1.本公开涉及计算机技术领域,具体地,涉及一种计算资源调度方法和装置、存储介质和电子设备。
背景技术:
2.随着计算机技术的发展和普及,生活中使用计算机进行计算和规划的场景越来越多,巨大的数据量为计算机计算带来了挑战,若使用少量的节点计算大量的数据,则单个节点的计算负荷较重,导致节点的计算能力、计算速度下降;若使用大量的节点计算少量的数据,则会造成计算资源的浪费;即使计算节点的数量与数据的总量相适应,由于在一些场景下的数据包是不可分割的,数据包内容有大有小,随机的数据分配可能使一些节点负荷过重,而另一些节点计算资源闲置,造成了计算节点的计算效率低下的问题。
3.应该将哪些数据分别分配给哪些计算节点进行计算,才可以使每个节点既不过负载计算,又不会过于空闲,如何使各个计算节点的计算效率最高化,一直是本领域的技术难题。
技术实现要素:
4.本公开的目的是提供一种计算资源调度方法和装置、存储介质和电子设备,已解决上述的技术问题。
5.为了实现上述目的,本公开的第一方面,提供一种计算资源调度方法,包括:确定待计算的至少一个数据集;确定至少一个计算节点的剩余计算容量;针对每个所述数据集,根据所述数据集的数据量,将所述剩余计算容量与所述数据量匹配的所述计算节点作为与所述数据集匹配的计算节点;将每个所述数据集分配至与所述数据集匹配的计算节点,以使分配到数据集的所述计算节点对所述数据集进行计算。
6.可选地,所述针对每个所述数据集,根据所述数据集的数据量,将所述剩余计算容量与所述数据量匹配的所述计算节点作为与所述数据集匹配的计算节点,包括:将所述数据集按数据量大小进行排序,得到第一序列;将所述计算节点按所述剩余计算容量大小进行排序,得到第二序列,其中,所述第二序列与所述第一序列的大小排序方式相同;将所述第一序列中的数据集与所述第二序列中对应序列位置的计算节点匹配。
7.可选地,所述方法还包括:在每个所述计算节点均匹配有数据集后,重新确定所述计算节点的剩余计算容量;将所述计算节点按重新确定的所述剩余计算容量大小进行排序,得到第三序列,所述第三序列与所述第一序列的大小排序方式相同;将所述第一序列中尚未匹配计算节点的数据集,与所述第三序列中对应序列位置的计算节点匹配。
8.可选地,所述方法还包括:在与所述数据集匹配的所述计算节点的剩余计算容量小于所述数据集的所述数据量的情况下,跳过所述计算节点的序列位置,为所述数据集匹配下一序列位置的计算节点,并将剩余计算容量小于所述数据量的所述计算节点加入待扩容节点列表。
9.可选地,在所有序列位置的所述计算节点均加入待扩容节点列表时,对所述待扩容节点列表中的计算节点进行扩容;将扩容后的计算节点按剩余计算容量大小进行排序,得到第四序列,所述第四序列与所述第一序列的大小排序方式相同;将所述第一序列中尚未匹配计算节点的数据集,与所述第四序列中对应序列位置的计算节点匹配。
10.可选地,在所述确定至少一个计算节点的剩余计算容量之前,所述方法还包括:获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度;所述计算节点的所述剩余计算容量与所述计算速度成正相关关系。
11.可选地,所述在确定待计算的至少一个数据集之前,所述方法还包括:获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度和/或计算时间;将满足预设计算效率条件的计算节点确定为故障节点,并在本次分配中禁用所述故障节点;所述计算效率条件包括:所述计算速度小于第一速度阈值,和/或所述计算时间大于第一时间阈值;所述确定至少一个计算节点的剩余计算容量,包括:确定非故障节点的至少一个计算节点的剩余计算容量。
12.可选地,所述方法还包括:在数据集分配后,获取各个所述计算节点的计算速度和/或计算时间;根据各个所述计算节点的所述计算速度和/或所述计算时间,计算平均计算速度和/或者平均计算时间;在满足预设扩容条件下,对各个所述计算节点进行扩容;所述预设扩容条件包括以下任意一种情况或几种情况的组合:所述平均计算速度小于第二速度阈值;所述平均计算时间大于第二时间阈值;当前时刻处于业务洪峰时期;当前时刻处于压力测试时期。
13.本公开的第二方面,提供一种计算资源调度装置,所述装置包括:第一确定模块,用于确定待计算的至少一个数据集;第二确定模块,用于确定至少一个计算节点的剩余计算容量;匹配模块,用于针对每个所述数据集,根据所述数据集的数据量,将所述剩余计算容量与所述数据量匹配的所述计算节点作为与所述数据集匹配的计算节点;分配模块,用于将每个所述数据集分配至与所述数据集匹配的计算节点,以使分配到数据集的所述计算节点对所述数据集进行计算。
14.可选地,所述匹配模块,还包括:第一排序子模块,用于将所述数据集按数据量大小进行排序,得到第一序列,并将所述计算节点按所述剩余计算容量大小进行排序,得到第二序列,其中,所述第二序列与所述第一序列的大小排序方式相同;第一匹配子模块,用于将所述第一序列中的数据集与所述第二序列中对应序列位置的计算节点匹配。
15.可选地,所述匹配模块,还包括:第二排序子模块,用于在每个所述计算节点均匹配有数据集后,重新确定所述计算节点的剩余计算容量,并将所述计算节点按重新确定的所述剩余计算容量大小进行排序,得到第三序列,所述第三序列与所述第一序列的大小排序方式相同;第二匹配子模块,用于将所述第一序列中尚未匹配计算节点的数据集,与所述第三序列中对应序列位置的计算节点匹配。
