:
1.本发明属于计算机视觉领域,尤其涉及基于小规模样本数据集的高质量图像的生成方法。
背景技术:
2.随着图像处理技术和计算机水平的发展,利用高质量图像可以极大的提高应用的准确性和预测性,改变了使用传统小图像导致精确度不高的模式。高精度的成像设备采集到的图像质量越来越高,使得图像中包含大量的信息以及更多的细节。在遥感、医学等领域,高质量图像的标注数据集十分的稀缺、昂贵,故而通常会面临样本少、无资源等问题。因此得到一个可以应用在小样本领域的分类器或者识别器是非常有挑战性的工作。
3.近年来,随着神经网络的广泛使用,对于各种类型数据集都得到了深入的挖掘。最早对于小样本的扩充是对数据集进行随机翻转、旋转、裁剪、变形缩放、添加噪声、颜色扰动等方法。截至目前,基于小样本数据集的学习方法主要的研究思路分为三个方向,分别是基于模型微调的小样本学习,基于数据增强的小样本学习,基于迁移学习的小样本学习。在基于模型微调的小样本学习方法中,通常在大规模数据中进行预训练模型,在目标的小样本数据集上对神经网络模型的全连接层或者顶端的几层进行参数微调。但是模型微调的方法比较简单,在真实场景中目标数据集和源数据集往往并不类似,并且得到的模型比较容易在目标数据集上产生过拟合。为了解决过拟合问题,提出了基于数据增强和基于迁移学习的方法。在基于数据增强的小样本学习方法中,主要借助辅助数据或者辅助信息对原本的数据集进行扩充或者特征增强。但是传统数据增强方法在提高样本多样性上具有一定的限制。在基于迁移学习的小样本学习中,是指利用旧知识来学习新知识来将已学会的知识很快的迁移到新的领域中。但是迁移学习方法的准确度过度依赖源领域和目标领域之间的关联性。
4.考虑到遥感、医学等小样本领域面临的三个挑战:数据量较少、算法跨中心泛化能力差和准确度要求较高,本发明提出一种基于多尺度生成对抗网络的小样本高质量生成方法。首先构建基于生成对抗网络(generative adversarial networks,gan)的图像生成模型。然后利用图像生成模型构建多层尺度的模型,利用不同大小的图像作为输入,在不同尺度下进行生成对抗,学习不同尺度下图像的分布。最后得到清晰的生成图像,实现小样本的高质量生成。
技术实现要素:
5.本发明提出一种基于多尺度生成对抗网络的小样本高质量生成方法,使用多个生成对抗网络结构分别学习了不同大小图像中图像块(patch)的分布,将每个图像块看作成一个图像,因此可以利用小样本数据集从粗糙到细致、从低分辨率到高分辨率逐步生成真实图像。
6.本发明的基于多尺度生成对抗网络的小样本生成方法,首先,利用生成对抗网络
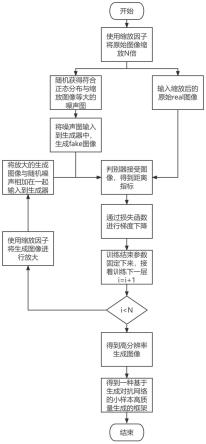
训练图像生成模型,其中生成器是由多个卷积层构成的全卷积神经网络(convolutional neural network,cnn),全卷积网络较之于传统带有全连接网络的训练更加高效,避免了由于使用像素块带来的重复存储和计算卷积的问题;其中判别器也是由多个卷积层构成的全卷积神经网络也可称马尔可夫判别器,输入图像通过多个卷积层得到的输出矩阵中每个数据代表着原输入图像中的一个感受野,对应了图像的一片区域,判别器因此可以拉近生成图像和真实图像在各个区域上的距离实现整体分布的拟合,依据此原理实现图像的增广。然后利用图像生成模型构建多尺度模型,每一层尺度下都会接收不同尺寸大小的图像,从低到高依次增大。待第一层尺度训练完毕后,图像生成模型会学习到第一层尺度下图像大小的轮廓细节。将第一尺度下生成的图像放大后传入到第二层尺度,放大后的图像较之于第二层尺度下的训练数据集图像会有失真不清晰的现象,所以第二层尺度的图像生成模型就是学习传入图像放大后中缺失的细节信息。逐步增加尺度,最后得到清晰的生成图像。本方法主要过程如附图1所示,可分为三个步骤:图像生成模型构建、多尺度模型构建、逐层生成图像。
