1.本发明涉及中文文本情感分析技术领域,尤其涉及一种知识与数据驱动的多粒度中文文本情感分析方法。
背景技术:
2.近年来,中文情感分析受到研究人员的广泛关注并取得了长足进步。目前,中文文本情感分析研究成果可以归纳为三类:一是知识驱动的情感分析研究,二是数据驱动的情感分析研究,三是知识与数据协同驱动的情感分析研究。
3.知识驱动的情感分析研究主要通过构建知识图谱,然后从知识图谱中获取有效的显式特征,制定相应的知识抽取规则进行情感识别。目前知识驱动的情感分析研究还不多,仅有的研究是许智宏等为充分利用影评数据提高影视推荐效果,构建出具有特定属性的影视与评论知识图谱,提出了一种半自动的影评知识抽取方法。该方法先对预处理后的影评数据进行句法分析、构建情感词典、数据标注等操作来制定知识抽取规则,然后结合词典和抽象量化聚类进行知识抽取,获得影评结构化知识,最后与电影本体知识进行融合成为影视与评论知识图谱,进而应用于情感分析。虽然知识驱动的情感分析研究很容易理解,但该类研究往往忽略文本的上下文,无法捕获到深层的语义信息,且其泛化能力较差。
4.数据驱动的情感分析研究主要基于传统方法和深度学习方法展开研究。传统方法利用情感词典或机器学习模型进行情感分析,该方法虽能取得一定效果,但需耗费大量的人力、物力和资源来人工设计复杂的语义和语法特征,其适用性与泛化性能受到极大限制。鉴于深度学习模型能够自动完成特征提取和语义表征,克服传统方法的缺陷,研究人员开始将其引入到文本情感分析。基于深度学习的方法主要通过深度学习模型对字、词等特征进行深层次语义特征提取,进而识别文本情感倾向。数据驱动的情感分析方法虽能很好的捕捉上下文和目标之间的语法和语义信息,但它们在有效整合外部知识以帮助理解文本方面存在不足。
5.知识与数据协同驱动的情感分析研究主要将知识图谱表示为知识向量,并与深度学习模型得到的特征向量进行融合来进行文本情感分析。学者们注意到知识驱动的情感分析和数据驱动的情感分析各自的优势与不足,因此将两者相结合,利用知识图谱中的先验知识为深度学习模型提供监督信号,提高深度学习模型的语义解析能力,以获得语义信息更加丰富的文本表示,用于情感识别。该类研究目前大都应用于英文文本情感分析。在semeval 2014task4数据集和twitter数据集上的实验表明,该方法分类效果较优。
6.对相关研究进行梳理可以看出,学者们在文本情感分析研究中取得了一系列研究成果,随着研究的深入,面临一些重要挑战:首先,数据驱动的情感分析研究中,其使用的中文文本情感分析方法大多借鉴英文文本情感分析方法,忽略了中文(象形文字)与英文(拉丁文字)的本质区别;其次,一些研究认识到字、词、词性特征对于情感分析的重要性,并将字、词、词性特征进行融合,以助力情感分析,但除字、词、词性等特征外,能否引入更多特征实现更高性能的情感识别尚未深入研究;最后,知识与数据协同驱动的情感分析研究大都
基于英文文本和英文知识图谱进行研究,而基于中文知识图谱和中文文本的情感分析研究尚未进行探讨。
技术实现要素:
7.为了解决现有技术的不足,本发明提供了一种知识与数据驱动的多粒度中文文本情感分析方法,在对字、词、部首、词性向量化表示的基础上,通过双向门控循环单元、注意力机制等模型进行特征提取,得到特征向量,通过transe模型将情感知识图谱表示为情感知识向量,通过多头注意力机制将特征向量与情感知识向量进行特征融合,获得知识增强的特征向量,最后将该特征向量通过全连接层和分类函数进行情感倾向识别。
8.本发明为解决其技术问题所采用的技术方案是:提供了一种知识与数据驱动的多粒度中文文本情感分析方法,包括以下步骤:
9.s1、将中文文本进行预处理,形成字级文本、字级部首文本、词文本、词级部首文本和词性文本这5类输入数据;
10.s2、利用词嵌入方法,将输入数据转换为由字向量、字级部首向量、词向量、词级部首向量和词性向量这5类向量各自组成的集合;
11.s3、利用bigru模型与点积注意力机制,将字向量与字级部首向量进行特征融合得到字-部首特征向量,将词向量与词级部首向量进行特征融合得到词-部首特征向量,将词向量与词性向量进行特征融合得到词-词性特征向量;
