1.本发明涉及人工智能技术领域,尤其涉及一种基于深度强化学习的涂装轨迹智能规划方法、装置及计算机可读存储介质。
背景技术:
2.自1959年工业机器人研制成功后,工业机器人因其高速度、高精度、可重复性的特点逐渐取代了各类生产活动中的人力作业。相较于传统的人工喷涂,使用机器人进行自动化喷涂可以解决人工喷涂中难以控制涂层厚度偏差、难以提高作业效率、难以规避有毒溶剂带来的人体伤害等问题。喷涂机器人自推向市场后发展迅速,被广泛应用于航天、汽车等工业制造领域中。
3.由于航空航天等工业产品大多尺寸庞大、涂料种类特殊,且具有工艺过程复杂、生产模式多变的特点,对智能喷涂工艺提出了更高的要求,需要基于现有喷涂装置和外部环境,选择最优的喷涂参数和最佳的喷涂轨迹。
4.现有技术中,智能喷涂过程中的涂装参数和轨迹多采用工艺试验法或通过过求解以工件表面涂层厚度均匀性为优化目标的优化模型来进行确定。其中,工艺实验法因需要耗费大量的人力物力,且流程复杂,难以满足实时性和安全性的需要。目前,针对优化模型的常用的优化算法有粒子群算法、遗传算法、模拟退火算法等。然而,上述上述传统算法存在的弊端如下:
5.1)具有收敛速度慢、控制变量多等问题;
6.2)在对优化问题进行求解之前,需要获取所有可能的轨迹,是针对已知轨迹的参数寻优方法,具有求解效率低,难以获得全局最优解,没有综合考虑喷涂轨迹和工艺参数之间的组合优化,泛化能力差,不具备通用性的问题。
7.因此,亟需一种能够综合考虑喷涂工艺参数和喷涂轨迹优化的影响的涂装轨迹智能规划方法。
技术实现要素:
8.本发明提供一种基于深度强化学习的涂装轨迹智能规划方法、系统、电子设备及存储介质,以解决现有的技术中的至少一个问题。
9.为实现上述目的,本发明提供的一种基于深度强化学习的涂装轨迹智能规划方法,应用于电子装置,包括:
10.获取待喷涂工件的模型数据,并按照预设的涂装精度标准对待喷涂工件的模型进行格栅化划分,将某一时刻的所有格栅内全部点云涂层厚度的均值进行向量排列,获得初始化的状态向量;
11.将初始化状态向量输入预训练好的基于深度强化学习的涂装控制策略模型,获取喷涂动作向量;并根据喷涂动作向量,确定下一时刻的喷涂轨迹;
12.在仿真环境下,按照喷涂动作向量所对应的下一时刻的喷涂轨迹执行喷涂动作,
利用漆膜厚度沉积模型,确定每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响;
13.根据每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响,更新下一时刻的状态向量;
14.根据下一时刻的状态向量,利用预训练好的基于深度强化学习的涂装控制策略模型确定喷涂动作向量所对应的下一时刻的喷涂轨迹;
15.循环执行,直至确定喷涂过程中每一时刻的状态向量、喷涂动作向量以及喷涂动作向量所对应的喷涂轨迹。
16.进一步,优选的,通过设定最大迭代次数,对基于深度强化学习的涂装控制策略模型进行迭代训练,迭代训练的方法包括:
17.随机初始化基于深度强化学习的涂装控制策略模型的参数,初始化网络训练迭代次数为1,并清空深度强化学习的经验回放池;其中,基于深度强化学习的涂装控制策略模型包括以mn维状态向量s为输入,l维动作向量a为输出的actor网络和actor
target
网络,以及,以l维动作向量a为输入,数值q为输出的critic网络和critic
target
网络;其中,critic网络和critic
target
网络各包括两个网络;基于深度强化学习的涂装控制策略模型的参数包括actor网络的参数、actor
target
网络的参数、critic网络的参数和critic
target
网络的参数;所述actor
target
网络的参数通过复制对应的actor
target
网络的参数得到,critic
target
网络的参数通过复制对应的critic网络的参数得到;
18.更新状态向量s
t
,基于状态向量s
t
获取actor网络的输出喷涂动作向量a
t
;
19.基于喷涂动作向量a
t
计算喷涂动作向量对应的喷涂轨迹t,利用漆膜厚度沉积模型更新待喷涂工件的漆膜厚度分布情况,得到状态向量s
t 1
;
20.基于状态向量s
t 1
和奖励函数r计算实时奖励reward;并以s
tb
=done是否成立,判断喷涂过程是否终止;
21.根据所获取的状态向量s
t
、喷涂动作向量a
t
、动状态向量s
t 1
和实时奖励reward,确定集合{s
t
,a
t
,s
t 1
,reward,s
tb
};
22.将集合{s
t
,a
t
,s
t 1
,reward,s
tb
}存入深度学习的经验回放池d,令t=t 1,循环执行,直至达到经验回放池d的最大容量;
23.从经验回放池d中进行m次随机采样,获得{sj,aj,s
j 1
,reward,s
jb
},j=1,2,...,m,计算当前策略π下理论q值;
24.使用均方差损失函数,通过神经网络的梯度反向传播对critic网络的参数ω进行更新;
25.当迭代次数为延迟更新基数d的整数倍时,使用损失函数通过神经网络的梯度反向传播对actor网络的参数θ进行更新,并将更新后的critic网络的参数和actor网络的参数分别复制给对应的critic
target
网络和actor
target
网络;
26.进行迭代训练,直至达到设定最大迭代次数;获得训练好的基于深度强化学习的涂装控制策略模型。
27.进一步,优选的,状态向量s=(ω0,ω1,ω2,...,ω
mn-1
)
t
,ωi表示数组下标为i的点云簇中所有数据点的漆膜厚度δ的平均值;
28.其中,点云簇ω中数据点ωk处漆膜厚度δ通过以下步骤获取:
29.计算喷枪在轨迹点ti的停留时间t;