16.可选地,所述匹配模块,还用于在与所述数据集匹配的所述计算节点的剩余计算容量小于所述数据集的所述数据量的情况下,跳过所述计算节点的序列位置,为所述数据集匹配下一序列位置的计算节点,并将剩余计算容量小于所述数据量的所述计算节点加入待扩容节点列表。
17.可选地,所述匹配模块,还用于在所有序列位置的所述计算节点均加入待扩容节
点列表时,对所述待扩容节点列表中的计算节点进行扩容;所述匹配模块,还包括,第三排序子模块,用于将扩容后的计算节点按剩余计算容量大小进行排序,得到第四序列,所述第四序列与所述第一序列的大小排序方式相同;所述匹配模块,还包括,第三匹配子模块,用于将所述第一序列中尚未匹配计算节点的数据集,与所述第四序列中对应序列位置的计算节点匹配。
18.可选地,所述装置还包括,速度确定模块,用于获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度,其中,所述计算节点的所述剩余计算容量与所述计算速度成正相关关系。
19.可选地,所述装置还包括,节点禁用模块,用于获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度和/或计算时间,并将满足预设计算效率条件的计算节点确定为故障节点,并在本次分配中禁用所述故障节点;所述计算效率条件包括:所述计算速度小于第一速度阈值,和/或所述计算时间大于第一时间阈值;所述确定至少一个计算节点的剩余计算容量,包括:确定非故障节点的至少一个计算节点的剩余计算容量。
20.可选地,所述装置还包括,扩容模块,用于在数据集分配后,获取各个所述计算节点的计算速度和/或计算时间,并根据各个所述计算节点的所述计算速度和/或所述计算时间,计算平均计算速度和/或者平均计算时间,并在满足预设扩容条件下,对各个所述计算节点进行扩容;所述预设扩容条件包括以下任意一种情况或几种情况的组合:所述平均计算速度小于第二速度阈值;所述平均计算时间大于第二时间阈值;当前时刻处于业务洪峰时期;当前时刻处于压力测试时期。
21.本公开的第三方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本公开的第一方面中任一项所述方法的步骤。
22.本公开的第四方面,提供了一种电子设备,包括存储器和处理器,存储器上存储有计算机程序,处理器用于执行所述存储器中的所述计算机程序,以实现本公开的第一方面中任一项所述方法的步骤。
23.基于上述的技术方案,至少可以达到以下的技术效果:可以根据待计算的数据集的数据量大小,为其分配剩余计算容量与之匹配的计算节点,而非随机为数据集分配计算节点。这样,计算节点可以分配到与之计算能力相符合的计算节点,不至于让单个计算节点的计算负荷较重,也不至于使单个节点的计算资源空置,可以为计算网络中的各个计算节点分配适合该计算节点的计算工作,从总体上可以提高计算网络的计算效率。
24.本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
25.附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:
26.图1是根据一示例性公开实施例示出的一种计算资源调度方法的流程图。
27.图2是根据一示例性公开实施例示出的一种计算资源调度方法的流程图。
28.图3是根据一示例性公开实施例示出的一种为计算节点匹配数据集的过程示意图。
29.图4是根据一示例性公开实施例示出的一种计算资源调度装置的框图。
30.图5是根据一示例性公开实施例示出的一种电子设备的框图。
具体实施方式
31.以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
32.下面对本公开的应用场景进行说明。本公开可以应用于包括但不限于订单分配、路线规划、配送时间预估等多种需要对数据进行实时运算处理的场景,其中,数据集中可以包括与运算结果相关的原始数据,例如用户订单数据、区域特征数据等。由于实时运算中,数据会随时间变化,每一时刻的数据集内的内容都可能与上一时刻的数据集内的内容有较大差异,每一时刻的数据分配不均匀则会影响各个节点的计算效率,进而影响下一时刻的数据分配及计算。因此,针对每一时刻获取到的数据集,可以重复使用本公开的方案进行分配,以提升每次分配的均匀程度,从而提升各个节点的计算效率。
33.图1是根据一示例性公开实施例示出的一种计算资源调度方法的流程图,如图1所示,所述方法包括以下步骤:
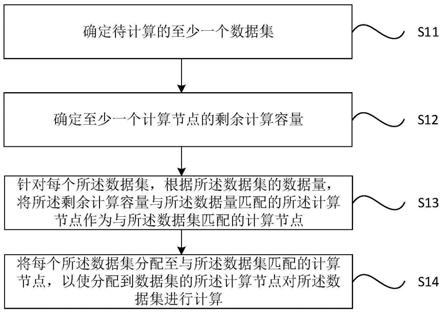
34.s11、确定待计算的至少一个数据集。
35.数据集是待计算的数据内容的集合,其中一个数据集的内容是不可分割的,若将一个数据集分割开,则可能造成数据不连贯,无法进行准确的计算。
36.当本公开应用于配送场景(例如订单分配、路线规划、配送时间预估等)下时,由于配送场景通常与区域特性息息相关,在这些场景下,可以预先将业务地点划分为多个区域,每一时刻下,将每个区域的数据作为一个数据集,参与到数据的分配及计算中。
37.也就是说,该数据集的划分可以是根据地理特征划分的,例如,预先将所有产生待计算数据的地区划分为多个片区,每个片区内获取到的所有待计算数据可以作为一个数据集。值得说明的是,该数据集的划分还可以是根据数据特点划分的,例如,一个数据集内的数据类型相同,都分属于交通数据或都分属于用户订单数据等。
