一种基于lr对对三阴性乳腺癌进行分型的方法及其应用
技术领域
1.本发明涉及分子生物学领域,具体涉及一种基于lr对对三阴性乳腺癌进行分型的方法及其应用。
背景技术:
2.乳腺癌是目前最常见的女性癌症之一,占所有癌症病例的11.7%。在临床中,根据雌激素、孕激素受体和人表皮生长因子受体2(her2)等分子标记物的表达情况,可将乳腺癌分为三个主要亚型,包括激素受体阳性/her2阴性亚型(70%)、her2阳性亚型(15%-20%)和三阴性亚型(tnbc,具体指缺乏上述3个标准分子标记的肿瘤类型,15%)。在所有三种乳腺癌亚型中,三阴性乳腺癌(tnbc)是侵袭性最强、预后最差的亚型。随着相关研究的报道,基于各种临床、病理和遗传因素分析,研究人眼认为三阴性乳腺癌是一种单独的异质性乳腺癌亚型。多组学分析研究也为tnbc的生物异质性提供了新的见解,根据其复发的遗传畸变、转录模式和肿瘤微环境特征等,将这些肿瘤的分类进化为不同的分子亚型,而这种分子亚型的准确分型和基于其基因图谱的预后情况预测将可能有助于促进个性化治疗的研究。但多组学分析步骤复杂,检测成本和时间成本高,对于人员要求高,无法有效普及,而现有技术中尚无其他可以针对三阴性乳腺癌不同的分子亚型进行有效分型的手段。
3.肿瘤是癌细胞和非癌细胞的异质性混合物。肿瘤微环境中由配体-受体相互作用介导的细胞间通信(tme)对肿瘤的进展有深远的影响。而研究证实,肿瘤内这些细胞之间的通讯是肿瘤进展的关键。这些细胞之间的通讯是通过细胞产生的配体(蛋白质、肽、脂肪酸、类固醇、气体和其他低分子量化合物)实现的,这些配体由细胞分泌或存在于细胞表面,因此在靶细胞上或靶细胞内充当受体。现有文献指出,大多数细胞表达数十到数百个配体和受体,通过多个配体-受体对形成高度连接的信号网络。受体及其相应配体的生物学重要性和可用性已将其指定为癌症特别有用的临床靶点,但目前并无其在三阴性乳腺癌方面的应用。
4.因此,开发一种高效、准确的三阴性乳腺癌亚型分型方法对于三阴性乳腺癌的诊断和早期治疗具有极为重要的意义。
技术实现要素:
5.本发明旨在至少解决上述现有技术中存在的技术问题之一。为此,本发明提出一种基于lr对对三阴性乳腺癌进行分型的方法及其应用,本发明中的分型方法能够针对三阴性乳腺癌进行进一步分型,相比传统的分型更加能够体现出患者的生存情况,预测出疾病的发展走向,从而施展更加有效的治疗手段或方式,有效降低三阴性乳腺癌的死亡率。
6.本发明的第一个方面,提供一种三阴性乳腺癌的分型方法,包括如下步骤:
7.检测样品中的三阴性乳腺癌预后相关lr对的表达情况,使用算法对样品进行分型,其中,所述算法为k-means算法、“1-pearson相关”和聚类算法。
8.根据本发明的第一个方面,在本发明的一些实施方式中,所述三阴性乳腺癌预后
相关lr对包括:apob-eno1、cxcl12-itga4、gpi-amfr、muc7-sell、selplg-sell、podxl-sell、bsg-slc16a7、cd22-ptprc、ptprc-cd22、ppbp-cxcr1、il7-il7r、ccl19-ccr7、serping1-selp、ccl16-ccr2、plg-f2rl1、cxcl13-ackr4、il11-il6st、icos-icoslg、icoslg-icos、ccl19-ackr4、cxcl3-cxcr1、icam4-itga4、ccl16-ccr5、cd2-cd48、cd48-cd2、tnfsf13b-tnfrsf13b、adam7-itga4、hbegf-erbb2、calr-scarf1、cxcl13-cxcr5、lgi3-stx1a、cd244-cd48、cd48-cd244、hla-a-kir3dl1、hla-b-kir3dl1、hla-f-kir3dl1、lgi3-flot1、vegfa-gpc1、efna4-epha5、qrfp-p2ry14、fgf4-fgfrl1、cxcl8-cxcr1、nms-nmur2、glg1-sele、ly9-ly9、edn3-kel、cxcl13-ccr10、ccl19-cxcr3、ccl21-cxcr3、adm-ramp2、cfh-sell、cxcl12-itgb1、cd34-sell、nmb-brs3、ccl21-ccr7、podxl2-sell、serping1-sele、clec2b-klrf1、klrf1-clec2b、cxcl13-cxcr3、sema4d-met、adm-mrgprx2、ebi3-il6st、tslp-il7r、b2m-cd1b、adam28-itga4、wnt8a-fzd5、adam7-itgb7、gnrh1-gnrhr、adm-calcr、ltb-ltbr、col14a1-cd44、f2-f2rl2、defb103a-ccr6、slit3-robo1、vtn-plaur、ccl25-ackr2、ccl19-ccr10、lrfn3-lrfn3、cxcl9-ccr3、mrc1-ptprc、ptprc-mrc1、cd58-cd2、cytl1-ccr2、dkk2-lrp6、serpine1-lrp1、efna4-epha6、nmb-nmbr、mmp7-erbb4、pomc-oprd1、clec2d-klrb1、klrb1-clec2d、gdf3-tdgf1、guca2a-gucy2c、il16-kcnj10、fgf3-fgfrl1、lrpap1-sort1、cxcl11-cxcr3、wnt9a-fzd10、apob-lsr、cd70-cd27、angptl1-tek、tnf-tnfrsf1b、cxcl12-cd4、nectin2-tigit、nectin4-tigit、tigit-nectin2、faslg-fas、pomc-mc3r、vcam1-itgb7、app-lrp1、il22-il22