1.本发明属于物流分拣和计算机视觉领域,涉及一种物流包裹目标检测的轻量化深度学习模型。
背景技术:
2.物流包裹在分拣机的分拣过程中,包裹可能存在重叠放置的情况,使得底层包裹的标签无法识别,导致包裹分配到错误路径,且袋装包裹、箱体包裹、信封袋包裹以及气泡袋包裹等常见包裹需要进行区分,以提供合理的抓取和分拣策略,因此需要进行重叠包裹、袋装包裹、箱体包裹、信封袋包裹以及气泡袋包裹的识别。目前的识别方法:监控录像等人眼观察的方法去识别,不但耗费人力精力,而且容易出错;的机器视觉目标检测方法有yolov3结合deep-sort(多目标跟踪)再剪枝的方法,以及基于faster r-cnn改进损失函数使得候选框更接近目标框的方法。由于yolov3相比较于yolov5具有很大的参数量,导致模型具有较长的训练时间和检测时间;基于faster r-cnn的方法属于两阶段检测方法,实时性较差,模型较大难以部署。
技术实现要素:
3.为了解决目前快递包裹类型识别过程中,目标检测模型参数量和计算量大、训练时间长、检测实时性差,难以部署在嵌入式硬件上等问题,本发明提供了一种轻量化的物流包裹目标检测模型,能够满足真实工作环境下的实时性、准确性、轻量化容易部署等要求。
4.本发明的目的是通过以下技术方案实现的:
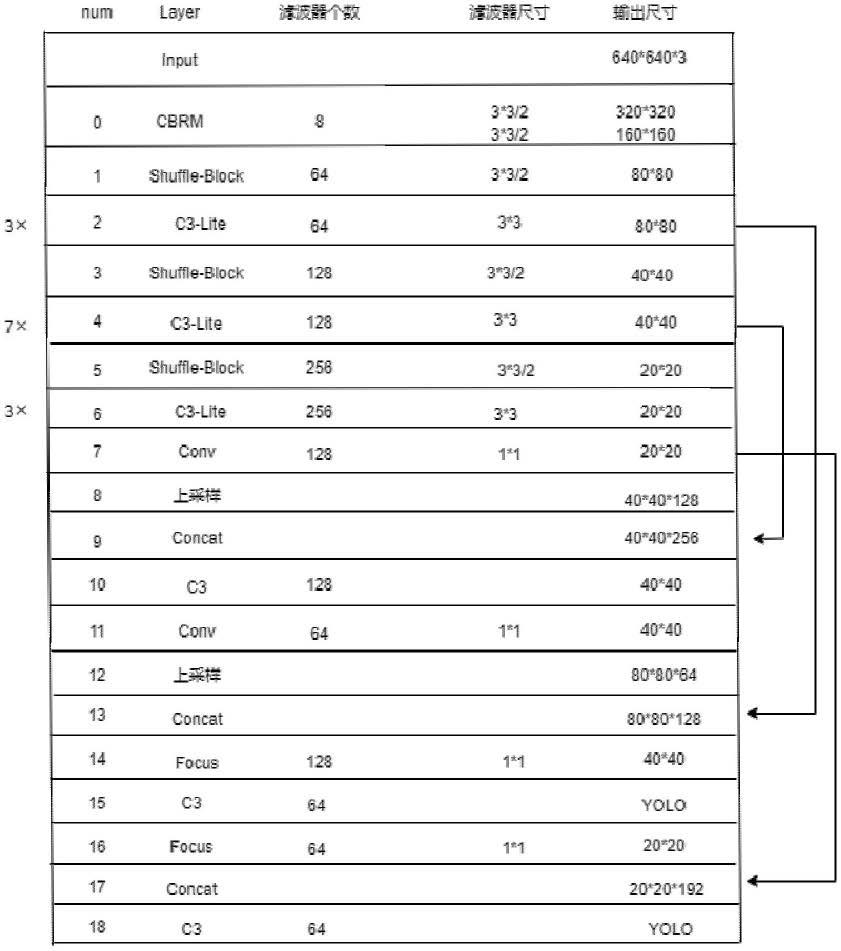
5.一种轻量化的物流包裹目标检测模型,由input模块、backbone模块、neck模块和prediction模块四部分构成,其中:
6.所述input模块是图像数据的输入端,用于将物流运输线上采集的尺寸为752
×
480的3通道图像数据处理成640
×
640
×
3的图像数据;
7.所述backbone模块用于提取input模块输出的图像数据的物流包裹特征;
8.所述neck模块用于对backbone模块提取的物流包裹特征进行混合和组合;
9.所述prediction模块用于处理neck模块获取的图像特征,并对目标类别和边界框进行预测并输出,即使用ciou_loss进行反向传播、更新梯度、减少损失,直至达到指定训练次数时或loss曲线不再下降且精度不再提高为止,使用nms进行筛选目标框;
10.所述backbone模块由第0层~第6层构成,neck模块由第7层~第18层构成,第15层和第18层分别作为prediction模块的中目标检测层和大目标检测层;
11.所述第0层为cbrm层,input模块输出的640
×
640
×
3图像数据作为第0层的输入,第0层输出的160
×
160
×
8图像数据作为第1层的输入;
12.所述第1层为shuffle-block层,步长s=2,第1层的输入图像数据大小为160
×
160
×
8,第1层输出的80
×
80
×
64图像数据作为第2层的输入;
13.所述第2层为c3-lite层,使用了3个bottleneck结构,c3-lite层的步长s=1,第2
层的输入图像数据大小为80
×
80
×
64,第2层输出的80
×
80
×
64图像数据同时作为第3层和第13层的输入;
14.所述第3层为shuffle-block层,步长s=2,第3层输入的图像数据大小为80
×
80
×
64,第3层输出的40
×
40
×
128图像数据作为第4层的输入;
15.所述第4层为c3-lite层,使用了7个bottleneck结构,c3-lite层的步长s=1,第4层的输入图像数据大小为40
×
40
×
128,第4层输出的40
×
40
×
128图像数据同时作为第5层和第9层的输入;
16.所述第5层为shuffle-block层,步长s=2,第5层的输入图像数据大小为40
×
40
×
128,第5层输出的20
×
20
×
256图像数据作为第6层的输入;
17.所述第6层为c3-lite层,使用了3个bottleneck结构,c3-lite层的步长s=1,第6层的输入图像数据大小为20
×
20
×
256,第6层输出的20
×
20
×
256图像数据作为第7层的输入;
18.所述第7层为conv层,第7层的输入图像数据大小为20
×
20
×
256,第7层输出的20
×
20
×
128图像数据同时作为第8层和第17层的输入;