38.每个数据集都有各自的数据量大小,且数据量大小由根据数据集的内容决定,本公开不限制数据集的数据量大小的上下限。例如,数据集a内的数据内容较少且都是文字内容,则其数据量可能很小,例如可以为100kb,而数据集b的数据内容较多且涉及图片内容,则其数据量可能较大,例如可以为300mb。在获取数据集的同时,该数据集的数据量大小已经固定,数据内容也不发生变化。
39.考虑到在一些场景下,数据集的内容可能会出现更新,例如,当数据集的内容为每分钟的订单信息时,数据集的内容每分钟都会变化。在本公开中,可以将变化后的数据集作为新的数据集,在下一次进行数据分配及计算的时,重新收集新的数据集,并将新的数据集作为下一轮分配中的待计算的数据集,与本轮分配中的数据集相区别,其分配和计算互不干扰,这样可以防止实时的数据更新导致数据量大小变化为后续的数据分配带来的影响。
40.s12、确定至少一个计算节点的剩余计算容量。
41.计算节点是指用于计算上述数据集的计算节点。计算机网络中可能存在许多节点,但是有部分节点不具备计算权限,或者,有部分节点不需要在本次计算中启用,则这些不用于计算的节点不作为本公开中的计算节点。
42.计算节点的剩余计算容量与节点的计算能力以及节点正在处理的计算量有关,其
中,节点的计算能力体现于节点的计算容量,以及节点的计算速度。节点的计算速度越快,则节点的计算能力越高,则节点的剩余计算容量也越高。
43.在确定计算节点的剩余计算容量之前,可以确定计算节点的计算速度。其中,该计算速度可以由计算节点上报,也可以是分配服务器通过分配至该节点的数据量及节点的响应时间计算得到。该计算速度可以是一定时间段内的计算速度,也可以是上一次分配到数据集后计算该数据集所用的计算速度。
44.在一种可能的实施方式中,可以获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度,所述计算节点的所述剩余计算容量与所述计算速度成正相关关系。
45.正在处理的计算量,可以是已经分配至该计算节点,该计算节点正在处理的计算任务的总量,也可以是分配服务器为该计算节点匹配了数据集,但尚未将该数据集分配至该计算节点的数据集的总数据量。
46.例如,假设一个计算节点的计算容量为100,计算速度对应的计算速度参数为0.9,正在处理的计算任务为10,已匹配的数据集为20,则该计算节点的剩余计算容量为100
×
0.9-10-20=60(单位省略)。
47.在本公开中,计算节点的数量可以是预设的,也可以是根据数据集的数据量总和确定的。
48.在一种可能的实施方式中,在确定至少一个计算节点的剩余计算容量之前,可以根据数据集的数据量的总和,在所有的计算节点中确定至少一个目标计算节点,所述目标计算节点的剩余计算容量的总和与所述数据集的数据量总和相匹配。
49.值得说明的是,剩余计算容量与数据量的总和相匹配并不意味着两者相同。由于数据集是不可拆分的,在实际分配的过程中,剩余计算容量可能需要大于数据集的数据总量,才可以在不拆分数据集的前提下将数据集分配完成。因此,与数据集相匹配的计算节点的剩余计算容量的总和可以比数据集的数据量总和稍高,例如,当确定所有待计算的数据集的数据量总和为3000时,则可以在所有计算节点中确定30个剩余计算容量为100~120的计算节点为目标计算节点。
50.在一种可能的实施方式中,在确定待计算的至少一个数据集之前,还可以获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度和/或计算时间,并将满足预设计算效率条件的计算节点确定为故障节点,并在本次分配中禁用所述故障节点。在确定计算节点的剩余计算容量时,可以只确定非故障节点的计算节点的剩余计算容量。其中,所述计算效率条件包括:所述计算速度小于第一速度阈值,和/或,所述计算时间大于第一时间阈值。
51.s13、针对每个所述数据集,根据所述数据集的数据量,将所述剩余计算容量与所述数据量匹配的所述计算节点作为与所述数据集匹配的计算节点。
52.例如,当有10个大小为10的数据集,20个大小为15的数据集,4个大小为75的数据集等待分配,且有7个剩余计算容量均为100的计算节点,则可以为每个计算节点匹配与之剩余计算容量相适应的数据集。例如,可以为前四个计算节点匹配大小分别为“75、15、10”的三个数据集,为第五个和第六个计算节点匹配大小分别为“15、15、15、15、15、15、10”的7个数据集,为第七个计算节点匹配大小分别为“15、15、15、15、10、10、10、10”的8个数据集。
这样,每个计算节点都可以得到与自身剩余计算容量相匹配的数据集。
53.在一种可能的实施方式中,可以将所述数据集按数据量大小进行排序,得到第一序列,并将所述计算节点按所述剩余计算容量大小进行排序,得到第二序列(所述第二序列与所述第一序列的大小排序方式相同),将所述第一序列中的数据集与所述第二序列中对应序列位置的计算节点匹配。
54.例如,有大小分别为99(数据集a’)、87(数据集b’)、76(数据集c’)、55(数据集d’)、44(数据集e’)的5个数据集待分配至计算节点(已按照大小顺序排序得到第一序列),且有大小分别为100(节点a)、98(节点b)、90(节点c)、88(节点d)、80(节点e)的五个计算节点(已按照大小顺序排序得到第二序列),则可以将数据集a’匹配至节点a,将数据集b’匹配至节点b,
……
,将数据集e’匹配至节点e。
