1.本技术涉及大数据领域,尤其涉及一种流数据处理方法、装置、存储介质和设备。
背景技术:
2.在数据量激增的如今,各种业务场景每时每刻都在产生大量的业务数据,对于这些不断产生的数据进行处理的过程中,免不了根据业务的需求将处理后的数据落盘到各个数据库中,如何保证处理前后的数据的一致性,成为了本领域亟需解决的问题。
技术实现要素:
3.本技术提供了一种流数据处理方法、装置、存储介质和设备,目的在于确保处理后的数据与处理前的数据保持一致。
4.为了实现上述目的,本技术提供了以下技术方案:
5.一种流数据处理方法,包括:
6.从预设消息队列中获取流数据;所述流数据包括数据序列;所述数据序列包括经由源数据库上传给所述预设消息队列的多个数据,且每个所述数据均按照所述数据自身的上传次序进行排序;
7.对各个所述数据进行处理,得到每个所述数据的处理结果;
8.基于所述数据所包含的字段,确定所述数据的第一校验码;
9.对所述处理结果进行校验码转换,得到所述数据的第二校验码;
10.在所述第一校验码和所述第二校验码不相同的情况下,对所述处理结果进行修正,得到满足预设要求的修正结果;所述预设要求为:经由对所述修正结果进行校验码转换得到的第二校验码,与所述第一校验码保持一致;
11.将所述数据以及所述修正结果,保存到目标数据库中。
12.可选的,所述对各个所述数据进行处理,得到每个所述数据的处理结果,包括:
13.为各个所述数据分配时间戳和水印;所述时间戳指示所述数据的处理时间;所述水印指示处理所述数据时的延迟时间;
14.按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对各个所述数据进行处理,得到每个所述数据的处理结果。
15.可选的,所述按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对各个所述数据进行处理,得到每个所述数据的处理结果,包括:
16.对各个所述数据中符合预设条件的数据进行删除,得到有效流数据;所述预设条件为:数据的字段值为空,以及数据的字段包含有预设敏感字符;
17.按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对于所述有效流数据中的每个所述数据进行处理,得到每个所述数据的处理结果。
18.可选的,所述按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对于所述有效流数据中的每个所述数据进行处理,得到每个所述数据的处理结果,包
括:
19.对所述有效流数据中的各个所述数据进行降维,以使剔除所述有效流数据中每个数据的冗余属性列,得到目标流数据;
20.按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对于所述目标流数据中的每个所述数据进行处理,得到每个所述数据的处理结果。
21.可选的,所述按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对于所述目标流数据中的每个所述数据进行处理,得到每个所述数据的处理结果,包括:
22.对所述目标流数据中的各个所述数据进行分类,得到多个数据分组;所述数据分组包括预设属性相同的多个数据;
23.对于每个所述数据分组,按照处理时间从早到晚的顺序,并延迟每个数据的延迟时间之后,依次对所述数据分组中各个数据进行处理,得到所述数据分组中每个数据的处理结果。
24.可选的,所述基于所述数据所包含的字段,确定所述数据的第一校验码,包括:
25.将所述数据所包含的各个字段进行拼接,得到所述数据的字符串;
26.对所述字符串进行校验码转换,得到所述数据的第一校验码。
27.可选的,所述对所述处理结果进行校验码转换,得到所述数据的第二校验码之后,还包括:
28.在所述第一校验码和所述第二校验码相同的情况下,直接将所述数据以及所述处理结果,保存到所述目标数据库中。
29.一种流数据处理装置,包括:
30.获取单元,用于从预设消息队列中获取流数据;所述流数据包括数据序列;所述数据序列包括经由源数据库上传给所述预设消息队列的多个数据,且每个所述数据均按照所述数据自身的上传次序进行排序;
