意力模块如图6示,分别将平均池化和最大池化后的特征向量输入共 享全连接层,然后将得到的两个特征向量相加后输入sigmoid激活层,得到特征 通道权重空间注意力模块将经过最大池化和平均池化的特征向量堆叠起来,通过 卷积将堆叠的特征向量变通道数为1的特征向量,然后经过sigmoid激活层,得 到特征空间权重;
[0102]
特征图输入全连接层实现分类,因为二元交叉熵函数收敛快,而且在整批累 积每像素的损失,所以将二元交叉熵作为损失函数:
[0103]
similarity index,ssim),用于度量两幅图像间的结构相似性。和被广 泛采用的l2 loss不同,ssim和人类的视觉系统(hvs)类似,对局部结构变化 的感知敏感。ssim的公式如下:
[0122][0123]
其中μ
x
,μy分别为图像x和y的均值,和分别为图像x和y的方差,σ
xy
为图 像x和y的协方差,c1和c2为常数。因此ssim loss为:
[0124]
ssim loss=1-ssim(x,y)
[0125]
(2)无监督缺陷检测
[0126]
在经过空间变换网络后,柔印标签与模板图片实现对齐。由于柔印标签的结 构复杂,衬底较薄的标签双面印刷时会产生透底现象,透底图案使得标签的图案 结构复杂度大大增加,且图案结构粗细不一。因此使用单个模板与测试样本做差 的检测方法会导致较高的误检率,所以通过构造核心集的方法来避免直接做差。
[0127]
使用多张经过校正对齐的无缺陷样本构建训练集,使用预先在imagenet上 训练的resnet网络提取训练集特征。resnet网络的第一层虽然包含大量的测试样 本的纹理特征,但同时也包含了大量的冗余信息,导致后续贪婪算法降采样的效 率降低和缺陷检测的检测时间大大增加,因此本发明使用resnet模型最后两层提 取的特征作为特征集。再通过贪婪算法对特征集关键点进行筛选,从而达到降维 的效果。将核心集降采样率设为0.01,即相对于直接提取的特征集,核心集大小 下降为原来的1%。
[0128]
使用faiss(facebook ai similarity search)构建量化器(quantizer)计算特 征间的欧氏距离(相似度),构建indexivfflat类型的索引。将簇心设为2400, 对降维后的特征集进行kmeans聚类,通过查询最近的聚类中心,然后比较聚类 中所有向量得到相似的向量。最后将聚类中心加入到索引中并保存索引。
[0129]
在测试阶段,由于需要使用最邻近算法,所以必须确保测试集特征与训练集 特征的尺寸相同。因此使用预训练的resnet网络的第二第三层提取的测试样本特 征。导入保存好的索引,通过索引搜索最近的簇,然后在簇内应用k近邻算法, 根据距离度量,在核心集中找出与测试样本特征m
test
最近邻的k个点,本文方 法中将k设为9。本文的距离度量公式为
[0130][0131]
其中m表示核心集的特征,d表示两点之间的距离。通过k近邻算法来衡量 异常得分。
[0132]
采用re-weighting的计算方法来计算image-level的异常得分,相比于以往的 直接取最大值的判断异常方法更加鲁棒。
[0133][0134]s*
=‖m
test,*-m
*
‖2[0135]
[0136]
其中m
test,*
,m
*
异常候选。为了得到re-weighting后的异常分数值s,增加了 s
*
的权重来解释相邻补丁的行为:如果内存库特征最接近异常候选m
test,*
,m
*
,由 于其本身距离相邻样本相对较远,这已经是一种罕见的事件,因此增加异常分数。 最后将异常分数图resize到输入尺寸大小,完成异常检测。
[0137]
(3)弱监督缺陷检测
[0138]
在完成无监督缺陷检测后,能够判断测试样本是否为缺陷样本。由于无监督 缺陷检测的分割结果不精准,使用弱监督缺陷检测对测试样本进行分割。以无监 督缺陷检测的分类结果作为弱监督检测的标签。弱监督检测阶段主要包括特征提 取网络,通道和空间注意力网络,分类器和分割几个部分。
[0139]
为了增强对细微缺陷的检测能力,特征提取网络使用u-net架构提取测试样 本的特征。由于柔印标签样本结构比较复杂,所以在u-net架构中添加压缩和激 励网络,抑制复杂背景对检测的干扰,增强有用特征的表示。将提取的特征分别 通过全局平均池化层、通道和空间注意力模块,然后将得到的特征相乘得到特征 图,通道注意力模块如图6示。分别将平均池化和最大池化后的特征向量输入共 享全连接层,然后将得到的两个特征向量相加后输入sigmoid激活层,得到特征 通道权重。
[0140]
空间注意力模块将经过最大池化和平均池化的特征向量堆叠起来,通过卷积 将堆叠的特征向量变通道数为1的特征向量,然后经过sigmoid激活层,得到特 征空间权重。
[0141]
特征图输入全连接层实现分类,因为二元交叉熵函数收敛快,而且在整批累 积每像素的损失,所以将二元交叉熵作为损失函数:
[0142][0143]
其中yi为无监督缺陷检测生成的标签,p(yi)为预测概率;
[0144]
模型生成热图中的较高值对应像素属于概率较高的缺陷,通过设置阈值对热 图进行二值化,阈值公式如下:
[0145]
t=μ
±
c*σ
[0146]
其中t为阈值,μ为热图均值,c为常数,σ为热图标准差,最后分割结果由 下式给出:
[0147][0148]
其中m为热图,为二值图,为对应的像素点。
[0149]
相同或相似的标号对应相同或相似的部件;
[0150]
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
[0151]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非 是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明 的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施 方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进 等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。