ra1、selplg-sele、ccl21-ackr4、tnfsf13-fas、cd160-tnfrsf14、tnfrsf14-cd160、fgf6-fgfr1、spp1-itgb1、madcam1-itga4、oxt-avpr1a、cxcl9-cxcr3、cxcl5-ackr1、btla-tnfrsf14、tnfrsf14-btla、ccl5-ccr3、tac3-tacr1、cxcl10-sdc4、vegfa-kdr、efna1-epha5、ccl5-ackr1、efna1-epha2、dkk4-kremen2、pomc-mc2r、gnas-ptgdr、ccl13-ccr2、il18-il18r1、myl9-cd69、cxcl6-cxcr1、rspo3-lrp6、ambn-cd63、calr-tshr、icam3-itgal、nmu-nmur1和dll4-notch3。
9.在本发明中,发明人通过对常规三阴性乳腺癌(tnbc)相关lr对进行分析和研究,共筛选出了上述145对与tnbc预后相关的lr,其中44对lr对应预后不良,101对lr对应预后良好。
10.其中,预后不良的44对lr为apob-eno1、gpi-amfr、bsg-slc16a7、ppbp-cxcr1、plg-f2rl1、cxcl3-cxcr1、hbegf-erbb2、calr-scarf1、lgi3-stx1a、lgi3-flot1、vegfa-gpc1、efna4-epha5、fgf4-fgfrl1、cxcl8-cxcr1、nms-nmur2、adm-ramp2、nmb-brs3、adm-mrgprx2、wnt8a-fzd5、adm-calcr、vtn-plaur、lrfn3-lrfn3、serpine1-lrp1、efna4-epha6、nmb-nmbr、gdf3-tdgf1、fgf3-fgfrl1、lrpap1-sort1、apob-lsr、app-lrp1、il22-il22ra1、fgf6-fgfr1、spp1-itgb1、oxt-avpr1a、tac3-tacr1、vegfa-kdr、efna1-epha5、efna1-epha2、dkk4-kremen2、cxcl6-cxcr1、ambn-cd63、calr-tshr、nmu-nmur1、dll4-notch3。
11.预后良好的101对lr为cxcl12-itga4、muc7-sell、selplg-sell、podxl-sell、cd22-ptprc、ptprc-cd22、il7-il7r、ccl19-ccr7、serping1-selp、ccl16-ccr2、cxcl13-ackr4、il11-il6st、icos-icoslg、icoslg-icos、ccl19-ackr4、icam4-itga4、ccl16-ccr5、cd2-cd48、cd48-cd2、tnfsf13b-tnfrsf13b、adam7-itga4、cxcl13-cxcr5、cd244-cd48、cd48-cd244、hla-a-kir3dl1、hla-b-kir3dl1、hla-f-kir3dl1、qrfp-p2ry14、glg1-sele、ly9-ly9、edn3-kel、cxcl13-ccr10、ccl19-cxcr3、ccl21-cxcr3、cfh-sell、cxcl12-itgb1、
cd34-sell、ccl21-ccr7、podxl2-sell、serping1-sele、clec2b-klrf1、klrf1-clec2b、cxcl13-cxcr3、sema4d-met、ebi3-il6st、tslp-il7r、b2m-cd1b、adam28-itga4、adam7-itgb7、gnrh1-gnrhr、ltb-ltbr、col14a1-cd44、f2-f2rl2、defb103a-ccr6、slit3-robo1、ccl25-ackr2、ccl19-ccr10、cxcl9-ccr3、mrc1-ptprc、ptprc-mrc1、cd58-cd2、cytl1-ccr2、dkk2-lrp6、mmp7-erbb4、pomc-oprd1、clec2d-klrb1、klrb1-clec2d、guca2a-gucy2c、il16-kcnj10、cxcl11-cxcr3、wnt9a-fzd10、cd70-cd27、angptl1-tek、tnf-tnfrsf1b、cxcl12-cd4、nectin2-tigit、nectin4-tigit、tigit-nectin2、faslg-fas、pomc-mc3r、vcam1-itgb7、selplg-sele、ccl21-ackr4、tnfsf13-fas、cd160-tnfrsf14、tnfrsf14-cd160、madcam1-itga4、cxcl9-cxcr3、cxcl5-ackr1、btla-tnfrsf14、tnfrsf14-btla、ccl5-ccr3、cxcl10-sdc4、ccl5-ackr1、pomc-mc2r、gnas-ptgdr、ccl13-ccr2、il18-il18r1、myl9-cd69、rspo3-lrp6、icam3-itgal。
12.在癌症的发展过程中,癌细胞-基质细胞串扰是由大量配体-受体相互作用协调的,以产生有利于肿瘤生长的tme(肿瘤微环境)。而在肿瘤微环境中,基于lr对的细胞间通讯则是多种癌症(如胰腺导管腺癌和结直肠癌等)预后不良的基础,因此,进一步研究受体和配体及其相互作用是本领域中的热点和重点。在本发明中,上述lr对均来自文献管理数据库connectome db2020,connectome db2020是一个集成2293对lr交互的数据库,在本发明中,发明人是基于该tnbc数据库中的2293对lr作为筛选的基础得到了上述145对lr,当然,本领域技术人员也可以根据实际使用需求,选择来自其他数据库来源的lr对。
