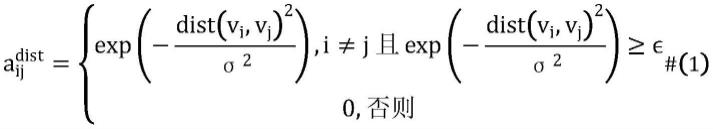
1.本发明涉及城市交通网络时空预测领域,具体涉及一种公共交通流量预测方法,主要功能是在短期和长期两种需求场景下解决交通网络的时空预测问题,对于城市公共交通移动模式以及规律的预测、建设智慧城市具有重大意义。
背景技术:
2.在最近几年,网络、信息与通信技术的飞速发展,包括物联网(internet of things,iot)、云计算、边缘计算等,推动了智慧城市的建设,帮助改善各类公共服务、民生安全、经济发展等城市需求,使得城市生活更加人性化和智能化。其中一个最重要的应用场景之一就是智慧交通系统(intelligent transportation system,its),旨在通过信息化技术,提供智能化、数字化的交通公共安全服务及交通问题的解决方案,方便城市居民的出行。与此同时,现有的大多数交通问题中,如交通拥挤、交通事故、线路规划、资源分配等,都和交通流量状况息息相关,与其变化存在紧密的因果关系。另一方面,信息化的城市交通工业的发展离不开城市交通大数据,每天都会产生大量的时空数据,其数据来源、结构复杂多样,如gps、感应器、监控摄像、出行记录。由此,基于城市时空大数据,现存在的主要挑战能够总结为两点:
3.(1)在城市大数据环境下,处理并分析海量且冗余的时空数据,结合数据特点,发现数据中潜在的关系特征。
4.(2)如何挖掘数据中的移动模式及规律,以改善出行,提供更好的公共服务。
5.公共交通在城市交通系统扮演着至关重要的角色,其产生的巨大乘客流量就是一重要体现。以北京为例,根据《2021北京市交通发展年度报告》,2020年城市公共汽车及地铁客运总量已经达到了43.54亿人次,并且可以很大程度反映整个城市的交通流量情况。此外,考虑到绿色低碳的出行方式和城市的可持续发展,人们往往也被鼓励采用这类公共交通方式出行。因此,公共交通的运营和管理能够直接或间接影响城市的交通环境,城市中的人流量和出情况分布往往与公共交通能够保持高度的一致性。这也一直被政府相关部门重视,为了改善公共交通,也采取过许多政策,例如优惠票价、公共专用道、增设站点和路线、优化公交运营时间等。
6.然而,城市中仍然会不断出现公共交通拥堵和资源分配不合理等新的交通问题,促使着学者们对此展开研究。以最常见的公交车为例,在许多现实工业应用中可以发现,为了提供新的服务来满足改善公交出行和乘坐体验的时候,需要对整个乘客流量情况进行分析和预测,在多样的实际场景中,短期或长期的预测都是有很大的需求的。例如,路径优化中,在制定服务决策之前,交通流量预测和评估是其中至关重要的一步。不难发现,如果我们可以准确的预测交通流量,就可以及时响应作出决策,避免交通拥堵,保持道路畅通,针对公交车环境甚至可以改善乘客出行体验。
技术实现要素:
7.本发明要克服现有技术的上述缺点,提出一种公共交通流量预测方法。在长短期交通时空预测中结合站点移动模式提高预测的表现和效率,利用深度聚类的模型,根据站点的时空属性,提取站点的移动模式;针对长短期的复杂交通预测场景,设计了一种基于transformer的时空预测模型(stgnnformer),在时间依赖关系的提取上,融入时序分解、自相关机制来降低时序计算的复杂度,而空间依赖关系的提取,利用可学习的自适应图应用于图卷积操作。
8.本发明是通过以下技术方案达到上述目的:一种长短期公共交通流量预测方法,包括如下步骤:
9.(1)对由公共交通公司提供的原始数据进行预处理;
10.(2)基于步骤(1)所得结果中的站点特征和距离网络,采取深度聚类模型,进行站点移动模式的提取,得到各自的模式标签;
11.(3)基于步骤(2)所得结果,采取多模式的方式进行预测工作,即对各个移动模式分别训练时空预测模型;
12.(4)结合步骤(2)和步骤(3)所得结果,进行整合得到最终的站点的交通预测结果。
13.其中,所述步骤(1)具体包含如下步骤:
14.11.对公共交通的原始数据进行预处理,去除敏感的乘客隐私信息;
