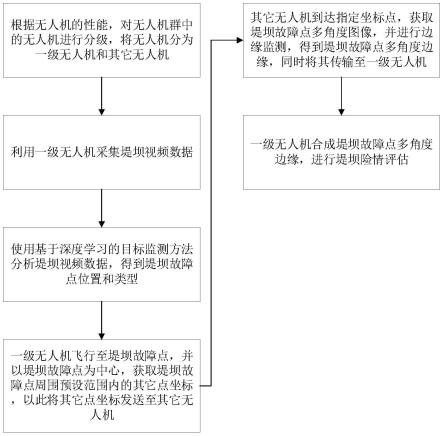
1.本发明属于无人设备自动化控制领域,涉及算法智能决策,具体提供一种搭载强化学习智能体的无人设备集群协同探索方法。
背景技术:
2.强化学习是智能决策领域的常用方法,尤其是深度强化学习结合了强化学习的决策优势与深度学习的感知优势,极大的推进了现代人工智能的发展,被誉为最可能实现通用人工智能的方法。强化学习智能体也比传统智能体具有更加强大的能力,尤其是具有较强的学习性和环境适应性,能够自主探索各类未知环境,对无人设备在野外、远海、太空等完全未知环境中的智能决策、自主运行有关键性作用。具体而言,搭载强化学习智能体的无人设备较传统无人设备有更强的决策能力,搭载强化学习智能体的无人设备集群则可以被认为是多智能体强化学习系统。
3.然而,强化学习算法要求环境提供的任务奖励不能过于稀疏,否则仍然需要人工制定奖励目标来引导智能体探索未知环境和决策最优策略。传统的强化学习智能体在未知环境中的探索上采取暴力穷举的方式,若环境任务奖励过于稀疏,智能体则需要花费大量的算力在探索奖励上,甚至可能完全无法正确的探索到任何奖励,而人工奖励塑形往往又需要较高的开销。这一问题使得强化学习智能体的训练需要耗费高昂的成本,该成本甚至无法被强化学习智能体的决策优势性所带来的收益补偿,这导致了强化学习算法在实际工业生产中难以落地。
4.现阶段的强化学习探索主要分为内在动机构建和先验知识引入两种方式,前者主要通过算法构建出除环境任务目标以外的其他奖励逻辑,如好奇心机制鼓励智能体探索从未访问过的环境区域;事后经验回放有效利用失败的探索,增强智能体的可探索范围,但单智能体领域的探索策略对多智能体系统仅部分有效,无法完全解决多智能体的协同探索问题;后者则是使智能体直接学习人类专家已制定完成的策略,此类方法需要专家对未知环境直接进行研究判断,无法充分发挥强化学习的决策优势。
技术实现要素:
5.本发明的目的在于针对上述现有技术存在的缺陷,提供一种搭载强化学习智能体的无人设备集群协同探索方法,能够有效增强无人集群对未知环境协同探索能力;本发明旨在训练不同智能体之间的独立性,鼓励不同智能体探索不同环境区域,加速多智能体系统的社会分工分化,极大的缩短总体探索时间,节省多智能体强化学习训练中探索阶段的算力开销,进而反映到无人设备集群上,可以提升集群间不同设备的有效配合,提升集群综合决策能力。
6.为达到上述目的,本发明采用的技术方案是:
7.一种搭载强化学习智能体的无人设备集群协同探索方法,将无人集群视为一个多智能体系统,将搭载强化学习智能体的无人设备集群视为一个多智能体强化学习系统,包
括以下步骤:
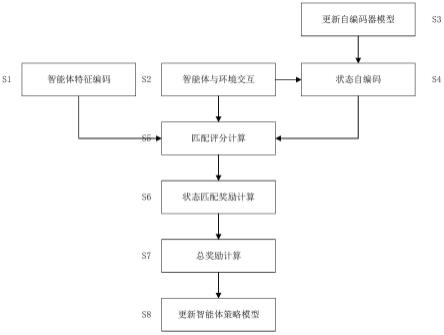
8.s1、根据智能体属性对多智能体系统中每个智能体进行特征向量编码,获得每个智能体的智能体特征向量;
9.s2、多智能体系统与环境交互,每个智能体从环境中获取下一个观测态和任务奖励;
10.s3、构建堆栈式自编码器,并根据环境中已探知状态对其进行无监督训练,得到自编码器模型;
11.s4、通过自编码器模型对多智能体系统中每个智能体在当前时间步访问状态的观测态进行编码,获得每个智能体的状态特征向量;
12.s5、采用分类器对当前时间步多智能体系统中每个智能体的智能体特征向量和状态特征向量计算匹配评分;
13.s6、根据匹配评分,对当前时间步多智能体系统中的每个智能体计算匹配评分奖励;
14.s7、根据匹配评分奖励、任务奖励,对当前时间步多智能体系统中的每个智能体计算总奖励;
15.s8、根据智能体当前观测态、动作、下一个观测态与总奖励,训练多智能体强化学习算法,更新强化学习智能体策略模型。
16.进一步的,步骤s1中,所述特征向量编码的过程为:
17.s11、马尔可夫决策决策过程中的全体动作空间{ai}
i∈i
可以被划分为互相独立的n份:{z1,z2,...,zn},采用n维向量编码智能体类型,若智能体i的可执行动作空间ai和划分空间zi重合,则将zi所对应的向量位记为1,其余向量位记为0,获得智能体i的智能体类型特性向量;
18.s12、对每个类型的智能体,通过独热编码方式编码智能体序号,获得智能体i的智能体序号特征向量;
19.s13、将智能体类型特征向量和智能体序号特性向量级联,获得智能体i的智能体特征向量。
20.进一步的,步骤s2中,在每个时间步中,多智能体系统中的每个智能体依次与环境交互:智能体i根据当前观测态oi与强化学习策略模型πi决策出动作ai,环境在智能体i的当前状态si执行动作ai,将智能体i转移到状态si′
,并将任务奖励和下一个观测态oi′
反馈给智能体i。