55.考虑到数据集与计算节点之间的数量可能不对等,则在一种可能的实施方式中,在每个所述计算节点均匹配有数据集后,重新确定所述计算节点的剩余计算容量,并将所述计算节点按重新确定的所述剩余计算容量大小进行排序,得到第三序列(所述第三序列与所述第一序列的大小排序方式相同),并将所述第一序列中尚未匹配计算节点的数据集,与所述第三序列中对应序列位置的计算节点匹配。
56.例如,有大小分别为99(数据集a)、87(数据集b)、76(数据集c)、55(数据集d)、44(数据集e)、34(数据集f)、32(数据集g)、24(数据集h)、10(数据集i)的9个数据集待分配至计算节点(已按照大小顺序排序得到第一序列),且有大小分别为100(节点a)、98(节点b)、90(节点c)、88(节点d)、80(节点e)的五个计算节点(已按照大小顺序排序得到第二序列),则可以将数据集a匹配至节点a,将数据集b匹配至节点b,
……
,将数据集e匹配至节点e。并在五个计算节点均分配有数据集后,重新确定五个计算节点的剩余容量,分别为36(节点e)、33(节点d)、24(节点c)、11(节点b)、1(节点a),则将数据集f分配至节点e,将数据集g分配至节点d,将数据集h分配至节点c,将数据集i分配至节点b。至此所有的数据集分配完毕,且计算节点a~e的剩余计算容量分别为1、2、1、0、1,即,所有的计算节点的工作均饱和且不过载,计算效率较高且资源浪费情况较少。
57.在一种可能的实施方式中,在与所述数据集匹配的所述计算节点的剩余计算容量小于所述数据集的所述数据量的情况下,跳过所述计算节点的序列位置,为所述数据集匹配下一序列位置的计算节点,并将剩余计算容量小于所述数据量的所述计算节点加入待扩容节点列表。
58.例如,有大小分别为99(数据集a”)、87(数据集b”)、76(数据集c”)、55(数据集d”)、44(数据集e”)、34(数据集f”)、32(数据集g”)、24(数据集h”)、10(数据集i”)、2(数据集j”)的10个数据集待分配至计算节点(已按照大小顺序排序得到第一序列),且有大小分别为100(节点a)、98(节点b)、90(节点c)、88(节点d)、80(节点e)的五个计算节点(已按照大小顺序排序得到第二序列),则可以将数据集a”匹配至节点a,将数据集b”匹配至节点b,
……
,将数据集e”匹配至节点e。并在五个计算节点均分配有数据集后,重新确定五个计算节点的剩余容量,分别为36(节点e)、33(节点d)、24(节点c)、11(节点b)、1(节点a),则将数据集f”分配至节点e,将数据集g”分配至节点d,将数据集h”分配至节点c,将数据集i”分配至节点b,在本应将数据集j”分配至节点a时,节点a的剩余计算容量不足,则跳过计算节点a的序列位置,为其匹配下一序列位置的计算节点,并将节点a加入待扩容节点列表。而节点a后没有下
一节点,则可以将五个节点重新排序,得到剩余容量大小分别为2(节点b)、1(节点a)、1(节点c)、1(节点e)和0(节点d),并为数据集j”匹配节点b。
59.在所有序列位置的所述计算节点均加入待扩容节点列表时,对所述待扩容节点列表中的计算节点进行扩容;将扩容后的计算节点按剩余计算容量大小进行排序,得到第四序列,所述第四序列与所述第一序列的大小排序方式相同;将所述第一序列中尚未匹配计算节点的数据集,与所述第四序列中对应序列位置的计算节点匹配。
60.例如,在数据集j”之后还存在数据集k”(大小为2)、l”(大小为2)、m”(大小为1),则在为数据集k”匹配节点时,由于所有的节点的剩余计算容量均不足,则可以将所有计算节点均加入待扩容列表,并为其扩容,将扩容后的计算节点重新排列,并为数据集k”至m”匹配计算节点。
61.s14、将每个所述数据集分配至与所述数据集匹配的计算节点,以使分配到数据集的所述计算节点对所述数据集进行计算。
62.在上一步骤中,仅确定了应当分配至计算节点的数据集,尚未进行分配。在本步骤中,可以确定与计算节点匹配的所有数据集,并一次性将所有与计算节点匹配的数据集发送至该计算节点。例如,若计算节点a在上一步骤中匹配了数据集a,计算节点b在上一步骤中匹配了数据集b和数据集i,计算节点c在上一步骤中匹配了数据集c和数据集h,计算节点d在上一步骤中匹配了数据集d和数据集g,计算节点e在上一步骤中匹配了数据集e合数据集f,则可以一次性将这些与计算节点匹配的数据集分发至各个计算节点,以使分配到数据集的所述计算节点对所述数据集进行计算。
63.在一种可能的实施方式中,在数据集分配后,可以获取各个所述计算节点的计算速度和/或计算时间,并根据各个所述计算节点的所述计算速度和/或所述计算时间,计算平均计算速度和/或者平均计算时间。在满足预设扩容条件下,对各个所述计算节点进行扩容,所述预设扩容条件包括以下任意一种情况或几种情况的组合:所述平均计算速度小于第二速度阈值;所述平均计算时间大于第二时间阈值;当前时刻处于业务洪峰时期;当前时刻处于压力测试时期。
64.基于上述的技术方案,至少可以达到以下的技术效果:可以根据待计算的数据集的数据量大小,为其分配剩余计算容量与之匹配的计算节点,而非随机为数据集分配计算节点。这样,计算节点可以分配到与之计算能力相符合的计算节点,不至于让单个计算节点的计算负荷较重,也不至于使单个节点的计算资源空置,可以为计算网络中的各个计算节点分配适合该计算节点的计算工作,从总体上可以提高计算网络的计算效率。
65.图2是根据一示例性公开实施例示出的一种计算资源调度方法的流程图,如图2所示,所述方法包括以下步骤:
66.s21、确定待计算的至少一个数据集。