12.s4、利用情感词汇本体库构建情感知识图谱,将情感知识图谱中的三元组进行分布式向量表示,得到情感知识向量;通过多头注意力机制,分别将字-部首特征向量、词-部首特征向量和词-词性特征向量与情感知识向量进行融合,得到知识增强后的字-部首特征输出向量、知识增强后的词-部首特征向量和知识增强后的词-词性特征向量;
13.s5、对增强后的字-部首特征输出向量、增强后的词-部首特征向量和增强后的词-词性特征向量进行输出处理,生成情感识别结果。
14.步骤s1具体包括以下过程:
15.s1.1、对于由m个字组成的输入文本t,其为字级文本tc={c1,c2,...,cm},其中各元素表示t中的每个字;利用分词工具将输入文本t切分为n个词,即词文本tw={w1,w2,...,wn},其中各元素表示t中的每个词;
16.s1.2、根据新华字典的部首映射关系对字级文本tc和词文本tw处理,分别得到字级部首文本t
rc
={rc1,rc2,...,rcm}和词级部首文本t
rw
={rw1,rw2,...,rwn},字级部首文本t
rc
中各元素表示字级部首,词级部首文本中各元素表示词级部首;利用jieba词性标注工具将词文本tw转换为词性文本t
pos
={pos1,pos2,...,posn},其中各元素表示词对应的词性,至此得到输入数据{tc,t
rc
,tw,t
rw
,t
pos
}。
17.步骤s2中具体采用词嵌入方法对输入数据进行转换,得到向量集合{ec,e
rc
,ew,e
rw
,e
pos
},其中:
18.表示字向量集合,当中各元素表示字向量;
19.表示字级部首向量集合,当中各元素表示字级部首向量;
20.表示词向量集合,当中各元素表示词向量;
21.表示词级部首向量集合,当中各元素表示词级部首向量;
22.表示词性向量集合,当中各元素表示词性向量。
23.步骤s3中利用bigru模型与点积注意力机制,将字向量与字级部首向量进行特征融合得到字-部首特征向量,具体包括以下过程:
24.s3.1、将bigruc模型的初始状态均置为0,将字向量集合ec输入bigruc模型,通过以下公式得到字特征向量集合其中各元素表示字特征向量,计算式为:
[0025][0026]
s3.2、通过点积注意力机制分别将yc与字级部首向量集合e
rc
进行特征融合,得到融合后的向量计算式为:
[0027][0028][0029]
其中αi表示字级部首向量集合e
rc
中第i个元素和字特征向量集合yc中第i个元素y
ic
点积运算后的权重矩阵,
·
表示点积运算,t为矩阵转置操作,softmax(
·
)表示softmax归一化函数;
[0030]
s3.3、将作为bigru
rc
模型的输入向量,将bigruc模型最后时刻的隐层状态传递给bigru
rc
模型作为初始状态,进而得到字-部首特征向量集合其中各元素表示字-部首特征向量,计算式为:
[0031][0032]
步骤s4中知识增强后的字-部首特征输出向量具体通过以下过程得到:
[0033]
s4.1、将情感词汇本体库中的情感词作为头实体h,将情感类别作为尾实体t,将情感词的情感强度作为关系r,构建情感知识图谱;
[0034]
s4.2、通过transe模型将情感知识图谱中的三元组进行分布式向量表示,得到情感知识向量k
r_c
;
[0035]
s4.3、将多头注意力机制将字-部首特征向量集合v
r_c
作为query向量、将情感知识向量k
r_c
作为对应的key向量和value向量进行特征融合,得到知识增强后的特征输出向量计算式为:
[0036]kr_c
=transe(h,r,t)
[0037][0038]
其中transe(
·
)表示transe模型,multihead(
·
)为多头注意力机制。
[0039]
步骤s5具体包括以下过程:
[0040]
s5.1、对增强后的字-部首特征输出向量增强后的词-部首特征向量和增强后的词-词性特征向量进行最大值池化操作,再通过向量拼接进行特征融合,得到融合后的特征向量vy;
[0041]
s5.2、将融合后的特征向量vy输入全连接神经网络,利用softmax函数进行归一化处理,得到概率输出p;
[0042]
s5.3、选择概率最大的值作为情感识别结果y。
[0043]
本发明基于其技术方案所具有的有益效果在于:
[0044]