30.以轨迹点ti为原点,构建局部坐标系γ
local
和漆膜厚度沉积模型,寻找点云簇ω中位于涂覆面积中的数据点ωk,计算数据点ωk在时间t内获得的漆膜沉积厚度δk;
31.分别计算轨迹t中各轨迹点对数据点ωk所产生的的漆膜沉积厚度δk,则,最终的漆膜厚度δ为:δ=∑δk。
32.进一步,优选的,漆膜厚度沉积模型为由平面涂层厚度模型转换得到的自由曲面涂层厚度分布模型;
33.由平面涂层厚度模型转换得到的自由曲面涂层厚度分布模型,通过以下公式实现:
[0034][0035][0036][0037]
其中,q
ω
表示当前喷涂范围内点云簇ω表面的数据点ωi的涂层厚度沉积速率,q
t
表示基准平面的涂层厚度沉积速率,x,y表示数据点ωi的坐标描述;d表示喷枪中心点到理论平面的距离高度,d'为喷枪中心点到基准平面的距离高度,α表示数据点ωi切平面法矢n与喷枪轴线方向的夹角,θ表示喷枪轴线与垂线段方向的夹角;a0,b0分别表示理论平面上喷涂椭圆的长短轴的长度,q
max
表示理论平面的涂层沉积率系数,β1,β2表示沉积模型分布系数。
[0038]
进一步,优选的,获取待喷涂工件的模型数据,并按照预设的精度标准对待喷涂工件进行格栅化划分的方法,包括,
[0039]
获取待喷涂工件的模型数据;其中,模型数据为点云数据或cad模型数据;
[0040]
根据待喷涂工件的模型数据,利用视觉传感器获取待喷涂工件的三维空间的点云数据,或将所述cad模型数据转换为点云数据;
[0041]
按照精度需求确定分割的间隔尺寸,按照分割的间隔尺寸将待喷涂工件进行m
×
n栅格化划分,并反向映射至三维空间的点云数据中;
[0042]
将三维空间的点云数据分割为m
×
n的点云簇,每个栅格对应一个数组,每个数组包含当前栅格内包含的点云数据点的编号。
[0043]
进一步,优选的,通过基于策略π的状态价值函数获取当前策略π下理论q值;基于策略π的状态价值函数v
π
(s)通过以下公式实现:
[0044]vπ
(s)=e
π
(g
t
|s
t
=s)
[0045]
=e
π
(r
t 1
γr
t 2
γ2r
t 3
...|s
t
=s)
[0046]
=e
π
(r
t 1
γ(r
t 2
γr
t 3
...)|s
t
=s)
[0047]
=e
π
(r
t 1
γv
π
(s
t 1
)|s
t
=s)
[0048]
=e
π
(r
t 1
|s
t
=s) γe(v
π
(s
t 1
)|s
t
=s)
[0049]
其中,r为状态s下的下一时刻所能获得的奖励期望,γ为折扣因子。
[0050]
进一步,优选的,基于状态向量s
t 1
和奖励函数r计算实时奖励reward,通过以下公式实现:
[0051]
id
begin
=0
[0052][0053][0054]
其中,ω
min_x
表示点云簇ω在坐标轴x方向上的最小值,t
ix
表示对应轨迹点在空间坐标系γ下的x坐标,δs表示理想漆膜厚度,δ
ij
表示仿真模型下数组下标为i的数据点j的漆膜厚度,λ1、λ2表示奖励函数系数。
[0055]
为了解决上述问题,本发明还提供一种基于深度强化学习的涂装轨迹智能规划系统,包括:
[0056]
数据获取单元,用于获取待喷涂工件的模型数据,并按照预设的涂装精度标准对待喷涂工件的模型进行格栅化划分,将某一时刻的所有格栅内全部点云涂层厚度的均值进行向量排列,获得初始化的状态向量;
[0057]
状态向量更新单元,用于将初始化状态向量输入预训练好的基于深度强化学习的涂装控制策略模型,获取喷涂动作向量;并根据喷涂动作向量,确定下一时刻的喷涂轨迹;
[0058]
在仿真环境下,按照喷涂动作向量所对应的下一时刻的喷涂轨迹执行喷涂动作,利用漆膜厚度沉积模型,确定每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响;
[0059]
根据每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响,更新下一时刻的状态向量;
[0060]
根据下一时刻的状态向量,利用预训练好的基于深度强化学习的涂装控制策略模型确定喷涂动作向量所对应的下一时刻的喷涂轨迹;
[0061]
执行单元,用于循环执行,直至确定喷涂过程中每一时刻的状态向量、喷涂动作向量以及喷涂动作向量所对应的喷涂轨迹。
[0062]
为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行前述的基于深度强化学习的涂装轨迹智能规划方法中的步骤。
[0063]
为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存
储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现上述所述的基于深度强化学习的涂装轨迹智能规划方法。
[0064]
本发明提供的上述基于深度强化学习的涂装轨迹智能规划方法,在涂料沉积模型的基础上,将喷涂过程抽象为马尔科夫决策过程,利用喷涂过程中喷枪和仿真环境的交互,使得喷涂轨迹的确定与待喷涂工件表面的实时状态息息相关;通过考虑局部奖励和全局奖励,并把学习最优执行策略以达成漆膜厚度分布均匀的目标,使得本发明的基于深度强化学习的涂装轨迹智能规划方法区别于传统的基于已知轨迹的参数寻优流程,综合考虑了喷涂过程中的工艺参数和喷涂轨迹的耦合影响;达到了有效获取最优的涂装轨迹,有效地改善复杂曲面的涂层厚度控制和喷涂轨迹计算的问题的技术效果。
附图说明
[0065]
图1为根据本发明实施例的基于深度强化学习的涂装轨迹智能规划方法的流程示意图;
[0066]
图2为根据本发明实施例的基于采样法将cad模型转换为三维空间点云数据的原理示意图;
[0067]