67.数据集是待计算的数据内容的集合,其中一个数据集的内容是不可分割的,若将一个数据集分割开,则可能造成数据不连贯,无法进行准确的计算。
68.当本公开应用于配送场景(例如订单分配、路线规划、配送时间预估等)下时,由于配送场景通常与区域特性息息相关,在这些场景下,可以预先将业务地点划分为多个区域,每一时刻下,将每个区域的数据作为一个数据集,参与到数据的分配及计算中。
69.也就是说,该数据集的划分可以是根据地理特征划分的,例如,预先将所有产生待
计算数据的地区划分为多个片区,每个片区内获取到的所有待计算数据可以作为一个数据集。值得说明的是,该数据集的划分还可以是根据数据特点划分的,例如,一个数据集内的数据类型相同,都分属于交通数据或都分属于用户订单数据等。
70.每个数据集都有各自的数据量大小,且数据量大小由根据数据集的内容决定,本公开不限制数据集的数据量大小的上下限。例如,数据集a内的数据内容较少且都是文字内容,则其数据量可能很小,例如可以为100kb,而数据集b的数据内容较多且涉及图片内容,则其数据量可能较大,例如可以为300mb。在获取数据集的同时,该数据集的数据量大小已经固定,数据内容也不发生变化。
71.考虑到在一些场景下,数据集的内容可能会出现更新,例如,当数据集的内容为每分钟的订单信息时,数据集的内容每分钟都会变化。在本公开中,可以将变化后的数据集作为新的数据集,在下一次进行数据分配及计算的时,重新收集新的数据集,并将新的数据集作为下一轮分配中的待计算的数据集,与本轮分配中的数据集相区别,其分配和计算互不干扰,这样可以防止实时的数据更新导致数据量大小变化为后续的数据分配带来的影响。
72.s22、确定至少一个计算节点的剩余计算容量。
73.计算节点是指用于计算上述数据集的计算节点。计算机网络中可能存在许多节点,但是有部分节点不具备计算权限,或者,有部分节点不需要在本次计算中启用,则这些不用于计算的节点不作为本公开中的计算节点。
74.计算节点的剩余计算容量与节点的计算能力以及节点正在处理的计算量有关,其中,节点的计算能力体现于节点的计算容量,以及节点的计算速度。节点的计算速度越快,则节点的计算能力越高,则节点的剩余计算容量也越高。
75.在确定计算节点的剩余计算容量之前,可以确定计算节点的计算速度。其中,该计算速度可以由计算节点上报,也可以是分配服务器通过分配至该节点的数据量及节点的响应时间计算得到。该计算速度可以是一定时间段内的计算速度,也可以是上一次分配到数据集后计算该数据集所用的计算速度。
76.在一种可能的实施方式中,可以获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度,所述计算节点的所述剩余计算容量与所述计算速度成正相关关系。
77.正在处理的计算量,可以是已经分配至该计算节点,该计算节点正在处理的计算任务的总量,也可以是分配服务器为该计算节点匹配了数据集,但尚未将该数据集分配至该计算节点的数据集的总数据量。
78.例如,假设一个计算节点的计算容量为100,计算速度对应的计算速度参数为0.9,正在处理的计算任务为10,已匹配的数据集为20,则该计算节点的剩余计算容量为100
×
0.9-10-20=60(单位省略)。
79.在本公开中,计算节点的数量可以是预设的,也可以是根据数据集的数据量总和确定的。
80.在一种可能的实施方式中,在确定至少一个计算节点的剩余计算容量之前,可以根据数据集的数据量的总和,在所有的计算节点中确定至少一个目标计算节点,所述目标计算节点的剩余计算容量的总和与所述数据集的数据量总和相匹配。
81.值得说明的是,剩余计算容量与数据量的总和相匹配并不意味着两者相同。由于
数据集是不可拆分的,在实际分配的过程中,剩余计算容量可能需要大于数据集的数据总量,才可以在不拆分数据集的前提下将数据集分配完成。因此,与数据集相匹配的计算节点的剩余计算容量的总和可以比数据集的数据量总和稍高,例如,当确定所有待计算的数据集的数据量总和为3000时,则可以在所有计算节点中确定30个剩余计算容量为100~120的计算节点为目标计算节点。
82.在一种可能的实施方式中,在确定待计算的至少一个数据集之前,还可以获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度和/或计算时间,并将满足预设计算效率条件的计算节点确定为故障节点,并在本次分配中禁用所述故障节点。在确定计算节点的剩余计算容量时,可以只确定非故障节点的计算节点的剩余计算容量。其中,所述计算效率条件包括:所述计算速度小于第一速度阈值,和/或,所述计算时间大于第一时间阈值。
83.s23、将所述数据集按数据量大小进行排序,得到第一序列。
84.该第一序列可以为大小升序,也可以为大小降序,本公开对此不做限制。例如,有大小分别为99(数据集a)、87(数据集b)、76(数据集c)、55(数据集d)、44(数据集e)的5个数据集,则该第一序列可以为“a、b、c、d、e”,也可以为“e、d、c、b、a”。
85.s24、将所述计算节点按所述剩余计算容量大小进行排序,得到第二序列。
86.该第二序列视第一序列的排序方式而定,可以为与第一序列相同排序方式的升序序列,可以为与第一序列相同排序方式的降序序列。
87.s25、将所述第一序列中的数据集与所述第二序列中对应序列位置的计算节点匹配。
