1.本说明书涉及计算机技术领域,尤其涉及一种房屋地址的解析方法、装置、设备及介质。
背景技术:
2.在数据分析及预测领域,为了实现以家庭为单位分析年龄分布情况、性别分布情况、收入分布情况、疾病分布情况等,获取人与房屋地址之间的翻脸关系是十分重要的,其次,例如收发快递,人口统计、房屋租赁、社区登记等也需要提供中文地址或者房屋地址。因此房屋地址的正确解析是进行相关业务的重要前提。由于受到数据隐私、填写方式各异,填写人习惯不同等各种条件的限制,导致采集的房屋地址数据中存在不规范、缺失、格式不一致甚至错误矛盾的信息等各种问题,给社会统计带来多种的管理困难问题。
3.当前的房屋地址解析结果的质量参差不齐,基于分词方法进行解析时由于分词解析受到词库大小的限制,无法解析到精确地房屋地址,且解析效率低。
4.因此,现需要一种高效且精确的房屋地址解析方法。
技术实现要素:
5.本说明书一个或多个实施例提供了一种房屋地址的解析方法、装置、设备及介质,用于解决如下技术问题:如何提供一种可以高效准确解析房屋地址的方法。
6.本说明书一个或多个实施例采用下述技术方案:
7.本说明书一个或多个实施例提供一种房屋地址的解析方法,包括:
8.获取待解析房屋地址;
9.将所述待解析房屋地址拆分为行政区域地址片段与其余地址片段;
10.基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果;
11.根据预先设置的格式对所述其余地址片段进行处理,并对处理后的其余地址片段进行解析,得到第二解析结果;
12.根据所述第一解析结果与所述第二解析结果,确定所述待解析房屋地址符合要求的解析结果。
13.在本说明书一个或多个实施例中,所述基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果之前,所述方法还包括:
14.建立包括第一数据的多层级行政区域划分词库;其中,所述第一数据包括:各行政区域地址的区划名称、所述各区划名称的后缀、所述各行政区域地址的区划级别与所述各行政区域地址的级别标签;
15.基于所述区域名称确定所述各行政区域的后缀,以根据所述各行政区域的后缀设置不同的区划级别;其中,所述后缀包括:省、市、区、街道、社区;
16.基于各行政区域的后缀确定对应的级别标签,并基于所述各行政区域的后缀,分别为不同的后缀对应的内容赋予区划级别;
17.建立包括多个第二数据项的多层级模式库;其中,所述第二数据项包括:模式名称、模式、模式级别、级别标签;
18.将所述多层级行政区域划分词库与所述多层级模式库存储于配置库中,以便基于所述配置库调用数据信息。
19.在本说明书一个或多个实施例中,所述根据所述各行政区域的后缀设置不同的区划级别,具体包括:
20.根据所述各行政区域的后缀,确定所述多层级行政区域划分词库的分词内容包括:省级内容、市级内容、区级内容、街道级内容、社区级内容;
21.根据所述多层级行政区域划分词库的分词内容,设置不同的区划级别;其中,所述省级内容的区划级别大于所述市级内容的区划级别,所述市级内容的区划级别大于所述区级内容的区划级别,所述区级内容的区划级别大于所述街道级内容的区划级别,所述街道级内容的区划级别大于所述社区级内容的区划级别。
22.在本说明书一个或多个实施例中,所述基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果,具体包括:
23.基于正向顺序逐级读取所述行政区域地址片段的字符;
24.根据所述区划级别依次确定对应的行政区域划分词库;
25.基于预设最大长度匹配方式,依次在所述行政区域划分词库中确定与所述字符相匹配的区划名称及后缀,确定第一匹配结果;
26.根据所述区划级别对所述第一匹配结果进行排序,获得第一解析结果。
27.在本说明书一个或多个实施例中,所述基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果之后,所述方法还包括:
28.获取所述待解析房屋地址的上下文环境信息;
29.确定与所述上下文环境信息相匹配的多层级行政区域划分词库;