19.所述第8层为上采样,第8层的输入图像数据大小为20
×
20
×
128,第8层输出的40
×
40
×
128图像数据作为第9层的输入;
20.所述第9层为concat层,第9层的输入图像大小为40
×
40
×
128 40
×
40
×
128,第9层输出的40
×
40
×
256图像数据作为第10层的输入;
21.所述第10层为c3层,第10层的输入图像大小为40
×
40
×
256,第10层输出的40
×
40
×
128图像数据作为第11层输入;
22.所述第11层为conv层,第11层的输入图像大小为40
×
40
×
128,第11层输出的40
×
40
×
64图像数据作为第12层的输入;
23.所述第12层为上采样层,第12层的输入图像大小为40
×
40
×
64,第12层输出的80
×
80
×
64图像数据作为第13层的输入;
24.所述第13层为concat层,第13层的输入图像大小为80
×
80
×
64 80
×
80
×
64,第13层输出的80
×
80
×
128图像数据作为第14层的输入;
25.所述第14层为focus层,第14层的输入图像大小为80
×
80
×
128,第14层输出的40
×
40
×
128图像数据作为第15层的输入;
26.所述第15层为c3层,第15层的输入图像大小为40
×
40
×
128,第15层输出的40
×
40
×
64图像数据作为第16层的输入,第15层即为prediction模块的中目标检测层;
27.所述第16层为focus层,第16层的输入图像大小为40
×
40
×
64,第16层输出的20
×
20
×
64图像数据作为第17层的输入;
28.所述第17层为concat层,第17层的输入图像大小为20
×
20
×
64 20
×
20
×
128,第17层输出的20
×
20
×
192图像数据作为第18层的输入;
29.所述第18层为c3层,第18层的输入图像大小为20
×
20
×
192,第18层输出为20
×
20
×
64,第18层即为prediction模块的大目标检测层。
30.相比于现有技术,本发明具有如下优点:
31.与现有的快递包裹目标检测模型相比,本发明的物流包裹目标检测模型在保证高识别精度和高map值的前提下,明显降低了参数量和计算量并缩短了模型训练时间,目标检
测速度也优于大部分网络模型,可更容易的部署到分拣设备的嵌入式硬件中。
附图说明
32.图1为shuffle-yolov5网络结构;
33.图2为shuffle-block结构;
34.图3为c3-lite结构;
35.图4为shuffle-yolov5识别效果;
36.图5为shuffle-yolov5的测试f1-score值图;
37.图6为shuffle-yolov5的测试精度图;
38.图7为shuffle-yolov5的测试map图。
具体实施方式
39.下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
40.本发明针对目前常见物流包裹目标检测方法的不足,提供了一种轻量化的物流包裹目标检测模型,包括:设计一种轻量化的特征提取网络,用于减少参数量计算量,提高特征提取速度;设计一种将低层细粒度信息与fpn pan(自顶向下 自底向上的特征金字塔网络)中的信息融合的融合方式;使用focus代替普通卷积下采样层,用于减少信息丢失,提高检测精度。
41.如图1所示,所述物流包裹目标检测模型由input模块、backbone模块、neck模块和prediction模块四部分构成,其中:
42.所述input模块是图像数据的输入端,本发明的图像数据绝大部分是在真实场景下即物流运输线上采集的,尺寸为752
×
480的3通道图片,图像数据进入input模块,经过mosaic数据增强、自适应锚框计算、自适应图片缩放等操作将图像数据统一处理成640
×
640
×
3(通道数)大小的图片数据。
43.所述backbone模块用于提取input模块输出的图像数据的物流包裹特征,将input模块输出的640
×
640
×
3图像数据作为第0层的cbrm的输入,cbrm(conv、bn、relu、maxpooling的缩写)指的是大小为3