88.例如,有大小分别为99(数据集a’)、87(数据集b’)、76(数据集c’)、55(数据集d’)、44(数据集e’)的5个数据集待分配至计算节点(已按照大小顺序排序得到第一序列),且有大小分别为100(节点a)、98(节点b)、90(节点c)、88(节点d)、80(节点e)的五个计算节点(已按照大小顺序排序得到第二序列),则可以将数据集a’匹配至节点a,将数据集b’匹配至节点b,
……
,将数据集e’匹配至节点e。
89.考虑到数据集与计算节点之间的数量可能不对等,则在本步骤之后,判断是否所有数据集都有匹配的计算节点,若是,则执行步骤s28,若不是,则执行步骤s26。
90.s26、重新确定所述计算节点的剩余计算容量,将所述计算节点按重新确定的所述剩余计算容量大小进行排序,得到第三序列。
91.该第三序列与所述第一序列的大小排序方式相同。
92.s27、将所述第一序列中尚未匹配计算节点的数据集,与所述第三序列中对应序列位置的计算节点匹配。
93.例如,有大小分别为99(数据集a)、87(数据集b)、76(数据集c)、55(数据集d)、44(数据集e)、34(数据集f)、32(数据集g)、24(数据集h)、10(数据集i)的9个数据集待分配至计算节点(已按照大小顺序排序得到第一序列),且有大小分别为100(节点a)、98(节点b)、90(节点c)、88(节点d)、80(节点e)的五个计算节点(已按照大小顺序排序得到第二序列),则可以将数据集a匹配至节点a,将数据集b匹配至节点b,
……
,将数据集e匹配至节点e。并在五个计算节点均分配有数据集后,重新确定五个计算节点的剩余容量,分别为36(节点e)、33(节点d)、24(节点c)、11(节点b)、1(节点a),则将数据集f分配至节点e,将数据集g分
配至节点d,将数据集h分配至节点c,将数据集i分配至节点b。至此所有的数据集分配完毕,且计算节点a~e的剩余计算容量分别为1、2、1、0、1,即,所有的计算节点的工作均饱和且不过载,计算效率较高且资源浪费情况较少。
94.在一种可能的实施方式中,在步骤s25和步骤s27中,可以在与所述数据集匹配的所述计算节点的剩余计算容量小于所述数据集的所述数据量的情况下,跳过所述计算节点的序列位置,为所述数据集匹配下一序列位置的计算节点,并将剩余计算容量小于所述数据量的所述计算节点加入待扩容节点列表。
95.例如,有大小分别为99(数据集a”)、87(数据集b”)、76(数据集c”)、55(数据集d”)、44(数据集e”)、34(数据集f”)、32(数据集g”)、24(数据集h”)、10(数据集i”)、2(数据集j”)的10个数据集待分配至计算节点(已按照大小顺序排序得到第一序列),且有大小分别为100(节点a)、98(节点b)、90(节点c)、88(节点d)、80(节点e)的五个计算节点(已按照大小顺序排序得到第二序列),则可以将数据集a”匹配至节点a,将数据集b”匹配至节点b,
……
,将数据集e”匹配至节点e。并在五个计算节点均分配有数据集后,重新确定五个计算节点的剩余容量,分别为36(节点e)、33(节点d)、24(节点c)、11(节点b)、1(节点a),则将数据集f”分配至节点e,将数据集g”分配至节点d,将数据集h”分配至节点c,将数据集i”分配至节点b,在本应将数据集j”分配至节点a时,节点a的剩余计算容量不足,则跳过计算节点a的序列位置,为其匹配下一序列位置的计算节点,并将节点a加入待扩容节点列表。而节点a后没有下一节点,则可以将五个节点重新排序,得到剩余容量大小分别为2(节点b)、1(节点a)、1(节点c)、1(节点e)和0(节点d),并为数据集j”匹配节点b。
96.在所有序列位置的所述计算节点均加入待扩容节点列表时,对所述待扩容节点列表中的计算节点进行扩容;将扩容后的计算节点按剩余计算容量大小进行排序,得到第四序列,所述第四序列与所述第一序列的大小排序方式相同;将所述第一序列中尚未匹配计算节点的数据集,与所述第四序列中对应序列位置的计算节点匹配。
97.例如,在数据集j”之后还存在数据集k”(大小为2)、l”(大小为2)、m”(大小为1),则在为数据集k”匹配节点时,由于所有的节点的剩余计算容量均不足,则可以将所有计算节点均加入待扩容列表,并为其扩容,将扩容后的计算节点重新排列,并为数据集k”至m”匹配计算节点。
98.在本步骤完成后,判断是否所有数据集都有匹配的计算节点,若是,则执行步骤s28,若不是,则返回步骤s26。
99.s28、将每个所述数据集分配至与所述数据集匹配的计算节点,以使分配到数据集的所述计算节点对所述数据集进行计算。
100.在上一步骤中,仅确定了应当分配至计算节点的数据集,尚未进行分配。在本步骤中,可以确定与计算节点匹配的所有数据集,并一次性将所有与计算节点匹配的数据集发送至该计算节点。例如,若计算节点a在上一步骤中匹配了数据集a,计算节点b在上一步骤中匹配了数据集b和数据集i,计算节点c在上一步骤中匹配了数据集c和数据集h,计算节点d在上一步骤中匹配了数据集d和数据集g,计算节点e在上一步骤中匹配了数据集e合数据集f,则可以一次性将这些与计算节点匹配的数据集分发至各个计算节点,以使分配到数据集的所述计算节点对所述数据集进行计算。
101.如图3所示的是一种为计算节点匹配数据集的过程示意图,计算节点及待计算的
数据集均以降序排列,在第一次排序的分发时,为各个计算节点分别分发与之序列位置匹配的数据集,在第一次排序的分发完成后,为个个计算节点重新排序,并再次为各个计算节点分别分发与之序列位置匹配的数据集,重复上述的过程,直至所有的数据集分配完毕。