图3为根据本发明实施例的对待喷涂的点云进行栅格化划分的原理示意图;
[0068]
图4为根据本发明实施例的基于深度强化学习的涂装控制策略模型的模型参数训练原理示意图;
[0069]
图5为现有技术中平面涂层厚度沉积分布模型的原理示意图;
[0070]
图6为根据本发明实施例的自由曲面涂层厚度沉积分布模型的原理示意图;
[0071]
图7为根据本发明实施例的基于切片法获取喷涂轨迹的原理示意图;
[0072]
图8根据本发明实施例的基于深度强化学习的涂装轨迹智能规划系统的逻辑结构框图;
[0073]
图9为根据本发明实施例的实现基于深度强化学习的涂装轨迹智能规划方法的电子设备的内部结构示意图。
[0074]
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
[0075]
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0076]
本技术实施例可以基于人工智能技术对相关的数据进行获取和处理。其中,人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。本发明中的人工智能软件技术为数字孪生模型的机器学习技术。
[0077]
深度强化学习(deep reinforcement learning,drl)是将深度学习与强化学习结合起来从而实现从感知(perception)到动作(action)的端对端(end-to-end)学习的一种全新的算法。强化学习系统具有四个主要元素:策略、回报函数、值函数和系统的任选模型。该策略主要是当其将系统的感知状态映射到动作时有兴趣查找的内容。回报函数将问题的
目标定义为状态(或状态-动作对)之间的映射以及捕获情形期望性的单个数值回报。该系统的目标是识别使回报最大化的策略。值函数是对从用于制定策略的当前状态可实现的未来回报的预测。任选的模型是可用于规划目的的环境的近似值。
[0078]
针对现有技术中存在的没有综合考虑喷涂轨迹和工艺参数之间的组合优化,泛化能力差,不具备通用性的问题,本发明将喷涂过程抽象为马尔科夫决策过程,利用喷涂过程中喷枪与仿真环境的交互,使得涂装轨迹的确定与待喷涂工件表面的实时状态息息相关;本发明的基于深度强化学习的涂装轨迹智能规划方法综合考虑了喷涂过程中的工艺参数和喷涂轨迹的耦合影响,实现了有效获取最优的涂装轨迹,有效地改善复杂曲面的涂层厚度控制和喷涂轨迹计算的问题。
[0079]
具体的,作为示例,图1为本发明一实施例提供的基于深度强化学习的涂装轨迹智能规划方法的流程示意图。参照图1所示,本发明提供一种基于深度强化学习的涂装轨迹智能规划方法,该方法可以由一个装置执行,该装置可以由软件和/或硬件实现。
[0080]
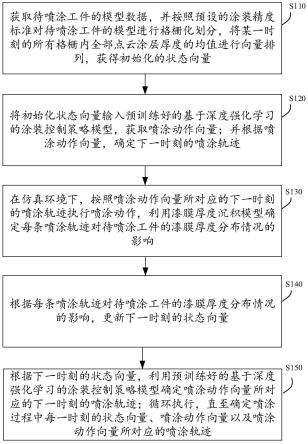
在本实施例中,基于深度强化学习的涂装轨迹智能规划方法包括:步骤s110~s150。
[0081]
s110、获取待喷涂工件的模型数据,并按照预设的涂装精度标准对待喷涂工件的模型进行格栅化划分,将某一时刻的所有格栅内全部点云涂层厚度的均值进行向量排列,获得初始化的状态向量。
[0082]
需要说明的是,在具体的实施过程中,视觉传感器可以但不限制于为激光雷达或扫描仪。对于利用视觉传感器获取待喷涂工件的三维空间的点云数据,具体为x、y、z数据点。
[0083]
图2为根据本发明实施例的基于采样法将cad模型转换为三维空间点云数据的原理示意图;如图2所示,对于不便采集的数据或已有cad模型的工件,可以通过但不限于均匀采样等采样方式将cad模型转换为三维空间点云数据,具体为x、y、z数据点。
[0084]
具体地说,获取待喷涂工件的模型数据,并按照预设的精度标准对待喷涂工件进行格栅化划分的方法包括,获取待喷涂工件的模型数据;其中,模型数据为点云数据或cad模型数据;根据待喷涂工件的模型数据,利用视觉传感器获取待喷涂工件的三维空间的点云数据,或将所述cad模型数据转换为点云数据;按照精度需求确定分割的间隔尺寸,按照分割的间隔尺寸将待喷涂工件进行m
×
n栅格化划分,并反向映射至三维空间的点云数据中;将三维空间的点云数据分割为m
×
n的点云簇,每个栅格对应一个数组,每个数组包含当前栅格内包含的点云数据点的编号。
[0085]
也就是说,将待喷涂工件按照精度需求进行栅格化划分,可以使用但不限于主成分分析等方式;在具体的实施过程中,通过计算待喷涂工件的几何主方向和姿态变换中心点,以几何主方向作为z轴,以姿态变换中心点作为坐标原点构建三维空间坐标系γ。如图2所示,按照间隔ix,iy将xoy投影区域分割为m
×
n的栅格区域,并反向映射至三维空间的点云数据中,将点云数据分割为m
×
n的点云簇,每个栅格对应一个数组,每个数组包含当前栅格内包含的点云数据点的编号。
[0086]
点云簇ω中数据点ωi所属数组下标id的通过以下公式获取:
[0087]
[0088][0089]
id=idy
×
m idx
[0090]
其中,ω
ix
、ω
iy
分别表示数据点ωi的在坐标轴x、y方向上的坐标值,ω
min_x
、ω
min_y
分别表示点云簇ω在坐标轴x、y方向上的最小值,符号[]表示向下取整函数。
[0091]
在按照预设的涂装精度标准对待喷涂工件的模型进行格栅化划分之后,将某一时刻的所有格栅内全部点云涂层厚度的均值进行向量排列,获得初始化的状态向量。
[0092]
具体地说,状态向量s=(ω0,ω1,ω2,...,ω
mn-1
)
t
,ωi表示数组下标为i的栅格中所有数据点的漆膜厚度平均值,即:
[0093][0094]
s120、将初始化状态向量输入预训练好的基于深度强化学习的涂装控制策略模型,获取喷涂动作向量;并根据喷涂动作向量,确定下一时刻的喷涂轨迹。