×
3、步长为2的卷积操作,输出为320
×
320
×
8和大小为3
×
3、步长为2的最大池化操作,输出为160
×
160
×
8;第1层shuffle-block(步长:s=2)的输入来自第0层cbrm的输出,输出为80
×
80
×
64,第2层的c3-lite(步长:s=1),使用了3个bottleneck结构,输入来自第1层shuffle-block的输出80
×
80
×
64,第2层输出为80
×
80
×
64,第2层的输出同时作用于第3层和第13层;shuffle-block和c3-lite是本发明设计的轻量化backbone的主要单元模块,第3层的shuffle-block(步长:s=2)的输入来自第2层的输出80
×
80
×
64,输出为40
×
40
×
128,第4层的c3-lite(步长:s=1),使用了7个bottleneck结构,第4层的输入来自第3层的输出40
×
40
×
128,输出为40
×
40
×
128,第4层的输出同时作用于第5层和第9层,第5层的shuffle-block(步长:s=2)的输入来自第4层的输出40
×
40
×
128,输出为20
×
20
×
256,第6层的c3-lite(步长:s=1),使用了3个bottleneck结构,第6层的输入来自第5层的输出20
×
20
×
256,输出为20
×
20
×
256。
44.所述neck模块用于对backbone模块提取的物流包裹特征进行混合和组合,第7层conv的输入来自第6层的输出20
×
20
×
256,输出为20
×
20
×
128,同时作用于第8层和第17层,第8层上采样的输入来自第7层的输出20
×
20
×
128,输出为40
×
40
×
128,第9层concat的输入来自第8层的输出40
×
40
×
128和第4层的输出40
×
40
×
128,两者进行concat操作即按照通道数相加,输出为40
×
40
×
256,第10层c3输入来自第9层的输出40
×
40
×
256,输出为40
×
40
×
128,第11层conv的输入来自第10层的输出40
×
40
×
128,输出为40
×
40
×
64,第12层上采样的输入来自11层的输出40
×
40
×
64,输出为80
×
80
×
64,第13层concat层的输入来自12层的输出80
×
80
×
64和第2层的输出80
×
80
×
64,输出为80
×
80
×
128,第14层focus的输入来自13层的输出80
×
80
×
128,输出为40
×
40
×
128,第15层c3层的输入来自14层的输出40
×
40
×
128,输出为40
×
40
×
64,第15层即为中目标检测层,第16层focus的输入来自第15层的输出40
×
40
×
64,输出为20
×
20
×
64,第17层concat的输入来自第16层的输出20
×
20
×
64和第7层的输出输出为20
×
20
×
128,按通道数相加输出为20
×
20
×
192,第18层的输入来自第17层的输出20
×
20
×
192,输出为20
×
20
×
64,第18层即为大目标检测层。
45.所述第15层和第18层分别作为prediction模块的中目标检测层和大目标检测层,prediction模块用于处理neck模块获取的图像特征,并对目标类别和边界框进行预测并输出,即使用ciou_loss(损失函数)用于反向传播、更新梯度、减少损失,直至达到指定训练次数时或loss曲线不再下降且精度不再提高为止,nms(非极大值抑制)用于筛选目标框。
46.具体设计方法如下:
47.一、backbone的设计:一种能更有效的能保证各组信息交流的轻量化的特征提取网络。
48.现有的快递包裹检测模型的backbone中,存在着众多的卷积操作,增加了模型的参数量和计算量。本发明设计了一种轻量化的backbone,将其中的主要单元模块命名为shuffle-block和c3-lite,该模块能明显的减少参数量和计算量。
