一种光纤通信系统中基于神经网络的ldpc码译码方法
技术领域
1.本发明属于通信技术领域,涉及ldpc码的关键技术,具体涉及一种在光纤通信系统中基于神经网络的ldpc码译码方法。
背景技术:
2.自从前向纠错码(fec)技术在20世纪90年代初首次提出以来,很多类型的码字都被用于光纤通信系统中来处理光学损伤,如无补偿色散、偏振模色散和非线性效应,并保持长距离的误码率(ber)足够低。近年来,随着微电子技术的快速发展,人们对各种码字的迭代软判决译码进行了深入的研究,以寻求尽可能高的编码增益。在当前和下一代光通信中,非常强大的fec码对于增强传输距离和速率至关重要。相比于turbo等其他码字,基于稀疏矩阵的ldpc(低密度奇偶校验码)码具有可以并行迭代译码,吞吐率大,硬件上实现容易,码字灵活性高,有可变的码长、码率,误码率平台低等优点,十分适合高速光通信系统。ldpc码是加性高斯白噪声(awgn)信道中最接近信道容量的仿真结果。它目前已经是ieee802.3n,ieee802.16e,5g,40g,100g至400g长距离光纤传输、下一代以太网无源光网络(ng-epon)等的编码方案。
3.在光纤通信系统的ldpc码译码方面,最传统的比特翻转译码(bf)算法是基于硬判决的ldpc码译码算法。之后,为了改进bf算法的译码性能,通过给不同的校验方程引入不同的可靠性度量值的加权比特翻转(wbf)和利用对数似然比(llr)信息的梯度比特翻转(gbf)等算法被提出。这些算法虽然复杂度低,但译码性能较低。和积算法(spa)是基于软信息的译码算法,其误码率性能距离香农极限仅有0.0045db,但复杂度很高,实现需要花费太多的硬件资源。因此,最小和算法(msa)简化了spa。然而,与spa相比,msa近似会造成相当大的性能损失。归一化最小和算法(nms)、偏置最小和(oms)算法和归一化偏置最小和算法(noms)在msa的基础上引入了归一化系数、偏置系数以及同时引入了归一化系数、偏置系数,改善msa的误码率,参数取值合适时,可以逼近spa。其中,在awgn信道中,通过密度演化(de)分析,归一化系数和偏置系数分别建议取0.8和0.15。而在光纤通信链路中,发射端,光纤和接收端都可能存在着各种非线性效应和符号间干扰,远远不是awgn信道。因此在光纤通信系统中,丞待一种确定合适的归一化系数和偏置系数的方法,使ldpc码译码更加准确。
技术实现要素:
4.对于ldpc译码算法,可学习的归一化/偏移因子被添加到nms/oms译码器,以提供对硬件更友好的神经译码器。然而,对于这些基于神经网络(nn)的ldpc码译码算法,其nms、oms或者noms译码器的参数都是基于只有高斯加性白噪声的awgn信道确定的,本发明针对存在各种非线性效应的光纤通信链路,提出了基于nn的神经noms算法,使ldpc码在光通信中的性能更好。
5.为实现上述目的,本发明采用如下技术方案:
6.对于一个qc-ldpc(准循环ldpc)码(n,k),其中,n为码字长度,k为信息比特的长
度,m为校验比特的长度(m=n-k)。其校验矩阵为h。其相应的指数矩阵e(h)的维度为(nb,kb),其中,nb和n
b-kb是e(h)的列数和行数,nb=n/z,kb=k/z,mb=m/z=n
b-kb。i是tanner图中的边数,eb是e(h)中的边数。h矩阵可以用一个tanner图来表示,它由n个变量节点vn,m个校验节点cm和i条边ei构成,其中,n∈{0,1,...,n-1},m∈{0,1,...,m-1}和i∈{0,1,...,i-1}。如果校验矩阵h的第m行和第n列是1,则第i条边连接第m个校验节点和第n个变量节点。变量节点vn的相邻点是校验节点cm,m∈a(n),其中a(n)是连接到变量节点vn的校验节点的索引集。类似地,校验节点cm的相邻点是变量节点vn,n∈b(m),其中,b(m)是连接到校验节点cm的变量节点的索引集。一个(n,k)的ldpc码是通过将e(h)中的每个元素变成z
×
z的循环移位矩阵或者全0矩阵。因此,qc-ldpc码的这种特性允许基于神经网络的noms译码器对相同边类型的所有边应用相同的参数。