[0095]
将喷涂过程抽象为马尔科夫奖励决策过程,并建立以喷涂距离、喷涂速度、搭接间距等可变参数作为自变量的action向量,同时建立以全局性漆膜厚度分布和局部性漆膜厚度影响为自变量的reward函数;基于深度强化学习模型和不同action向量输入下仿真环境中涂层漆膜的厚度分布变化情况,根据损失函数对actor和critic等网络参数进行更新,并将更新后的critic网络的参数和actor网络的参数分别复制给对应的critic
target
网络和actor
target
网络。
[0096]
需要说明的是,喷涂动作向量可以但不限制与包括喷涂距离、喷涂速度、搭接间距等参数。
[0097]
图4为根据本发明实施例的基于深度强化学习的涂装控制策略模型的模型参数训练原理示意图;如图4所示,基于深度强化学习的涂装控制策略模型包括两个当前网络(main net)以及两个目标网络(target net);其中,当前网络包括actor网络和critic网络;而目标网络包括actor
target
网络和critic
target
网络。也就是说,基于深度强化学习的涂装控制策略模型包括以mn维状态向量s为输入,l维动作向量a为输出的actor网络和actor
target
网络,和以l维动作向量a为输入,数值q为输出的critic网络和critic
target
网络;其中,所述的critic网络和critic-target网络各包含两个网络,即critic网络1和critic网络2,critic-target网络1,critic
target
网络2,其中,critic
target
网络的参数复制对应编号的critic网络得到。actor
target
网络的参数也是复制actor网络得到。基于深度强化学习的涂装控制策略模型的参数包括actor网络参数、actor
target
网络参数、critic网络参数和critic
target
网络参数。
[0098]
经验回放池的功能主要是解决模型训练过程中相关性及非静态分布问题。具体做法是把每个时间步agent与环境交互得到的转移样本{sj,aj,s
j 1
,reward,s
jb
}储存到回放记忆单元,要训练时就随机拿出一些(minibatch)来训练(其实就是将训练的过程打成碎片存储,训练时随机抽取就避免了相关性问题)。
[0099]
使用均方差损失函数,通过神经网络的梯度反向传播对critic网络的参数ω进行
更新;使用损失函数,通过神经网络的梯度反向传播对actor网络的参数θ进行更新。
[0100]
通过设置目标网络,具体地,q(aj)表示当前网络(main net)的输出,用来评估当前状态动作对的值函数;q(a
j 1
)表示目标网络(target net)的输出,用以得到目标q值。利用各自的损失函数更新当前网络(main net)的参数,每经过n轮迭代,将当前网络(main net)的参数复制给目标网络(target net),也就是定时更新目标网络(target net)的参数。在一定程度降低了当前q值和目标q值的相关性,提高了算法稳定性。
[0101]
在一个具体的实施例中,通过设定最大迭代次数,对基于深度强化学习的涂装控制策略模型进行迭代训练,迭代训练的方法包括步骤s121-s128。
[0102]
s121、随机初始化基于深度强化学习的涂装控制策略模型的参数θ,θ',ω,ω',初始化网络训练迭代次数为1,并清空深度强化学习的经验回放池d;需要说明的是,对于网络更新速率也进行初始化,一般设定为0.001;而训练回合数也初始化为1,初始化训练时刻t=1;
[0103]
s122、更新状态向量s
t
,基于状态向量s
t
获取actor网络的输出喷涂动作向量a
t
;其中,需要说明的是状态向量s
t
为随机状态向量。
[0104]
s123、基于喷涂动作向量a
t
计算喷涂动作向量对应的喷涂轨迹t,利用漆膜厚度沉积模型更新待喷涂工件的漆膜厚度分布情况,得到状态向量s
t 1
;
[0105]
s124、基于状态向量s
t 1
和奖励函数r计算实时奖励reward;并以s
tb
=done是否成立,判断喷涂过程是否终止;需要说明的是,以布尔值s
tb
进行描述,即s
tb
=done是否成立,进而判断喷涂过程是否终止。
[0106]
s125、根据所获取的状态向量s
t
、喷涂动作向量a
t
、动状态向量s
t 1
和实时奖励reward,确定集合{s
t
,a
t
,s
t 1
,reward,s
tb
};将集合{s
t
,a
t
,s
t 1
,reward,s
tb
}存入深度学习的经验回放池d,令t=t 1,循环执行,直至达到经验回放池d的最大容量;
[0107]
s126、从经验回放池d中进行m次随机采样,获得{sj,aj,s
j 1
,reward,s
jb
},j=1,2,...,m,计算当前策略π下理论q值(状态动作q函数)。需要说明的是,如果经验回放池d中的样本数量大于设定值,则从经验回放池中选择设定值数量的样本进行采样。其中,根据状态sj获取actor
target
网络的输出aj,利用sj和aj计算两个critic
target
网络的输出q1,q2,取最小值作为q。
[0108]
当前策略π下理论q值yj通过以下公式获取:
[0109][0110]
其中,γ表示奖励衰减因子,π
θ'
(s
j 1
)表示网络参数为θ'的actor
target
网络在状态向量s
j 1
的输入下的对应输出喷涂动作向量a
j 1
,q
ω'
(s
j 1
,π
θ'
(s
j 1
))表示网络参数为ω'的critic
target
网络在对应输入下的对应输出。
[0111]
s127、使用均方差损失函数通过神经网络的梯度反向传