7.(1)图像生成模型构建
8.图像生成模型由生成器、判别器组成。各层生成器的输入包括两个部分,一个是当前层的随机噪声,一个是来自上一层的放大图像,利用残差思想,将放大后的输入图像不仅作为输入,也会和网络输出相加作为最终的输出,让生成器仅仅去学习缺失的细节,间接的降低生成器的学习难度。由全卷积神经网络组成的马尔可夫判别器,采用该结构进行训练,既拓展了样本数量,又保留了各个样本之间的关联性。
9.(2)多尺度模型构建
10.每一层都是由单独的一个图像生成模型组成,第一层尺度生成的图像大小与缩小一定倍数的原图相同,小图像中无法获得太多细节,所以在第二层尺度中生成的图像较之第一尺度要大,直到达到所需的大小。
11.(3)逐层生成图像
12.除了第一层尺度的图像生成模型是学习生成完整图像,其余尺度的图像生成模型都是学习填补来自上一尺度放大后的生成图像丢失的细节。逐步生成图像使多尺度模型可以生成较大的高质量图像。
13.本发明与现有技术相比,具有以下明显的优势和有益效果:
14.1、使用全卷积神经网络构建的生成器可以处理任意尺寸大小的图像,不需要为每一层尺度单独设计模型。基于全卷积神经网络构建判别器,采用该结构进行训练,在原理上既拓展了样本数量,又保留了各个样本之间的关联性。
15.2、构建的多尺度结构,在每一层尺度上只是学习由上一尺度传来图像放大后缺失的细节信息,层层递进给生成高分辨率图像创造了可行性。
16.实验证实,利用多尺度生成对抗网络进行训练,可以在breakhis数据库上实现38.41593的fid(fr
é
chet inception distance),该指标表示生成图像的多样性和质量,fid越小,则图像多样性越好,质量越好。因此,该方法在小样本数据集任务中,有着重要的应用价值。
附图说明:
17.图1为本发明所涉及方法的流程图;
18.图2为第一层尺度下生成器结构图;
19.图3为第一层尺度下判别器结构图;
20.图4单尺度下图像生成模型网络结构图;
21.图5为多尺度生成对抗网络网络结构图;
22.图6最终生成图像示例;
具体实施方式:
23.以下结合具体实施例,并参照附图,数据集从breakhis数据库中进行选取,对本发明进一步详细说明。
24.步骤1:第一层尺度图像生成模型的构建
25.步骤1.1:基于全卷积神经网络的生成器构建
26.本发明提出的基于多尺度生成对抗网络的小样本高质量生成的方法基于当前主流深度学习框架pytorch实现,本步骤中生成器具体结构图见附图2。第一层尺度生成器的输入为符合期望值为0,标准差为1的正态分布的噪声图,卷积前噪声图在上下左右各填充(padding)5行,经过5个卷积层进行卷积,卷积核大小皆为3
×
3,步长皆为1,卷积过程中不进行填充,前4个卷积层通道数全是32,都采用批量归一化(batch normalization),它将对后续激活函数的输入进行归一化,使得数值更加稳定,批量归一化后将采用带泄露修正线性单元(leaky rectified linear unit,relu)作为激活函数,控制负斜率的角度设置为0.2,使模型收敛更快。第5个卷积层通道数为3,采用双曲正切函数(tanh)作为激活函数,将输出的数值范围定在-1至1之间。噪声图通过5层卷积后会得到一个与其等大的生成图像,将作为第一层尺度判别器的输入和下一层尺度生成器的输入。