102.在一种可能的实施方式中,在数据集分配后,可以获取各个所述计算节点的计算速度和/或计算时间,并根据各个所述计算节点的所述计算速度和/或所述计算时间,计算平均计算速度和/或者平均计算时间。在满足预设扩容条件下,对各个所述计算节点进行扩容,所述预设扩容条件包括以下任意一种情况或几种情况的组合:所述平均计算速度小于第二速度阈值;所述平均计算时间大于第二时间阈值;当前时刻处于业务洪峰时期;当前时刻处于压力测试时期。
103.基于上述的技术方案,至少可以达到以下的技术效果:可以根据待计算的数据集的数据量大小,为其分配剩余计算容量与之匹配的计算节点,而非随机为数据集分配计算节点。并且,分别为数据集合计算节点按照数据量大小或者剩余计算容量大小进行排序,根据排序更精准的进行匹配,这样,计算节点可以精准地分配到与之计算能力相符合的计算节点,不至于让单个计算节点的计算负荷较重,也不至于使单个节点的计算资源空置,可以为计算网络中的各个计算节点分配适合该计算节点的计算工作,从总体上可以提高计算网络的计算效率。
104.图4是根据一示例性公开实施例示出的一种计算资源调度装置的框图,如图4所示,该装置400包括:
105.第一确定模块410,用于确定待计算的至少一个数据集。
106.第二确定模块420,用于确定至少一个计算节点的剩余计算容量。
107.匹配模块430,用于针对每个所述数据集,根据所述数据集的数据量,将所述剩余计算容量与所述数据量匹配的所述计算节点作为与所述数据集匹配的计算节点。
108.分配模块440,用于将每个所述数据集分配至与所述数据集匹配的计算节点,以使分配到数据集的所述计算节点对所述数据集进行计算。
109.通过上述的技术方案,可以根据待计算的数据集的数据量大小,为其分配剩余计算容量与之匹配的计算节点,而非随机为数据集分配计算节点。这样,计算节点可以分配到与之计算能力相符合的计算节点,不至于让单个计算节点的计算负荷较重,也不至于使单个节点的计算资源空置,可以为计算网络中的各个计算节点分配适合该计算节点的计算工作,从总体上可以提高计算网络的计算效率。
110.可选地,所述匹配模块,还包括:第一排序子模块,用于将所述数据集按数据量大小进行排序,得到第一序列,并将所述计算节点按所述剩余计算容量大小进行排序,得到第二序列,其中,所述第二序列与所述第一序列的大小排序方式相同;第一匹配子模块,用于将所述第一序列中的数据集与所述第二序列中对应序列位置的计算节点匹配。
111.通过排序的方式,将各计算节点的剩余计算容量和各个数据集的数据量大小进行依次匹配,可以更精确地为各计算节点分配到与其计算能力相匹配的数据集。
112.可选地,所述匹配模块,还包括:第二排序子模块,用于在每个所述计算节点均匹配有数据集后,重新确定所述计算节点的剩余计算容量,并将所述计算节点按重新确定的所述剩余计算容量大小进行排序,得到第三序列,所述第三序列与所述第一序列的大小排序方式相同;第二匹配子模块,用于将所述第一序列中尚未匹配计算节点的数据集,与所述
第三序列中对应序列位置的计算节点匹配。
113.值得说明的是,在所有数据集都被分配至计算节点以前,可以由匹配模块中的第二排序子模块和第二匹配子模块重复执行上述步骤,直至每个数据集都分配至计算节点。这样,可以在每一次排序后都按照计算节点的剩余计算容量以及数据集的数据量进行匹配,可以最大化地利用计算节点的剩余计算容量来处理其能力范围内的数据集,使各个计算节点的计算能力接近饱和,从总体上提高计算效率。
114.可选地,所述匹配模块,还用于在与所述数据集匹配的所述计算节点的剩余计算容量小于所述数据集的所述数据量的情况下,跳过所述计算节点的序列位置,为所述数据集匹配下一序列位置的计算节点,并将剩余计算容量小于所述数据量的所述计算节点加入待扩容节点列表。
115.这样,可以及时筛选出剩余计算容量不足的计算节点以便后续扩容,并且为尚不需要扩容的计算节点匹配与之剩余计算容量相符合的数据集,以最大化地利用各个计算节点的计算容量,提升整体的计算效率。
116.可选地,所述匹配模块,还用于在所有序列位置的所述计算节点均加入待扩容节点列表时,对所述待扩容节点列表中的计算节点进行扩容;所述匹配模块,还包括,第三排序子模块,用于将扩容后的计算节点按剩余计算容量大小进行排序,得到第四序列,所述第四序列与所述第一序列的大小排序方式相同;所述匹配模块,还包括,第三匹配子模块,用于将所述第一序列中尚未匹配计算节点的数据集,与所述第四序列中对应序列位置的计算节点匹配。
117.当所有的计算节点都不能满足当前的计算任务时,可以对计算节点进行扩容,相较于现有技术中单个计算节点饱和即对其进行扩容的方案相比,可以在各个节点都饱和后进行扩容,减少扩容带来的不便,减少扩容带来的成本。在所有的计算节点都扩容后,可以重新对计算节点进行排列并为其匹配数据集,以使各个计算节点可以分配到与自身计算能力相符的数据集,提升各个计算节点的任务饱和程度,从整体上提升计算效率。
118.可选地,所述装置还包括,速度确定模块,用于获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度,其中,所述计算节点的所述剩余计算容量与所述计算速度成正相关关系。
119.可选地,所述装置还包括,节点禁用模块,用于获取上一次将所有数据集分配至匹配的计算节点后,各个计算节点的计算速度和/或计算时间,并将满足预设计算效率条件的计算节点确定为故障节点,并在本次分配中禁用所述故障节点;所述计算效率条件包括:所述计算速度小于第一速度阈值,和/或所述计算时间大于第一时间阈值;所述确定至少一个计算节点的剩余计算容量,包括:确定非故障节点的至少一个计算节点的剩余计算容量。
