1.本发明涉及计算机领域,具体地,涉及一种基于线上多用户pdf文件生成、分配及管理的方法及系统。
背景技术:
2.如今企业线上平台以及线上协议签署,渐渐取消原有的线下纸质签署,无纸化智能化越来越成为市场的刚需。对于协议中字段动态填充然后生成pdf等文件,目前处理是前端处理html填充字段然后使用第三方插件转成pdf等文件。这样处理会很消耗前端性能,对于大文件的生成,会大大降低用户的体验感。
3.专利文献cn110008195b(申请号:cn201910290777.9)公开了一种动态配置html转pdf的方法、装置及系统。该专利的html转pdf是在前端web服务器生成,对于大的文件,很消耗前端web服务器性能。但该发明没有开发一个转换中台,使得转pdf等文件完全脱离前端界面。
4.专利文献cn110516191a(申请号:cn201910811771.1)公开了一种网页页面数据转换成图片文件的方法及装置,其中该网页页面数据转换成图片文件的方法包括:接收所述网页页面数据对应的目标网址,并调用网页验收测试工具操作浏览器访问所述目标网址;加载所述目标网址对应的目标网页,并判断所述目标网页是否已经加载完毕;若是,则使用所述网页验收测试工具对所述目标网页进行截图,形成目标网页图片;将所述目标网页图片导出并保存至指定地址。但该发明并不是转换成pdf。
技术实现要素:
5.针对现有技术中的缺陷,本发明的目的是提供一种基于线上多用户pdf文件生成、分配及管理的方法及系统。
6.根据本发明提供的一种基于线上多用户pdf文件生成、分配及管理的方法,包括:
7.步骤s1:通过模版文件配置模块选取用户对应的html文件模版配置,并发送模版配置请求给服务端,从服务端获取该用户配置对应的html模版;
8.步骤s2:服务端根据请求的html模版同时获取对应需要向html模版中填充的数据,服务端将数据返回给web端,web端进行文件对象模型操作,将数据依次插入html模版中对应的位置;
9.步骤s3:调用node文件处理服务;
10.步骤s4:将填充好数据的html文件传入node文件处理服务转换成pdf文件,输出转换好的pdf文件。
11.优选地,在所述步骤s1中:
12.从服务端获取用户配置对应的html模版,所述模版为未填充数据的文件的html格式的模版,并且用户能够预览模版;
13.步骤s1.1:用户通过模版文件配置模块选取某个用户对应的html文件模版配置,
并发送模版配置请求给服务端,服务端收到该配置请求,筛取出对应的模版返回给web端;
14.模版文件配置模块是以用户为维度,管理该用户下的所有html文件模版配置,能够在web页面中的用户列表中选取某个用户,查看该用户下的所有html文件模版,能够在该用户下添加新的html文件模版,修改html文件模版,替换html模版,以及删除html模版;
15.步骤s1.2:web端获取到未填充数据的文件的html模版,用户通过web端操作查看该模版内容;
16.文件的格式、字体和字号大小都集成在html模版,预览时文件样式为生成pdf后文件的样式。
17.优选地,在所述步骤s2中:
18.步骤s2.1:服务端根据请求端html模版,同时获取该模版对应的需要向html模版中填充的数据,服务端将数据返回给web端;
19.步骤s2.2:web端进行文件对象模型操作定位到每个需要填充数据的位置,然后依次将需要填充到对应位置的数据依次填入指定位置;
20.步骤s2.3:填充完数据之后,对整个文件数据填充的位置进行数据判断是否为空值处理,如果存在空值,则调取数据字段配置文件,配置文件中对每个字段都有是否允许为空值的标识,依次判断各个空值是否为允许为空的值,如果是允许为空的值则跳过检验,如果不是允许为空的值,记录整个文件中存在必填值项、存在空值,并且提示用户文件中存在空值,填充好数据之后,用户能够预览填充好数据的完整的文件内容。
21.优选地,在所述步骤s3中:
22.将puppeteer的page.pdf写成node文件处理服务,作为html转pdf的模块,将通过填充参数空值检测的填充好数据的html文件传入node文件处理服务。
23.优选地,在所述步骤s4中:
24.步骤s4.1:通过填充参数空值检测的填充好数据的html文件在node文件处理服务中通过puppeteer的page.pdf的对应的api调取转换成pdf文件,即为已填充好不要数据的pdf文件;