15.12.乘车站点匹配:通过算法实现乘车站点匹配,即乘客刷卡数据与公共交通工具进出站数据进行匹配以确认乘客的具体乘车站点和下车站点;
16.13.途径站点轨迹补全:根据公交车线路和站点网络,扩展成出行的途经站点轨迹,得到时空预测所需的乘客站点流量数据;
17.14.数据清洗和过滤:筛选过滤一些只有少量刷卡记录的乘客流量,保证在探索乘客移动模式的时候,避免异常孤立的乘客节点;对由于公共交通进出站数据存在少量的缺失,导致流量的统计也存在异常缺失情况采用线性插值的方法进行填补减少实际误差。
18.其中,所述步骤(2)具体包括如下步骤:
19.21.公交车站点网络设置为站点距离关系网络,可以表示为一个无向图站点关系的定义和邻接矩阵的计算是由实际交通网络中站点之间的空间距离决定。的各个元素值的计算公式如下:
[0020][0021]
其中dist(vi,vj)表示站点vi和vj的空间距离计算(由经纬度计算得到),σ2和∈为两个阈值,分别控制邻接矩阵的分布和稀疏性。中的元素取决于各元素的数值,即当成立。
[0022]
22.利用训练集中的时序数据作为站点的时间特征向量,使得站点特征可以一定程度反映站点时间上的特性,其特征数值大小也可以反应站点流量的具体交通状态。站点的特征维度ds=156,站点的特征矩阵可以表示为
[0023]
23.基于步骤21以及步骤22的结果,使用深度聚类模型与中基于gcn的深度聚类方法,设计了一种双自监督的深度聚类方法,去挖掘潜在的乘客移动模式。其中模型主要由若干层堆叠自编码器和gcn模块组成,利用双自监督的方法学习得到各模式的标签种类。在数据上,将输入替换为站点距离关系网络和站点的特征矩阵xs,并在模型参数上进行了一定的修改。以若干天的平均一天的流量分布为站点的时间特征,这样在堆叠自编器模块学习站点的表示向量的时候,能够在一定程度上分析时间流量分布特征上的差异,而gcn模块能够进一步学习距离空间关系上的特征。其中双自监督的深度聚类方法内容如下。
[0024]
首先使用基于无监督的表示学习算法——堆叠自编码器,作为学习乘客节点表示的网络骨架,可以简单的描述为一个映射关系φ:其中其中编码器和解码器是对称的,这里假设编码器和解码器各有l层。第l层的编码层和其对应的解码层的表示计算公式可以表示成如下:
[0025][0026]
其中θe和θd分别表示编码器和解码器中的全连接层的学习参数矩阵,σ(
·
)为激活函数(这里使用的是relu激活)。此外,原始特征矩阵x是由网络邻接矩阵线性编码得到,编码器的输入为y
(0)
=x,编码器的输出对应着解码器的输入且设最终重构的原始输入数据为即解码器的输入由此,其目标函数为:
[0027][0028]
接下来,设计gcn模块来融入图卷积,进一步提取关系特征。同样地,gcn模块与堆叠自编码器对应着有l层图卷积,第l层的图卷积层学习过程如下:
[0029][0030]
其中(为单位对角矩阵),是一个对角矩阵,且θg为图卷积层的学习参数矩阵;σ(
·
)为激活函数(这里使用的是relu激活)。然而,h
(l)
是通过网络关系聚合邻居节点信息的表示向量,而y
(l)
是能够重构数据本身的表示向量,包含的信息价值是有所不同的。因此,为了得到一个更有效的表示向量,这里将二者相结合:
[0031][0032]
其中,α为超参,作为两个表示向量融合的平衡系数。通过这样的方式,将堆叠自编码器和gcn模块进行连接,并且,使用作为gcn模块中第l层的输入,即表示成如下:
[0033][0034]
这样,最终得到的h
(l)
经过多层网络的不断学习和累加,能够学习得到不同阶(多跳邻居)的结构信息。在gcn模块的最后,再使用softmax函数作为多分类层:
[0035][0036]
其中这里的h表示一个聚类的概率矩阵,其中元素h
ij
表示乘客节点vi属于蔟cj的概率,且聚类中的蔟与移动模式一一对应,即移动模式pj。
[0037]