播对critic网络的参数ω进行更新;使用损失函数通过神经网络的梯度反向传播对actor网络的参数θ进行更新;并将更新后的critic网络的参数和actor网络的参数分别复制给对应的critic
target
网络和actor
target
网络。即采用软更新的方式将actor网络和critic网络1、critic网络2的参数复制给对应的target网络。
[0112]
具体地说,每经过一定的迭代次数c,对基于深度强化学习的涂装控制策略模型中的actor
target
、critic
target
进行更新;更新通过以下公式实现:
[0113][0114]
其中,0《τ《1,τ为强化学习过程中的学习率。
[0115]
s128、进行迭代训练,直至达到设定最大迭代次数;获得训练好的基于深度强化学习的涂装控制策略模型。需要说明的是,若时刻t到达设定的最大训练时刻数,则一个训练回合结束。若eps达到设定的最大回合数,则离线训练结束,得到离线训练完毕的智能体。
[0116]
综上,本发明所示的基于深度强化学习模型和不同action向量输入下仿真环境中涂层漆膜的厚度分布变化情况,根据损失函数对actor和critic等网络参数进行更新,并将更新后的critic网络的参数和actor网络的参数分别复制给对应的critic
target
网络和actor
target
网络;是基于点云模型栅格划分的数量mn和已知的action向量维度l,构建以mn维状态向量s为输入,l维动作向量a为输出的actor及actor
target
多层网络模型和以l维动作向量a为输入,数值q为输出的critic及critic
target
多层网络模型,并按照深度强化学习的训练过程对actor、actor
target
、critic、critic
target
的网络参数θ,θ',ω,ω'进行更新。
[0117]
具体地说,对构建的基于深度强化学习的涂装控制策略模型进行训练直至模型收敛后。利用训练好的基于深度强化学习的涂装控制策略模型进行涂装轨迹智能规划的获取。
[0118]
需要说明的是,设定仿真环境下所使用的漆膜厚度沉积模型和模型参数,通过提取影响机器人喷涂过程中的关键因素,构建多变量的喷枪涂层厚度沉积模型,并对模型参数进行初始化,用来模拟机器人喷涂过程中的工件表面漆膜厚度的变化情况。其中,常用的厚度沉积模型代表有β分布模型、分析沉积模型、抛物线沉积模型以及椭圆双β分布模型等。
[0119]
在一个具体的实施例中,漆膜厚度沉积模型为由平面涂层厚度模型转换得到的自由曲面涂层厚度分布模型,上述转换基于椭圆双β漆膜厚度沉积模型及微分放大原理可实现。
[0120]
图5和图6对漆膜厚度沉积模型进行了整体描述;其中,图5为现有技术中平面涂层厚度沉积分布模型的原理示意图;图6为根据本发明实施例的自由曲面涂层厚度沉积分布模型的原理示意图。如图5和图6所示,
[0121]
由平面涂层厚度模型转换得到的自由曲面涂层厚度分布模型,通过以下公式实现:
[0122]
[0123][0124][0125]
其中,q
ω
表示当前喷涂范围内点云簇ω表面的数据点ωi的涂层厚度沉积速率,q
t
表示基准平面的涂层厚度沉积速率,x,y表示数据点ωi的坐标描述;d表示喷枪中心点到理论平面的距离高度,d'为喷枪中心点到基准平面的距离高度,α表示数据点ωi切平面法矢n与喷枪轴线方向的夹角,θ表示喷枪轴线与垂线段方向的夹角;a0,b0分别表示理论平面上喷涂椭圆的长短轴的长度,q
max
表示理论平面的涂层沉积率系数,β1,β2表示沉积模型分布系数。
[0126]
可通过上述基于椭圆双β漆膜厚度沉积模型进行点云数据点ωk处漆膜厚度δ的数值计算。具体地说,可按照下述过程进行:
[0127]
计算喷枪在轨迹点ti的停留时间t,有:
[0128][0129]
以轨迹点ti为原点,构建局部坐标系γ
local
和椭圆双β漆膜厚度沉积模型,寻找点云ω中位于椭圆涂覆面积中的数据点ωk,计算数据点数据点ωk在时间t内获得的漆膜沉积厚度为:
[0130]
δk=t
×qω
[0131]
重复上述过程,分别计算轨迹t中各轨迹点对数据点ωk所产生的的漆膜沉积厚度δk,则最终的漆膜厚度δ可表示为:
[0132]
δ=∑δk[0133]
在具体的实施过程中,根据喷涂动作向量,确定下一时刻的喷涂轨迹的方法可以但不限制于为切片法。图7为根据本发明实施例的基于切片法获取喷涂轨迹的原理示意图;如图7所示,基于喷涂动作向量a
t
可以计算得到离散化的喷涂轨迹;具体地说,计算空间散乱点云即点云簇ω与一组平行平面的截交线,并沿交点切平面的法矢方向平移dis距离,即可获取与喷涂动作向量a
t
相对应的喷涂轨迹t;喷涂轨迹t由若干间距为e的离散轨迹点ti组成,上述平行平面的法向量方向与喷涂轨迹的朝向保持一致。
[0134]
s130、在仿真环境下,按照喷涂动作向量所对应的下一时刻的喷涂轨迹执行喷涂动作,利用漆膜厚度沉积模型,确定每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响。
[0135]
因为将喷涂过程抽象为马尔科夫奖励决策过程,并建立以喷涂距离、喷涂速度、搭接间距等可变参数作为自变量的action向量,同时建立以全局性漆膜厚度分布和局部性漆膜厚度影响为自变量的reward函数。所以,需要在仿真环境下,利用漆膜厚度沉积模型,确定每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响。
[0136]
具体地说,由强化学习(rl)解决的示例性机器人喷涂问题可以用马尔科夫决策过