13.在本发明中,对上述145对lr进行富集分析,发现在145对lr中,主要有10条途径最为丰富,包括病毒蛋白与细胞因子和细胞因子受体的相互作用、细胞因子-细胞因子受体相互作用、粘附分子(cam)、趋化因子信号通路、iga产生的肠道免疫网络、类风湿关节炎、癌症中的蛋白多糖、疟疾、神经活性配体-受体相互作用以及造血细胞谱系。
14.在本发明的一些实施方式中,所述算法的聚类数k为3。
15.在本发明的一些实施方式中,聚类的数量由共识累积分布函数(cdf)图和delta面积图决定,标准为聚类内的一致性高,变异系数低,cdf曲线下的面积未有显著增加,而经过发明人的测试发现,k=3时产生了稳定的聚类结果。
16.在本发明的一些实施方式中,所述三阴性乳腺癌被分型为c1型、c2型和c3型。
17.在本发明的一些实施方式中,所述分型的定义标准是基于训练集生存时间得到的,具体地,不同分型的生存时间上,c1》c2》c3。即训练集中患者总生存时间最长的分群定义为c1,次之为c2,再次之为c3。
18.而对于本发明中的方法而言,在训练集、聚类方法和条件均完全公开的情况下,本领域技术人员能够基于本发明中的训练集、聚类方法和条件复现本发明中的分型标准,从而以复现的分型标准为依据,通过将受试者实际检测得到的表达谱带入本发明中提供的矩阵后得到对应参数,通过比较欧式距离即可实现准确的分型。
19.在本发明中,发明人在三组不同来源的常规tnbc队列中,采用了相同的分子亚型判定方法后,也形成了对应的三种分子亚型,并且在生存分析中观察到三种亚型之间的预后同样存在显著和相似的差异情况。
20.在本发明的一些实施方式中,所述分型的判断标准为:
21.通过表达谱计算受试者样品与三种分型聚类中心的欧式距离,根据距离判断分
型;其中,若受试者样品的质心与c1型聚类中心的欧式距离短于其与c2和c3的欧式距离,则受试者为三阴性乳腺癌c1型;若受试者样品的质心与c2型聚类中心的欧式距离短于其与c1和c3的欧式距离,则受试者为三阴性乳腺癌c2型;若受试者样品的质心与c3型聚类中心的欧式距离短于其与c1和c2的欧式距离,则受试者为三阴性乳腺癌c3型。
22.在本发明中,发明人对上述方法得到的三种不同三阴性乳腺癌亚型间突变和拷贝数变异(cnv)进行分析,发现分子亚型与临床变量(如肿瘤分期、年龄和性别)之间未发现显著相关性。而且,还注意到广泛接受的5种乳腺癌固有分子亚型(luminal a、luminal b、her2-enriched、basal-like和claudin-low)在三种基于lr对的亚型中的分布存在显著差异。其中,claudin-low亚型样本占c3亚型的很大比例,而basal-like亚型样本则占c1亚型的较大比例。c1和c3之间的死亡率也存在显著差异。超过60%的c1样本死亡,超过55%的c3样本存活。而在另一队列中,c1和c3的年龄分布趋势相反。三个亚型之间的生存状态也存在统计学显著差异。但本发明中的三个亚型能够实现对于传统的5种亚型分型无法实现的治疗及预后效果方面的评估作用。
23.在本发明中,发明人探索了基于三种分子亚型的lr对之间的分子生物学差异,发现在三个tnbc数据集中的c1和c3中,糖酵解、缺氧和雌激素反应早期显著上调,而包括凋亡、通过nf-xb和补体的tnfa信号传导等在内的10条途径显著下调。在进一步比较了代谢队列中c1和c2之间以及c2和c3亚型之间的各种途径的活性后,发现在每个基于lr对的分子亚型中均激活了6条途径,包括糖酵解、缺氧、上皮-间充质转化、myc靶点、肌生成、早期和晚期雌激素反应。
24.在本发明中,发明人对三种分子亚型进行免疫分析,发现三种基于lr对的分子亚型之间估计比例存在差异的大多数免疫细胞(总共16个)都在代谢组群中,包括幼稚b细胞、记忆b细胞、cd8 t细胞、幼稚cd4 t细胞、激活的cd4记忆t细胞、δ-γt细胞、静止和激活的nk细胞、m0巨噬细胞、m1巨噬细胞、m2巨噬细胞、静息的树突状细胞、活化的树突状细胞、静息和活化的肥大细胞、以及中性粒细胞。在所有三个tnbc队列中的基于lr对的分子亚型中,幼稚b细胞、幼稚cd4 t细胞、活化cd4记忆t细胞、δ-γt细胞、激活nk细胞、m0巨噬细胞、m1巨噬细胞、m2巨噬细胞和活化的肥大细胞的估计比例存在显著差异。通过kruskalwallis检验比较各亚型间基质评分、免疫评分和估计评分。每个队列中的三个分子亚型之间的免疫评分显示出显著差异,p值均《0.01。每个队列中三个分子子型之间的免疫评分/估计评分也显示出高度的显著差异,p值均《0.0001。无论三个评分中的哪一个,c3始终》c2》c1。
25.本发明的第二个方面,提供本发明第一个方面所述的分型方法在三阴性乳腺癌患病人群划分中的应用。
26.在本发明中,发明人基于第一个方面所述的分型方法成功构建得到了一种基于lr对(lr pairs)的风险模型,该模型使用lasso惩罚的cox回归分析预后相关的lr对,通过减少模型参数的权重来消除不重要的lr对,得到初筛lr对。然后将初筛lr对通过mass软件包中的stepaic策略进行过滤。利用stepaic值最低的基因建立lr对评分模型,并通过多元cox回归分析获得每个基因的系数。
27.在本发明的一些实施方式中,按临床治疗效果计,c1型人群优于c2型人群优于c3型人群。
28.本发明的第三个方面,提供检测如下lr对表达量的检测产品在制备三阴性乳腺癌
诊断和/或分型产品中的应用;