gcn模块是一种半监督的学习方法,把堆叠自编码器和gcn模块连接起来后,该模型仍然无法做到无监督的深度聚类。由此,在整个深度聚类模型的最后,设计了一种双自监督模块,能够整合学习得到的表示向量h
(l)
,有效地进行端到端的聚类训练。根据堆叠自编码器的表示向量结果,为了衡量表示yi∈y
(l)
(矩阵y
(l)
中取第i行)与蔟cj的中心向量μj的相似度,利用student’s t分布来计算:
[0038][0039]
其中μj由预训练堆叠自编码器后的表示向量经过k-means初始化得到,n是t分布中的自由度参数。类似地,这里可以将q
ij
视为乘客节点vi分配给蔟cj的概率,并得到概率分布矩阵q={q
ij
}作为聚类结果。另一方面,对于目标分布p={p
ij
},为了使q的聚类结果具有更高的置信度,并且让各个节点的表示向量能够更加接近蔟中心,提高蔟的内聚性,其归一化的计算的公式如下:
[0040][0041]
由此,在得到聚类结果分布和目标分布后,可以采用kl散度来衡量分布之间的差异,即自监督的聚类学习的目标函数为:
[0042][0043]
通过最小化该目标函数,可以被认为是一种自监督机制,目标分布p可以帮助更好的学习堆叠自编码器表示向量,并且目标分布p是由聚类结果分布q计算得到的,等价于同时监督q的更新。
[0044]
此外,在训练gcn模块过程中,选择分布p作为真实标签,用分布p来监督之前获得的聚类分布矩阵h,其目标函数如下:
[0045][0046]
整个模型的损失函数为
[0047][0048]
其中θ为超参。选择聚类概率分布h用于判断最终的聚类结果,即对于节点vi,其聚类的标签结果可以设置为以深度聚类的结果作为移动模式,获取得到与聚类标签一一对应的乘客潜在的移动模式。
[0049]
优选地,步骤21邻接矩阵的分布和稀疏性分别被设置为10002和0.1;步骤22和步骤23中的激活函数σ(
·
)使用relu激活;步骤23中的超参α设置为0.5;步骤24中的自由度参数n设置为1。
[0050]
其中,所述步骤(3)具体包括如下步骤:
[0051]
31.基于(1)中所得结果,采用移动平均的方式来逐步聚合和提取季节性波动和长期趋势。对于输入(时空数据),t,nv,d分别表示时序长度、图的节点数量和嵌入向量特征维度,时序分解块的计算过程为:
[0052][0053]
其中其中分布表示分解得到的季节性部分和趋势部分,avgpool(
·
)通过平均池化操作来实现移动平均,在平均池化前需要进行复制填补(replicate padding),保证得到的数据在该计算过程中的输入和输出的长度的一致性。此外,时序分解块是一个内部计算,不需要额外参数,可以用块是一个内部计算,不需要额外参数,可以用块是一个内部计算,不需要额外参数,可以用表示该模块操作;
[0054]
32.选择历史时序数据的后半段作为起始标记,并用特定值进行填充拼接,拼接长度为所需预测长度,作为待预测的目标时序的占位符(placeholder)。设定原始输入时空数据为(c为真实时序数据特征维度),通过时空嵌入(stembed)后得到编码器的输入数据为在引入时序分解后的解码器包含趋势和季节性两部分作为输入入公式化后如下:
[0055][0056]
其中其中表示对历史时序数据的后半段进行时序分解后的结果,的后半段进行时序分解后的结果,表示预测时序数据的占位符,分别代表0值和的均值;
[0057]
33.使用(编码层中tsdecomp2的季节性部分)作为每一层的输出且在该过程中并没有使用趋势部分,编码器的最终输出将作为交叉信息用于解码器;
[0058]
34.解码器在预测需要用时序数据的趋势部分,包括关于季节性部分的自相关层和自适应gnn层堆叠结构,以及关于趋势部分累积的分支结构;假设解码器有n
de
个解码层组成,第l层的解码层可以简单总结为成,第l层的解码层可以简单总结为成,第l层的解码层可以简单总结为成,第l层的解码层可以简单总结为作为每一层的输出作为每一层的输出且且且conv1d(
·