30.根据所述第一解析结果与所述多层级行政区域划分词库,确定所述第一解析结果的缺补内容;
31.根据所述下文环境信息获取所述第一解析结果的缺补内容,并基于所述多层级行政区域划分词库将所述缺补内容合并到所述第一解析结果中。
32.在本说明书一个或多个实施例中,所述根据预先设置的格式对所述其余地址片段进行处理,对处理后的其余地址片段进行解析,得到第二解析结果,具体包括:
33.利用正则表达式对所述其余地址片段的地址格式进行标准化处理,获得处理后的其余地址片段;
34.根据所述多层级模式库中的模式级别,依次对所述处理后的其余地址片段进行模式匹配,获得第二匹配结果;
35.根据所述多层级模式库的模式内容,对所述第二匹配结果进行排序,获得第二解析结果。
36.在本说明书一个或多个实施例中,所述根据所述第一解析结果与所述第二解析结果,确定所述待解析房屋地址符合要求的解析结果,具体包括:
37.根据所述第一解析结果与所述第二解析结果,在所述行政区域地址片段与其余地址片段中删除对应的字段;
38.将所述第一解析结果与所述第二解析结果进行合并,获得所述待解析房屋地址符合要求的解析结果。
39.本说明书一个或多个实施例提供一种房屋地址的解析设备,包括:
40.至少一个处理器;以及,
41.与所述至少一个处理器通信连接的存储器;其中,
42.所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够:
43.获取待解析房屋地址;
44.将所述待解析房屋地址拆分为行政区域地址片段与其余地址片段;
45.基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果;
46.根据预先设置的格式对所述其余地址片段进行处理,并对处理后的其余地址片段进行解析,得到第二解析结果;
47.根据所述第一解析结果与所述第二解析结果,确定所述待解析房屋地址符合要求的解析结果。
48.本说明书一个或多个实施例提供的一种非易失性计算机存储介质,存储有计算机可执行指令,所述计算机可执行指令设置为:
49.获取待解析房屋地址;
50.将所述待解析房屋地址拆分为行政区域地址片段与其余地址片段;
51.基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果;
52.根据预先设置的格式对所述其余地址片段进行处理,并对处理后的其余地址片段进行解析,得到第二解析结果;
53.根据所述第一解析结果与所述第二解析结果,确定所述待解析房屋地址符合要求的解析结果。
54.本说明书实施例采用的上述至少一个技术方案能够达到以下有益效果:
55.通过对房屋地址的拆分,使得行政区域地址片段可以通过预设分词方式进行高效高质量的解析,避免了基于分词方式解析全部房屋地址时,所需数据库规模大造成的解析效率低的问题。通过对其余地址片段进行处理后解析,使得解析结果更加规范,提高了房屋地址解析的准确性。
附图说明
56.为了更清楚地说明本说明书实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。在附图中:
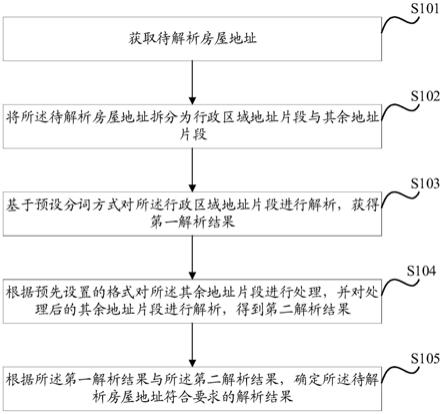
57.图1为本说明书实施例提供的一种房屋地址的解析方法的流程示意图;
58.图2为本说明书实施例提供的一种应用场景下房屋地址解析方法的概要流程图;
59.图3为本说明书实施例提供的一种房屋地址的解析装置的内部结构示意图;
60.图4为本说明书实施例提供的一种房屋地址的解析设备的内部结构示意图;
61.图5为本说明书实施例提供的一种非易失性存储介质的内部结构示意图。
具体实施方式
62.本说明书实施例提供一种房屋地址的解析方法、装置、设备及介质。
63.为了使本技术领域的人员更好地理解本说明书中的技术方案,下面将结合本说明书实施例中的附图,对本说明书实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本说明书一部分实施例,而不是全部的实施例。基于本说明书实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都应当属于本说明书保护的范围。