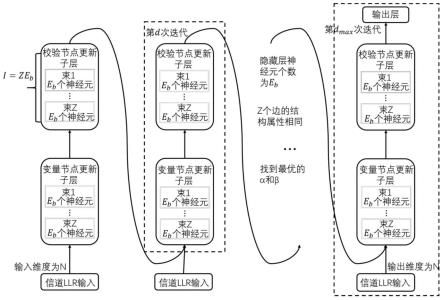
7.神经网络的输入层输入的是一个大小为n的向量,它是码字长度;神经网络的输入是经过信道接收到的n个比特;输出是估计的n个发送比特,神经网络的结构是根据校验矩阵h构造的。除最后一层外(即所有隐藏层),网络中的所有后续层的大小均为i。与noms译码过程中的第d次迭代相对应的隐藏层索引也为d(d=1,2,...,d
max
)。每个隐藏层包括两个子层dv和dc,分别对应于变量节点更新和校验节点更新。输出层包含n个神经元。其基本结构图1所示。对于隐藏层d的边e(vn,cm),子层dv中的神经元沿着从相关联的变量节点vn发送到校验节点cm的边输出消息。对于子层dc中的神经元沿着从相关联的校验节点cm发送到变量节点vn的边输出消息。与边e(vn,cm)对应的第一个隐藏层中的神经元连接到输入层中的第vn个元素。与边e(vn,cm)对应的隐藏层d(d》1)的神经元连接到与边且c
m'
≠cm相关联的隐藏层d-1的子层中的神经元。与边e(vn,cm)对应的隐藏层d(d≥1)的子层dc中的神经元与子层dv中的与边e(vn,c
m'
)且v
n'
≠vn相关联的神经元相连接,边e(vn,c
m'
)为tanner图中连接第n个变量节点vn、校验节点c
m'
的边,c
m'
为集合a(n)中的校验节点。
8.其具体步骤包括:
9.1.对于qc-ldpc码,基于神经网络nn的每个隐藏层包括两个子层,分别用于更新变量节点和用于更新校验节点;每个子层中的所有i个神经元都可以划分为z组,每组包含eb个元素,其与指数矩阵上的边数相对应,因此,i=zeb。
10.2.考虑第d个隐藏层,为子层dv中处理e(vn,cm)的神经元。此神经元的输出消息可以表示为:其中,是信道的对数似然比,与光纤通信链路中接收的信息rn有关,rn为光纤通信系统接收机接收到的n个比特,光纤通信链路的通信信道中存在平均值为0、方差为σ的加性高斯白噪声信道。a(n)\m为不包括cm的校验节点a(n)的索引集。对于所有e(vn,c
m'
),其初始化
11.3.为子层dc中处理e(vn,cm)的神经元,神经元的输出信息可以表示为:其中,b(m)\n为不包括vn的变量节点b(m)的索引集,e(vn,c
m'
)为tanner图中连接第n个变量节点vn、校验节点c
m'
的边,c
m'
为集合a(n)中不包括cm的校验节点,b(m)是连接到校验节点cm的变量节点的索引集,e(vn,c
m'
)为tanner图中连接变量节点v
n'
、校验节点cm的边,v
n'
为b(m)中不包括vn的变量
节点,为第d次迭代边e(vn,cm)的归一化系数,为第d次迭代边e(vn,cm)的偏置系数。
12.4.输出神经元输出的信息为:其中,激活函数sigmoid()保证了最终神经网络的输出值在0和1之间,因此,on是发送比特wn=0的概率。训练过程中,神经元内的权重和偏置随着译码迭代次数d(d=1,2,...,d
max
)变化,最大译码迭代次数d
max
等于神经网络的隐藏层总数。
13.5.使用在实际光纤通信链路中传输的码字w和基于神经网络noms译码器输出o之间的交叉熵作为损失函数,定义为:其中,wn和on分别是第n个发送码字和神经网络输出。为了找到最佳的归一化因子和偏移因子,训练方法是根据构造noms译码神经网络,并调整所有d
max
次迭代的权重和偏差,以最小化损失函数。上线过程中,则直接用固定的和来迭代更新。
14.与现有技术相比,本发明的积极效果为:
15.本发明通过nn学习光通信信道的特征,提高了ldpc码译码算法的性能,使ldpc码在光传输系统中得到充分的利用。
附图说明
16.图1为nn-noms译码器的结构示意图。
17.图2为基于vpi的短距离光互连系统仿真框图。
18.图3为码字1的误码率性能。
19.图4为码字1的eb个神经元的α值。
20.图5为码字1的eb个神经元的β值。
21.图6为当rop=4dbm时,码字1随迭代次数的误码率性能。