)表示标准的一维卷积计算,将模型嵌入向量特征维度转换为真实输出时序数据特征维度;最终编码层的输出为而模型的输出结果为季节性部分和趋势部分的二整合:θs表示对季节性部分通过一层全连接将嵌入向量向量特征维度转换为真实输出时序数据特征维度;因此,stgnnformer模型预测结
果可以写作
[0059]
35.数据自适应图构建用于图卷积操作;自适应图的邻接矩阵构建需要使用一个可学习的节点嵌入作为基础,其中dv为超参表示节点嵌入的特征维度;如果存在预先定义的邻接矩阵,利用矩阵的奇异值分解(singular value decomposition)用于节点嵌入的初始化,否则随机初始化即可;由此,图卷积操作中使用到的归一化后的邻接矩阵表示为:
[0060][0061]
其中softmax(
·
)和relu(
·
)均为激活函数,前者作用是对生成得到的邻接矩阵进行归一化;这样,在训练过程中,会自适应的学习和更新节点嵌入,学习潜在的空间依赖关系,具有更好的可解释性,同时也在不断更新邻接矩阵,得到的自适应邻接矩阵用于图卷积操作(adagnn);
[0062]
36.自注意力机制主要用于短期预测任务中,是transformer中一个重要的模块,简单描述为将查询(query)和一组键值对(key-value pairs)映射到输出中;在这里,注意力函数的计算公式如下:
[0063][0064]
其中q,k,v分别为查询、键、值的向量矩阵,dk是特征维度,用于归一化处理;
[0065]
对于周期时间段的时间依赖关系的挖掘,通过序列的自相关计算来表示;基于随机过程理论(stochastic process theory),时间序列视为离散时间过程由此其自相关系数计算写成如下形式:
[0066][0067]
其中表示序列{x
t
}与其自身在延迟τ步的序列{x
t-τ
}的相似性,也理解为未归一化的时间段长为τ下的置信度;并且,基于维纳-辛钦(wiener-khinchin)定理,利用快速傅立叶变换(fast fourier transforms)来优化自相关计算过程:
[0068][0069]
其中,和分别表示快速傅立叶变换和其逆变化,表示共轭相称,为时序在频域的表示形式;通过该优化,有效地将复杂度降为o(tlogt);
[0070]
37.对相似度最高的若干个子序列进行时延信息聚合操作;计算得到自相关后,即序列在各种步长延迟情况下的相似度,首先取前个相似度最高的时间段,其长度为并使用roll(
·
)操作信息对齐相似的子序列和待
估计序列的位置,具体过程为序列的向左平滚,即位首的值将移动到末尾;在信息聚合时,先使用softmax(
·
)对原自相关值进行归一化得到作为各子序列权重完成时延信息聚合;最终,写成如下:
[0071][0072]
其中,∈为超参,用于选择相似子序列数量,q,k,v对应着自注意力机制中的查询、键、值,因此,可以直接替换自注意力机制模块;
[0073]
38.时空嵌入;这里设计了一种具有针对性的时空嵌入方式,包括数据上下文嵌入(context embedding,cembed)、时序位置编码嵌入(temporal positional embedding,tpembed)、时间戳特征嵌入(timestamp feature embedding,tfembed)和空间位置嵌入(sptial positional embedding,spembed);
[0074]
数据上下文嵌入指的是对原始时序数据进行编码,简单地采用一维卷积来实现;时序位置编码嵌入与transformer的位置编码计算一致;虽然时序位置编码在一定程度上反映时间关系,但是只能表示局部的上下文关系;因此,这里使用时间戳特征嵌入,融入全局的时间戳特征,即利用时序数据某一位置的时间戳信息(如分钟、小时、周、月等),由离散的信息转换成连续的表示向量;最后,为了捕捉不同节点的静态的空间拓扑结构特征,先将每个节点的索引号投影成模型嵌入向量特征维度,再通过多层平滑的图卷积得到节点的空间位置嵌入;因此,时空嵌入的过程可以表示成如下:
[0075][0076]
其中,所述步骤(4)具体包括如下步骤:
[0077]
这里假设共有k个站点移动模式,于是得到模式pi的节点数量为n
v,i
,且与单独训练相比,有效的减少内存空间的需求,在有限的硬件资源下,使得内存空间开销从优化为o(∑|n
v,i
|2)。最后的预测结果是由每个模式的预测结果拼接而成,即
[0078]
本发明的创新之处在于:
[0079]
(1)提出一种新颖的公共交通流量预测方法,mpgnnformer,在长短期交通时空预测中结合站点移动模式提高预测的表现和效率,其中,我们将利用深度聚类的模型,根据站点的时空属性,提取站点的移动模式,该移动模式的定义可以简单地理解为具有相似乘客流量分布的一类站点;
[0080]
(2)针对长短期的复杂交通预测场景,设计了一种基于transformer的时空预测模型(stgnnformer),在时间依赖关系的提取上,融入时序分解、自相关机制来降低时序计算的复杂度,而空间依赖关系的提取,利用可学习的自适应图应用于图卷积操作。
[0081]
本发明的优点是:
[0082]
(1)研究探索考虑到人群的移动模式,该模式可以定义为具有相似出行路线的一类人或者具有相似乘客流量分布的一类站点。在解决交通流量预测任务的时候,与基于传统的数理统计的算法和基于深度学习的预测算法只是单纯考虑交通预测算法在时序数据
统计的数值上的分析能力不同。
[0083]
(2)在stgnnformer中利用自相关机制(auto-correlation mechanism)来替代自注意力机制来探索基于周期时间段的依赖关系,空间依赖关系的提取由数据自适应图(data self-adaptive graph)的gnn层来实现。此外,在原始时序数据的嵌入模块也进行了一定的修改,设计了一种时空嵌入(spatial-temporal embedding)的方法,使得输入数据不仅包含数据本身的信息,还能够包含时序位置顺序信息、时间戳信息、空间位置信息。在解码器部分借鉴自然语言处理中利用起始标记(start token)的动态解码的思路,扩展为一种生成式推理(generative inference)的预测方式,进一步提高计算效率。
[0084]
(3)使用自相关机制来取代自注意力机制,挖掘周期时间段的时间依赖关系,实现序列向(series-wise)连接,提高时序数据信息的利用效率。
附图说明
[0085]
图1是本发明的长短期交通预测整体框架。
[0086]
图2是本发明实例乘客总流量分布示例。
[0087]
图3(a)~3(b)是本发明的数据勘察和分析结果,其中,3(a)是每个乘客乘上车的站点数量分布,3(b)是每个站点的刷卡记录数量分布。
[0088]
图4是本发明实例随机选取十个站点的特征分布示例。
[0089]
图5(a)~5(b)是本发明实例站点移动模式可视化分析,其中,5(a)是流量特征分布,5(b)是pca降维。
具体实施方式
[0090]
下面结合附图对本发明进行进一步描述。
[0091]
本实例是江苏熊猫公交公司交通预测实例,一种长短期公共交通流量预测方法,其公交车长短期交通预测整体框架如图1所示,具体包括以下步骤:
[0092]
(1)对由公共交通公司提供的原始数据进行预处理;
[0093]
a).对公交数据集去除敏感的乘客隐私信息后的公交车刷卡数据集和公交车进出站数据集描述如下表所示:
[0094]
[0095]
表1
[0096]
b).从表1可以注意到需要进行进一步处理的点内容。
[0097]
第一点从原始的数据表是无法直接获取乘客的所乘坐的站点信息,也就无法统计站点流量数据,因此需要对数据进行一定的预处理,即乘客刷卡数据与公交车进出站数据进行匹配以确认乘客的具体乘车站点。
[0098]
第二点在公交车数据的处理中,与地铁不同,无法准确得知乘客的下车站点。
[0099]