29.其中,所述lr对包括:apob-eno1、cxcl12-itga4、gpi-amfr、muc7-sell、selplg-sell、podxl-sell、bsg-slc16a7、cd22-ptprc、ptprc-cd22、ppbp-cxcr1、il7-il7r、ccl19-ccr7、serping1-selp、ccl16-ccr2、plg-f2rl1、cxcl13-ackr4、il11-il6st、icos-icoslg、icoslg-icos、ccl19-ackr4、cxcl3-cxcr1、icam4-itga4、ccl16-ccr5、cd2-cd48、cd48-cd2、tnfsf13b-tnfrsf13b、adam7-itga4、hbegf-erbb2、calr-scarf1、cxcl13-cxcr5、lgi3-stx1a、cd244-cd48、cd48-cd244、hla-a-kir3dl1、hla-b-kir3dl1、hla-f-kir3dl1、lgi3-flot1、vegfa-gpc1、efna4-epha5、qrfp-p2ry14、fgf4-fgfrl1、cxcl8-cxcr1、nms-nmur2、glg1-sele、ly9-ly9、edn3-kel、cxcl13-ccr10、ccl19-cxcr3、ccl21-cxcr3、adm-ramp2、cfh-sell、cxcl12-itgb1、cd34-sell、nmb-brs3、ccl21-ccr7、podxl2-sell、serping1-sele、clec2b-klrf1、klrf1-clec2b、cxcl13-cxcr3、sema4d-met、adm-mrgprx2、ebi3-il6st、tslp-il7r、b2m-cd1b、adam28-itga4、wnt8a-fzd5、adam7-itgb7、gnrh1-gnrhr、adm-calcr、ltb-ltbr、col14a1-cd44、f2-f2rl2、defb103a-ccr6、slit3-robo1、vtn-plaur、ccl25-ackr2、ccl19-ccr10、lrfn3-lrfn3、cxcl9-ccr3、mrc1-ptprc、ptprc-mrc1、cd58-cd2、cytl1-ccr2、dkk2-lrp6、serpine1-lrp1、efna4-epha6、nmb-nmbr、mmp7-erbb4、pomc-oprd1、clec2d-klrb1、klrb1-clec2d、gdf3-tdgf1、guca2a-gucy2c、il16-kcnj10、fgf3-fgfrl1、lrpap1-sort1、cxcl11-cxcr3、wnt9a-fzd10、apob-lsr、cd70-cd27、angptl1-tek、tnf-tnfrsf1b、cxcl12-cd4、nectin2-tigit、nectin4-tigit、tigit-nectin2、faslg-fas、pomc-mc3r、vcam1-itgb7、app-lrp1、il22-il22ra1、selplg-sele、ccl21-ackr4、tnfsf13-fas、cd160-tnfrsf14、tnfrsf14-cd160、fgf6-fgfr1、spp1-itgb1、madcam1-itga4、oxt-avpr1a、cxcl9-cxcr3、cxcl5-ackr1、btla-tnfrsf14、tnfrsf14-btla、ccl5-ccr3、tac3-tacr1、cxcl10-sdc4、vegfa-kdr、efna1-epha5、ccl5-ackr1、efna1-epha2、dkk4-kremen2、pomc-mc2r、gnas-ptgdr、ccl13-ccr2、il18-il18r1、myl9-cd69、cxcl6-cxcr1、rspo3-lrp6、ambn-cd63、calr-tshr、icam3-itgal、nmu-nmur1和dll4-notch3。
30.在本发明中,上述lr对均来自文献管理数据库connectome db2020,当然,本领域技术人员也可以根据实际使用需求,选择来自其他数据库来源的lr对。
31.在本发明的一些实施方式中,所述检测lr对表达量的检测产品包括但不限于基于半定量rt-pcr、northern blot、实时荧光定量pcr等方法构建的检测产品。相关特异性引物或探针等可基于本领域常规得到。
32.在本发明的一些实施方式中,所述检测产品包括但不限于检测试剂、检测试剂盒、基因芯片。
33.本发明的第四个方面,提供一套检测系统,所述检测系统包括:
34.用于检测lr对的检测单元;和
35.分型单元;
36.所述分型单元通过将检测单元得到的数据带入矩阵中,并按原始建模分类方法和参数进行分型,得到分型结果。
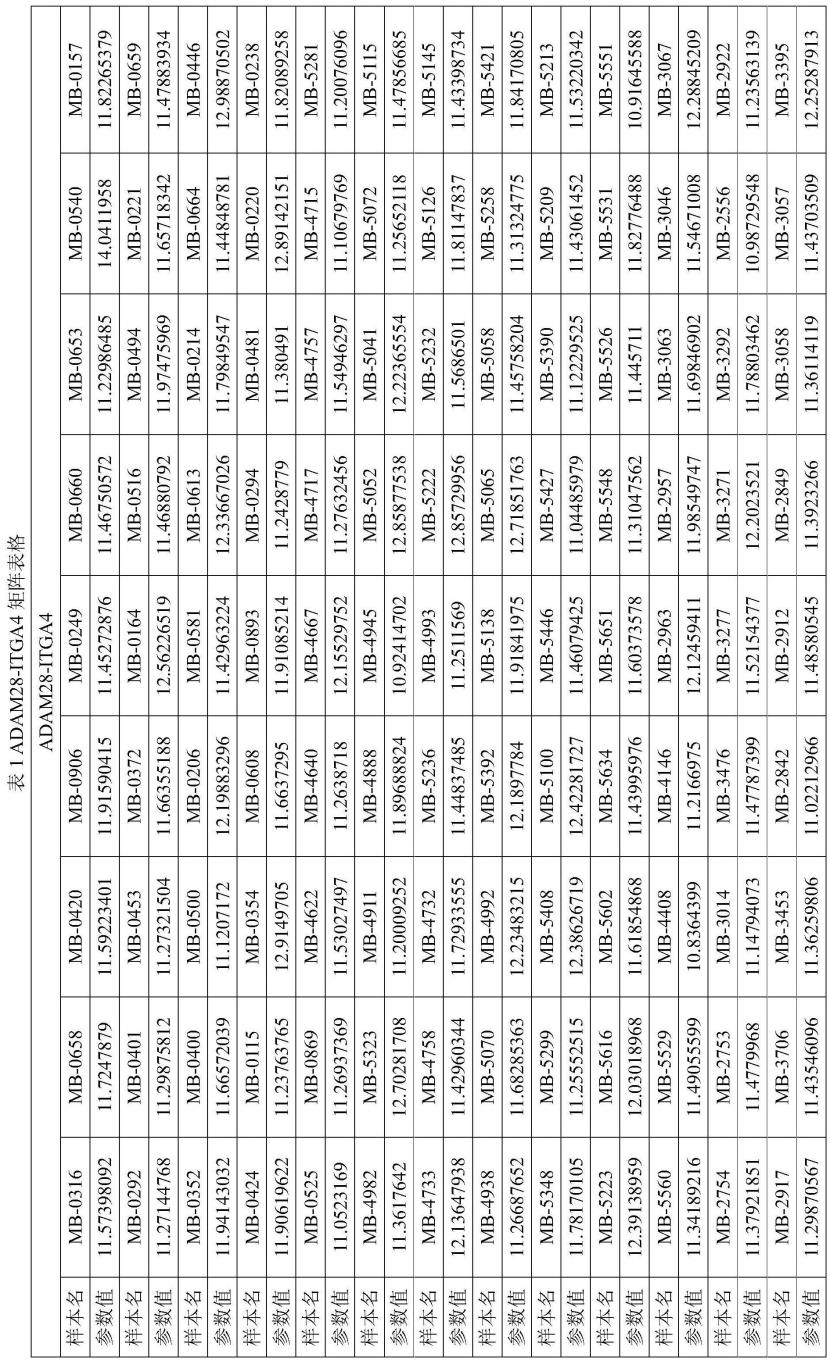
37.在本发明的一些实施方式中,所述矩阵是基于实施例中的训练集得到,得到矩阵的示例如表1和图24所示。
38.在本发明的一些实施方式中,所述分型单元中还包括计算装置,用于计算待测样
品数据到三个已知聚类中心(c1~c3)的欧氏距离,并根据欧氏距离导出分型结果。若待测样品数据的质心与c1型聚类中心的欧式距离短于其与c2和c3的欧式距离,则受试者为三阴性乳腺癌c1型;若待测样品数据的质心与c2型聚类中心的欧式距离短于其与c1和c3的欧式距离,则受试者为三阴性乳腺癌c2型;若待测样品数据的质心与c3型聚类中心的欧式距离短于其与c1和c2的欧式距离,则受试者为三阴性乳腺癌c3型。
39.本发明的有益效果是:
40.本发明提供了一种三阴性乳腺癌的分型方法,该方法通过对检测样品中的三阴性乳腺癌预后相关lr对的表达情况,使用算法对样品进行分型,分型准确且快捷,其相比于传统的5种亚型的分型方式更加具有针对性,分型得到的3种亚型能够很好的将三阴性乳腺癌患者分为3种类型,从而根据3种亚型对应的生存率、预后效果估计、免疫效果、临床治疗有效性等方面的显著差异性,给予合理且合适的治疗或处理,提高治疗有效性,从而有效降低三阴性乳腺癌的死亡率。
附图说明