21.进一步的,步骤s3中,具体为:s31、在每个时间步中,收集多智能体系统中各个智能体访问状态的观测态,存入大小为buffsize的观测态缓存区bs;
22.s32、通过多层感知器构建足够解析全体环境状态空间的堆栈式自编码器coder;
23.s33、在强化学习的每个epsiode结束时,从观测态缓存区bs中采样抽取数据,采用均方误差损失函数对堆栈式自编码器coder进行无监督训练,得到收敛的自编码器模型。
24.进一步的,步骤s4中,具体为:将智能体i从环境获取的下一个观测态输入至自编码器模型中,由自编码器模型的编码模块计算得到智能体i的状态特征向量。
25.进一步的,步骤s5中,具体为:
26.s51、将智能体i的智能体特征向量与状态特征向量输入分类器,由分类器输出匹
配评分;
27.s52、构建临时标签:《featurei,codei;1》和其中,表示除智能体i以外的其他智能体的特征向量,-为反事实标注,1表示智能体特征向量featurei和状态特征向量codei的事实组合是正样本,0表示除智能体i外的其他智能体特征向量和状态特征向量codei的反事实组合是负样本;通过临时标签更新分类器classifier的网络参数。
28.进一步的,步骤s6中,具体为:计算智能体i应获取的状态匹配奖励
[0029][0030]
其中,β为奖励权重,rb为基础奖励,score为匹配评分;
[0031]
并将状态匹配奖励反馈给智能体i。
[0032]
进一步的,步骤s7中,具体为:
[0033]
s71、将智能体i的状态匹配奖励与其他内在奖励采用好奇心机制或事后经验重放计算得到智能体i的总内在奖励
[0034]
s72、将智能体i的总内在奖励与任务奖励相加得到总奖励ri,并将总奖励ri反馈给智能体i。
[0035]
基于上述技术方案,本发明的有益效果在于:
[0036]
1、采用堆栈式自编码器将相似状态编码为相似特征向量,使得智能体能够更清晰的识别相似的环境状态,能够从环境中获取更多信息,进而在实际上加强了无人设备集群的综合信息获取能力;
[0037]
2、使用自监督分类器classifier为智能体与所访问的环境状态计算匹配评分,判断该智能体是否应当访问这一状态,随着强化学习训练的episode增加,引导智能体访问状态的分化,促使不同智能体探索不同的区域,增强多智能体系统对环境的总体探索能力,实现多智能体系统的协同探索,进而加强无人设备集群中不同设备的协同性,提升不同设备间的有效配合,提升集群综合决策能力。
附图说明
[0038]
图1为本发明中基于强化学习的智能体协同探索方法的流程示意图。
[0039]
图2为本发明中多智能体系统与环境交互过程示意图。
[0040]
图3为本发明中自编码器模型的结构示意图。
[0041]
图4为本发明中自监督分类器classifier网络模型的结构示意图。
具体实施方式
[0042]
为使本发明的目的、技术方案和优点更加清楚,下面结合实施例和附图,对本发明作进一步地详细描述。
[0043]
本实施例旨在提出一种搭载强化学习智能体的无人设备集群协同探索方法,该方法通过构建状态匹配奖励,给智能体提供新的内在动机,加速多智能体之间的环境社会分工分化,提高多智能体系统的综合探索效率,进而解决搭载强化学习智能体的无人设备集
群对未知环境自主学习困难的问题;具体流程如图1所示,包括以下步骤:
[0044]
s1、根据智能体属性对多智能体系统中每个智能体进行特征向量编码,获得每个智能体的智能体特征向量;所述特征向量编码的过程为:
[0045]
s11、马尔可夫决策决策过程中的全体动作空间{ai}
i∈i
可以被划分为互相独立的n份:{z1,z2,
…
,zn},采用n维向量编码智能体类型,若智能体i的可执行动作空间ai和划分空间zi重合,则将zi所对应的向量位记为1,其余向量位记为0,获得智能体i的智能体类型特性向量i表示智能体集合;
[0046]
s12、对每个类型的智能体,通过独热编码方式编码智能体序号(若智能体序号过大、则采用分段独热编码方式),获得智能体i的智能体序号特征向量
[0047]
s13、将智能体类型特征向量和智能体序号特性向量级联,获得智能体i的智能体特征向量featurei;
[0048]
s2、多智能体系统与环境交互,每个智能体从环境中获取下一个观测态和任务奖励;
[0049]
所述多智能体系统与环境交互的过程如图2所示,其中,在每个时间步中,多智能体系统中的每个智能体依次与环境交互:智能体i根据当前观测态oi与强化学习策略模型πi决策出动作ai,环境在智能体i的当前状态si执行动作ai,将智能体i转移到状态si′
,并将任务奖励和下一个观测态oi′
反馈给智能体i;
[0050]
