技术特征:
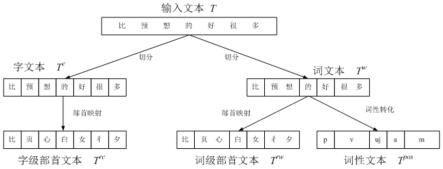
1.一种知识与数据驱动的多粒度中文文本情感分析方法,其特征在于包括以下步骤:s1、将中文文本进行预处理,形成字级文本、字级部首文本、词文本、词级部首文本和词性文本这5类输入数据;s2、利用词嵌入方法,将输入数据转换为由字向量、字级部首向量、词向量、词级部首向量和词性向量这5类向量各自组成的集合;s3、利用bigru模型与点积注意力机制,将字向量与字级部首向量进行特征融合得到字-部首特征向量,将词向量与词级部首向量进行特征融合得到词-部首特征向量,将词向量与词性向量进行特征融合得到词-词性特征向量;s4、利用情感词汇本体库构建情感知识图谱,将情感知识图谱中的三元组进行分布式向量表示,得到情感知识向量;通过多头注意力机制,分别将字-部首特征向量、词-部首特征向量和词-词性特征向量与情感知识向量进行融合,得到知识增强后的字-部首特征输出向量、知识增强后的词-部首特征向量和知识增强后的词-词性特征向量;s5、对增强后的字-部首特征输出向量、增强后的词-部首特征向量和增强后的词-词性特征向量进行输出处理,生成情感识别结果。2.根据权利要求1所述的知识与数据驱动的多粒度中文文本情感分析方法,其特征在于:步骤s1具体包括以下过程:s1.1、对于由m个字组成的输入文本t,其为字级文本t
c
={c1,c2,...,c
m
},其中各元素表示t中的每个字;利用分词工具将输入文本t切分为n个词,即词文本t
w
={w1,w2,...,w
n
},其中各元素表示t中的每个词;s1.2、根据新华字典的部首映射关系对字级文本t
c
和词文本t
w
处理,分别得到字级部首文本t
rc
={rc1,rc2,...,rc
m
}和词级部首文本t
rw
={rw1,rw2,...,rw
n
},字级部首文本t
rc
中各元素表示字级部首,词级部首文本中各元素表示词级部首;利用jieba词性标注工具将词文本t
w
转换为词性文本t
pos
={pos1,pos2,...,pos
n
},其中各元素表示词对应的词性,至此得到输入数据{t
c
,t
rc
,t
w
,t
rw
,t
pos
}。3.根据权利要求2所述的知识与数据驱动的多粒度中文文本情感分析方法,其特征在于:步骤s2中具体采用词嵌入方法对输入数据进行转换,得到向量集合{e
c
,e
rc
,e
w
,e
rw
,e
pos
},其中:表示字向量集合,当中各元素表示字向量;表示字级部首向量集合,当中各元素表示字级部首向量;表示词向量集合,当中各元素表示词向量;表示词级部首向量集合,当中各元素表示词级部首向量;表示词性向量集合,当中各元素表示词性向量。4.根据权利要求3所述的知识与数据驱动的多粒度中文文本情感分析方法,其特征在于:步骤s3中利用bigru模型与点积注意力机制,将字向量与字级部首向量进行特征融合得到字-部首特征向量,具体包括以下过程:s3.1、将bigru
c
模型的初始状态均置为0,将字向量集合e
c
输入bigru
c
模型,通过以下公式得到字特征向量集合其中各元素表示字特征向量,计算式为:
s3.2、通过点积注意力机制分别将y
c
与字级部首向量集合e
rc
进行特征融合,得到融合后的向量计算式为:计算式为:其中α
i
表示字级部首向量集合e
rc
中第i个元素和字特征向量集合y
c
中第i个元素点积运算后的权重矩阵,
·
表示点积运算,t为矩阵转置操作,softmax(
·
)表示softmax归一化函数;s3.3、将作为bigru
rc
模型的输入向量,将bigru
c
模型最后时刻的隐层状态传递给bigru
rc
模型作为初始状态,进而得到字-部首特征向量集合其中各元素表示字-部首特征向量,计算式为:5.根据权利要求4所述的知识与数据驱动的多粒度中文文本情感分析方法,其特征在于:步骤s4中知识增强后的字-部首特征输出向量具体通过以下过程得到:s4.1、将情感词汇本体库中的情感词作为头实体h,将情感类别作为尾实体t,将情感词的情感强度作为关系r,构建情感知识图谱;s4.2、通过transe模型将情感知识图谱中的三元组进行分布式向量表示,得到情感知识向量k
r_c
;s4.3、将多头注意力机制将字-部首特征向量集合v
r_c
作为query向量、将情感知识向量k
r_c
作为对应的key向量和value向量进行特征融合,得到知识增强后的特征输出向量计算式为:k
r_c
=transe(h,r,t)其中transe(
·
)表示transe模型,multihead(
·
)为多头注意力机制。6.根据权利要求5所述的知识与数据驱动的多粒度中文文本情感分析方法,其特征在于:步骤s5具体包括以下过程:s5.1、对增强后的字-部首特征输出向量增强后的词-部首特征向量和增强后的词-词性特征向量进行最大值池化操作,再通过向量拼接进行特征融合,得到融合后的特征向量v
y
;s5.2、将融合后的特征向量v
y
输入全连接神经网络,利用softmax函数进行归一化处理,得到概率输出p;s5.3、选择概率最大的值作为情感识别结果y。
技术总结
本发明提供了一种知识与数据驱动的多粒度中文文本情感分析方法,在对字、词、部首、词性向量化表示的基础上,通过双向门控循环单元、注意力机制等模型进行特征提取,得到特征向量,通过TransE模型将情感知识图谱表示为情感知识向量,通过多头注意力机制将特征向量与情感知识向量进行特征融合,获得知识增强的特征向量,最后将该特征向量通过全连接层和分类函数进行情感倾向识别。通过对比实验和消融实验的结果表明,本发明方法在F1值上较其他模型有明显提升。有明显提升。有明显提升。
技术研发人员:刘忠宝 张兴芹
受保护的技术使用者:山东外国语职业技术大学
技术研发日:2022.07.15
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。