64.如图1所示,本说明书一个或多个实施例提供了一种房屋地址的解析方法的流程示意图。
65.本方案提供的一种房屋地址解析方法可以应用于多种不同的应用领域,例如:需要进行人口统计的社会服务领域、需要进行房屋地址统计的租赁销售领域、需要进行流调管理的医疗溯源领域等不同的应用领域,由各个不同领域对应的计算设备(如服务器或各个执行单元)执行方案内容。如图1所示,一种房屋地址的解析方法,包括以下步骤:
66.s101:获取待解析房屋地址。
67.在数据分析与预测等领域中,存在着基于房屋地址获取人员信息的数据分析需求。例如:通过人员与房屋之间的关联信息,可以实现以家庭为单位分析人口年龄分布情况、性别分布情况、收入分布情况、支出情况、疾病分布情况、教育程度分布情况等,以便为相关机构提供决策依据或者为经济单位提供市场支持数据。为了实现各类应用领域对与房屋地址相关联的数据分析的需求,那么房屋地址的解析工作是重要的前提条件。
68.所以,为了实现对房屋地址的解析工作,需要获取各个不同需求下待解析的房屋地址,以便对待解析的房屋地址进行后续的解析。
69.s102:将所述待解析房屋地址拆分为行政区域地址片段与其余地址片段。
70.由上述步骤s101可知房屋地址的解析工作是获取与房屋地址相关的人员信息的重要前提条件。现有技术中由于受到数据隐私、人员素质、书写环境等条件的影响,通过人为方式上门摸排或者用户自行填报方式采集的房屋地址数据,存在数据缺失、书写错误、格式不一致等各类问题,导致房屋地址的不精确,影响后续对房屋地址的利用分析工作。现有技术中为了改善这一问题,采用分词的方式或者单纯采用模式匹配的方式进行房屋地址的解析。
71.但是当采用分词方法进行解析时,如果需要解析全部的房屋地址则受到词库大小的限制将无法解析的精确的房屋地址。例如:对某个社区中的地址进行房屋地址的解析,如果初步统计到社区级的词库大约有679,000条数据,而假设每个社区管辖有3个小区是,将大约有2037,000条数据,此时如果全部基于分词方法解析全部的房屋地址,那么由于词库规模巨大,将导致解析效率过低。而当单纯采用模式匹配的方式进行解析时,由于数据是基于用户自主填写获得的,将存在简写、漏写、格式不一致的问题,从而导致解析后的准确性低。
72.为了解决上述基于分词方式与单纯的模式匹配方式进行房屋地址解析时遇到的房屋解析结果准确性低,效率低下的问题。本说明书一个或多个实施例中,将获取的待解析房屋地址进行了拆分,获得行政区域地址片段与其余地址片段,从而基于不同的地址片段设定不同的解析方式对房屋地址的详细信息进行全面解析,避免了单纯基于分词方式或模
式匹配方式,对全部地址进行解析时造成的效率低的问题。
73.s103:基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果。
74.在本说明书一个或多个实施例中,所述基于预设分词方式对行政区域地址片段进行解析,获得第一解析结果之前,方法还包括词库以及模式库的建立过程,具体的包括以下步骤:首先建立包括第一数据的多层级行政区域划分数据库。其中,需要说明的是第一数据包括:各行政区域地址的区划名称、所述各区划名称的后缀、所述各行政区域地址的区划级别与所述各行政区域地址的级别标签。然后基于区域名称确定各行政区域的后缀,以根据各行政区域的后缀设置不同的区划级别;其中,所述后缀包括:省、市、区、街道、社区。根据各行政区域的后缀确定对应的级别标签,基于各行政区域的后缀,分别为不同的后缀对应的内容赋予区划级别。为了可以清楚的理解该多层级行政区域划分数据库,如下表1所示提供了一种应用场景下的5级行政化词库的示例表。
[0075][0076][0077]
表1.一种应用场景下的5级行政化词库的示例表
[0078]
其中,还需要说明的是每个级别的行政区划的后缀可以包括多种情况,如下表2所示为一种应用常见下区划后缀的示例表。由表2可知区划级别1对应的后缀可以包括:省、自治区、特别行政区。区划级别2对应的后缀可以包括:市、自治州、盟。区划级别3对应的后缀可以包括:自治县、县、自治旗、旗/特区、林区、区。区划级别4对应的后缀包括:街道、镇、族乡、民族苏木、木、辖区。区划级别5对应的后缀包括:社区。