31.处理单元,用于对各个所述数据进行处理,得到每个所述数据的处理结果;
32.确定单元,用于基于所述数据所包含的字段,确定所述数据的第一校验码;
33.转换单元,用于对所述处理结果进行校验码转换,得到所述数据的第二校验码;
34.修正单元,用于在所述第一校验码和所述第二校验码不相同的情况下,对所述处理结果进行修正,得到满足预设要求的修正结果;所述预设要求为:经由对所述修正结果进行校验码转换得到的第二校验码,与所述第一校验码保持一致;
35.保存单元,用于将所述数据以及所述修正结果,保存到目标数据库中。
36.一种计算机可读存储介质,所述计算机可读存储介质包括存储的程序,其中,所述程序执行所述的流数据处理方法。
37.一种流数据处理设备,包括:处理器、存储器和总线;所述处理器与所述存储器通过所述总线连接;
38.所述存储器用于存储程序,所述处理器用于运行程序,其中,所述程序运行时执行所述的流数据处理方法。
39.本技术提供的技术方案,从预设消息队列中获取流数据。对各个数据进行处理,得到每个数据的处理结果。基于数据所包含的字段,确定数据的第一校验码。对处理结果进行
校验码转换,得到数据的第二校验码。在第一校验码和第二校验码不相同的情况下,对处理结果进行修正,得到满足预设要求的修正结果。将数据以及修正结果,保存到目标数据库中。本技术对流数据所示数据的第一校验码和第二校验码进行比对,在第一校验码和第二校验码不相同的情况下,对数据的处理结果进行修正,得到满足预设要求的修正结果,使得处理后的数据与处理前的数据保持一致。
附图说明
40.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
41.图1a为本技术实施例提供的一种流数据处理方法的流程示意图;
42.图1b为本技术实施例提供的一种流数据处理方法的流程示意图;
43.图2为本技术实施例提供的另一种流数据处理方法的流程示意图;
44.图3为本技术实施例提供的一种流数据处理装置的架构示意图。
具体实施方式
45.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
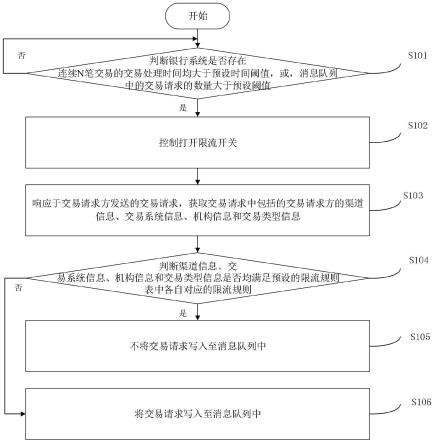
46.如图1a和图1b所示,为本技术实施例提供的一种流数据处理方法的流程示意图,包括如下步骤:
47.s101:从预设消息队列中获取流数据。
48.其中,流数据包括数据序列;数据序列包括经由源数据库上传给预设消息队列的多个数据,且每个数据均按照数据自身的上传次序进行排序。预设消息队列包括但不限于为kafka。
49.需要说明的是,流数据包括数据序列,数据序列包括多个数据、且每个数据按照存入预设消息队列的时间由早到晚的顺序进行排序。
50.可选的,可以将flink框架提供的datastream接口作为预设消息队列的消息消费者,调用datastream接口从预设消息队列中获取流数据。
51.s102:为各个数据分配时间戳(timestamp)和水印(watermark)。
52.其中,时间戳指示数据的处理时间,水印指示处理数据时的延迟时间。
53.需要说明的是,可以利用flink框架为流数据所示的每个数据分配时间戳和水印。
54.s103:对各个数据中符合预设条件的数据进行删除,得到有效流数据。
55.其中,预设条件为:数据的字段值为空,以及数据的字段包含有预设敏感字符。
56.需要说明的是,数据包括字段以及字段值。
57.可选的,可以调用flink框架提供的fliter算子,对流数据所示各个数据中符合预设条件的数据进行删除,得到有效流数据。具体的,在fliter算子所提供的算法逻辑中,若
数据不符合预设条件,即确定数据的fliter判断结果为true,则保留该数据,若数据符合预设条件,即确定数据的fliter判断结果为flase,则删除该数据。
58.s104:对有效流数据中的各个数据进行降维,以使剔除有效流数据中的每个数据的冗余属性列,得到目标流数据。
59.其中,冗余属性列为数据结构中额外包含的多余属性列。