第三点需要筛选过滤一些只有少量刷卡记录的乘客流量,保证在探索乘客移动模式的时候,避免异常孤立的乘客节点。需要采用某种方法对由于公交车进出站数据存在少量的缺失(某辆公交车在某个时间段无数据),导致流量的统计也存在异常缺失的情况进行填补减少实际误差。
[0100][0101]
算法1
[0102]
c).乘车站点匹配。选择时间窗口扩大间隔τ=30秒扩大公交车进出站的时间窗口,通过站点匹配算法1所示确认乘客的具体乘车站点。
[0103]
d).od匹配。假设大多数具有多次刷卡记录的乘客,其公交车出行是对称的。基于此假设,将对于同一乘客的所有乘车记录,如果一条记录与另一条记录的公交线路是一样的,则互视为起始点和目的地,从而推导出od表。推导得到od表后,根据公交车线路和站点网络,扩展成出行的途经站点轨迹,得到时空预测所需的乘客站点流量数据。
[0104]
e).数据清洗和过滤。筛选过滤一些只有少量刷卡记录的乘客流量。在站点流量数据表中,采用线性插值的方法进行简单地填补由于公交车进出站数据存在少量的缺失(某辆公交车在某个时间段无数据),导致流量的统计也存在异常缺失的情况,减少实际误差。
[0105]
f).根据e)所得到的数据,对其进行数据勘察和分析。如图2所示,展示了一天(工作日)的流量数据随时间变化的分布情况(2019年11月1日),分析出其中具有很明显的分布规律性,尤其是在固定的时间段具有特定的波峰和波谷。如图3所示,统计了数据集中每个乘客乘坐过的站点数量,以及每个站点的刷卡记录数量,并按照一定的数量级描述该分布,两种统计分布都符合重尾(heavy-tailed)分布。
[0106]
(2)采取深度聚类模型,进行站点移动模式的提取,得到各自的模式标签;
[0107]
a).公交车站点网络设置为站点距离关系网络,可以表示为一个无向图站点关系的定义和邻接矩阵的计算是由实际交通网络中站点之间的空间距离决定。的各个元素值的计算公式如下:
[0108][0109]
其中,dist(vi,vj)表示站点vi和vj的空间距离计算(由经纬度计算得到),σ2和∈为两个阈值,分别控制邻接矩阵的分布和稀疏性(这里分别被设置为10002和0.1)。中的元素取决于各元素的数值,即当成立。
[0110]
b).利用训练集中的时序数据作为站点的时间特征向量,使得站点特征可以一定程度反映站点时间上的特性,其特征数值大小也可以反应站点流量的具体交通状态。站点的特征维度ds=156,站点的特征矩阵可以表示为
[0111]
c).深度聚类模型保持4层自编码器和5层gcn,堆叠自编器的网络维度设置改为训练过程中的学习率和训练次数分别为0.001和500。聚类数选取范围为设k∈{2,3,4,5,6}。以深度聚类的结果作为移动模式,即获取得到与聚类标签一一对应的乘客潜在的移动模式。
[0112]
(3)基于(2)所得结果,采取多模式的方式进行预测工作,即对各个移动模式分别训练时空预测模型。
[0113]
a).单一模式下的时空预测模型stgnnformer,这里经过一定的调参对比结果后,网络模型的各参数设置细节如表2所示。其中时间戳信息的特征选择一般包括年、月、周数、日、星期、小时、分钟、秒等,由于数据集的时间范围仅两个月,因此选择的有效时间戳特征为星期、小时和分钟这三个特征。训练过程中,采用mae作为损失函数,使用adam作为优化器,初始学习率为0.001,此外使用单步的学习率调整策略,即每轮训练会减小学习率,衰减比率为0.5,训练次数设为10。
[0114]
参数描述设定e_layers编码器层数n
en
3d_layers解码器层数n
de
2dropoutdropout选择概率p0.1conv_kernelconv1d的核大小3n_smooth/n_ordergnn的图卷积层数2t_freq时间戳信息选择的特征数3d_model数据嵌入特征维度d32decomp_kernel时序分解模块的avgpool的核大小12factor自相关模块的topk超参∈2n_head多头的数量4node_embed自适应的可学习节点特征dv10
[0115]
表2
[0116]
