1.本发明涉及一种语音降噪的训练方法、语音降噪系统及语音降噪方法。
背景技术:
2.在交互式的实时语音应用中,信号采集通常会带有非目标说话人的噪声,这些噪声会严重影响交互中的语音品质,从而降低了例如语音对话,语音会议等场景中的用户体验,因此语音降噪是交互式语音应用中不可缺少的一部分。
3.噪声按照时间变化的特性,可以分为稳态噪声和非稳态噪声。一般声音强度起伏小于lodb的连续噪声被认为是稳态噪声,而起伏大于1odb的连续噪声和脉冲噪声被认为是非稳态噪声。在传统的语音降噪中,通常在时频域利用统计学模型对语音和噪声进行建模,从而去除噪声,由于稳态噪声的频率比较固定,因此具有较好的效果,但这种方式对非稳态噪声的去除存在一定的局限性。例如,当估计的背景噪声过小,则会有噪声残留,残余的噪声会形成“音乐噪声”,如果估计的背景噪声过大,则会导致语音被消除。
4.深度学习(dl,deep learning)是机器学习(ml,machine learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(ai,artificial intelligence)。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术,因此,基于深度学习的语音降噪方法对稳态和非稳态效果均有比较好的效果。
技术实现要素:
5.发明所要解决的技术问题
6.然而,基于深度学习的语音降噪需要芯片具有足够的计算能力,且对存储单元也具有相应的要求,因而在资源受限的情况下,无法发挥出较好的效果。
7.此外,基于深度学习的语音降噪虽然能直接应用到资源受限的离线终端,但在进行实时交互的情况下,依然存在资源受限的问题,进而无法发挥出较好的效果。
8.本发明是鉴于上述问题而完成的,其目的在于提供一种语音降噪的训练方法、语音降噪系统及语音降噪方法,即使在实时交互的情况下,也能应用在资源受限的边缘端、例如耳机通话等应用场景中。
9.解决技术问题所采用的技术方案
10.本发明的一个实施方式所涉及的语音降噪的训练方法基于深度学习来进行,其特征在于,包括以下步骤:构建噪声和语音的训练样本;对不带噪声的语音和带噪声的语音进行傅里叶变换,以获取各自的幅值和相位特征;将带噪声的语音的幅值输入到神经网络中,通过神经网络处理而得到降噪后的幅值;将降噪后的幅值与不带噪声的语音的幅值通过模型训练损失函数进行训练,以优化神经网络的权值。
11.本发明的一个实施方式所涉及的语音降噪系统的特征在于,包括:神经网络模块,该神经网络模块应用本发明的一个实施方式所涉及的语音降噪的训练方法,对带噪声的语音进行降噪处理;以及信号处理模块,该信号处理模块设置在所述神经网络模块的后级,对从所述神经网络模块输出的降噪后的语音进行信号处理,进一步去除噪声。
12.本发明的一个实施方式所涉及的语音降噪方法的特征在于,包括:获取音频信号,其中,所述音频信号包括语音信号、稳态噪声信号和非稳态噪声信号;利用神经网络模块对所述音频信号执行使所述非稳态噪声信号减小的第一降噪处理,以生成第一降噪信号;利用信号处理模块对所述第一降噪信号执行使所述稳态噪声信号减小的第二降噪处理,进而生成第二降噪信号。
13.发明效果
14.根据本发明所涉及的语音降噪的训练方法、语音降噪系统及语音降噪方法,通过采用神经网络-传统信号处理级联的方法,噪声语音首先通过神经网络过滤非稳态噪声,然后进一步通过传统信号处理方法压制稳态噪声,从而能同时兼顾和平衡降噪效果与功耗。也就是说,采用级联的方法,由神经网络主要解决(高能量的)非稳态噪声,进而再使用传统信号处理的方法来压制稳态的底噪,从而能兼顾和平衡降噪效果与功耗。因此,即使在实时交互的情况下,也能应用在资源受限的边缘端、例如耳机通话等应用场景中。
附图说明
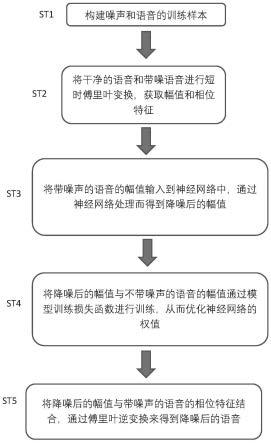
15.图1是示出本发明所涉及的语音降噪的训练方法的步骤的流程图。
16.图2是示出本发明所涉及的语音降噪系统的结构的框图。
17.图3是示出本发明所涉及的语音降噪系统的降噪效果的图。
18.图4是本发明所涉及的语音降噪方法的信号路径图。