[0079]
区划级别区划后缀1省/自治区/特别行政区2市/自治州/盟3自治县/县/自治旗/旗/特区/林区/区4街道/镇/族乡/乡/民族苏木/苏木/县辖区5社区
[0080]
表2.一种应用常见下区划后缀的示例表
[0081]
此外,因为将待解析房屋地址拆分为了行政区域地址片段与其余地址片段,建立包括多个第二数据项的多层级模式库;其中,所述第二数据项包括:模式名称、模式、模式级别、级别标签。所述多层级行政区域划分词库与所述多层级模式库存储于配置库中,以便基于所述配置库调用数据信息。为了可以清楚的理解该多层级模式库,下表3提供了一种应用场景下的5级模式库的示例表。
[0082]
[0083][0084]
表3.一种应用场景下的5级模式库的示例表
[0085]
由上表3可知模式库中对各类模式名称所对应的模式进行了规定,方便了后续基于模式库对其余地址片段进行解析。
[0086]
在本说明书一个或多个实施例中,所述根据所述各行政区域的后缀设置不同的区划级别,具体包括:首先各行政区域的后缀,确定出多层级行政区域划分词库的分词内容包括:省级内容、市级内容、区级内容、街道级内容、社区级内容。然后再根据多层级行政区域划分词库的分词内容,设置不同的区划级别。其中,如上表1所示,区划级别包括1-5,而级别1大于级别2,级别2大于级别3依次类推,即省级内容的区划级别大于所述市级内容的区划级别,所述市级内容的区划级别大于所述区级内容的区划级别,所述区级内容的区划级别大于所述街道级内容的区划级别,所述街道级内容的区划级别大于所述社区级内容的区划级别。通过对区划级别的确认,便于后续解析时基于高级别到低级别的顺序对行政区域地址片段中各字段进行解析,避免解析过程出现混乱无序的现象。
[0087]
在建立了多层级行政区域划分词库与多层级模式库之后,将其存储于配置库中,以便基于配置可调用数据信息进行后续解析。在建立了配置库之后,需要对行政区域地址片段进行解析。在本说明书一个或多个实施例中,基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果,具体包括以下步骤:
[0088]
首先根据正向顺序逐级读取所述行政区域地址片段的字符。也就是由高等级1到低等级5,依次读取行政区域地址片段中相应的字符,进行有序解析。根据所述区划级别依次确定对应的行政区域划分词库。然后根据预先设置的最大长度匹配方式,依次在所述行政区域划分词库中确定与所述字符相匹配的区划名称及后缀,确定第一匹配结果。其中需要说明的是:基于最大长度匹配的方式依次确定与字符相匹配的区划名称及后缀是由于书写不规范的问题,房屋地址中相同的行政区域地址片段,可能存在“山东济南历中区”、“山东省济南市历中区”、“山东省济南历中区”等地址呈现。所以当依次对字符进行匹配时,先对第一级别的山东省进行字符匹配,此时如果存在“区划名称 区划后缀”的地址表示也就是存在“山东省”这种“山东”区划名称加“省”区划后缀的表示时,将优先匹配山东省。如果不能匹配例如只存在“山东”此时仅仅匹配区划名称。例如:对于房屋地址“山东省济南市市中区舜耕街道舜德社区舜德路1号太阳小区8号楼3单元603室”进行解析,解析结果示例如下表4与下表5所示。由表4可知依次进行解析时,先对级别1进行匹配,此时的剩余部分地址如下表4所示,为剩余字符“济南市市中区舜耕街道舜德社区舜德路1号太阳小区8号楼3单元603室”,如下表5所示为对应的解析结果
[0089]
待解析房屋地址剩余部分济南市市中区舜耕街道舜德社区舜德路1号太阳小区8号楼3单元603室
[0090]
表4.剩余部分地址
[0091][0092]
表5.解析结果
[0093]
继续执行上述步骤,直至待解析房屋地址为空,或者无法从行政区划词库中,找到任何匹配的内容后完成行政区域地址片段的解析。将匹配后获得的第一匹配结果放入相应的位置进行排序,获得第一解析结果。并在匹配成功后将该待解析房屋地址中匹配成功的字符进行删除,避免进行重复匹配,浪费资源。继续以上述房屋地址“山东省济南市市中区舜耕街道舜德社区舜德路1号太阳小区8号楼3单元603室”为例进行说明,那么对行政区域地址片段进行解析之后,待解析房屋地址剩余部分如下表6所示,最终的行政区域地址片段解析结果如下表7所示。