41.图1为本发明中对与预后相关的lr对的筛选,其中,a为筛选流程图;b为145对lr的预测火山图;c为145对lr的交互式网络图。
42.图2为145对lr的10条高度富集的kegg途径。
43.图3为基于lr对的三种tnbc亚型识别结果,其中,a为k=2~9时的一致聚类累积分布函数(cdf)图;b为metaric中样本一致聚类的增量-面积曲线;c一致性k=3时样本聚类热图。
44.图4为metaric数据集中的三种亚型的os的kaplan-meier分析图。
45.图5为gse58812数据集(a)和gse21653数据集(b)中的三种分子亚型os的kaplan-meier分析图。
46.图6为基于lr对的分子亚型的临床特征和基因组改变情况,其中,a为metaric数据库中各亚型的分期、分级、年龄、pam50 claudin-low分子亚型的分布比例和生存状况;b为gse588123队列中每个亚型的年龄和生存状态的分布比例。
47.图7为gse21653数据集中三种亚型的年龄和生存状态分布。
48.图8为本发明中的三个亚型在metaric数据库中的体细胞突变和cnv的瀑布图(卡方检验)。
49.图9为基于lr对的分子亚型之间的功能分析结果,其中,a为代谢队列中c1和c3亚型的gsea气泡图;b为三个队列中c1和c3亚型的gsea气泡图;c为c1与c2、c1与c3、c2与c3的gsea归一化富集分数(ne)热图,纵轴表示不同的比较组,水平轴表示路径名称;d为metabric数据库中c1对c2和c2对c3相干激活的路径雷达图。
50.图10为metabric(a)、gse58812(b)、gse21653(c)队列中基于lr对的分子亚型中22个免疫细胞的估计比例;p值通过kruskalwallis检验计算,ns:p》0.05,*:p《0.05,**:p《0.01,***:p《0.001,****p《0.0001。
51.图11为metabric(a)、gse58812(b)、gse21653(c)队列中三种基于lr对的分子亚型之间的基质评分、免疫评分和估计评分;p值通过kruskalwallis检验计算,ns:p》0.05,*:p《0.05,**:p《0.01,***:p《0.001,****p《0.0001。
52.图12为6对lr的lasso-cox回归分析和拟合lasso-cox回归模型曲线。
53.图13为4对lr对应的cox回归模型中与这些预测因子相对应的系数图。
54.图14为代谢组群(a)、gse58812队列(b)和gse21653队列(c)中三种基于lr对的亚型的lr对分数图,kruskalwallis检验。
55.图15为基于kaplan-meier比较metabric队列(a)、gse58812队列(c)和gse21653队列(d)中具有不同lr对分数的样本的os估计结果,对数秩检验;以及时间依赖性roc曲线显示代谢组群中lr对分数的预测能力(b);ns:p》0.05,*:p《0.05,**:p《0.01,***:p《0.001,****p《0.0001。
56.图16为时间依赖性roc曲线显示gse58812队列(a)和gse21653队列(b)中lr对分数的预测能力。
57.图17为单变量(a)和多变量(b)cox回归的系数及其置信区间森林图,其中,包括代谢组中lr对分数、患者年龄、分期、分级和患者结局等的因素。
58.图18为lr对分数与免疫组成和免疫相关途径之间的相关性,其中,a为pearson相关分析kegg途径的ssgsea得分与metabric中的lr分数之间的结果,r》0.4;b为了metabric队列中高lr对分数和低lr对分数组中22个免疫细胞的相对丰度,wilcoxon检验;c为metabric队列中高lr对分数和低lr对分数组的估计免疫得分,wilcoxon检验;d为lr对分数与免疫细胞成分的皮尔逊相关分析;ns:p》0.05,*:p《0.05,**:p《0.01,***:p《0.001,****p《0.0001。
59.图19为lr对分数与免疫检查点基因表达的相关性,wilcoxon检验;ns:p》0.05,*:p《0.05,**:p《0.01,***:p《0.001,****p《0.0001。
60.图20为lr对评分模型与排除评分(a)、功能障碍评分(b)和tide评分(c)之间的相关性。
61.图21为imvigor210队列中完全反应(cr)/部分反应(pr)组和稳定疾病(pd)/进展性疾病(pd)组之间的lr对分数的差异性(a)和imvigor210队列中不同lr对分数组的生存曲线;ns:p》0.05,*:p《0.05,**:p《0.01,***:p《0.001,****p《0.0001。
62.图22为imvigor210队列中具有不同lr对分数的的患者对抗pd-l1治疗的反应,对数秩检验。
63.图23为lr对分数与药物敏感性之间的关系,其中,a为lr对分数与药敏曲线auc的相关性,spearman相关分析;b为不同lr对分数组之间紫杉醇、veliparib、olaparib和talazoparib的ic50估计值差异,wilcoxon检验;ns:p》0.05,*:p《0.05,**:p《0.01,***:p《0.001,****p《0.0001。
64.图24为其他lr对的4个样本下的示例性数据。
具体实施方式
65.为了使本发明的发明目的、技术方案及其技术效果更加清晰,以下结合具体实施方式,对本发明进行进一步详细说明。应当理解的是,本说明书中描述的具体实施方式仅仅是为了解释本发明,并非为了限定本发明。
66.所使用的实验材料和试剂,若无特别说明,均为常规可从商业途径所获得的耗材和试剂。