60.可选的,可以利用flink框架提供的flatmap算子,对有效流数据中的每个数据的数据结构进行调整,以提出每个数据的数据结构中未被预先选定的属性列,得到目标流数据。具体的,通常使用flink框架提供的collect方法,选定数据结构中的属性列,剩余未被选定的属性列则被视为冗余属性列,予以剔除。
61.s105:对目标流数据中的各个数据进行分类,得到多个数据分组。
62.其中,数据分组包括预设属性相同的多个数据。
63.具体的,以交易数据(即数据的一种具体表现形式)为例,可以将交易发起方(即预设属性的一种具体表现形式)相同的交易数据划分到同一数据分组中。
64.可选的,可以利用flink框架提供的keyby算子,对目标流数据所示各个数据进行分类,得到多个数据分组。
65.s106:对于每个数据分组,按照处理时间从早到晚的顺序,并延迟每个数据的延迟时间之后,对数据分组中各个数据进行处理,得到数据分组中每个数据的处理结果。
66.其中,对数据进行处理的具体实现过程,为本领域技术人员熟悉的公知常识,这里不再赘述。
67.可选的,可以利用flink框架提供的process算子,对数据分组中各个数据进行处理,以提高数据的处理效率。
68.s107:对于数据分组中的每个数据,将数据所包含的各个字段进行拼接,得到数据的字符串。
69.其中,可以按照预设拼接顺序(字段在数据中所处位置从前到后的顺序),将数据所包含的各个字段进行拼接。具体的,假设数据包括字段aa、字段bb和字段cc,字段aa的位置最靠前,字段bb的位置居中,字段cc的位置靠后,则拼接得到的字符串为aabbcc。
70.s108:对数据的字符串进行校验码转换,得到数据的第一校验码。
71.其中,可使用md5报文摘要算法,对数据的字符串进行校验码(checksum)转换,得到数据的第一校验码。
72.s109:对数据的处理结果进行校验码转换,得到数据的第二校验码。
73.s110:在第一校验码和第二校验码不相同的情况下,对数据的处理结果进行修正,得到满足预设要求的修正结果。
74.其中,预设要求为:经由对修正结果进行校验码转换得到的第二校验码,与第一校验码保持一致。
75.可选的,在第一校验码和第二校验码相同的情况下,直接将数据以及处理结果,保存到目标数据库中。
76.s111:将数据以及修正结果,保存到目标数据库中。
77.基于上述s101-s111所示流程,能够通过flink框架提高数据传输的安全性,并确保目标数据库中的数据与源数据库中的数据相同,对于众多业务系统产生的海量数据而
言,可提高源数据库中的数据的安全性。
78.综上所述,本实施例对流数据所示数据的第一校验码和第二校验码进行比对,在第一校验码和第二校验码不相同的情况下,对数据的处理结果进行修正,得到满足预设要求的修正结果,使得处理后的数据与处理前的数据保持一致。
79.需要说明的是,上述实施例提及的s101,为本技术实施例所示流数据处理方法的一种可选的实现方式。此外,上述实施例提及的s107,也为本技术实施例所示流数据处理方法的一种可选的实现方式。为此,上述实施例提及的流程,可以概括为图2所示的方法。
80.如图2所示,为本技术实施例提供的另一种流数据处理方法的流程示意图,包括如下步骤:
81.s201:从预设消息队列中获取流数据。
82.其中,流数据包括数据序列;数据序列包括经由源数据库上传给预设消息队列的多个数据,且每个数据均按照数据自身的上传次序进行排序。
83.s202:对各个数据进行处理,得到每个数据的处理结果。
84.s203:基于数据所包含的字段,确定数据的第一校验码。
85.s204:对处理结果进行校验码转换,得到数据的第二校验码。
86.s205:在第一校验码和第二校验码不相同的情况下,对处理结果进行修正,得到满足预设要求的修正结果。
87.其中,预设要求为:经由对修正结果进行校验码转换得到的第二校验码,与第一校验码保持一致。
88.s206:将数据以及修正结果,保存到目标数据库中。
89.综上所述,本实施例对流数据所示数据的第一校验码和第二校验码进行比对,在第一校验码和第二校验码不相同的情况下,对数据的处理结果进行修正,得到满足预设要求的修正结果,使得处理后的数据与处理前的数据保持一致。