[0094]
待解析房屋地址剩余部分舜德路1号太阳小区8号楼3单元603室
[0095]
表6.待解析房屋地址剩余部分地址
[0096][0097]
表7.最终的行政区域地址片段解析结果
[0098]
由于在实际的数据填写过程中,填写人员可能会忽略共同的地址部分,例如:在社区中统计接种新冠疫苗时,由于同一社区所在地的省、市、区等地址信息都是已知的,只需要填写具体的地址部分即可。所以为了准确获得完整的地址信息,在本说明书一个或多个实施例中,所述基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果之后,方法还包括以下步骤:获取待解析房屋地址有关的预先设置的上下文环境信息,然后确定出和这个上下文环境信息相匹配的多层级行政区域划分词库。从而根据第一解析结果与多层级行政区域划分词库,确定出第一解析结果中的缺补内容。再根据下文环境信息获取第一解析结果的缺补内容,通过多层级行政区域划分词库将所述缺补内容合并到所述第一解析结果中,获得完整的行政区域地址片段的第一解析结果。
[0099]
s104:根据预先设置的格式对所述其余地址片段进行处理,并对处理后的其余地址片段进行解析,得到第二解析结果。
[0100]
在对行政区域地址片段进行解析之后,还需要对其余地址片段即详细地址部分进行解析。在本说明书一个或多个实施例中,根据预先设置的格式对其余地址片段进行处理,对处理后的其余地址片段进行解析,得到第二解析结果,具体包括:
[0101]
由于填写人员填写过程中多种因素的影响获得的地址信息的格式并不一致,没有统一的规范。所以在对其余地址片段进行解析时,首先要利用正则表达式对所述其余地址片段的地址格式进行标准化处理,获得处理后的其余地址片段,以便于后续的模式解析。如下表8所示,为本说明书一种应用场景下对其余地址片段进行标准化处理前后的对比示例
表。
[0102]
标准化前标准后5#3-6085号楼3单元608室5-3-6085号楼3单元608室5单元6-25单元6-2室5#6-25单元6-2室
[0103]
表8.其余地址片段进行标准化处理前后的对比示例表
[0104]
由表8可知,标准化处理之前的地址存在各种不标准的特殊符号,没有统一的格式形式,而经过标准化处理之后,各个地址信息的后缀统一便于对后续的模式匹配。在进行标准化处理之后,再根据多层级模式库中的模式级别,依次对所述处理后的其余地址片段进行模式匹配,获得第二匹配结果。例如上述表6.待解析房屋地址剩余部分地址为“舜德路1号太阳小区8号楼3单元603室”那么根据模式级别首先对门牌号进行匹配此时其余地址片段的剩余地址如下表9所示,而解析结果如下表10所示。
[0105]
待解析房屋地址剩余部分太阳小区8号楼3单元603室
[0106]
表9.其余地址片段的剩余地址的示例表
[0107][0108]
表10.门牌号解析结果
[0109]
按照其余地址片段中各个字符的顺序依次对地址进行解析直到,地址全部解析,此时的待解析房屋地址剩余地址为空。根据所述多层级模式库的模式内容,对所述第二匹配结果进行排序,获得第二解析结果。而解析结果如下表11所示为其余地址片段的最终解析结果的示例图。
[0110][0111]
表11.其余地址片段的最终解析结果的示例图
[0112]
s105:根据所述第一解析结果与所述第二解析结果,确定所述待解析房屋地址符合要求的解析结果。
[0113]
在获得第一解析结果与第二解析结果之后,需要对解析结果进行合并获得完整的解析结果。在本说明书一个或多个实施例中,根据第一解析结果与第二解析结果,确定待解析房屋地址符合要求的解析结果,具体包括以下步骤:首先根据第一解析结果与第二解析结果,在行政区域地址片段与其余地址片段中删除对应的字段。然后将第一解析结果与第二解析结果进行合并,获得待解析房屋地址符合要求的解析结果。例如上述过程中表7与表11获得的第一解析结果与第二解析结果进行合并之后,可以获得符合要求的解析地址,合