25.步骤s4.2:node文件处理服务将转换好的pdf文件输出到想要使用的地方;
26.或者node文件处理服务将转换好的pdf文件以及发送的模版配置,输出给模版文件配置模块,模版文件配置模块通过发送的模版配置匹配用户以及对应的html模版文件,输出并归纳到该用户的对应的html文件模版的pdf文件;
27.模版文件配置模块匹配用户以及对应的html模版文件,是根据发送的模版配置中用户标识以及html模版标识,定位到该pdf属于某个用户下的某个html文件模版的pdf文件。
28.根据本发明提供的一种基于线上多用户pdf文件生成、分配及管理的系统,包括:
29.模块m1:通过模版文件配置模块选取用户对应的html文件模版配置,并发送模版配置请求给服务端,从服务端获取该用户配置对应的html模版;
30.模块m2:服务端根据请求的html模版同时获取对应需要向html模版中填充的数据,服务端将数据返回给web端,web端进行文件对象模型操作,将数据依次插入html模版中对应的位置;
31.模块m3:调用node文件处理服务;
32.模块m4:将填充好数据的html文件传入node文件处理服务转换成pdf文件,输出转换好的pdf文件。
33.优选地,在所述模块m1中:
34.从服务端获取用户配置对应的html模版,所述模版为未填充数据的文件的html格式的模版,并且用户能够预览模版;
35.模块m1.1:用户通过模版文件配置模块选取某个用户对应的html文件模版配置,并发送模版配置请求给服务端,服务端收到该配置请求,筛取出对应的模版返回给web端;
36.模版文件配置模块是以用户为维度,管理该用户下的所有html文件模版配置,能够在web页面中的用户列表中选取某个用户,查看该用户下的所有html文件模版,能够在该用户下添加新的html文件模版,修改html文件模版,替换html模版,以及删除html模版;
37.模块m1.2:web端获取到未填充数据的文件的html模版,用户通过web端操作查看该模版内容;
38.文件的格式、字体和字号大小都集成在html模版,预览时文件样式为生成pdf后文件的样式。
39.优选地,在所述模块m2中:
40.模块m2.1:服务端根据请求端html模版,同时获取该模版对应的需要向html模版中填充的数据,服务端将数据返回给web端;
41.模块m2.2:web端进行文件对象模型操作定位到每个需要填充数据的位置,然后依次将需要填充到对应位置的数据依次填入指定位置;
42.模块m2.3:填充完数据之后,对整个文件数据填充的位置进行数据判断是否为空值处理,如果存在空值,则调取数据字段配置文件,配置文件中对每个字段都有是否允许为空值的标识,依次判断各个空值是否为允许为空的值,如果是允许为空的值则跳过检验,如果不是允许为空的值,记录整个文件中存在必填值项、存在空值,并且提示用户文件中存在空值,填充好数据之后,用户能够预览填充好数据的完整的文件内容。
43.优选地,在所述模块m3中:
44.将puppeteer的page.pdf写成node文件处理服务,作为html转pdf的模块,将通过填充参数空值检测的填充好数据的html文件传入node文件处理服务。
45.优选地,在所述模块m4中:
46.模块m4.1:通过填充参数空值检测的填充好数据的html文件在node文件处理服务中通过puppeteer的page.pdf的对应的api调取转换成pdf文件,即为已填充好不要数据的pdf文件;
47.模块m4.2:node文件处理服务将转换好的pdf文件输出到想要使用的地方;或者node文件处理服务将转换好的pdf文件以及发送的模版配置,输出给模版文件配置模块,模版文件配置模块通过发送的模版配置匹配用户以及对应的html模版文件,输出并归纳到该用户的对应的html文件模版的pdf文件;
48.模版文件配置模块匹配用户以及对应的html模版文件,是根据发送的模版配置中用户标识以及html模版标识,定位到该pdf属于某个用户下的某个html文件模版的pdf文件。
49.与现有技术相比,本发明具有如下的有益效果:
50.1、本发明开发一个转换中台,转pdf等文件完全脱离前端界面,互不影响,大大提升生成文件的前端性能以及用户体验感;