27.步骤1.2:基于全卷积神经网络的判别器构建
28.本步骤提出的判别器具体结构图见附图3。判别器的输入为真实图像或者生成图像,经过5个卷积层,卷积核大小皆为3
×
3,步长皆为1,卷积过程中不进行填充,前4个卷积层通道数全是32,都采用批量归一化,批量归一化后将采用带泄露修正线性单元作为激活函数,控制负斜率的角度设置为0.2。第5个卷积层通道数为1,不添加激活函数。图像通过5层卷积后会得到一个1维矩阵,将矩阵中所有元素的均值作为距离指标,作为后续损失函数的输入。
29.步骤2:多尺度模型构建
30.多层尺度模型结构见附图5,其中g表示生成器,d表示判别器,z表示噪声图,f表示生成图像,r表示真实图像。
31.步骤2.1:确定尺度n的数量
32.在breakhis数据集中,原始图像数据集的分辨率大小为700
×
460;在模型中各尺度图像的输入最小尺寸不能低于32,最大尺寸不能高于256;因此通过缩放将原始数据集图像长宽按等比例缩放至256
×
168,该大小也会作为最高尺度的输入尺寸大小;在模型中各尺度之间的缩放因子r定为0.75;通过缩放因子r从高到低计算出各尺度的图像输入大小256
×
168,192
×
126,144
×
95,108
×
72,81
×
54,61
×
41,继续向下最小尺寸会低于32,共有
6层尺度,所以尺度n设置为6;
33.步骤2.2:除第一层尺度外,其余尺度图像生成模型构建
34.第二层包括第二层以上的尺度都需要接收来自上一尺度的生成图像,具体图像生成模型结构见附图4。第n层尺度的生成器的输入为符合标准正态分布的噪声图zn和来自n-1层尺度生成器生成的图像f
n-1
。在输入网络前先通过1/r乘上f
n-1
对图像进行放大,得到放大的生成图像f
n-1r
。将f
n-1r
和zn分别在上下左右各填充5行,相加后输入到5层卷积网络中,其中5个卷积层,卷积核大小皆为3
×
3,步长皆为1,卷积过程中不进行填充。前4个卷积层通道数全是32x(pow(2,n//4)),其中“//”是一个算术运算符,表示整数除法,它可以返回商向下取整的整数部分,pow函数用于进行求幂运算2为底数,n//4为指数。整体表示每隔4个尺度,通道数就翻倍,所以从第1到第7尺度通道数分别为32,32,32,32,64,64,64。第5个卷积层通道数为3,采用双曲正切函数作为激活函数,将输出的数值范围定在-1至1之间。最后网络的输出结果会与f
n-1r
相加得到的生成图像fn,fn会作为判别器的输入和下一尺度生成器的输入。
35.第n层尺度的判别器的输入为真实图像或者生成图像,经过5个卷积层,卷积核大小皆为3
×
3,步长皆为1,卷积过程中不进行填充,前4个卷积层通道数全是32x(pow(2,n//4)),都采用批量归一化,批量归一化后将采用带泄露修正线性单元作为激活函数。第5个卷积层通道数为1,不添加激活函数。图像通过5层卷积后会得到一个1维矩阵,将矩阵中所有元素的均值作为距离指标,作为后续损失函数的输入。
36.步骤3:逐层生成图像
37.步骤3.1:通过损失函数进行动态博弈,在博弈开始前先对判别器预训练2000轮,在博弈阶段判别器连续训练3次,生成器连续训练3次,这样可以避免生成器在优化的过程中梯度过小的问题。优化的过程是通过损失函数进行。损失函数分为2个部分:对抗损失、重建损失。整体损失函数公式如下:
[0038][0039]
其中d为判别器,g为生成器。为在对生成器进行优化时最小化损失函数,对判别器进行优化时最大化损失函数。l
adv
(g,d)为对抗损失,如公式(2)所示。l
rec
(g)为重建损失,如公式(4)所示。本发明中重建损失权重系数