67.在本发明实施例中,其tnbc数据资源主要为通过bio cancer genomics portal(cbioportal)整理得到的metabric数据集(乳腺癌数据库)。metabric数据集是从cbioportal下载(http://cbioportal.org/)并进行可用性筛选。最终本发明中所使用的数据集中包括318个tnbc样本的基因组变异数据和298个样本的基序表谱(均来自metabric数据集),以及从基因表达综合数据库(gene expression omnibus,geo,https://www.ncbi.nlm.nih.gov/geo/)中的gse58812和gse21653数据集中收集得到的10783个tnbc样本的微阵列数据。
68.在本发明实施例中,各统计数据采用r 4.0.2软件进行分析。kaplan-meier生存曲线和受试者操作特征(roc)曲线分别通过“survminer”软件包和“time roc”可视化。lr评分和临床参数纳入cox比例风险回归,以确定预测tnbc预后的独立因素。p值截止值设置为0.05。
69.在本发明中,“lr对的表达量”是指该lr对中的两个基因的表达量之和,示例:“cxcl9-ccr3表达量”或“cxcl9-ccr3”是指cxcl9的表达量 ccr3的表达量。
70.在本发明中,各lr对或基因的检测可基于现有的检测试剂盒或检测产品进行定量检测,也可以采用本领域常规手段涉及引物和/或探针进行检测,本发明中的模型构建及评估效果并不受限制于检测产品的选择。
71.配体受体对的获得和筛选
72.发明人从文献管理数据库connectome db2020下载了2293个相互作用的配体-受体(lr)对用于lr的筛选。其中,筛选标准为:如果lr中的基因表达总和等于或大于所有患者lr基因表达总和的中位数,则将患者定义为高表达。否则,患者被定义为低表达。r数据包中的“生存(survival)”数据包用于分析每对lr与每个队列中tnbc患者生存率之间的相关性。通过gehan-wilcoxon检验的peto和peto修正分析统计显著性,并建立cox回归模型的指数系数来计算风险比(hr)。使用“metap”包中的“sump”函数以基于edgington方法整合不同队列的p值,并基于storey方法进行多项测试校正。
73.结果如下。
74.筛选流程图如图1a所示。
75.如上所述,发明人为了筛选与tnbc预后相关的lr对,对metabric、gse58812和gse21653进行lr对的生存分析,并将三个队列产生的lr组的预后显著性p值合并,进行meta分析,使用“metap”软件包中的“sump”函数,基于edgington方法对三个队列的p值进行积分,并使用“qvalue”软件包执行基于storey方法的多项测试校正。结果共筛选出了145对与tnbc预后相关的lr,其中44对lr对应预后不良,101对lr对应预后良好(图1b)。并针对这些与tnbc预后相关的lr对绘制了相互作用网络图(图1c)。
76.通过进一步将上述lr对纳入kegg,进行富集分析(图2)。结果发现,在145对lr中,主要有10条途径最为丰富,包括病毒蛋白与细胞因子和细胞因子受体的相互作用、细胞因子-细胞因子受体相互作用、粘附分子(cam)、趋化因子信号通路、iga产生的肠道免疫网络、类风湿关节炎、癌症中的蛋白多糖、疟疾、神经活性配体-受体相互作用以及造血细胞谱系。
77.基于共识聚类的lr亚型分型
78.根据tnbc预后相关lr对的表达情况,使用“共识聚类”对聚类进行分类。其中,指定k-means算法、“1-pearson相关”和聚类算法将每个样本分为k组,并使每个引导程序涉及
80%的样本,共500个重复。共识聚类的热图由r数据包“pheatmap”生成。聚类的数量由共识累积分布函数(cdf)图和delta面积图决定,标准为聚类内的一致性高,变异系数低,cdf曲线下的面积未有显著增加。
79.结果如下。
80.发明人采用上述方法检查了tnbc样本是否可以根据其预后相关lr对的表达模式的多样性区分出不同亚型(三种tnbc亚型)。其中,重要的预后相关lr对被纳入聚类模式中进行分析,每个lr对的表达丰度由配体和受体基因的表达总和表示。在metaric队列中,298个tnbc样本通过一致聚类分析进行聚类。在聚类数k的优化中,累积分布函数(cdf)曲线表明,k=3时产生了稳定的聚类结果(图3a和3b),因此k=3被选为最终选项(图3c)。
81.而后对预后特征的进一步分析表明,三种亚型之间的预后存在显著差异。c1的总生存率(os)最为不利,c3的os是三种亚型中最长的,c2的os介于两种亚型之间(图4)。此外,发明人在对gse58812和gse21653的tnbc患者队列应用了相同的分子亚型判定方法后,也形成了对应的三种分子亚型,并且在生存分析中观察到三种亚型之间的预后同样存在显著和相似的差异情况(图5a和5b)。
82.以下以adam28-itga4为例(表1)展示最终得到的矩阵,通过将受试者的数据带入该矩阵即可得到其聚类数据,根据聚类数据与本发明中的验证集聚类分型信息即可判断其分型。其他lr对的示例性数据可参考图24。
83.84.[0085][0086]
不同三阴性乳腺癌亚型间突变和拷贝数变异(cnv)分析
[0087]
基于cbioportal整合的基因组数据类型包括体细胞突变、拷贝数改变、基因表达
t细胞、幼稚cd4 t细胞、激活的cd4记忆t细胞、δ-γt细胞、静止和激活的nk细胞、m0巨噬细胞、m1巨噬细胞、m2巨噬细胞、静息的树突状细胞、活化的树突状细胞、静息和活化的肥大细胞、以及中性粒细胞(图10a)。在所有三个tnbc队列中的基于lr对的分子亚型中,幼稚b细胞、幼稚cd4 t细胞、活化cd4记忆t细胞、δ-γt细胞、激活nk细胞、m0巨噬细胞、m1巨噬细胞、m2巨噬细胞和活化的肥大细胞的估计比例存在显著差异(图10b和10c)。通过kruskalwallis检验比较各亚型间基质评分、免疫评分和估计评分。每个队列中的三个分子亚型之间的免疫评分显示出显著差异,p值均《0.01。每个队列中三个分子子型之间的免疫评分/估计评分也显示出高度的显著差异,p值均《0.0001。无论三个评分中的哪一个,c3始终》c2》c1(图11a、11b、11c)。