51.2、本发明增加一个企业(或用户)模版配置模块,该模块可以动态配置各个企业(或用户)对应的所有线上模版文件,企业(或用户)入住平台或者撤离平台更加灵活,对于企业(或用户)文件动态获取及操作更加更加灵活便捷,并且方便线上文件的企业(或用户)级别管理。
附图说明
52.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
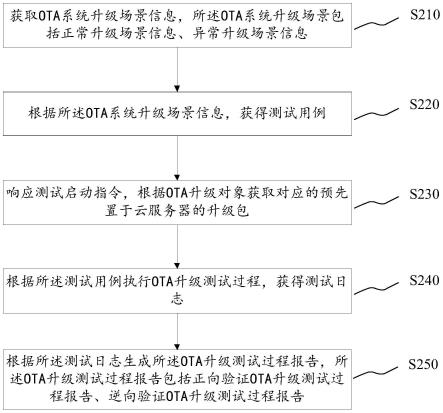
53.图1为本发明流程图。
具体实施方式
54.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
55.实施例1:
56.本发明提供了一种基于线上多用户pdf文件生成、分配及管理的方法及系统,用户发送模板配置请求给service端,获取到需要生成文件的html模版文件,从service端获取需要填充到文件中到数据,进行dom操作动态将数据填充到html模版文件中。将puppeteer的page.pdf写成node文件处理服务,作为html转pdf的模块。将填充好数据的html模版文件调用该node文件处理服务模块转成pdf。将该pdf存储到服务端,以便随时读取使用。在此基础上加入平台企业(或用户)模版文件配置模块,该模块可单独处理各个企业(或用户)的模版文件(上传、更新等等)。对于文件生成可以准确定位到对应的企业(或用户)。方便文件管理。
57.根据本发明提供的一种基于线上多用户pdf文件生成、分配及管理的方法,如图1所示,包括:
58.步骤s1:通过模版文件配置模块选取用户对应的html文件模版配置,并发送模版配置请求给服务端,从服务端获取该用户配置对应的html模版;
59.具体地,在所述步骤s1中:
60.从服务端获取用户配置对应的html模版,所述模版为未填充数据的文件的html格式的模版,并且用户能够预览模版;
61.步骤s1.1:用户通过模版文件配置模块选取某个用户对应的html文件模版配置,并发送模版配置请求给服务端,服务端收到该配置请求,筛取出对应的模版返回给web端;
62.模版文件配置模块是以用户为维度,管理该用户下的所有html文件模版配置,能够在web页面中的用户列表中选取某个用户,查看该用户下的所有html文件模版,能够在该用户下添加新的html文件模版,修改html文件模版,替换html模版,以及删除html模版;
63.步骤s1.2:web端获取到未填充数据的文件的html模版,用户通过web端操作查看
该模版内容;
64.文件的格式、字体和字号大小都集成在html模版,预览时文件样式为生成pdf后文件的样式。
65.步骤s2:服务端根据请求的html模版同时获取对应需要向html模版中填充的数据,服务端将数据返回给web端,web端进行文件对象模型操作,将数据依次插入html模版中对应的位置;
66.具体地,在所述步骤s2中:
67.步骤s2.1:服务端根据请求端html模版,同时获取该模版对应的需要向html模版中填充的数据,服务端将数据返回给web端;
68.步骤s2.2:web端进行文件对象模型操作定位到每个需要填充数据的位置,然后依次将需要填充到对应位置的数据依次填入指定位置;
69.步骤s2.3:填充完数据之后,对整个文件数据填充的位置进行数据判断是否为空值处理,如果存在空值,则调取数据字段配置文件,配置文件中对每个字段都有是否允许为空值的标识,依次判断各个空值是否为允许为空的值,如果是允许为空的值则跳过检验,如果不是允许为空的值,记录整个文件中存在必填值项、存在空值,并且提示用户文件中存在空值,填充好数据之后,用户能够预览填充好数据的完整的文件内容。
70.步骤s3:调用node文件处理服务;
71.具体地,在所述步骤s3中:
72.将puppeteer的page.pdf写成node文件处理服务,作为html转pdf的模块,将通过填充参数空值检测的填充好数据的html文件传入node文件处理服务。
73.步骤s4:将填充好数据的html文件传入node文件处理服务转换成pdf文件,输出转换好的pdf文件。
74.具体地,在所述步骤s4中:
75.步骤s4.1:通过填充参数空值检测的填充好数据的html文件在node文件处理服务中通过puppeteer的page.pdf的对应的api调取转换成pdf文件,即为已填充好不要数据的pdf文件;
76.步骤s4.2:node文件处理服务将转换好的pdf文件输出到想要使用的地方;
77.或者node文件处理服务将转换好的pdf文件以及发送的模版配置,输出给模版文件配置模块,模版文件配置模块通过发送的模版配置匹配用户以及对应的html模版文件,输出并归纳到该用户的对应的html文件模版的pdf文件;
78.模版文件配置模块匹配用户以及对应的html模版文件,是根据发送的模版配置中用户标识以及html模版标识,定位到该pdf属于某个用户下的某个html文件模版的pdf文件。
79.根据本发明提供的一种基于线上多用户pdf文件生成、分配及管理的系统,包括:
80.模块m1:通过模版文件配置模块选取用户对应的html文件模版配置,并发送模版配置请求给服务端,从服务端获取该用户配置对应的html模版;
81.具体地,在所述模块m1中:
82.从服务端获取用户配置对应的html模版,所述模版为未填充数据的文件的html格式的模版,并且用户能够预览模版;
83.模块m1.1:用户通过模版文件配置模块选取某个用户对应的html文件模版配置,并发送模版配置请求给服务端,服务端收到该配置请求,筛取出对应的模版返回给web端;
84.模版文件配置模块是以用户为维度,管理该用户下的所有html文件模版配置,能够在web页面中的用户列表中选取某个用户,查看该用户下的所有html文件模版,能够在该用户下添加新的html文件模版,修改html文件模版,替换html模版,以及删除html模版;
85.模块m1.2:web端获取到未填充数据的文件的html模版,用户通过web端操作查看该模版内容;
86.文件的格式、字体和字号大小都集成在html模版,预览时文件样式为生成pdf后文件的样式。
87.模块m2:服务端根据请求的html模版同时获取对应需要向html模版中填充的数据,服务端将数据返回给web端,web端进行文件对象模型操作,将数据依次插入html模版中对应的位置;
88.具体地,在所述模块m2中:
89.模块m2.1:服务端根据请求端html模版,同时获取该模版对应的需要向html模版中填充的数据,服务端将数据返回给web端;
90.模块m2.2:web端进行文件对象模型操作定位到每个需要填充数据的位置,然后依次将需要填充到对应位置的数据依次填入指定位置;
91.模块m2.3:填充完数据之后,对整个文件数据填充的位置进行数据判断是否为空值处理,如果存在空值,则调取数据字段配置文件,配置文件中对每个字段都有是否允许为空值的标识,依次判断各个空值是否为允许为空的值,如果是允许为空的值则跳过检验,如果不是允许为空的值,记录整个文件中存在必填值项、存在空值,并且提示用户文件中存在空值,填充好数据之后,用户能够预览填充好数据的完整的文件内容。
92.模块m3:调用node文件处理服务;
93.具体地,在所述模块m3中:
94.将puppeteer的page.pdf写成node文件处理服务,作为html转pdf的模块,将通过填充参数空值检测的填充好数据的html文件传入node文件处理服务。
95.模块m4:将填充好数据的html文件传入node文件处理服务转换成pdf文件,输出转换好的pdf文件。
96.具体地,在所述模块m4中:
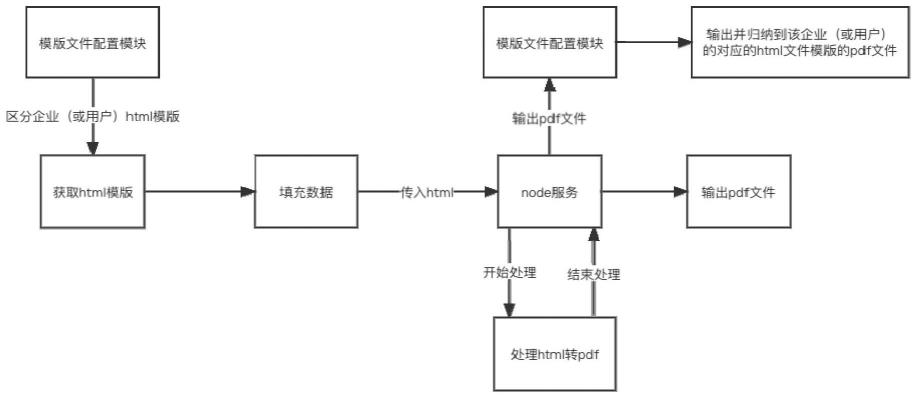
97.模块m4.1:通过填充参数空值检测的填充好数据的html文件在node文件处理服务中通过puppeteer的page.pdf的对应的api调取转换成pdf文件,即为已填充好不要数据的pdf文件;
98.模块m4.2:node文件处理服务将转换好的pdf文件输出到想要使用的地方;或者node文件处理服务将转换好的pdf文件以及发送的模版配置,输出给模版文件配置模块,模版文件配置模块通过发送的模版配置匹配用户以及对应的html模版文件,输出并归纳到该用户的对应的html文件模版的pdf文件;
99.模版文件配置模块匹配用户以及对应的html模版文件,是根据发送的模版配置中用户标识以及html模版标识,定位到该pdf属于某个用户下的某个html文件模版的pdf文件。
100.实施例2:
101.实施例2为实施例1的优选例,以更为具体地对本发明进行说明。
102.步骤1:用户通过模版文件配置模块选取某个企业(或用户)对应的html文件模版配置,并发送模版配置请求给service端,从service端获取该企业(或用户)配置对应的html模版,该模版为未填充数据的文件的html格式的模版,并且用户可以预览该模版。
103.所述步骤1包括如下步骤:
104.步骤1.1:用户通过模版文件配置模块选取某个企业(或用户)对应的html文件模版配置,并发送模版配置请求给service端,service收到该配置请求,筛取出对应的模版返回给web端。
105.说明:模版文件配置模块,是以企业(或用户)为维度,管理该企业(或用户)下的所有html文件模版配置。可以在web页面中的企业(或用户)列表中选取某个企业(或用户)查看该企业(或用户)下的所有html文件模版,同样的,可以在该企业(或用户)下添加新的html文件模版,修改html文件模版,替换html模版,以及删除html模版。
106.步骤1.2:web端获取到未填充数据的文件的html模版,用户可以通过web端操作查看该模版内容。(文件的格式以及字体以及字号大小等样式,都集成在该html模版,即预览时文件样式即为生成pdf后文件的样式,同样的,下文步骤html转pdf时,html模版中集成的样式会影响pdf文件样式。)
107.步骤2:service端根据步骤1.1中请求的html模版同时获取对应需要向html模版中填充的数据,service端将数据返回给web端,web端进行dom操作,将数据依次插入html模版中对应的位置。
108.所述步骤2包括如下步骤:
109.步骤2.1:service端根据步骤1.1中请求端html模版,同时获取该模版对应的需要向html模版中填充的数据,service端将数据返回给web端。
110.步骤2.2:web端进行dom操作定位到每个需要填充数据的位置,然后依次将需要填充到对应位置的数据依次填入指定位置。
111.步骤2.3:填充完数据之后,对整个文件数据填充的位置进行数据判断是否为空值处理,如果存在空值,则调取数据字段配置文件(配置文件中对每个字段都有是否允许为空值的标识),依次判断各个空值是否为“允许为空”的值,如果是“允许为空”的值则跳过检验,否则记录整个文件中存在必填值项存在空值,并且提示用户文件中存在空值。填充好数据之后,用户可以预览填充好数据的完整的文件内容。
112.步骤3:调用node文件处理服务(将puppeteer的page.pdf写成node文件处理服务,作为html转pdf的模块),将步骤2.3中通过填充参数空值检测的填充好数据的html文件传入node文件处理服务。html文件在node文件处理服务中转换成pdf文件,输出转换好的pdf文件。
113.步骤3.1:将puppeteer的page.pdf写成node文件处理服务,作为html转pdf的模块。将步骤2.3中通过填充参数空值检测的填充好数据的html文件传入该node文件处理服务。
114.步骤3.2:通过填充参数空值检测的填充好数据的html文件在node文件处理服务中通过puppeteer的page.pdf的对应的api调取转换成pdf文件(即为已填充好不要数据的
pdf文件)。
115.步骤3.3:node文件处理服务将转换好的pdf文件输出到想要使用的地方。
116.步骤3.4:或者node文件处理服务将转换好的pdf文件以及步骤1.1中发送的模版配置,输出给模版文件配置模块,模版文件配置模块通过步骤1.1中发送的模版配置匹配企业(或用户)以及对应的html模版文件,输出并归纳到该企业(或用户)的对应的html文件模版的pdf文件,以便文件作为企业(或用户)级别管理。
117.说明:模版文件配置模块匹配企业(或用户)以及对应的html模版文件,是根据步骤1.1中发送的模版配置中企业(或用户)标识以及html模版标识,定位到该pdf属于某个企业(或用户)下的某个html文件模版的pdf文件。
118.本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
119.以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。