∝
rec
设置为10,具有通用性。
[0040]
对抗损失l
adv
(g,d)具体公式如下:
[0041][0042]
其中对抗损失采用的是wgan-gp损失以提高模型的稳定性,防止模式崩塌。d(x)是判别器输入图片为x时图片为真的概率,表示d(x)的数学期望,其中x服从真实图像数据的概率分布p
data
(x);d(g(z))是当g(z)生成器输入某个隐空间时得到生成图像,判别器判别该图为真的概率,表示d(g(z))的数学期望,其中z服从正态分布噪声的概率分布pz(z);服从分布x,公式如(3)所示,α为-1至1之间的随机数,是在真实图像和生成图像之间做线性差值。为在上的梯度,
即相对于原始输入的梯度的l2范数要约束在1附近的数学期望;λ为梯度惩罚因子,本发明中λ取值为10,具有通用性。
[0043][0044]
重建损失l
rec
(g)具体公式如下:
[0045][0046][0047]
其中n表示当前尺度的层数,x1和xn分别是第1个尺度和第n尺度下的真实图像,它在整个训练过程中保持不变。和分别是第1个尺度和第n尺度下的重建图像,如公式(5)所示,其中z
*
是第1个尺度下输入的噪声图,对于所有的真实图像都会有一个固定的z
*
,它在整个训练过程中保持不变。g1(z
*
,0)表示第1层尺度下的生成器输入z
*
噪声图后得到的重建图像到的重建图像表示第n个尺度下生成器输入为放大1/r倍的第n-1尺度的重建图像后生成重建图像度的重建图像后生成重建图像和表示重建图像和真实图像差值的2范数,相当于重建图像采用均方误差和真实图像进行对比。最小化重建损失可以在一定程度上让随机生成的图像尽可能的拟合真实图像,控制生成图像的发散性。发散性由重建损失权重系数
∝
rec
控制。
[0048]
随后,生成器通过最小化损失函数进行训练,判别器通过取损失函数相反数后最小化损失进行训练。皆采用adam(adaptive moment estimation)优化算法,本发明中将学习速率设为0.0005,一阶矩估计的指数衰减率设为0.5,二阶矩估计的指数衰减率设为0.999,动态学习率调整为每隔2000次迭代学习率变为之前的0.1倍。共进行24000次的迭代。
[0049]
步骤3.2:随后从低到高逐一进行训练,直到所有尺度训练完毕,形成一个基于多尺度生成对抗网络的小样本高质量生成框架。
[0050]
步骤3.3:检测结果评价
[0051]
使用基于fid(fr
é
chet inception distance)指标对生成的图像进行评价。fid在数学上的含义为计算两个分布之间的距离,距离越小代表生成图像分布越贴近于真实图像分布,最佳情况下的得分为0.0,表示两组图像相同。该指标可以表示生成图像的多样性和质量,fid越小,则图像多样性越好,质量越好。fid计算公式如(6)所示。
[0052]
fid=||μ
r-μg||2 tr(σr σ
g-2(σrσg)
1/2
)
ꢀꢀꢀꢀ
(6)
[0053]
在fid中通过预训练的inception v3来提取全连接层之前2048维向量作为图片的特征,本发明中的inception v3模型及其权重由pytorch 1.12.1提供。在公式(6)中,μr表示真实图片的特征均值,μg表示生成图像的特征均值,σr真实图片的特征的协方差矩阵,σg生成图像的特征的协方差矩阵。tr()表示求矩阵的特征值之和。
[0054]
随机抽取9张生成图像作为展示,见附图6。
[0055]
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。