s3、构建堆栈式自编码器,并根据环境中已探知状态对其进行无监督训练,得到自编码器模型;
[0051]
所述堆栈式自编码器模型如图3所示,分为编码器和解码器,其中编码器包括输入层与隐藏层,解码器包括隐藏层与输出层,编码器与解码器共享隐藏层网络参数,以加快训练,其计算式为:
[0052]hw,b
(x)=x
[0053]
decoder(encoder(k))=x
[0054][0055]
其中,h
w,b
(.)表示自编码器,x表示智能体观测态向量,encoder、decoder分别为编码器和解码器,loss为损失函数,yi和分别表示真实值和网络预测值;
[0056]
具体为:s31、在每个时间步中,收集多智能体系统中各个智能体访问状态的观测态(观测态oi′
),存入大小为buffsize的观测态缓存区bs;
[0057]
s32、通过多层感知器构建足够解析全体环境状态空间的堆栈式自编码器coder;
[0058]
s33、在强化学习的每个epsiode结束时,从观测态缓存区bs中采样抽取数据,采用均方误差损失函数对堆栈式自编码器coder进行无监督训练,得到收敛的自编码器模型;
[0059]
s4、通过自编码器模型对多智能体系统中每个智能体在当前时间步访问状态的观测态(观测态oi′
)进行编码,获得每个智能体的状态特征向量;
[0060]
具体为:将智能体i从环境获取的下一个观测态oi′
输入至自编码器模型中,由自编码器模型的编码模块encoder计算得到智能体i的状态特征向量codei;
[0061]
s5、采用分类器对当前时间步多智能体系统中每对智能体特征向量和状态特征向量计算匹配评分;
[0062]
所述分类器classifier的网络模型如图4所示,包括输入层、隐藏层与输出层,评分计算式为:
[0063]
score=sigmoid(w4(w3(w1cfeaturei) w2(codei)))
[0064]
其中,w1、w2分别为智能体特征向量、状态特征向量在输入层的网络参数,w3为隐藏层网络参数,w4、sigmoid分别为输出层网络参数和激活函数;
[0065]
在训练阶段,分类器classifier通过智能体特征向量featurei和状态特征向量codei,采用sigmoid激活函数计算出匹配评分,同时通过智能体特征向量featurei和状态特征向量codei产生自监督学习标签,并采取最小化交叉熵损失函数的方式,自监督的更新网络参数;
[0066]
在执行阶段,具体为:
[0067]
s51、将智能体i的智能体特征向量featurei与状态特征向量codei输入分类器classifier,由分类器classifier输出智能体特征向量featurei和状态特征向量codei的匹配评分score;
[0068]
s52、构建临时标签:《featurei,codei;1》和其中,表示除智能体i以外的其他智能体的特征向量,-为反事实标注,1表示智能体特征向量featurei和状态特征向量codei的事实组合是正样本,0表示除智能体i外的其他智能体特征向量和状态特征向量codei的反事实组合是负样本;通过临时标签更新分类器classifier的网络参数;
[0069]
s6、对当前时间步多智能体系统中的每个智能体计算匹配评分奖励;
[0070]
具体为:计算智能体i应获取的状态匹配奖励
[0071][0072]
其中,β为奖励权重,rb为基础奖励;
[0073]
并将状态匹配奖励反馈给智能体i;
[0074]
s7、对当前时间步多智能体系统中的每个智能体计算总奖励;
[0075]
具体为:
[0076]
s71、将智能体i的状态匹配奖励与其他内在奖励采用好奇心机制或事后经验重放计算得到智能体i的总内在奖励
[0077]
s72、将智能体i的总内在奖励与任务奖励相加得到总奖励ri:将总奖励ri反馈给智能体i;
[0078]
s8、根据智能体当前观测态、动作、下一个观测态与总奖励,择机训练多智能体强化学习算法,更新强化学习智能体策略模型;具体的,若存在经验回放区,智能体将观测态、动作下一个观测态与总奖励存入经验回放区,待模型更新阶段从回放区采样进行训练;若采用在线学习的方式进行更新,则智能体之间利用这条经验更新策略模型,并将该经验抛弃。
[0079]
上述强化学习智能体分为训练阶段和执行阶段,在训练阶段时,s1为初始化阶段
实施,s2、s4-s8随着时间步推进迭代实施,s3在每个episode结束阶段实施;在执行阶段时,智能体特征向量编码方式已确立,自编码器coder、分类器classifier已训练完成,s2、s4-s7随着时间步推进迭代实施。
[0080]
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。