程(mdp)的五元组《s,a,t,r,γ》来表示,其中,s是状态空间,a是行动空间,t:是状态转换模型,r:是奖励函数,γ是累积奖励的折扣系数。强化学习被用于通过使行动主体(agent)能够从与环境的相互作用中学习来优化策略π:以实现特定的目标。行动主体观察来自环境的状态s,选择由要在环境中执行的政策π给出的行动a,观察下一个状态,并同时获得奖励r,直到达到终点状态。因此,由最优策略π获得的预期累积奖励是最大的。强化学习方法的目标是找到最优策略π。对于一些实施方式,强化学习需要与环境互动,以了解每个策略的益处是什么,然后结合各策略进行序列化决策。
[0137]
在本实施例中,将实际的喷涂过程按照时间顺序相互交替的顺序进行排列,用下述的状态—动作链(马尔科夫链)进行表述:
[0138]
{s0,a0,s1,a1,...,s
t-1
,a
t-1
,s
t
}
[0139]
其中,a
t
表示t时刻所采取的喷涂选择,可由是否进行喷涂、喷涂点所处位置、喷涂工艺参数等多要素组成,s
t
表示t时刻待喷涂工件的表面漆膜厚度分布情况。状态s
t
基于权利要求4中构建的涂层厚度沉积模型进行表述。
[0140]
将喷涂过程抽象为马尔科夫决策过程,提取时刻t的喷涂动作构成深度强化学习网络中critic网络输入action向量,喷涂动作向量a
t
可包括但不限于喷涂速度vec
t
、喷涂距离dis
t
、轨迹搭接距离inter
t
等。
[0141]
即a
t
=(vec
t
,dis
t
,inter
t
)
t
,且:
[0142][0143]
其中,vec
min
、vec
max
分别代表喷涂轨迹中可变参数vec的理论最小值和最大值,dis
min
、dis
max
分别代表喷涂轨迹中可变参数dis的理论最小值和最大值,inter
min
、inter
max
分别代表喷涂轨迹中可变参数inter的理论最小值和最大值。
[0144]
为了求得深度强化学习的策略π,需要对每次采取喷涂动作向量a
t
所产生的实际效果做出客观的评价,按照既定的方法确定相应的奖励函数r。
[0145]
可以引入基于策略π的状态价值函数v
π
(s):
[0146]vπ
(s)=e
π
(g
t
|s
t
=s)
[0147]
=e
π
(r
t 1
γr
t 2
γ2r
t 3
...|s
t
=s)
[0148]
=e
π
(r
t 1
γ(r
t 2
γr
t 3
...)|s
t
=s)
[0149]
=e
π
(r
t 1
γv
π
(s
t 1
)|s
t
=s)
[0150]
=e
π
(r
t 1
|s
t
=s) γe(v
π
(s
t 1
)|s
t
=s)
[0151]
其中,r为状态s下的下一时刻所能获得的奖励期望,γ为折扣因子。需要说明的是,状态价值函数是从某一状态根据策略π确定行动时所获得的收益的期望值,用v
π
(s)表示;也就是说,状态价值函数代表喷涂机器人在状态s下的预期累积奖励,直到喷涂动作完成。策略网络的策略π的目标为最大化状态价值函数。当作为在状态s
t
下选择行动a
t
的结果,观测到报酬r
t 1
和下一个转变的状态s
t 1
时,由在转变至一小时步长后的状态下所选择的行动a
t 1
来更新行动价值q
(st,at)
。
[0152]
对于喷涂过程而言,以喷涂朝向为空间坐标系γ下ox方向为例,奖励函数r可以但不限制于按照下述方法予以确定:
[0153]
id
begin
=0
[0154][0155][0156]
其中,id
begin
、id
end
的具体数值与当前计算出的轨迹的位置有关;ω
min_x
表示点云簇ω在坐标轴x方向上的最小值,t
ix
表示对应轨迹点在空间坐标系γ下的x坐标,δs表示理想漆膜厚度,δ
ij
表示仿真模型下数组下标为i中数据点j的漆膜厚度,λ1、λ2表示奖励函数系数,通常有λ2》λ1。
[0157]
需要说明的是,当t
ix
满足t
ix-ω
max_x
》γ时,有s=done成立,γ表示可变距离参数。
[0158]
s140、根据每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响,更新下一时刻的状态向量。s150、根据下一时刻的状态向量,利用预训练好的基于深度强化学习的涂装控制策略模型确定喷涂动作向量所对应的下一时刻的喷涂轨迹;循环执行,直至确定喷涂过程中每一时刻的状态向量、喷涂动作向量以及喷涂动作向量所对应的喷涂轨迹。
[0159]
也就是说,初始化状态向量s
t
=(0,0,0,...,0)
t
;以状态s
t
作为actor网络模型的输入,获取网络输出喷涂动作向量a
t
,基于喷涂动作向量a
t
给出的喷涂速度vec
t
、喷涂距离dis
t
、轨迹搭接距离inter
t
等使用切片法获取实际的离散化喷涂轨迹t
t
;基于喷涂轨迹t
t
和椭圆双β漆膜厚度沉积模型更新待喷涂工件的漆膜厚度分布情况,获取状态向量s
t 1
;令t=t 1,重复上述步骤直至满足s=done;由此,实现了对每一时刻(步骤)t下如喷涂速度vec
t
、喷涂距离dis
t
、轨迹搭接距离inter
t
等涂装工艺参数的确定,并获得了一系列离散的喷涂轨迹ti,i=0,1,2,...。
[0160]
综上,本发明的基于深度强化学习的涂装轨迹智能规划方法针对现有技术中优化模型求解方法中求解效率低,难以获取全局最优解以及通用性差的问题。基于涂料沉积模型,将喷涂过程抽象为马尔科夫决策过程,利用喷涂过程中喷枪和仿真环境的交互,考虑局部奖励和全局奖励,学习最优执行策略以达成喷涂漆膜厚度分布均匀的目标,区别于传统的基于已知轨迹的参数寻优流程,通过综合考虑喷涂过程中工艺参数和涂装轨迹的耦合影响,有效地获取最优的涂装轨迹,有效地改善复杂曲面的涂层厚度控制和喷涂轨迹计算的技术效果。
[0161]
与上述基于深度强化学习的涂装轨迹智能规划方法相对应,本发明还提供一种基于深度强化学习的涂装轨迹智能规划系统。图6示出了根据本发明实施例的基于深度强化学习的涂装轨迹智能规划系统的功能模块。