并结果如下表12所示。
[0114][0115]
表12待解析房屋地址符合要求的解析结果
[0116]
如图2所示,本说明书一个或多个实施例中,提供了一种应用场景下房屋地址解析的概要流程示意图。
[0117]
由图2可知,本说明书一个或多个实施例中在某应用场景下,首先基于配置词库获得风机行政区划词库,详细地址标准化模式库与分级模式库。将待解析房屋地址进行拆分获得行政区域地址片段与其余地址片段。然后根据获得的分级行政区划词库分级解析行政区域地址片段获得行政区划部分的第一解析结果。而对于其余地址片段则基于详细地址标准化模式库,进行详细地址的标准化处理,获得标准化后的待解析房屋地址的其余地址片段。再通过分级模式库分级解析其余地址片段获得其余地址片段的第二解析结果。最后将第一解析结果与第二解析结果进行合并,获得最终的解析结果。
[0118]
如图3所示,本说明书一个或多个实施例在,提供了一种房屋地址的解析装置的内部结构示意图。
[0119]
由图3可知,装置包括:
[0120]
获取模块301,用于获取待解析房屋地址;
[0121]
拆分模块302,用于将所述待解析房屋地址拆分为行政区域地址片段与其余地址片段;
[0122]
第一解析模块303,用于基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果;
[0123]
第二解析模块304,用于根据预先设置的格式对所述其余地址片段进行处理,并对处理后的其余地址片段进行解析,得到第二解析结果;
[0124]
确定模块305,用于根据所述第一解析结果与所述第二解析结果,确定所述待解析房屋地址符合要求的解析结果。
[0125]
在本说明书一个或多个实施例中,所述装置还包括建立模块;所述建立模块包括:第一建立模块、第一确定模块、第二确定模块、第二建立模块、存储模块;
[0126]
所述第一建立模块,用于建立包括第一数据的多层级行政区域划分词库;其中,所述第一数据包括:各行政区域地址的区划名称、所述各区划名称的后缀、所述各行政区域地址的区划级别与所述各行政区域地址的级别标签;
[0127]
所述第一确定模块,用于基于所述区域名称确定所述各行政区域的后缀,以根据所述各行政区域的后缀设置不同的区划级别;其中,所述后缀包括:省、市、区、街道、社区;
[0128]
所述第二确定模块,用于基于各行政区域的后缀确定对应的级别标签,并基于所述各行政区域的后缀,分别为不同的后缀对应的内容赋予区划级别;
[0129]
所述第二建立模块,用于建立包括多个第二数据项的多层级模式库;其中,所述第二数据项包括:模式名称、模式、模式级别、级别标签;
[0130]
所述存储模块,用于将所述多层级行政区域划分词库与所述多层级模式库存储于配置库中,以便基于所述配置库调用数据信息。
[0131]
在本说明书一个或多个实施例中,所述第二确定模块具体包括:第三确定模块与设置模块;
[0132]
所述第三确定模块,用于根据所述各行政区域的后缀,确定所述多层级行政区域划分词库的分词内容包括:省级内容、市级内容、区级内容、街道级内容、社区级内容;
[0133]
所述设置模块,用于根据所述多层级行政区域划分词库的分词内容,设置不同的区划级别;其中,所述省级内容的区划级别大于所述市级内容的区划级别,所述市级内容的区划级别大于所述区级内容的区划级别,所述区级内容的区划级别大于所述街道级内容的区划级别,所述街道级内容的区划级别大于所述社区级内容的区划级别。
[0134]
在本说明书一个或多个实施例中,所述第一解析模块具体包括:读取模块、第四确定模块、第五确定模块、第一排序模块;
[0135]
所述读取模块,用于基于正向顺序逐级读取所述行政区域地址片段的字符;
[0136]
所述第四确定模块,用于根据所述区划级别依次确定对应的行政区域划分词库;
[0137]
所述第五确定模块,用于基于预设最大长度匹配方式,依次在所述行政区域划分词库中确定与所述字符相匹配的区划名称及后缀,确定第一匹配结果;
[0138]