[0099]
基于lr对(lr pairs)的风险模型构建
[0100]
从与预后相关的lr对中筛选重要基因,构建风险模型。
[0101]
具体筛选步骤为:
[0102]
使用lasso惩罚的cox回归分析预后相关的lr对,通过减少模型参数的权重来消除不重要的lr对,得到初筛lr对。然后将初筛lr对通过mass软件包中的stepaic策略进行过滤。利用stepaic值最低的基因建立lr对评分模型,并通过多元cox回归分析获得每个基因的系数。
[0103]
结果如下。
[0104]
为了选择最适合预测tnbc预后的lr对,发明人对上述实施例中筛选出的145对lr对进行了lasso-cox回归分析,并在10倍交叉验证过程中共筛选出6对lr,因为它们在拟合的lasso-cox回归模型中呈现非零系数(图12)。通过stepaic多因素回归分析,最终选择了其中的4个lr对(cxcl9-ccr3、gpi-amfr、il18-il18r1和plg-f2rl1),该4对lr具有模型的统计拟合和用于拟合的参数数量。
[0105]
得到的模型公式为:
[0106]
lr对分数=-0.08996361
×
(cxcl9-ccr3表达量) 0.27093847
×
(gpi-amfr表达量)-0.29143116
×
(il18-il18r1表达量) 0.28034741
×
(plg-f2rl1表达量)。
[0107]
其中,“cxcl9-ccr3”是指cxcl9的表达量 ccr3的表达量,其他以此类推。
[0108]
本质上,上述对于每个患者的风险评分的模型公式是基于lr对分数=bate
×
expi得到的。其中,expi是指受配体i基因的表达水平,beta是多变量cox回归的特定基因的系数,通过进行zscore处理,以“0”作为阈值,即可将患者划分为高风险组(高lr对分数组)和低风险组(低lr对分数组)。但用于预后分析时,可进一步采用kaplan-meier法绘制生存曲线来直观表现出其预后风险情况,其中,采用对数秩检验确定差异的显著性。
[0109]
当然,需要理解的是,本发明实施例中所用的阈值本质上是一个连续性的变量,在需要进行等级资料划分时可以根据情况限定为一个cut off值。在本实施例中,阈值设定为“0”。
[0110]
cox回归模型中与这些预测因子相对应的系数如图13所示。基于上述4个lr对,构建了lr对评分模型和lr对分数,以用于定量分析tnbc样本的lr对模式。发明人还发现,在metabric、gse58812和gse21653队列中,c1亚型的lr对分数显著高于c2和c3亚型(图14a、14b、14c)。为了分析lr对的临床相关性,根据lr对分数将每个队列的tnbc样本分为两组。metabric队列中lr对分数低的患者显示出显著有利的生存结果(图15a)。lr对分数的时间
依赖性roc曲线的曲线下面积(auc)在1、3、5和10年时分别为0.72、0.63、0.65和0.66(图15b)。使用来自gse58812的107个样本和来自gse21653的83个样本进一步验证lr对分数的可靠性,发现在这两个验证集中,lr对分数高的样本显示出更高的死亡率和更短的生存时间(图15c、15d)。gses8812验证集中,lr对评分模型的auc值在3年、5年和10年时分别为0.72、0.75和0.67(图16a)。lr对评分模型在gse21653验证队列中表现更佳,对应于1年、3年和5年生存期的auc分别为0.90、0.87和0.78(图16b)。
[0111]
此外,metabric中的单变量cox回归模型分析表明,分期、年龄和lr对分数与tnbc的预后显著相关(图17a)。且在多变量cox回归模型中,这些预后因素均可以被视为tnbc的独立预后因素(图17b)。
[0112]
lr对分数与免疫组成和免疫相关途径之间的相关性
[0113]
为了找出与lr对分数最相关的途径。发明人进一步使用r软件包中的“gsva”对metabric样本进行分析。
[0114]
结果如下。
[0115]
通过“gsva”获得了具有不同功能的metabric样本的单样本gsea(ssgsea)得分,并通过pearson相关分析获得了30条与lr对分数显著相关的途径。其中,2条通路与lr对分数呈正相关,28条通路与lr对分数呈负相关。免疫相关途径(如趋化因子信号通路、抗原处理和呈递、自然杀伤细胞介导的细胞毒性、toll样受体信号通路、自然杀伤性细胞介导细胞毒性和t细胞受体信号通路)的ssgsea评分与lr对分数呈显著负相关(图18a)。而进一步分析lr对分数与肿瘤免疫成分之间的关系,发现22种免疫细胞中至少有一般在高lr对分数样本和低lr对分数样本之间存在显著差异(图18b)。
[0116]
此外,lr对分数与免疫细胞之间的皮尔逊相关分析表明(图18c),lr对分数与cd8 t细胞、活化的cd4记忆t细胞和巨噬细胞存在显著负相关,但与m0巨噬细胞和m2巨噬细胞正相关(图18d),说明lr对分数与肿瘤免疫之间存在关联。
[0117]
lr对评分模型在预测临床治疗反应中的效果
[0118]
通过wilcoxon检验确定lr对分数值与免疫检查点中基因表达水平之间的关系,并生成方框图以实现可视化。肿瘤免疫功能障碍和排斥(tide)则是通过模拟两种免疫逃逸机制的准确基因特征来预测样本的免疫检查点阻断(icb)治疗反应。
[0119]