90.需要说明的是,本发明提供的流数据处理方法可用于人工智能领域、区块链领域、分布式领域、云计算领域、大数据领域、物联网领域、移动互联领域、网络安全领域、芯片领域、虚拟现实领域、增强现实领域、全息技术领域、量子计算领域、量子通信领域、量子测量领域、数字孪生领域或金融领域。上述仅为示例,并不对本发明提供的流数据处理方法的应用领域进行限定。
91.本发明提供的流数据处理方法可用于金融领域或其他领域,例如,可用于金融领域中的交易应用场景。其他领域为除金融领域之外的任意领域,例如,电力领域。上述仅为示例,并不对本发明提供的流数据处理方法的应用领域进行限定。
92.与上述本技术实施例提供的流数据处理方法相对应,本技术实施例还提供了一种流数据处理装置。
93.如图3所示,为本技术实施例提供的一种流数据处理装置的架构示意图,包括:
94.获取单元100,用于从预设消息队列中获取流数据;流数据包括数据序列;数据序列包括经由源数据库上传给预设消息队列的多个数据,且每个数据均按照数据自身的上传次序进行排序。
95.处理单元200,用于对各个数据进行处理,得到每个数据的处理结果。
96.可选的,处理单元200具体用于:为各个数据分配时间戳和水印;时间戳指示数据
的处理时间;水印指示处理数据时的延迟时间;按照处理时间从早到晚的顺序,并延迟每个数据的延迟时间之后,对各个数据进行处理,得到每个数据的处理结果。
97.处理单元200具体用于:对各个数据中符合预设条件的数据进行删除,得到有效流数据;预设条件为:数据的字段值为空,以及数据的字段包含有预设敏感字符;按照处理时间从早到晚的顺序,并延迟每个数据的延迟时间之后,对于有效流数据中的每个数据进行处理,得到每个数据的处理结果。
98.处理单元200具体用于:对有效流数据中的各个数据进行降维,以使剔除有效流数据中每个数据的冗余属性列,得到目标流数据;按照处理时间从早到晚的顺序,并延迟每个数据的延迟时间之后,对于目标流数据中的每个数据进行处理,得到每个数据的处理结果。
99.处理单元200具体用于:对目标流数据中的各个数据进行分类,得到多个数据分组;数据分组包括预设属性相同的多个数据;对于每个数据分组,按照处理时间从早到晚的顺序,并延迟每个数据的延迟时间之后,依次对数据分组中各个数据进行处理,得到数据分组中每个数据的处理结果。
100.确定单元300,用于基于数据所包含的字段,确定数据的第一校验码。
101.可选的,确定单元300具体用于:将数据所包含的各个字段进行拼接,得到数据的字符串;对字符串进行校验码转换,得到数据的第一校验码。
102.转换单元400,用于对处理结果进行校验码转换,得到数据的第二校验码。
103.修正单元500,用于在第一校验码和第二校验码不相同的情况下,对处理结果进行修正,得到满足预设要求的修正结果;预设要求为:经由对修正结果进行校验码转换得到的第二校验码,与第一校验码保持一致。
104.保存单元600,用于将数据以及修正结果,保存到目标数据库中。
105.可选的,保存单元600还用于:在第一校验码和第二校验码相同的情况下,直接将数据以及处理结果,保存到目标数据库中。
106.综上所述,本实施例对流数据所示数据的第一校验码和第二校验码进行比对,在第一校验码和第二校验码不相同的情况下,对数据的处理结果进行修正,得到满足预设要求的修正结果,使得处理后的数据与处理前的数据保持一致。
107.本技术还提供了一种计算机可读存储介质,计算机可读存储介质包括存储的程序,其中,程序执行上述本技术提供的流数据处理方法。
108.本技术还提供了一种流数据处理设备,包括:处理器、存储器和总线。处理器与存储器通过总线连接,存储器用于存储程序,处理器用于运行程序,其中,程序运行时执行上述本技术提供的流数据处理方法,包括如下步骤:
109.从预设消息队列中获取流数据;所述流数据包括数据序列;所述数据序列包括经由源数据库上传给所述预设消息队列的多个数据,且每个所述数据均按照所述数据自身的上传次序进行排序;
110.对各个所述数据进行处理,得到每个所述数据的处理结果;
111.基于所述数据所包含的字段,确定所述数据的第一校验码;