19.标号说明
20.1000 语音降噪系统
21.100 神经网络模块
22.200 信号处理模块
23.101 输入的语音
24.102 非稳态噪声去除后的语音
25.103 非稳态噪声和稳态噪声去除后的语音
具体实施方式
26.以下,参照附图,对本发明的实施方式进行详细说明
27.一、语音降噪的训练方法
28.图1是示出本发明所涉及的语音降噪的训练方法的步骤的流程图。该训练方法用于使基于神经网络的语音降噪模型的参数进一步优化,从而能使经由该语音降噪模型降噪后的语音更为干净,且能进一步抑制非稳态噪声。
29.本发明所涉及的语音降噪的训练方法基于深度学习来进行,其主要目的在于,通过对语音降噪进行训练,从而能更准确、高效地去除语音中的噪声(特别是语音中难以通过传统的信号处理方法来去除的非稳态噪声)。
30.语音降噪的训练方法的具体步骤如下:
31.(1)在图1的步骤st1中,建立数据集、即构建噪声和语音的训练样本。
32.(2)在图1的步骤st2中,对不带噪声的语音(即:干净的语音)和带噪声的语音进行傅里叶变化,以获取各自的幅值和相位特征。通过傅里叶变化,能从时域转换到频域,从而能进行降维以减少数据量。由于仅对幅值特征进行训练,因此能高效地完成训练,且节省资源。
33.(3)在图1的步骤st3中,将带噪的语音的幅值输入到神经网络中,通过神经网络的处理而得到降噪后的幅值,这也是预测出的不带噪声的语音的幅值(即、预测出的去噪后的语音的幅值)。
34.(4)在图1的步骤st4中,利用模型训练损失函数,对降噪后的幅值与实际的不带噪声的语音的幅值进行训练。具体而言,通过模型训练损失函数计算它们之间的损失,并基于该损失来反向传播、迭代神经网络中的权值。通过大量、不断地学习和迭代,从而可以得到神经网络中的最优权值。在确定了最优权值以后,学习的过程实际上也就完成了。
35.关于模型训练损失函数,从去除非稳态噪声的目的出发,可以采用对数功率谱的正则(以下有时简称为“对数正则”)。即,在进行傅里叶变换并得到相应的频域参数后,先对其取对数(log),然后再取其正则项。关于正则项,可以取一次(绝对值)正则、二次(绝对值的二次幂)正则、三次(绝对值的三次幂)正则、四次(绝对值的四次幂)正则等。
36.另外,关于训练中所使用的神经网络,可以是循环神经网络(rnn),可以是长短时记忆网络(lstm),也可以是门控循环单元(gru)。循环神经网络是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络。长短时记忆网络是一种时间循环神经网络,是为了解决一般的rnn(循环神经网络)存在的长期依赖问题而专门设计的。此外,门控循环单元在rnn的基础上加了门操作,目的和lstm基本一样,都为了加强rnn神经网络的记忆能力。
37.除此以外,也可以使用上述神经网络以外的各种神经网络。
38.(5)在图1的步骤st5中,将步骤st4中所输出的降噪后的幅值与原本带噪声的语音的相位特征结合,并通过傅里叶逆变换来得到降噪后的语音。也就是说,通过傅里叶逆变换从频域转换为时域,从而得到降噪后的实际的语音。
39.通过上述那样的基于神经网络的训练,可以有效地优化针对非稳态噪声的降噪模型(算法),从而在过滤非稳态噪声的过程中能起到更好的效果。
40.具体而言,通过该训练,能使语音降噪模型的参数(损失函数)进一步优化,从而能使经由该模型降噪后的语音更为干净,且能进一步抑制非稳态噪声。
41.二、语音降噪系统
42.图2是示出本发明所涉及的语音降噪系统1000的结构的框图。
43.图2中,标号1000表示语音降噪系统,标号100表示神经网络模块,标号200表示信号处理模块。两个模块通过多级级联的方式相连接。
44.对于神经网络模块100,应用了由上述“语音降噪的训练方法”所产生的参数。
45.具体而言,利用上述那样的基于深度学习的语音降噪的训练方法来优化针对非稳态噪声的降噪模型(算法),并将经由上述语音降噪的训练方法训练后而得的参数应用于该神经网络模块100,从而能对所输入的语音101中所包含的非稳态噪声进行过滤(去除),并
将去除了非稳态噪声后而得的语音102输入到后级的信号处理模块200。
