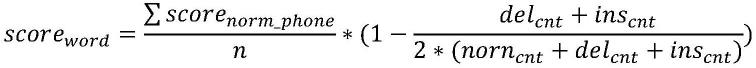
1.本发明涉及语音评测技术领域,具体涉及一种基于深度学习的发音评测打分方法,利用深度学习方法来实现发音评测过程中对音素的打分机制,使发音评测中的音素打分更加合理,更加准确。
背景技术:
2.口语在语言教育课程中越来越受到重视,师生一对一的交流与教学是提高英语口语最有效的方式,但很难满足众多口语学习者的需求。得益于计算机技术和发音评测技术的飞速进步,各种基于人工智能技术的口语评价方案相继落地。为学生提供额外的学习机会和丰富的学习资料,能够协助或代替教师指导学生进行更有针对性的发音练习,指出学生发音错误,提供有效的诊断反馈信息,评估学生的整体发音水平,有效提高学生的口语学习效率和口语水平。
3.发音评测目前的主流方法是基于隐马尔科夫-深度神经网络(hmm-dnn)模型获取语音的后验概率,然后与评测文本进行强制对齐后,使用gop方法进行打分。
4.强制对齐方法可以达到很高的准确度,但这必须要满足一个前提:给定的文本和音频必须是匹配的。如果一个用户将i am a teacher读成了i was a teacher,在处理was所对应的音频片段时,会错误地将它和am对应的音素进行比对,那么很有可能造成后续的a和teacher也无法对齐到正确的位置,从而影响打分的准确性。
技术实现要素:
5.为了解决上述问题,本发明提出一种基于深度学习的语音评测打分方法。首先通过一个语音识别模型,识别出该音频的文本,然后使用识别出的文本去进行强制对齐,这样对齐的结果会更加的准确。最后通过一个深度神经网络构建的打分模型,预测音素的得分,根据音素的得分计算出单词和句子的得分。
6.本文提出了一种基于深度学习的发音评测打分方法,首先通过语音识别的模型,用它来识别出音频的真实文本结果。其次是通过hmm-dnn模型,用它来获取音频的后验概率。然后是使用音频的识别文本结果和音频的后验概率进行强制对齐,确定每一个音素的时间边界。最后是通过打分模型,用它来对音素进行打分。
7.具体的技术方案如下:
8.步骤一,对待评测语音提取声学特征,送入到语音识别模型中,识别出待评测语音的真实文本结果。
9.步骤二,将步骤一中提取的待评测语音的声学特征,送入到hmm-dnn模型中,预测出每一帧的后验概率。
10.步骤三,根据步骤一中识别出的文本结果和步骤二中得到的每一帧的后验概率,进行强制对齐,确定每一个音素的时间边界。
11.步骤四,根据步骤三得到的每一个音素的时间边界和步骤二得到的每一帧的后验
概率,计算出每一个音素的后验概率的平均值,然后将该音素的后验概率的平均值和该音素的元辅音、词性、声调、发音时长等特征信息拼接在一起,送入到打分模型中,得到该音素的打分。
12.步骤五,根据步骤一中识别出的文本结果和参考文本,进行音素对齐,确定哪些音素是多读和漏读的。
13.步骤六,计算最终的得分,根据步骤五的多读和漏读情况计算出单词的得分和整个句子的得分。
14.有益效果
15.本发明通过在强制对齐前,使用语音识别模型,识别出音频的正确文本,避免了在强制对齐过程中,音频与文本不一致时,无法对齐到正确位置。同时使用深度神经网络构建打分模型,可以拟合后验概率、元辅音、词性、声调、发音时长等多种信息,使得音素打分更加合理,更加准确。
16.1.使用语音识别模型,识别出音频的正确文本,避免了在强制对齐过程中,音频与文本不一致时,无法对齐到正确位置。
17.2.使用深度神经网络构建打分模型,可以拟合后验概率、元辅音、词性、声调、发音时长等多种信息,使得音素打分更加合理,更加准确。
附图说明
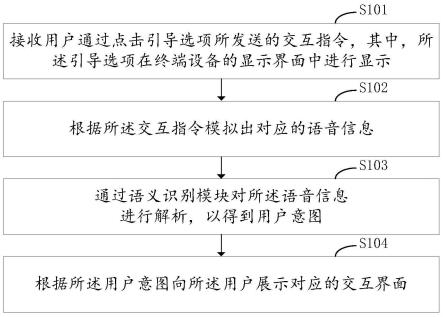
18.图1是流程示意图。
具体实施方式
19.下面结合附图对本发明做进一步详细地描述。
20.图1是本发明基于深度学习的发音评测方法的流程示意图。如图1所示,主要包含以下几个步骤:
21.步骤一,对待评测语音提取声学特征,提取的声学特征可以是fbank特征,提取fbank特征时,采样频率是16000,窗长设置为25ms,帧移设置为10ms。提取完特征后,送入到语音识别模型中,语音识别模型可以使用wenet模型,识别出待评测语音的真实文本结果。
22.步骤二,将步骤一中提取的待评测语音的声学特征,如fbank特征,送入到hmm-dnn模型中,预测出每一帧的后验概率。假设一共有m帧,n个音素,最终会生成一个m*n的后验概率矩阵。
23.步骤三,根据步骤一中识别出的文本结果和步骤二中得到的每一帧的后验概率,进行强制对齐,强制对齐采用贪心或者viterbi算法进行,找出一条概率最大的路径,最终确定每一个音素的时间边界。
24.步骤四,根据步骤三得到的每一个音素的时间边界和步骤二得到的每一帧的后验概率,可以计算出每一个音素的后验概率的平均值。
25.之后需要获取每一个音素的特征信息,如元辅音、词性、声调、发音时长等特征。
26.1、元辅音特征,判断当前音素是否是元音还是辅音,针对音素类型的不同,元音和辅音的打分会不同,元音会更加重要。
27.2、词性特征,判断当前音素所在单词的词性,根据单词词性的重要性,打分结果会
不同,动词、名词等实词的重要性要高于虚词。
28.3、音调特征,判断当前音素是否含有音调,参考文本中若标出音调信息,但音频中未读出音调,会降低最终的得分。
29.4、发音时长特征,计算当前音素的持续时长,并跟标准音素的发音时长做归一化处理,
30.若归一化后的发音时长特征较低或较高都会导致分数降低。
31.最后将该音素的后验概率的平均值和该音素的元辅音、词性、声调、发音时长等特征信息拼接在一起,送入到打分模型中,得到该音素的打分。
32.打分模型可采用dnn进行建模,使用三层深度神经网络dnn,隐藏层的维度设置为128,最后一层维度设置为1,输出最后的打分结果。
33.通过使用深度神经网络dnn来对音素的各种特征进行建模,拟合出一个复杂的函数来对音素进行打分,使得音素的打分更加合理和准确。
34.步骤五,根据步骤一中识别出的文本结果和参考文本,进行音素对齐,确定哪些音素是多读音素、漏读音素和正常音素。
35.对齐方法可使用计算编辑距离的方式来实现,首先将识别出的文本结果转换成对应的音素字符串列表x[1,
…
,n],参考文本转换成对应的音素字符串列表y[1,
…
,m],定义距离d(i,j)为x[1,
…
,i]和y[1,
…
,j]的距离,那么x和y的编辑距离就是d(n,m)。使用动态规划的方法进行求解,状态转移方程为:
[0036]
d(i,0)=i
[0037]
d(0,j)=j
[0038][0039]
其中,insert表示多读音素,delete表示漏读音素,norm表示正常音素。
[0040]
通过记录每个子结果是由哪个子问题解得的,可以对结果进行回溯,最后可以得到两个字符串的对齐结果。
[0041]
步骤六,计算最终的得分,根据步骤五的多读和漏读情况计算出单词的得分和整个句子的得分。
[0042]
单词的得分与单词内所有正常音素的得分和多读漏读比例有关。句子的得分不仅与句子内所有正常音素的得分和多读漏读比例有关,同时与单词的持续帧数和单词间静音帧数有关,单词间静音帧数只计算大于正常停顿时间的静音帧数。
[0043]
计算单词的得分,可采用以下公式:
[0044][0045]
其中,score
norm_phone
表示单词内正常音素的得分,n表示参考文本中所有音素的个数,norn
cnt
表示正常音素的个数,ins
cnt
表示多读音素的个数,del
cnt
表示漏读音素的个数。
[0046]
计算句子的得分,可采用以下公式:
[0047][0048]
其中,score
norm_phone
表示句子内正常音素的得分,n表示参考文本中所有音素的个数,norn
cnt
表示正常音素的个数,ins
cnt
表示多读音素的个数,del
cnt
表示漏读音素的个数。frame
word
表示所有单词所占的帧数,frame
sil
表示单词之间的静音帧数。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。