22.图7为100gb/s,100m场景下,码字1的误码率性能。
23.图8为100gb/s,btb场景下,码字1的误码率性能。
24.图9为码字2的eb个神经元的α值。
25.图10为码字2的eb个神经元的β值。
26.图11为码字2的误码率性能。
具体实施方式
27.下面通过具体实施例,并配合附图,对本发明做详细的说明。
28.vpitransmissionmaker v10.0(vpi)建立数据中心内短距离光互连系统仿真平台,如图2所示。本节介绍的仿真平台中的垂直腔面发射激光器(vcsel),多模光纤(mmf)以及光探测器均使用vpi提供的模块。由于神经网络已被证明,其可以估计伪随机码(prbs)的一部分发送规律,从而高估性能,因此,在发送端,我们产生0为均值,1为方差的高斯分布随机数,然后判断其符号,从而确定发送比特并产生不归零码(nrz)信号。光载波由3db带宽约
为3ghz的850nm vcsel产生。然后,分别在长度为100m的mmf和端到端(btb)的场景下以100gb/s的速率传输光信号。接收机采用可变光衰减器(voa)调节接收光功率。光信号由光电二极管(pd)检测之后,依次进行前向均衡(ffe)、ldpc码译码,得到恢复之后的比特,并计算误码率。
29.仿真使用的基码是5g标准中的bg1矩阵,其奇偶校验矩阵h
bg1
中有46行68列。测试码字1(2240,1760)的码率为5/6,z=80,其eb=87。测试码字2(2232,1584)的码率为3/4,z=72,其eb=113。训练长度为1000帧ldpc码,测试长度也为1000帧ldpc码,确定α和β的值之后,noms迭代次数为25次。码字1在100gb/s的100m光互连链路的误码率性能如图3所示。在ber=10-3
时,基于神经网络的noms算法,即,nn-noms算法比起传统noms算法,可带来将近4db的增益。
30.图4和图5是速率为100gb/s,传输距离为100m,rop=4dbm时,测试码字1的eb个神经元的归一化值α和偏置值β。可以看出,α值都集中在0.895附近,β值都集中在0.053左右。于是,我们尝试将α值固定为0.89,β值固定为0.05左右,得到的测试码字1在接收信噪比(rop)=4dbm时,随着迭代次数的误码率性能如图6所示(nn-noms-fix为固定值之后的曲线)。可以看出,参数值固定之后,nn-noms-fix算法和nn-noms算法性能几乎一致。
31.图7和图8为100gb/s的场景下,传输距离分别为100m和btb时,测试码字1的nn-noms-fix算法、nn-noms和noms的误码率性能。此时,对于不同的rop,我们均采用了任意一个功率点时训练得到的固定α值和β值。nn-noms-fix算法和nn-noms算法的误码率性能均相似,且明显好于传统的noms算法。因此,我们的方法不仅可以很好的学习光纤通信系统的各种非线性效应,而且泛化能力很强,对于同一信道的相同ldpc码,我们只需训练一次,即可得到合适的参数值。之后,对于不同接收光功率的传输链路,则无需重新训练。
32.图9和图10是速率为100gb/s,传输距离为100m,nn-noms经过四次迭代训练后,在rop=0dbm时,测试码字2的eb个神经元的α和β值。可以看出,α值都集中在0.893附近,β值都集中在0.06左右。于是,在nn-noms-fix算法中,我们尝试将α值固定为0.89,β值固定为0.06左右。
33.图11为测试码字2在速率为100gb/s,传输距离为100m和btb时的误码率性能,在ber=10-5
左右,相比传统noms算法,nn-noms算法可分别带来约2db和1db的信噪比增益。nn-noms-fix算法和nn-noms算法的误码率性能相似,进一步证明了nn-noms算法的泛化能力很强。
34.尽管为说明目的公开了本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。因此,本发明不应局限于最佳实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。