1.差分隐私(differential privacy(dp))是密码学中的一种手段,保证数据查询在结果上不可区分是否存在某一条记录,从而提供了强大的隐私保障:任何人在查询数据集时,无法从数据中了解任何有关个人的信息。本发明涉及差分隐私系统的部署方法,特别涉及一种基于可编程交换机的差分隐私大数据处理方法。
背景技术:
2.近年来,随着互联网和云计算的快速发展,大规模的用户将个人数据提交给云计算平台,由不受信任的第三方分析以获得有用的信息并为用户提供更好的服务。由于分析的数据通常是个人的和敏感的,如果缺乏有效的保护措施,数据隐私可能会泄露。基于差分隐私的隐私保护特性,可以向数据集中添加扰动以混淆恶意分析者,阻止其分析获得个人隐私信息。在大规模数据处理的背景下,差分隐私被部署在一些著名的框架中,例如,部署在hadoop和spark中,并构建一个实用的系统,允许不信任的第三方分析数据的同时提供隐私保证。
3.随着数据量快速增长,上述系统需要实时处理这些高速大量的数据,使其达到差分隐私的要求,然而这一过程带来了巨大的开销。如何低开销、高效率地在上述框架中实现差分隐私保护,构建实用的系统,成为了差分隐私在实际部署中的难点。在大数据的场景下实现差分隐私保护时,现有的系统实施方案存在如下三个问题:
4.1)cpu周期开销问题:生成噪声以及对数据添加扰动的过程消耗cpu周期,降低了整体的吞吐量。
5.2)网络带宽问题:在执行敏感度计算时产生大量不必要的流量,导致拥塞和高时延。
6.3)隐私预算问题:每次分析者执行查询都需要计算并扣除隐私预算,而隐私计算的方法是容易出错且效率低下的,导致数据利用率低,也带来了很高的维护成本。
技术实现要素:
7.针对现有技术的不足,本发明公开一种基于可编程交换机的差分隐私大数据处理方法,该方法基于可编程交换机,能够在大数据场景下加速差分隐私计算,减少网络流量并实现隐私预算的自动配置。
8.本发明采用的技术方案具体如下:
9.一种基于可编程交换机的差分隐私大数据处理方法,包括以下步骤:
10.步骤一:收集每一数据的键值对信息,并逐一检查收集的每一数据的键值对信息是否在预定义范围内;
11.步骤二:在可编程交换机控制平面生成一组随机分布的噪声值,并将其预加载到可编程交换机的数据平面的有状态内存中;然后生成一个随机数,从该随机数索引的有状态内存中采样噪声;将采样的噪声加入到步骤一处理获得的尚未添加噪声的数据中,获得
满足差分隐私的数据并转发至规约器,规约器对其中不在预定义范围内的数据用预定义范围的平均值替换对应数据,所有数据聚合后输出结果。
12.进一步地,所述步骤一包括以下子步骤:
13.(1.1)在可编程交换机的数据平面部署cm-sketch算法,收集全部基于映射器提取的每一数据的键值对信息;
14.(1.2)逐一检查收集的每一数据的键值对信息是否在预定义范围内,若在预定义范围内,继续执行步骤二;若超出预定义范围,则基于哈希表或精确表检查该数据是否第一次出现,若是第一次出现,则交换机将该超出预定义范围的数据的键汇集到哈希表或精确表中,继续执行步骤二;否则,丢弃该数据。
15.进一步地,所述步骤(1.2)具体为:
16.在可编程交换机数据平面创建一张哈希表和一张精确表,逐一检查收集的每一数据的键值对信息是否在预定义范围内,若在预定义范围内,继续执行步骤二;若超出预定义范围,则基于哈希表或精确表检查该数据是否第一次出现,若是第一次出现,则哈希表在o(1)的时间复杂度内记录键,如果存储时发生哈希冲突,则将该键上报可编程交换机控制平面,可编程交换机控制平面将这些冲突的键插入到精确表中,继续执行步骤二。
17.进一步地,所述步骤二包括以下子步骤:
18.(2.1)在可编程交换机控制平面中生成一组随机分布的噪声值;
19.(2.2)将生成的一组随机分布的噪声值预加载到可编程交换机的数据平面的有状态内存中;