[0162]
如图8所示,本发明提供的基于深度强化学习的涂装轨迹智能规划系统800可以安装于电子设备中。根据实现的功能,所述基于深度强化学习的涂装轨迹智能规划系统800可以包括数据获取单元810、状态向量更新单元820和执行单元830。本发明所述单元也可以称之为模块,指的是一种能够被电子设备的处理器所执行,并且能够完成某一固定功能的一系列计算机程序段,其存储在电子设备的存储器中。
[0163]
在本实施例中,关于各模块/单元的功能如下:
[0164]
数据获取单元810,用于获取待喷涂工件的模型数据,并按照预设的涂装精度标准对待喷涂工件的模型进行格栅化划分,将某一时刻的所有格栅内全部点云涂层厚度的均值进行向量排列,获得初始化的状态向量;
[0165]
状态向量更新单元820,用于将初始化状态向量输入预训练好的基于深度强化学习的涂装控制策略模型,获取喷涂动作向量;并根据喷涂动作向量,确定下一时刻的喷涂轨迹;在仿真环境下,按照喷涂动作向量所对应的下一时刻的喷涂轨迹执行喷涂动作,利用漆膜厚度沉积模型,确定每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响;根据每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响,更新下一时刻的状态向量;根据下一时刻的状态向量,利用预训练好的基于深度强化学习的涂装控制策略模型确定喷涂动作向量所对应的下一时刻的喷涂轨迹;
[0166]
执行单元830,用于循环执行,直至确定喷涂过程中每一时刻的状态向量、喷涂动作向量以及喷涂动作向量所对应的喷涂轨迹。
[0167]
本发明所提供的上述基于深度强化学习的涂装轨迹智能规划系统的更为具体的实现方式,均可以参照上述对基于深度强化学习的涂装轨迹智能规划方法的实施例表述,在此不再一一列举。
[0168]
如图9所示,本发明提供一种基于深度强化学习的涂装轨迹智能规划方法的电子设备9。
[0169]
该电子设备9可以包括处理器90、存储器91和总线,还可以包括存储在存储器91中并可在所述处理器90上运行的计算机程序,如基于深度强化学习的涂装轨迹智能规划程序92。
[0170]
其中,所述存储器91至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、移动硬盘、多媒体卡、卡型存储器(例如:sd或dx存储器等)、磁性存储器、磁盘、光盘等。所述存储器91在一些实施例中可以是电子设备9的内部存储单元,例如该电子设备9的移动硬盘。所述存储器91在另一些实施例中也可以是电子设备9的外部存储设备,例如电子设备9上配备的插接式移动硬盘、智能存储卡(smart media card,smc)、安全数字(secure digital,sd)卡、闪存卡(flash card)等。进一步地,所述存储器91还可以既包括电子设备9的内部存储单元也包括外部存储设备。所述存储器91不仅可以用于存储安装于电子设备9的应用软件及各类数据,例如基于深度强化学习的涂装轨迹智能规划程序的代码等,还可以用于暂时地存储已经输出或者将要输出的数据。
[0171]
所述处理器90在一些实施例中可以由集成电路组成,例如可以由单个封装的集成电路所组成,也可以是由多个相同功能或不同功能封装的集成电路所组成,包括一个或者多个中央处理器(central processing unit,cpu)、微处理器、数字处理芯片、图形处理器及各种控制芯片的组合等。所述处理器90是所述电子设备的控制核心(control unit),利
用各种接口和线路连接整个电子设备的各个部件,通过运行或执行存储在所述存储器91内的程序或者模块(例如基于深度强化学习的涂装轨迹智能规划程序等),以及调用存储在所述存储器91内的数据,以执行电子设备9的各种功能和处理数据。
[0172]
所述总线可以是外设部件互连标准(peripheral component interconnect,简称pci)总线或扩展工业标准结构(extended industry standard architecture,简称eisa)总线等。该总线可以分为地址总线、数据总线、控制总线等。所述总线被设置为实现所述存储器91以及至少一个处理器90等之间的连接通信。
[0173]
图9仅示出了具有部件的电子设备,本领域技术人员可以理解的是,图9示出的结构并不构成对所述电子设备9的限定,可以包括比图示更少或者更多的部件,或者组合某些部件,或者不同的部件布置。
[0174]
例如,尽管未示出,所述电子设备9还可以包括给各个部件供电的电源(比如电池),优选地,电源可以通过电源管理装置与所述至少一个处理器90逻辑相连,从而通过电源管理装置实现充电管理、放电管理、以及功耗管理等功能。电源还可以包括一个或一个以上的直流或交流电源、再充电装置、电源故障检测电路、电源转换器或者逆变器、电源状态指示器等任意组件。所述电子设备9还可以包括多种传感器、蓝牙模块、wi-fi模块等,在此不再赘述。
[0175]
进一步地,所述电子设备9还可以包括网络接口,可选地,所述网络接口可以包括有线接口和/或无线接口(如wi-fi接口、蓝牙接口等),通常用于在该电子设备9与其他电子设备之间建立通信连接。
[0176]
可选地,该电子设备9还可以包括用户接口,用户接口可以是显示器(display)、输入单元(比如键盘(keyboard)),可选地,用户接口还可以是标准的有线接口、无线接口。可选地,在一些实施例中,显示器可以是led显示器、液晶显示器、触控式液晶显示器以及oled(organic light-emitting diode,有机发光二极管)触摸器等。其中,显示器也可以适当的称为显示屏或显示单元,用于显示在电子设备9中处理的信息以及用于显示可视化的用户界面。