49.如图2所示,shuffle-block由分支1、分支2和channel shuffle构成,其中:分支1和分支2的通道数与输入的特征通道数相同,分支1通过3*3/2的dwconv、1*1conv进行处理;分支2通过1*1conv、3*3/2的dwconv、1*1conv进行处理;由于分支1和分支2的通道数与输入的特征通道数相同,分支1和分支2经过concat处理后即按照通道数相加,图像数据的长宽都减半,通道数翻倍,concat的输出作为channel shuffle的输入,其采用的dwconv、channel shuffle中的gconv(group conv)都是比常规卷积更加轻量化的卷积操作。
50.如图3所示,c3-lite由分支1、分支2构成,其中:特征图输入分支1经过1*1的dwconv卷积操作降维后,再经过n个bottleneck叠加的操作(n分别是3、7、3),维度不变,得到的特征图与分支2经过1*1的dwconv卷积操作降维得到的特征图进行concat操作,最后再经过1*1的cbs标准卷积操作最终输出,这种设计减少了模型的参数量。bottleneck由分支a和分支b构成,其中:分支b不进行任何处理,分支a先是使用1*1的标准卷积进行降维,后使用3*3的标准卷积升维,再和分支b进行add操作,维度不变。
51.二、针对快递包裹检测图像的特点,设计包括中目标和大目标的多尺度特征融合方法。
52.本发明在特定的设备环境中进行物流包裹的目标识别,因此各种包裹在图像中为中目标或大目标,因此所设计的神经网络模型prediction部分包括中目标检测和大目标检
测两部分,即prediction模块中40
×
40
×
64用于检测中目标,20
×
20
×
64用于检测大目标。
53.三、设计一种低层细粒度信息与fpn pan中的信息融合方法,用于充分利用细粒度的特征。
54.为了合理利用特征图中的浅层特征信息,本发明设计了将低层细粒度信息与fpn pan中的信息融合的方法(见表1),得到了特征融合后的中目标的特征。该方法将经过第4层c3-lite后的特征图送到第9层的concat层,将经过第2层c3-lite后的特征图送到第13层的concat层,将经过第7层conv后的特征图送到第17层的concat层。该特征融合方式,不仅提升了神经网络的速度,而且保证了低层细粒度信息充分利用,提升了神经网络的效果。
55.表1
[0056][0057]
四、设计两个focus层进行下采样,减少下采样时带来的信息损失,提升精度和map。
[0058]
由于现有的快递包裹目标检测模型中的下采样层是用普通卷积实现的,这种实现方式会带来信息的丢失。针对这个问题,本发明设计两个focus层进行下采样,通过切片操
作把高分辨率的特征图拆分成多个低分辨率的图片/特征图,结合三中设计的特征融合的方式,focus层将宽高平面上的信息转换到通道维度,再通过3*3卷积的方式提取不同特征。采用这种方式可以减少下采样带来的信息损失,提升了模型的精度和map。
[0059]
实施例:
[0060]
(1)搭建本发明物流包裹目标检测模型的运行环境,硬件配置为12th gen intel core i9-12900k 3020ghz处理器,nvidia geforce gtx 3090ti显卡,操作系统为windows11 64位系统,深度学习框架为pytorch,gpu加速库为cuda11.3和cudnn8.3.2,编程语言为python(软、硬件不局限于以上配置环境)。
[0061]
(2)构建数据集与数据增强。首先是图片数据的获取,本次任务的图片数据绝大多数都是在真实的工作环境下即物流运输线上拍摄获取,采用了翻转图像、亮度颜色和对比度增强等方法进行数据增强,然后对数据集进行标注,进而将数据集按照8:1:1的比例随机划分为训练集、验证集和测试集。
[0062]
(3)将训练集和验证集输送到预训练模型中进行模型训练,当达到指定训练次数时或loss曲线不再下降且精度不再提高为止,将训练好的模型保存,然后将测试集输送到保存好的网络模型中,输出物流包裹的目标检测结果,其检测结果如图4~图7所示。
[0063]
通过图4~7可以得出:在精确度和map等目标检测的评估指标下,可以看出本发明的精确度、召回率以及map都很优秀,从而证明本发明的有效性。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。