20.(2.3)基于数据的键和数据表查询每一数据是否被噪声扰动,若数据表中存在该键,即该数据已被扰动,则该数据被转发至规约器;若数据表中不存在该键,即该数据未被扰动,则生成一个随机数,从该随机数索引的有状态内存中采样噪声;将采样的噪声加入到该数据的值中,再将该数据的键汇集到数据表中并转发该数据至规约器;所述数据表包含全部被扰动的数据的键。
21.进一步地,所述步骤(2.1)中,所述一组随机分布的噪声值为符合拉普拉斯分布的噪声值。
22.进一步地,所述步骤(2.2)中,所述有状态内存采用寄存器数组的实现方式,其中,左移生成的每个噪声值缩放为整数再预加载到寄存器中。
23.进一步地,所述步骤(2.3)中,在扰动数据时,对映射器输出的数据的键值对移动相同比例,并添加采样的移动后的噪声值到该移动相同比例的数据的值中,将添加噪声后的数据的键汇集到数据表中之后转发至规约器,其中,转发时将移动的比例封装在分组报头中,报头也被进一步转发到规约器,规约器将经过缩放且加噪声的数据右移以恢复缩放比例,规约器对其中不在预定义范围内的数据用预定义范围的平均值替换对应数据,所有数据聚合后输出结果。
24.进一步地,还包括运用布隆过滤器记录输出键值和映射器的依赖关系,通过查询所有输出键的依赖关系计算隐私预算。
25.进一步地,运用布隆过滤器记录输出键和映射器的依赖关系,通过查询所有输出键的依赖关系计算隐私预算具体为:
26.a、将布隆过滤器划分为多个分区与每个映射器对应,记录各映射器输出过的键,
即键与映射器的依赖关系;
27.b、运用布隆过滤器统计各分区相应的映射器输出的键数量;
28.c、根据获得的各分区相应的映射器输出的键数量的最大值计算隐私预算。
29.在可编程交换机部署布隆过滤器能够加速计算需要扣除的隐私预算的过程。
30.本发明的有益成果是:
31.(1)利用线速数据包处理asic流水线加速差分隐私的计算,显着减少cpu周期的消耗;(2)通过聚合网络流量并除去不必要的操作减少网络流量开销;(3)通过可编程交换机自动化隐私审计。本发明在网内部署差分隐私系统,加速差分隐私计算,提高cpu吞吐量,减少网络流量和隐私审计的开销,解决大数据场景下实现差分隐私保护带来开销过大的问题。
附图说明
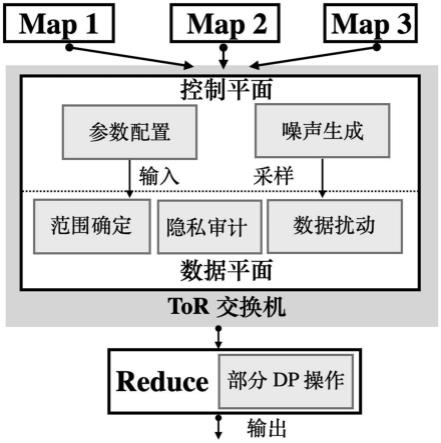
32.图1为本发明的架构示意图;
33.图2为范围确定的工作过程示意图;
34.图3为数据扰动的工作过程示意图;
35.图4为隐私审计的工作过程示意图;
具体实施方式
36.下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
37.本发明的一种基于可编程交换机的差分隐私大数据处理方法,基于可编程交换机实现,其系统架构如图1所示,其中,主要包括映射器map,用于获取每一数据的键值对;可编程交换机,用于基于映射器获取的数据的键值对,将数据限制在预定义范围内同时对数据进行扰动,规约器reduce,用于输出最终的满足差分隐私的数据。本发明方法主要包括以下步骤:
38.步骤一、范围确定:将系统输出限定在预定义范围内,如图2所示,具体步骤如下:
39.(1.1)执行原语sketch_val,在可编程交换机的数据平面部署cm-sketch算法,使用cm-sketch记录全部基于映射器提取出来的每一数据的键值对信息,转到步骤(1.2)。
40.(1.2)执行原语pool_kv,将超出预定义范围的键汇集到哈希表中,其中,若发生哈希冲突,则将该键上报交换机控制系统(可编程交换机的控制平面),并存储在精确表中。具体地,在可编程交换机数据平面创建一张哈希表和一张精确表,记录超出预定义范围的键。哈希表在o(1)的时间复杂度内快速记录键,如果存储时发生哈希冲突,则将该键上报交换机操作系统(即交换机的控制平面),交换机操作系统将这些冲突键的信息插入到精确表中。