本发明针对中文文本的特殊性和情感分析的实际需求,利用汉字部首和词语的词性助力中文文本语义理解,围绕中文情感分析问题展开研究,其次在中文情感分析领域引入“知识 数据”的研究范式,通过将情感知识向量与深度模型的特征向量进行融合,充分挖掘字、词、部首、词性等特征的潜在语义和情感信息,提高了中文情感分析的能力,进一步丰富了中文情感分析的理论体系和方法体系,同时通过实验验证了本发明方法在中文情感分析上带来的性能提升。
附图说明
[0045]
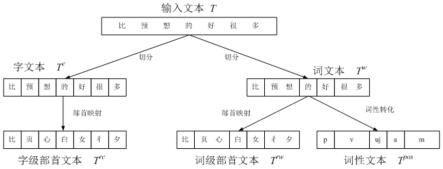
图1是文本转换过程实例示意图。
[0046]
图2是skip-gram模型结构示意图。
[0047]
图3是字-部首特征向量生成示意图。
[0048]
图4是transe模型原理示意图。
[0049]
图5是输出向量的生成过程示意图。
[0050]
图6是输出过程示意图。
具体实施方式
[0051]
下面结合附图和实施例对本发明作进一步说明。
[0052]
本发明提供了一种知识与数据驱动的多粒度中文文本情感分析方法,包括以下步骤:
[0053]
s1、将中文文本进行预处理,形成字级文本、字级部首文本、词文本、词级部首文本和词性文本这5类输入数据。具体包括以下过程:
[0054]
s1.1、对于由m个字组成的输入文本t,其为字级文本tc={c1,c2,...,cm},其中ci(i=1,2,...,m)表示t中的每个字;利用jieba分词工具将输入文本t切分为n个词,即词文本tw={w1,w2,...,wn},其中wi(i=1,2,...,n)表示t中的每个词;
[0055]
s1.2、根据新华字典的部首映射关系对字级文本tc和词文本tw处理,分别得到字级部首文本t
rc
={rc1,rc2,...,rcm}和词级部首文本t
rw
={rw1,rw2,...,rwn},其中rci(i=1,2,...,m)表示字级部首,rwi(i=1,2,...,n)表示词级部首;利用jieba词性标注工具将词文本tw转换为词性文本t
pos
={pos1,pos2,...,posn},其中posi(i=1,2,...,n)表示词对应的词性,至此得到输入数据{tc,t
rc
,tw,t
rw
,t
pos
}。
[0056]
由上述分析可知,|tc|=|t
rc
|,|tw|=|t
rw
|=|t
pos
|,|
·
|表示文本规模。图1以“比预想的好很多”文本为例,给出了输入文本的转换过程。
[0057]
s2、利用词嵌入方法,将输入数据转换为由字向量、字级部首向量、词向量、词级部首向量和词性向量这5类向量各自组成的集合。具体而言,采用word2vec词嵌入方法对输入数据进行转换,得到向量集合{ec,e
rc
,ew,e
rw
,e
pos
},其中:
[0058]
表示字向量集合,当中各元素表示字向量;
[0059]
表示字级部首向量集合,当中各元素表示字级部首向量;
[0060]
表示词向量集合,当中各元素表示词向量;
[0061]
表示词级部首向量集合,当中各元素表示词级部首向量;
[0062]
表示词性向量集合,当中各元素表示词性向量。
[0063]
word2vec方法训练向量时有连续词袋模型(continuous bag of words,cbow)和跳字模型(skip-gram)。鉴于skip-gram模型在大规模语料中训练得到的向量质量更优,故本文均使用该模型对输入数据进行向量化表示。以词向量为例,skip-gram模型通过中心词wc来预测上下文背景词wo的概率。其模型结构如图2所示,其中w
t
表示wc,w
t-2
、w
t-1
、w
t 1
、w
t 2
表示wo,sum为求和操作。
[0064]
该模型将每个词语都表示为中心词的词向量和背景词的词向量,以此来计算中心词和待预测背景词之间的条件概率,如下式所示:
[0065][0066]
其中,p表示条件概率,wc表示中心词,wo表示背景词,vc表示中心词的词向量,vo表示背景词的词向量,n表示词典大小,c、o、i表示单词在词典中的索引,exp(
·
)表示以自然常数e为底的指数函数。
[0067]