46.信号处理模块200设置在神经网络模块100的后级,对从神经网络模块100输出的降噪后的语音102进行信号处理,从而进一步去除噪声。
47.具体而言,信号处理模块200采用传统的降噪算法(信号处理方法),例如可以采用普减法、维纳滤波法、基于最大似然、最大后验、最小均方估计等。通过该信号处理模块200可以压制(去除)稳态噪声(例如:底噪等),同时兼顾较低的功耗和内存使用。
48.如图2所示那样,输入到信号处理模块200的语音102经过进一步去噪后,稳态噪声也被去除,从而得到干净(噪声去除后)的语音103。
49.根据本发明所涉及的语音降噪系统1000,将神经网络模块(算法)100和信号处理模块(传统降噪算法)200级联,利用计算量较大、资源和功耗开销较高的神经网络算法有效的对非稳态噪声进行建模,并利用功耗较低、内存使用较少的传统信号处理算法有效降低稳态噪声,从而即使在实时交互的情况下,也能应用在资源受限的边缘端、例如耳机通话等应用场景中。
50.通过采用神经网络-传统信号处理级联的方法,噪声语音首先通过神经网络过滤非稳态噪声,然后进一步通过传统信号处理方法压制稳态噪声,从而能同时兼顾和平衡降噪效果与功耗。也就是说,采用级联的方法,由神经网络主要解决(高能量的)非稳态噪声,进而再使用传统信号处理的方法来压制稳态的底噪,从而能兼顾和平衡降噪效果与功耗。
51.此外,通过采用上述结构,不同于现有的端到端技术,能够简单地更新模型训练损失函数和训练策略,而不会对后级的信号处理造成影响。也就是说,根据本发明所涉及的语音降噪系统,其结构更为灵活、修改更为简单,与此同时,其降噪效果却不会降低,因而能应用在更多的场景中。
52.图3是示出本发明所涉及的语音降噪系统的降噪效果的图。上半部分表示所输入的语音信号,下半部分表示去噪后的语音信号。
53.由图3可知,通过本发明所涉及的语音降噪系统,利用芯片中所包含的神经网络算法去除非稳态噪声进行建模,并利用传统信号处理算法去除稳态噪声,从而能得到优异的去噪效果。
54.作为实际的应用例,可以将本发明所涉及的语音降噪系统装载到(植入)芯片中来发挥作用。该芯片可以应用在无线耳机等资源受限的边缘端,该情况下,cpu处理算法耗时小于一帧语音的时长,实时性较好,并且,由于进行混合处理,因而功耗小,计算快。
55.三、语音降噪方法
56.接下来,对本发明所涉及的语音降噪方法进行说明。图4是本发明所涉及的语音降噪方法的信号路径图。
57.该方法中,首先获取音频信号,该音频信号包括语音信号、稳态噪声信号和非稳态噪声信号。其中,稳态噪声为公交、飞机或地铁等的噪声,或者为嘈杂人声等。非稳态噪声为突发噪声、音乐噪声或无规律的噪声等。
58.通过短时傅里叶变换对所输入的音频信号进行转换,从而将音频信号从时域转换到频域,然后,利用神经网络模块对该音频信号执行使非稳态噪声信号减小的第一降噪处理,以生成第一降噪信号。具体而言,通过神经网络进行降噪,提取语音特征信息,并生成掩蔽矩阵,最后通过短时傅里叶逆变换将音频信号从频域转换回时域。此时,所生成的第一降
噪信号为非稳态噪声被去除(抑制)后的音频信号。
59.接下来,利用信号处理模块对上述第一降噪信号执行使稳态噪声信号减小的第二降噪处理,进而生成第二降噪信号。具体而言,通过数字信号处理(dsp)、语音概率估计、噪声谱更新、增益因子更新等,生成稳态噪声被去除(抑制)后的音频信号(即、第二降噪信号)。
60.最终,得到非稳态噪声和稳态噪声均被去除(抑制)后的音频信号(即、仅包含干净的语音信号的音频信号)。
61.关于本发明所涉及的语音降噪方法,由于传统的信号处理方法无法处理大噪声,比较容易失真,因此需要先利用神经网络模块进行处理。也就是说,降噪处理的顺序不应改变,需要先利用神经网络处理非稳态噪声,再利用信号处理的方法来处理稳态噪声,从而能得到较好的降噪效果,以最大化抑制各类噪声。
62.工业上的实用性
63.本发明所涉及的语音降噪的训练方法、语音降噪系统及语音降噪方法能应用于耳机通话等。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。