41.(1.3)执行原语check_ran,检查键值是否在预定义范围内,若在预定义范围内,则进入步骤二;对超出范围的键值信息,则基于步骤(1.2)收集的哈希表或精确表检查该数据是否第一次出现,若是第一次出现,则基于步骤(1.2)交换机存储并转发该键值对信息,转入步骤二,否则,丢弃该数据包。
42.步骤二、数据扰动:根据计算得到的敏感度等参数随机生成噪声,在输出的隐私数
据中加入噪声后生成最终的输出值,如图3所示,具体步骤如下:
43.(2.1)执行原语gen_noise,根据预先设定的参数包括所需生成的噪声分布所需的敏感度数值、输出范围、特定分布模型等,生成所需的随机噪声分布,转到步骤(2.2)。作为一种实施方案,可以通过拉普拉斯算法生成噪声,公式如下:
[0044][0045]
参数说明:
[0046]
i.b为噪声参数,其中s为敏感度,ε为隐私预算参数,x是噪声值。
[0047]
ii.敏感度s由步骤一种预定义的范围确定得出。
[0048]
iii.ε由计算平台设定。
[0049]
(2.2)执行原语pool_noise,将噪声汇集到可编程交换机的数据平面的有状态内存中,转到步骤(2.3)。具体地,以寄存器数组实现有状态内存,由于可编程数据平面中的寄存器仅存放整数值,因此针对浮点型的噪声值,首先左移控制平面中产生的每个噪声值以缩放为整数,再预加载到寄存器中。
[0050]
(2.3)对于每个提取出来的键执行原语query_kv,首先查询数据表该键对应数据是否被噪声扰动。若被扰动,则值被转发至规约器,转到步骤(2.5);否则未被扰动的值将被转到步骤(2.4)添加噪声。
[0051]
(2.4)执行原语sam_noise、add_noise,基于随机数索引从寄存器阵列中随机采样噪声,并将噪声加到该值,转到步骤(2.5)。对于从寄存器中采样的噪声,在扰动数据时,对映射器输出的数据的键值对移动相同比例,并添加采样的移动后的噪声值到该移动相同比例的数据的值中,转到步骤(2.5)。
[0052]
(2.5)执行原语pool_kv,将已被扰动的数据的键汇集到数据表中。然后转发至规约器;其中,转发时将移动的比例封装在分组报头中,报头也将被进一步转发到规约器,规约器将经过缩放且加噪声的数据右移以恢复缩放比例;对于键存储在哈希表或精确表中的超出预定义范围的数据,规约器还执行原语repl_val,用预定义范围的平均值替换超过输出范围的键值对的数据作为最终的输出,使得所有数据均在预定义范围内。
[0053]
此外,本发明还包括隐私审计:根据映射器输出键的数量计算并扣除隐私预算,具体步骤如下:
[0054]
a、执行原语update_bf,将布隆过滤器划分为多个分区与每个映射器对应,记录各映射器输出过的键,即键与映射器的依赖关系,转入步骤(b)。
[0055]
b、执行原语get_priv_cost,查询布隆过滤器,获取键信息与映射器的依赖关系,统计各分区输出的键数量,转入步骤(c)。
[0056]
c、执行原语acct_bdg,根据步骤(b)获得的各分区输出的键数量的最大值计算隐私预算,转入步骤(d)。所述计算需要扣除的隐私预算方法为,
[0057]
pb=ε
×n[0058]
其中,pb为需要扣除的隐私预算,ε为计算平台设定的隐私预算参数,n为各分区输出的键数量中的最大值。
[0059]
d、执行原语ded_bdg,扣除步骤(c)计算得到的隐私预算。
[0060]
本发明基于哈希映射的思想,运用布隆过滤器记录各映射器输出过的键值信息,
布隆过滤器保证查询结果只存在假阳性,即只存在误报,不存在漏报,因此扣除的隐私预算不会偏少,从而能够保护用户隐私。为承担对每个键执行哈希映射带来的巨大计算开销,本发明部署布隆过滤器到可编程交换机上,并进行相应的硬件优化,加速记录键值和映射器依赖关系的过程。
[0061]
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。