s3、利用bigru模型与点积注意力机制,将字向量与字级部首向量进行特征融合得到字-部首特征向量,将词向量与词级部首向量进行特征融合得到词-部首特征向量,将词向量与词性向量进行特征融合得到词-词性特征向量。
[0068]
鉴于中文文本具有显著的序列特征,故采用bigru模型作为基础模型。该模型通过拼接具有正向和反向的gru模型的特征向量,实现了文本上下文语义特征的有效利用。gru模型的工作原理如下式所示:
[0069]rt
=sigmoid(x
t
×wxr
h
t-1
×whr
br)
[0070]zt
=sigmoid(x
t
×wxz
h
t-1
×whz
bz)
[0071][0072][0073]
其中,x
t
为t时刻的输入向量,r
t
和z
t
分别表示t时刻的重置门和更新门,w和b为对应的权重矩阵和偏置向量,表示候选记忆单元,sigmoid(
·
)和tanh(
·
)表示激活函数,h
t
为当前时刻的输出向量,
⊙
为哈达玛积,
×
表示矩阵乘法。
[0074]
bigru的原理如下式所示:
[0075][0076][0077][0078]
其中,x
t
为t时刻的输入向量,分别表示正向和反向gru模型得到的特征向
量,y
t
为当前时刻bigru模型得到的特征向量。
[0079]
注意力机制(attention)的灵感来源于人的注意力,即能通过给输入数据分配不同的权重,以区分其重要程度。从实现方法来看,注意力机制主要通过线性加权的方式和点积的方式实现,两者效果没有本质区别,而点积方式计算速度更快,因此本文通过点积注意力机制进行特征融合。其计算过程如下式所示:
[0080]
attention(q,k,v)=softmax(qk
t
)v
[0081]
其中q和k为query矩阵和key矩阵,v为value矩阵,softmax(
·
)表示归一化函数。
[0082]
基于上述分析,特征提取层利用bigru模型与点积注意力机制,将字向量与字级部首向量进行特征融合,得到字-部首特征向量,将词向量与词级部首向量进行特征融合,得到词-部首特征向量,将词向量与词性向量进行特征融合,得到词-词性特征向量。
[0083]
参照图3,以字-部首特征向量的生成为例,具体包括以下过程:
[0084]
s3.1、将bigruc模型的初始状态均置为0,将字向量集合ec输入bigruc模型,通过以下公式得到字特征向量集合其中表示字特征向量,计算式为:
[0085][0086]
s3.2、通过点积注意力机制分别将yc与字级部首向量集合e
rc
进行特征融合,得到融合后的向量计算式为:
[0087][0088][0089]
其中αi表示字级部首向量集合e
rc
中第i个元素和字特征向量集合yc中第i个元素y
ic
点积运算后的权重矩阵,
·
表示点积运算,t为矩阵转置操作,softmax(
·
)表示softmax归一化函数;
[0090]
s3.3、将作为bigru
rc
模型的输入向量,并将bigruc模型最后时刻的隐层状态传递给bigru
rc
模型作为初始状态,进而得到字-部首特征向量集合:
[0091]
其中表示字-部首特征向量,计算式为:
[0092][0093]
同理,词-部首特征向量和词-词性特征向量的生成过程与字-部首特征向量类似,最终得到词-部首特征向量集合:
[0094]
以及词-词性特征向量集合:
[0095][0096]
其中表示词-部首特征向量,表示词-词性特征向量。
[0097]
s4、利用情感词汇本体库构建情感知识图谱,将情感知识图谱中的三元组进行分布式向量表示,得到情感知识向量;通过多头注意力机制,分别将字-部首特征向量、词-部首特征向量和词-词性特征向量与情感知识向量进行融合,得到知识增强后的字-部首特征输出向量、知识增强后的词-部首特征向量和知识增强后的词-词性特征向量。
[0098]
transe模型属于知识图谱嵌入模型,该模型将知识图谱中的实体和关系进行分布
式向量表示,进而得到实体语义向量。transe模型的原理图如图4所示。
[0099]
令头实体为h,尾实体为t,关系为r,则对于给定的三元组(h,r,t),transe模型将其表示为图5中的(h,r,t),其中h为头实体的向量表示,r为关系的向量表示,t为尾实体的向量表示。在transe模型训练过程中,令h r≈t时的三元组为正样本三元组,h r≠t时的三元组为负样本三元组,通过构造目标损失函数l使得正样本三元组之间的距离变小,负样本三元组的距离变大,l计算公式如下式所示:
[0100]
d(h,r,t)=||h r-t||
l1/l2
[0101][0102]
其中d为衡量h r与t两个向量之间的距离函数,||
·
||表示欧式距离,其使用l1或l2范数来计算,s
表示正样本三元组集合,s-表示负样本三元组集合,γ指的损失函数中的间隔,该参数大于0。
[0103]
多头注意力(multi-head attention,multihead)机制通过将多个注意力机制进行横向拼接来增强模型的关注能力,进而可以表征不同位置、不同方面的语义信息。其原理为:
[0104]
headi=attention(qw
iq
,kw
ik
,vw
iv
)
[0105]
multihead(q,k,v)=concat(head1,head2,...,headh)wo[0106]
其中,head表示注意力的头,h表示头的个数,q、k和v为query向量、key向量和value向量,分别为第i个head的query、key和value的权重矩阵,wo为权重矩阵,concat(
·
)表示拼接函数,和concat(
·
)wo表示图1中的linear层运算。
[0107]
经过上述分析,以增强后的字-部首特征输出向量生成过程为例,参照图5,具体过程为:
[0108]
s4.1、使用大连理工大学情感词汇本体库中约2.7万个情感词作为头实体h,将21种情感类别作为尾实体t,将情感词的情感强度作为关系r,进而构建情感知识图谱;
[0109]
s4.2、通过transe模型将情感知识图谱中的三元组进行分布式向量表示,得到情感知识向量k
r_c
、k
r_w
和k
pos_w
(这三者为同一向量);
[0110]
s4.3、将多头注意力机制将字-部首特征向量集合v
r_c
作为query向量、将情感知识向量k
r_c
作为对应的key向量和value向量进行特征融合,得到知识增强后的特征输出向量计算式为:
[0111]kr_c
=transe(h,r,t)
[0112][0113]
其中transe(
·
)表示transe模型,multihead(
·
)为多头注意力机制。
[0114]
同理可得到增强后的词-部首特征向量和增强后的词-词性特征向量
[0115]
s5、对增强后的字-部首特征输出向量、增强后的词-部首特征向量和增强后的词-词性特征向量进行输出处理,生成情感识别结果。参照图6,具体过程为:
[0116]
s5.1、对增强后的字-部首特征输出向量增强后的词-部首特征向量和增强后的词-词性特征向量进行最大值池化操作,再通过向量拼接进行特征融合,得到融合
后的特征向量vy;
[0117]
s5.2、将融合后的特征向量vy输入全连接神经网络,利用softmax函数进行归一化处理,得到概率输出p;
[0118]
s5.3、选择概率最大的值作为情感识别结果y。计算式为:
[0119][0120]
p=softmax(wvy b)
[0121]
y=argmax(p)
[0122]
其中concat(
·
)表示拼接函数,max(
·
)为最大池化操作,w表示权重矩阵,b表示偏置,softmax(
·
)表示归一化函数,argmax(
·
)表示概率最大函数。
[0123]
为验证本发明方法的有效性,进行实验分析。
[0124]
实验环境与配置如表1所示:
[0125][0126]
表1实验环境与配置
[0127]
实验所用数据集为nlpecc数据集和自制的豆瓣电影数据集。其中nlpecc数据集共计44875条样本,其情感标签有喜好、悲伤、厌恶、愤怒、高兴和其他六种。实验中将nlpecc数据集划分为训练集、验证集和测试集,其比例为6:2:2。自制的豆瓣电影数据集为从豆瓣电影上爬取的《大圣归来》、《夏洛特烦恼》、《美国队长3》、《小时代3》、《七月与安生》5部电影评论数据,数据规模约30万条。对这些数据进行数据清洗、全角字符转为半角字符、标点符号归一化、英文字母大写转小写、繁简转化、去重等预处理后,得到约25万条评论数据。表2给出了预处理后数据的统计信息。
[0128][0129]