b).使用评估指标为平均绝对误差(mean absolute error,mae)、均方根误差(root mean square error,rmse)和平均绝对百分比误差(mean absolute percentage error,mape)。各个计算指标的定义表达式由表3给出,其中所有表达式中的和yi分别表示
预测值和真实值。
[0117][0118]
表3
[0119]
c).站点移动模式分析。以一天的流量分布作为站点的特征属性时,不同的站点具有明显的分布规律,图4展示了随机挑选的十个站点特征的分布情况,可以看出,特征在数值和整体规律上都有一定的相似性和差异性。因此,站点进行移动模式旨在有效地将具有相似移动规律的站点划分成一类。在时空预测任务中,为了验证在移动模式下的多模式预测的有效性,这里分别设置t
h-t
p
为12-12和72-72,移动模式数量设置为k∈{2,3,4,5,6},并展示了模型的在长期时空预测中的计算时间开销。实验结果如表4所示。
[0120][0121]
表4
[0122]
通过观察可以看到,多模式的预测方式可以有效的减少计算开销,并且提高预测的精度。选取预测效果最好的移动模式数量,即k=3,各个模式的站点数量分别为396,478和246。接下来,对各个模式的进行聚类分析的可视化:对同一移动模式下的站点流量分布进行平均并展示;对站点聚类结果进行pca降维并展示,结果如图5所示,不同颜色代表不同的移动模式。观察发现,不同移动模式下的站点的差异,例如各自的高峰时间段存在差异,不同移动模式的特征降维后具有明显区分度。
[0123]
注:所有深度模型网络的实现、训练和测试等实验,均由pytorch实现,在google colab平台上运行。
[0124]
(4)结合(2)和(3)所得结果,进行整合得到最终的站点的交通预测结果。
[0125]
a).使用stgnnformer和mpgnnformer进行短期时空预测,并评估其预测表现。另外,由于自相关机制在短期时空预测上无法体现其优势,将使用自注意力机制进行。基线对比方法包括最新的基于gcn的时空预测模型:stgcn,astgcn、stsgcn、graphwavenet、agcrn。在短期时空预测任务中,各个模型输入步长为th=12,评估的输出步长为t
p
∈{3,6,12},评估结果如表5所示。从表5可以看出,本文的mpgnnformer实现了最优的预测效果。另外,随着时序长度的增加,其他的基于gcn的方法在效果上普遍地会下降,而stgnnformer和
mpgnnformer对短期的时序长度的变化并不敏感,存在一定的优势。虽然stgnnformer和mpgnnformer在预测效果上有所提升,但是其在模型参数量、计算效率是不如其他基线方法,因此其优势在短期时空预测任务中并不是特别突出。
[0126][0127]
表5
[0128]
b).进一步测试stgnnformer和mpgnnformer在长期时空预测的表现,以及其在计算效率上的情况,基线对比方法为transformer,以及两个最新的基于transformer的长时序预测模型:informer和informer*(informer的一个变体)。在长期时空预测任务中,各个模型输入步长为th=72,评估的输出步长为t
p
∈{12,36,72,108,156}(分别对应着真实小时数:1,3,6,9,13),最长的预测时间步长(156)恰好为一天的时空数据,预测表现和计算效率的评估结果如表6所示。相较于基线方法,stgnnformer和mpgnnformer在预测精度的表现上基本都是最好的,但是由于需要计算空间上的依赖关系,stgnnformer的计算效率较低,而mpgnnformer采取多模式的方式不仅可以一定程度提高预测精度,还能大大降低每次训练所需的节点数量计算效率高,也足以实现实时预测。
[0129][0130]
表6。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