[0177]
可选地,包括成像传感器、温度传感器和/或湿度传感器的外感受传感器。成像传感器可以是包括rgb传感器、单色传感器、红外传感器、雾度传感器、反射率传感器和/或漫射率传感器的视觉传感器,或者可以是包括rgb-d(结构化光、飞行时间和/或立体摄影测量)、立体偏折法、轮廓测量法和/或显微镜法的地形传感器。外感受传感器还可包括用于弹性体成像(即,gelsight)的触觉传感器;也可使用温度传感器,包括热电偶和/或ir热成像。
[0178]
应该了解,所述实施例仅为说明之用,在专利申请范围上并不受此结构的限制。
[0179]
所述电子设备9中的所述存储器91存储的基于深度强化学习的涂装轨迹智能规划程序92是多个指令的组合,在所述处理器90中运行时,可以实现:获取待喷涂工件的模型数据,并按照预设的涂装精度标准对待喷涂工件的模型进行格栅化划分,将某一时刻的所有格栅内全部点云涂层厚度的均值进行向量排列,获得初始化的状态向量;将初始化状态向量输入预训练好的基于深度强化学习的涂装控制策略模型,获取喷涂动作向量;并根据喷涂动作向量,确定下一时刻的喷涂轨迹;在仿真环境下,按照喷涂动作向量所对应的下一时刻的喷涂轨迹执行喷涂动作,利用漆膜厚度沉积模型,确定每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响;根据每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响,
更新下一时刻的状态向量;根据下一时刻的状态向量,利用预训练好的基于深度强化学习的涂装控制策略模型确定喷涂动作向量所对应的下一时刻的喷涂轨迹;循环执行,直至确定喷涂过程中每一时刻的状态向量、喷涂动作向量以及喷涂动作向量所对应的喷涂轨迹。
[0180]
具体地,所述处理器90对上述指令的具体实现方法可参考图1对应实施例中相关步骤的描述,在此不赘述。需要强调的是,为进一步保证上述基于深度强化学习的涂装轨迹智能规划程序的私密和安全性,上述基于深度强化学习的涂装轨迹智能规划程序存储于本服务器集群所处区块链的节点中。
[0181]
进一步地,所述电子设备9集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-only memory)。
[0182]
本发明实施例还提供一种计算机可读存储介质,所述存储介质可以是非易失性的,也可以是易失性的,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现:获取待喷涂工件的模型数据,并按照预设的涂装精度标准对待喷涂工件的模型进行格栅化划分,将某一时刻的所有格栅内全部点云涂层厚度的均值进行向量排列,获得初始化的状态向量;将初始化状态向量输入预训练好的基于深度强化学习的涂装控制策略模型,获取喷涂动作向量;并根据喷涂动作向量,确定下一时刻的喷涂轨迹;在仿真环境下,按照喷涂动作向量所对应的下一时刻的喷涂轨迹执行喷涂动作,利用漆膜厚度沉积模型,确定每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响;根据每条喷涂轨迹对待喷涂工件的漆膜厚度分布情况的影响,更新下一时刻的状态向量;根据下一时刻的状态向量,利用预训练好的基于深度强化学习的涂装控制策略模型确定喷涂动作向量所对应的下一时刻的喷涂轨迹;循环执行,直至确定喷涂过程中每一时刻的状态向量、喷涂动作向量以及喷涂动作向量所对应的喷涂轨迹。
[0183]
具体地,所述计算机程序被处理器执行时具体实现方法可参考实施例基于深度强化学习的涂装轨迹智能规划方法中相关步骤的描述,在此不赘述。
[0184]
在本发明所提供的几个实施例中,应该理解到,所揭露的设备,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
[0185]
所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。
[0186]
另外,在本发明各个实施例中的各功能模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能模块的形式实现。
[0187]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。
[0188]
因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的
含义和范围内的所有变化涵括在本发明内。不应将权利要求中的任何附关联图标记视为限制所涉及的权利要求。
[0189]
本发明所指区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链(blockchain),本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层等区块链可以存储医疗数据,如个人健康档案、厨房、检查报告等。
[0190]
此外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。系统权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第二等词语用来表示名称,而并不表示任何特定的顺序。
[0191]
最后应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或等同替换,而不脱离本发明技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。