表2预处理后的数据集信息
[0130]
将1星评论和2星评论归为负面评论,将3星评论归为中立评论,将4星评论和5星评
论归为正面评论,由于中立评论的情感标签打分错误率太高,无法满足实验要求,故舍弃中立评论。因此负面评论约6.7万条,正面评论约14万条,正面和负面的评论数量不平衡,为了解决数据不平衡问题,从正面评论和负面评论中随机抽取5万条评论作为实验数据集,构建了规模总数为10万条电影评论的实验数据集。在实验中,将实验数据集等分为10分,训练集、验证集和测试集比例为6:2:2。即训练集共6万条(正、负面评论各3万条),验证集共2万条(正、负面评论各1万条),测试集2万条(正、负面评论各1万条)。
[0131]
实验所提模型的超参数设置如表3所示:
[0132][0133]
表3超参数设置
[0134]
实验采用准确率(precision,p)、召回率(recall,r)以及调和平均值(f1-score,f1)来衡量情感识别性能。其计算公式为:
[0135][0136][0137][0138]
其中,真正例(true positive,tp)表示被正确分类的正例样本,假正例(false positive,fp)表示被错误分类的正例样本,假负例(false negative,fn)表示被错误分类的负例样本。而p表示模型预测正确的正例样本占预测为正例的样本的比例,r表示模型预测正确的正例样本中占实际为正例的样本的比例。
[0139]
将本发明提出的一种知识与数据驱动的多粒度中文文本情感分析方法(keamm)与以下现有的中文文本情感分析模型进行对比:
[0140]
(1)bigru。该模型使用双向门控循环单元对词向量进行特征提取,实现文本情感分析。
[0141]
(2)dccnn。该模型采用不同通道进行卷积运算,其中一个通道为字向量,另一个为词向量,通过融合两个通道的特征进行情感分析。
[0142]
(3)fg_mccnn。该模型通过cnn模型的多通道综合利用字向量、词向量、词向量与词性融合的词性对向量进行情感分析。
[0143]
(4)bert-bilstm。该模型使用bert模型构造字向量,然后利用bilstm进行特征提
取,以实现情感识别。
[0144]
(5)bert-mcnn。该模型为融合bert模型与多层协同卷积神经网络的情感分析模型。
[0145]
本发明以字、词、部首、词性等特征作为输入。为了验证本发明方法中每个模块的有效性,调整模型结构后进行以下消融实验:
[0146]
(1)two bigrus。使用两个bigru模型分别字文本和词文本进行建模,将两者的输出向量进行拼接,并进行情感识别。
[0147]
(2)four bigrus。使用四个bigru分别对字文本、字级部首文本、词文本、词级部首文本进行建模,将四个通道经bigru的输出向量进行拼接,并进行情感识别。
[0148]
(3)five bigrus。该模型舍弃keamm模型中通过注意力机制将字、词、部首、词性进行特征融合的方式,而是通过五个bigru分别对字文本、字级部首文本、词文本、词级部首文本和词性文本进行特征提取,将五个通道上经bigru的输出特征向量进行拼接,并进行情感识别。
[0149]
(4)attention-based multi-granularity model(amm)。舍弃keamm模型中知识引入的部分,即去除特征融合层,将特征提取层输出的特征向量进行拼接,并进行情感识别。
[0150]
(5)keamm。本文所提模型。
[0151]
表4给出了以上各个模型在实验数据集上的实验结果。
[0152][0153][0154]
表4实验结果
[0155]
针对豆瓣电影数据集和nlpecc数据集,通过将表4对比实验与消融实验中的模型实验结果进行综合分析,可以得出以下结论。
[0156]
其中bigru模型为只使用词特征的模型,其f1值分别为85.63%和77.70%,而two bigrus模型为同时利用字特征和词特征的双通道模型,其f1值分别为86.58%和79.35%,two bigrus模型的f1值相较于bigru模型分别提升了0.95%和1.65%,这表明同时利用字、词特征,能将字词各自的优势结合起来,提取到更丰富的语义特征助力情感分析。