发明人从癌症药物敏感性基因组学(gdsc)下载了约1000个癌症细胞系的药物敏感性数据(http://www.cancerrxgene.org,gdsc是关于癌细胞药物敏感性和药物反应分子标记的最大公共资源平台),其中,主要针对乳腺细胞系的数据进行下载,得到了共50个用190种药物治疗的细胞系数据。以肿瘤细胞系中抗肿瘤药物的曲线下面积(auc)值作为药物反应指数,使用spearman相关分析来计算药物敏感性与lr对分数值之间的相关性。使用benjamin和hochberg方法计算调整后的fdr。rs绝对值》0.2且fdr《0.05的相关性被认为具有统计学意义。此外,在不同的lr对评分组中,使用prrophetic软件包比较了推荐性抗肿瘤药物紫杉醇、veliparib、奥拉帕尼(olaparib)和他拉唑帕尼(talazoparib)在tnbc治疗中的最大抑制浓度(以半抑制浓度ic50计)。
[0120]
结果如下。
[0121]
结合上述实施例中公开的lr对分数与肿瘤免疫之间的关联,发明人进一步分析了lr对分数与免疫检查点基因之间的关联。就表达水平而言,19个免疫检查点中的18个显示
出两个lr对评分组之间存在差异,高lr对分数组有更大的反应(图19)。与低lr对分数组相比,高lr对分数也显示出显著上调的t细胞排斥评分和显著下调的t细胞功能障碍评分,而tide评分在两组之间没有显着差异(图20)。
[0122]
进一步地,发明人在免疫治疗队列imvigor210(抗pd-li)中,检查了lr对分数预测免疫检查点抑制剂(ici)治疗反应的能力。发现与完全应答(cr)和部分应答(pr)的样本相比,稳定疾病(sd)和进行性疾病(pd)的样本具有显著更高的lr对分数(图21a)。将经抗pd-l1治疗的样本分为低lr对分数组和高lr对分数组。在imvigor210队列中,lr对分数高的样本的预后仍明显差于lr对分数低的样本(图21b)。lr对分数低的患者对抗pd-l1治疗反应积极的比例显著高于lr对分数的患者(图22)。
[0123]
gdsc数据库存储有各种抗癌药物的治疗反应数据,以及大量癌症细胞系的基因表达谱。发明人通过对gdsc数据进行spearman相关分析,发现lr对分数与29种药物的治疗反应显著相关,具体关系如药物敏感性曲线下面积(auc)所示。其中,28个相关对(lr对)为阳性,表明肿瘤中的高lr对分数与其对这些药物的耐药性有关(图23a)。此外,通过比较了两个lr对分数组中紫杉醇、veliparib、奥拉帕尼(olaparib)和他拉唑帕尼(talazoparib)的ic50估计值,发现低lr对分数组中四种药物的ic50值显著低于高lr对分数组,表明低lr对分数组可能对四种药物治疗更敏感(图23b)。
[0124]
综上所述,通过对2293对lr进行tnbc生存分析,发明人共筛选出145对与tnbc预后显著相关的lr对,然后根据145个lr对的表达情况,采用了无监督聚类的方式获得了tnbc的三个lr对亚型。在这三种lr对亚型中,c1亚型预后最差,其中最具侵袭性的乳腺癌亚型——basal-like亚型在c1亚型组中的比例显著高于其他两组,相应的该组临床特征中死亡比例最高。此外,c1亚型组显示出最低的抗肿瘤免疫反应,如较低的肿瘤浸润淋巴细胞(幼稚b细胞、cd8 t细胞、幼稚cd4t细胞)、基质评分和免疫评分,这些可能是c1亚型预后不良的原因。
[0125]
此外,除了基于145对lr对tnbc进行分型外,本发明中还对145对lr对进行了lasso回归和cox分析,并选择4对lr对构建lr对评分模型。该lr对评分模型对于预后评估的意义在tcga和两个地理数据集中均得到证实。在该模型中,与低lr对分数的样本相比,高lr对分数的样本显示出显著更短的生存时间。在本领域中,公知趋化因子信号通路通过募集免疫细胞促进免疫系统的抗肿瘤反应;抗原加工和呈递作为适应性免疫应答的启动,在抗肿瘤免疫中起着关键作用;t细胞受体信号通路的强度是t细胞介导的抗肿瘤反应的关键决定因素;自然杀伤细胞介导的细胞毒性是免疫系统对抗癌症的重要效应机制;以及toll样受体信号通路的激活可用于增强针对恶性细胞的免疫应答等。而本发明验证发现lr对分数不仅与趋化因子信号通路、抗原处理和呈递、t细胞受体信号通路、自然杀伤细胞介导的细胞毒性、toll样受体信号通路、自然杀伤细胞中介的细胞毒性和t细胞受体信号通路呈显著负相关,而且还能体现出基质评分、免疫评分、以及cd8 t细胞、活化的cd4记忆t细胞和巨噬细胞的浸润情况。此外,高lr对分数和低lr对分数之间的tide得分没有显著差异,免疫逃逸可能对lr对分数没有显著影响。综合考虑所有上述结果,可以认为具有高lr对分数的tnbc样品没有强的抗肿瘤免疫性。
[0126]
癌细胞表达的不同配体与免疫细胞上的细胞表面受体结合,触发抑制途径(如pd-1/pd-l1)并促进免疫细胞免疫耐受。在本发明中,发明人利用抗pd-l1队列验证了4个lr对分数(基于lr对评分模型)预测免疫检查点抑制剂(ici)治疗反应的能力。发现疾病完全缓
解或部分缓解患者的lr对分数显著低于疾病稳定或进展患者。低lr对分数组抗pd-l1治疗的临床获益显著大于高lr对分数组,这印证了lr对评分模型预测抗pd-l1治疗的有效性。
[0127]
一些分子靶向抗肿瘤药物可以预防癌症的免疫治疗耐药性,但仅应用单一药物治疗并非能起到稳定的治疗效果,而将这些抗肿瘤药物与ici免疫治疗相结合,可以大大改善患者的预后。在本发明实施例中,发明人通过spearman相关分析在gdsc数据库中确定了29对lr对得分和药物敏感性,其中28对药物敏感性曲线显示auc和lr对分数之间存在显著正相关(只有wnt-c59表现出与lr对分数相关的敏感性)。这表明他们表现出与lr对分数相关的耐药性,基于对于这些lr对进行靶向药物开发能够有效得到高效的抗耐药性药物。
[0128]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。