120.这样,可以保证各个待分配计算集的计算节点的计算能力满足计算需求,减少将计算任务分配至故障节点后由于计算效率过低造成的损失。
121.可选地,所述装置还包括,扩容模块,用于在数据集分配后,获取各个所述计算节点的计算速度和/或计算时间,并根据各个所述计算节点的所述计算速度和/或所述计算时间,计算平均计算速度和/或者平均计算时间,并在满足预设扩容条件下,对各个所述计算节点进行扩容;所述预设扩容条件包括以下任意一种情况或几种情况的组合:所述平均计算速度小于第二速度阈值;所述平均计算时间大于第二时间阈值;当前时刻处于业务洪峰
时期;当前时刻处于压力测试时期。
122.这样,可以在各个计算节点总体的计算效率偏低的情况下对各个计算节点进行扩容,可以在特殊情况下大幅提升总体计算效率,满足计算需求。
123.关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
124.基于上述的技术方案,至少可以达到以下的技术效果:可以根据待计算的数据集的数据量大小,为其分配剩余计算容量与之匹配的计算节点,而非随机为数据集分配计算节点。这样,计算节点可以分配到与之计算能力相符合的计算节点,不至于让单个计算节点的计算负荷较重,也不至于使单个节点的计算资源空置,可以为计算网络中的各个计算节点分配适合该计算节点的计算工作,从总体上可以提高计算网络的计算效率。
125.图5是根据一示例性实施例示出的一种电子设备500的框图。如图5所示,该电子设备500可以包括:处理器501,存储器502。该电子设备500还可以包括多媒体组件503,输入/输出(i/o)接口504,以及通信组件505中的一者或多者。
126.其中,处理器501用于控制该电子设备500的整体操作,以完成上述的计算资源调度方法中的全部或部分步骤。存储器502用于存储各种类型的数据以支持在该电子设备500的操作,这些数据例如可以包括用于在该电子设备500上操作的任何应用程序或方法的指令,以及应用程序相关的数据,例如联系人数据、收发的消息、图片、音频、视频等等。该存储器502可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,例如静态随机存取存储器(static random access memory,简称sram),电可擦除可编程只读存储器(electrically erasable programmable read-only memory,简称eeprom),可擦除可编程只读存储器(erasable programmable read-only memory,简称eprom),可编程只读存储器(programmable read-only memory,简称prom),只读存储器(read-only memory,简称rom),磁存储器,快闪存储器,磁盘或光盘。多媒体组件503可以包括屏幕和音频组件。其中屏幕例如可以是触摸屏,音频组件用于输出和/或输入音频信号。例如,音频组件可以包括一个麦克风,麦克风用于接收外部音频信号。所接收的音频信号可以被进一步存储在存储器502或通过通信组件505发送。音频组件还包括至少一个扬声器,用于输出音频信号。i/o接口504为处理器501和其他接口模块之间提供接口,上述其他接口模块可以是键盘,鼠标,按钮等。这些按钮可以是虚拟按钮或者实体按钮。通信组件505用于该电子设备500与其他设备之间进行有线或无线通信。无线通信,例如wi-fi,蓝牙,近场通信(near field communication,简称nfc),2g、3g、4g、nb-iot、emtc、或其他5g等等,或它们中的一种或几种的组合,在此不做限定。因此相应的该通信组件505可以包括:wi-fi模块,蓝牙模块,nfc模块等等。
127.在一示例性实施例中,电子设备500可以被一个或多个应用专用集成电路(application specific integrated circuit,简称asic)、数字信号处理器(digital signal processor,简称dsp)、数字信号处理设备(digital signal processing device,简称dspd)、可编程逻辑器件(programmable logic device,简称pld)、现场可编程门阵列(field programmable gate array,简称fpga)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述的计算资源调度方法。
128.在另一示例性实施例中,还提供了一种包括程序指令的计算机可读存储介质,该
程序指令被处理器执行时实现上述的计算资源调度方法的步骤。例如,该计算机可读存储介质可以为上述包括程序指令的存储器502,上述程序指令可由电子设备500的处理器501执行以完成上述的计算资源调度方法。
129.以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
130.另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
131.此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。