[0157]
通过对比dccnn模型与fg_mccnn模型可以发现,dccnn模型为同时利用字特征和词特征的双通道cnn模型,其f1值分别为86.53%和79.32%,fg_mccnn模型为综合利用字特征、词特征以及词性特征的三通道cnn模型,其f1值分别为86.92%和80.47%,后者的f1值比前者分别提高了0.39%和1.15%,这表明词性特征能为情感识别性能的提升带来增量。消融实验中five bigrus模型的f1值相较于four bigrus模型分别提高了0.34%和0.43%也证实了这一结论。
[0158]
dccnn模型的f1值分别为86.53%和79.32%,two bigrus模型的f1值分别为86.58%和79.35%,后者的f1值比前者分别提高了0.05%和0.03%,分析发现,这两类模型均为同时利用字特征和词特征的双通道模型,区别在于前者使用cnn作为基础模型,后者使用bigru作为基础模型,因此造成two bigrus模型的f1值较dccnn模型略高的原因在于cnn模型的卷积特性会造成文本语义特征的丢失,而bigru模型能够学习到上下文的长期依赖关系,进而捕捉到丰富的文本语义特征,从而导致结果更优。
[0159]
由上述分析可知,本实验中cnn模型的性能弱于bigru模型,而表4中four bigrus的f1值分别为87.07%和80.80%,相较于two bigrus分别提升了0.49%和1.45%,相较于dccnn模型分别提升了0.53%和1.48%;five bigrus模型的f1值分别为87.41%和81.23%,相较于fg_mccnn模型分别提升了0.49%和0.76%。这表明了部首特征对于中文情感分析具有一定作用,另一方面证明了融合多个有效特征能为情感识别的性能带来提升。
[0160]
amm模型的f1值分别为88.24%和82.20%,相较于five bigru分别提升了0.83%和0.97%,对比两类模型可以发现,five bigrus模型只是将不同粒度的特征通过简单拼接进行特征融合,在特征提取过程中,字、词、部首、词性等特征间均没有进行任何信息交互,而amm模型通过bigru模型提取字、词特征,并利用点积注意力机制将其分别与部首特征和词性特征进行信息交互与融合,使得融合后的特征向量能从字、词、部首、词性的深层次语义特征中感知情感倾向,进而提升情感识别性能。
[0161]
bert-bilstm的f1值分别为88.25%和82.99%,bert-mcnn模型的f1值分别为88.68%和83.14%,这两类模型高于以amm模型为代表的各类基准模型与消融模型,其识别性能仅低于本文所提模型keamm,这主要因为bert模型可以动态的表示文本向量,且能根据情感分析任务为语义表征能力进行微调,帮助模型学习领域知识,进而产生更为丰富的语义特征,因此带来了性能的提升。
[0162]
最后,本发明的f1值达到了89.23%和84.84%,超过了所有的对比模型,这证明了本发明的有效性与优越性。该模型相较于消融实验中的amm模型,其f1值分别提升了0.99%和2.64%,相较于对比实验中的bert-bilstm模型,其f1值分别提升了0.98%和1.85%,相较于bert-mcnn模型,其f1值分别提升了0.55%和1.7%。分析得知amm、bert-bilstm和bert-mcnn模型是没有引入情感知识的,而keamm模型通过多头注意力机制将情感知识向量引入到amm模型中,进而使得keamm模型的性能超过了bert-mcnn等一众模型,这表明在中文情感分析中,引入显式的情感知识能够指导深度模型进行更为精准的情感分析,进而带来性能的提升。
[0163]
本发明提供的一种知识与数据驱动的多粒度中文文本情感分析方法基于中文文本的特殊性以及情感分析的实际需求,将“知识 数据”的研究范式引入中文情感分析领域,将情感知识向量与bigru模型与注意力机制得到的特征向量进行深度融合,提出融入字、
词、部首、词性等多粒度特征的中文文本情感分析方法。通过对比实验和消融实验的结果表明,本发明方法在f1值上较其他模型有明显提升。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。