所述第一排序模块,用于根据所述区划级别对所述第一匹配结果进行排序,获得第一解析结果。
[0139]
在本说明书一个或多个实施例中,所述装置还包括:补缺模块;
[0140]
所述补缺模块用于获取所述待解析房屋地址的上下文环境信息;确定与所述上下文环境信息相匹配的多层级行政区域划分词库;根据所述第一解析结果与所述多层级行政区域划分词库,确定所述第一解析结果的缺补内容;根据所述下文环境信息获取所述第一解析结果的缺补内容,并基于所述多层级行政区域划分词库将所述缺补内容合并到所述第一解析结果中。
[0141]
在本说明书一个或多个实施例中,所述第二解析模块具体包括:标准化模块、匹配模块、第二排序模块;
[0142]
所述标准化模块,用于利用正则表达式对所述其余地址片段的地址格式进行标准化处理,获得处理后的其余地址片段;
[0143]
所述匹配模块,用于根据所述多层级模式库中的模式级别,依次对所述处理后的其余地址片段进行模式匹配,获得第二匹配结果;
[0144]
所述第二排序模块,用于根据所述多层级模式库的模式内容,对所述第二匹配结果进行排序,获得第二解析结果。
[0145]
在本说明书一个或多个实施例中,所述确定模块具体包括:删除模块、合并模块;
[0146]
所述删除模块,用于根据所述第一解析结果与所述第二解析结果,在所述行政区域地址片段与其余地址片段中删除对应的字段;
[0147]
所述合并模块,用于将所述第一解析结果与所述第二解析结果进行合并,获得所述待解析房屋地址符合要求的解析结果。
[0148]
如图4所示,本说明书一个或多个实施例中,提供了一种房屋地址的解析设备的内部结构示意图。
[0149]
由图4可知,设备包括:
[0150]
至少一个处理器401;以及,
[0151]
与所述至少一个处理器401通信连接的存储器402;其中,
[0152]
所述存储器402存储有可被所述至少一个处理器401执行的指令,所述指令被所述至少一个处理器401执行,以使所述至少一个处理器401能够:
[0153]
获取待解析房屋地址;
[0154]
将所述待解析房屋地址拆分为行政区域地址片段与其余地址片段;
[0155]
基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果;
[0156]
根据预先设置的格式对所述其余地址片段进行处理,并对处理后的其余地址片段进行解析,得到第二解析结果;
[0157]
根据所述第一解析结果与所述第二解析结果,确定所述待解析房屋地址符合要求的解析结果。
[0158]
如图5所示,本说明书一个或多个实施例中,提供了一种非易失性存储介质的内部结构示意图。
[0159]
由图5可知,一种非易失性存储介质,存储有计算机可执行指令501,所述可执行指令501包括:
[0160]
获取待解析房屋地址;
[0161]
将所述待解析房屋地址拆分为行政区域地址片段与其余地址片段;
[0162]
基于预设分词方式对所述行政区域地址片段进行解析,获得第一解析结果;
[0163]
根据预先设置的格式对所述其余地址片段进行处理,并对处理后的其余地址片段进行解析,得到第二解析结果;
[0164]
根据所述第一解析结果与所述第二解析结果,确定所述待解析房屋地址符合要求的解析结果。
[0165]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置、设备、非易失性计算机存储介质实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0166]
上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0167]
以上所述仅为本说明书的一个或多个实施例而已,并不用于限制本说明书。对于本领域技术人员来说,本说明书的一个或多个实施例可以有各种更改和变化。凡在本说明书的一个或多个实施例的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本说明书的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。