112.对所述处理结果进行校验码转换,得到所述数据的第二校验码;
113.在所述第一校验码和所述第二校验码不相同的情况下,对所述处理结果进行修正,得到满足预设要求的修正结果;所述预设要求为:经由对所述修正结果进行校验码转换
得到的第二校验码,与所述第一校验码保持一致;
114.将所述数据以及所述修正结果,保存到目标数据库中。
115.具体的,在上述实施例的基础上,所述对各个所述数据进行处理,得到每个所述数据的处理结果,包括:
116.为各个所述数据分配时间戳和水印;所述时间戳指示所述数据的处理时间;所述水印指示处理所述数据时的延迟时间;
117.按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对各个所述数据进行处理,得到每个所述数据的处理结果。
118.具体的,在上述实施例的基础上,所述按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对各个所述数据进行处理,得到每个所述数据的处理结果,包括:
119.对各个所述数据中符合预设条件的数据进行删除,得到有效流数据;所述预设条件为:数据的字段值为空,以及数据的字段包含有预设敏感字符;
120.按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对于所述有效流数据中的每个所述数据进行处理,得到每个所述数据的处理结果。
121.具体的,在上述实施例的基础上,所述按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对于所述有效流数据中的每个所述数据进行处理,得到每个所述数据的处理结果,包括:
122.对所述有效流数据中的各个所述数据进行降维,以使剔除所述有效流数据中每个数据的冗余属性列,得到目标流数据;
123.按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对于所述目标流数据中的每个所述数据进行处理,得到每个所述数据的处理结果。
124.具体的,在上述实施例的基础上,所述按照处理时间从早到晚的顺序,并延迟每个所述数据的延迟时间之后,对于所述目标流数据中的每个所述数据进行处理,得到每个所述数据的处理结果,包括:
125.对所述目标流数据中的各个所述数据进行分类,得到多个数据分组;所述数据分组包括预设属性相同的多个数据;
126.对于每个所述数据分组,按照处理时间从早到晚的顺序,并延迟每个数据的延迟时间之后,依次对所述数据分组中各个数据进行处理,得到所述数据分组中每个数据的处理结果。
127.具体的,在上述实施例的基础上,所述基于所述数据所包含的字段,确定所述数据的第一校验码,包括:
128.将所述数据所包含的各个字段进行拼接,得到所述数据的字符串;
129.对所述字符串进行校验码转换,得到所述数据的第一校验码。
130.具体的,在上述实施例的基础上,所述对所述处理结果进行校验码转换,得到所述数据的第二校验码之后,还包括:
131.在所述第一校验码和所述第二校验码相同的情况下,直接将所述数据以及所述处理结果,保存到所述目标数据库中。
132.本技术实施例方法所述的功能如果以软件功能单元的形式实现并作为独立的产
品销售或使用时,可以存储在一个计算设备可读取存储介质中。基于这样的理解,本技术实施例对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该软件产品存储在一个存储介质中,包括若干指令用以使得一台计算设备(可以是个人计算机,服务器,移动计算设备或者网络设备等)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器、随机存取存储器、磁碟或者光盘等各种可以存储程序代码的介质。
133.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似部分互相参见即可。
134.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。