1.一种无监督的两阶段领域自适应方法。
背景技术:
2.基于传统机器学习的图像分类假设测试样本和训练样本需要满足独立同分布,同时需要大量与测试数据同分布的有标记样本保证模型的泛化性能,这两个条件在现实应用中很难实现。领域自适应能够突破传统机器学习的隐式假设,期望利用有标签的源域数据和无标签的目标域数据构建跨领域学习模型,能够解决机器学习中训练样本标签稀缺以及难以真正满足独立同分布条件的问题。
技术实现要素:
3.本发明针对目前基于低秩子空间学习的领域自适应方法中学习一个投影子空间导致域间分布差异减少不足的问题,提出两阶段伪标签精确化的领域自适应方法,利用对分类有意义的类别先验信息和局部结构信息,探索隐含在数据底层的内在规律,提升跨域图像分类模型的鲁棒性、泛化性和高效性。
4.为实现上述目的,本发明是通过的这样的技术方案实现的,方法概述如下:
5.该方法主要分为两个阶段,阶段一将源域和目标域投影到各自的子空间内,联合自适应概率图结构增强类间独立性和类内依赖性,同时使用条件分布对齐特征在类别空间中使得来自两个域的同类样本距离减少,进一步减少子空间内的条件分布差异。阶段二在训练伪标签时使用了不断优化的子空间进行引导,并将更新后的伪标签反馈至第一阶段。尽管刚开始训练的伪标签准确度较低,但是随着伪标签和子空间的不断交替更新,最终能够得到一个判别的、领域共享的子空间,从而获得一个对目标域分类性能最优的分类器。
6.本发明的主要特点如下:(1)为了实现跨域自适应,该算法分别学习针对于两个域的投影矩阵,能够最小化流形空间中的域偏移,获取对分类任务更可靠的特征。(2)数据对齐项迫使目标数据由源域数据的线性表示,并且使每个目标数据由其在源域中的相邻数据进行重建。(3)为了保证学习到的子空间的鉴别性,应该尽可能地保留数据中的标签信息,为了达到这一目的,联合使用源域样本的标签信息和预测的目标域样本伪标签信息。(4)引入条件特征对齐损失函数,以确保在类别空间中来自相同类别的样本能够尽可能的聚类,进一步在子空间内减少条件分布差异。(5)在学习判别的投影空间时,为了避免过拟合,联合学习自适应概率图,有效地保留了数据的几何结构,提高目标分类器的性能,获得更高的分类准确率。
7.本发明的优点在于:本发明提供的无监督的两阶段领域自适应方法,实现了源域向目标域的有效知识迁移,并且在预测精度和可靠性方面,应用于图像分类任务时更加具有优势。
附图说明
8.为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
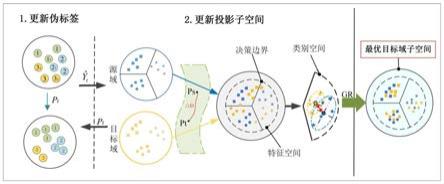
9.图1为本方法发明流程图。其中,正方形、圆形和五角星形分别表示3种不同类别的样本。ps为源域投影,p
t
表示目标域投影,表示预测的目标域样本的伪标签。gr(graph regularization)表示图正则化约束,
△
d表示流形空间中的域偏移。lc表示c类样本被错误的判定为第l类,这是由于刚开始目标域伪标签的不够准确所引起的,通过投影子空间p
t
的不断更新,伪标签随之不断精确化,目标数据能够被正确分类。
具体实施方式
10.本发明提出一种无监督的两阶段领域自适应方法,该方法在四个层面上实现了源域和目标域之间的对齐,减少了分布差异。分别为:子空间对齐、数据对齐、标签对齐和图结构对齐。
11.子空间对齐项:ps和p
t
分别定义为源域子空间投影和目标域子空间投影,最小化流形空间中两个特定域的投影之间的距离,能够减少域偏移。子空间对齐项定义如下:
[0012][0013]
数据对齐项:为了缩小源域和目标域之间的分布差异,利用数据的内在信息学习一个最优的目标投影p
t
。假设目标数据由公共子空间中的源域数据线性表示,并且通过对重建矩阵施加低秩约束,使得每个目标数据都可以由其在源域中的相似邻居来重建。数据对齐损失函数定义如下:
[0014][0015]
其中,rank(
·
)表示一个矩阵的秩运算符,然而,秩函数的非凸性使得等式(2)很难优化。因此,一般利用核范数作为矩阵秩的凸近似,等式(2)可以被重新表述为:
[0016][0017]
其中,||
·
||
*
表示矩阵的核范数。
[0018]
在无监督领域自适应问题中,尽管目标域的标签不可用,但是可以充分利用已有的源域标签和目标域的伪标签来提高生成目标投影的判别性。使用svm分类器初始化伪标签,由于源域样本和目标域样本具有不同的结构,刚开始的伪标签并不精确,通过学习目标子空间来逐步更新伪标签。标签对齐项定义如下:
[0019][0020]
其中,
⊙
是矩阵的hadamard乘积运算,表示源域和目标域的所有数据,m∈rd×n表示松弛矩阵。d是原始数据空间的维度,d表示子空间的维度,n=ns n
t
表示源域和目标域的样本总数。
[0021]
标签矩阵定义为:
[0022][0023]
其中,ys表示源域样本的标签,表示预测的目标域样本的伪标签。y
{i,j
}表示矩阵y的第{i,j}个元素,c是样本中的类别总数。
[0024]
为了在类别空间中聚类来自于同一类的两个域的样本,最小化域间条件分布差异,使用语义引导的最大平均距离(maximum mean distance,mmd)相似性特征对齐损失度量跨域条件分布的差异性。标签对齐项可以重述为下式:
[0025][0026]
其中,分别表示源域和目标域数据集。上式等价为:
[0027][0028]
其中,是mmd矩阵系数,其计算方式为:
[0029]
在源域向目标域知识迁移过程中,引入图结构来保持局部临近信息,同时可以避免过拟合问题。与现有的在高维空间中建立的图结构不同,在判别的目标域投影子空间中利用每个样本对象的语义信息和两个样本对象之间的距离信息建立了图结构,避免了高维空间的冗余信息和噪声。通过以下图结构对齐项来定义:
[0030][0031]
其中,dist(a,b)表示样本a和样本b之间的距离,en表示n维全1向量,约束矩阵q是转移概率矩阵,其每一个行都是一个概率分布。使用欧氏距离的平方定义任意两个在子空间中数据的距离。为了避免转移概率矩阵q出现平凡解,将式(8)可以重写为下式:
[0032][0033]
将子空间对齐项(1)、数据对齐项(3)、标签对齐项(7)和图结构对齐项(9)结合,得到最终的目标函数:
[0034][0035]
其中,α、β和λ是权重参数。
[0036]
采用实验评估了所提出方法在图像分类任务中的性能。在领域自适应问题的基准数据集4da上进行实验。将本发明和svm、dtsl、jgsa、bda、ldada、dac六种方法进行比较。其中分类准确率最高的结果使用加粗表示。
[0037][0038][0039]
通过实验结果可以看出本发明总体上取得了良好的分类性能。与其他对比方法相比,在12个跨域任务中,有8个任务取得了最优的结果,并且获得了最高的平均分类准确率,这代表了本发明在跨域图像分类任务中的有效知识可转移性。
[0040]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管通过上述实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
